 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLymph Node Gross Tumor Volume Detection in Oncology Imaging via Relationship Learning Using Graph Neural Network
Aug 29, 2020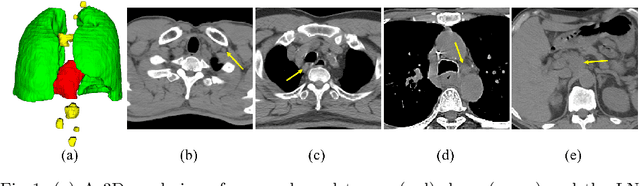
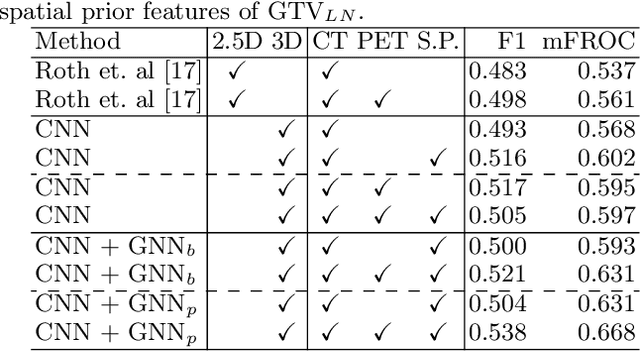
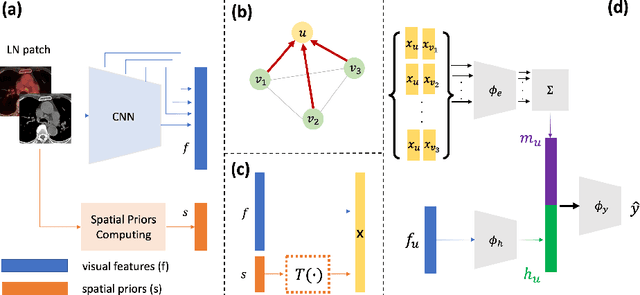
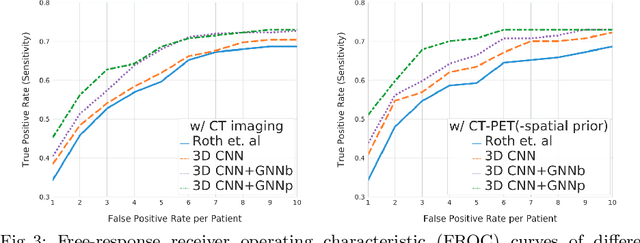
Determining the spread of GTV$_{LN}$ is essential in defining the respective resection or irradiating regions for the downstream workflows of surgical resection and radiotherapy for many cancers. Different from the more common enlarged lymph node (LN), GTV$_{LN}$ also includes smaller ones if associated with high positron emission tomography signals and/or any metastasis signs in CT. This is a daunting task. In this work, we propose a unified LN appearance and inter-LN relationship learning framework to detect the true GTV$_{LN}$. This is motivated by the prior clinical knowledge that LNs form a connected lymphatic system, and the spread of cancer cells among LNs often follows certain pathways. Specifically, we first utilize a 3D convolutional neural network with ROI-pooling to extract the GTV$_{LN}$'s instance-wise appearance features. Next, we introduce a graph neural network to further model the inter-LN relationships where the global LN-tumor spatial priors are included in the learning process. This leads to an end-to-end trainable network to detect by classifying GTV$_{LN}$. We operate our model on a set of GTV$_{LN}$ candidates generated by a preliminary 1st-stage method, which has a sensitivity of $>85\%$ at the cost of high false positive (FP) ($>15$ FPs per patient). We validate our approach on a radiotherapy dataset with 142 paired PET/RTCT scans containing the chest and upper abdominal body parts. The proposed method significantly improves over the state-of-the-art (SOTA) LN classification method by $5.5\%$ and $13.1\%$ in F1 score and the averaged sensitivity value at $2, 3, 4, 6$ FPs per patient, respectively.
Controllable Image Synthesis via SegVAE
Jul 17, 2020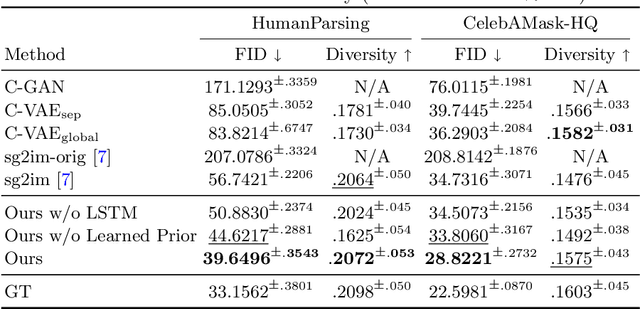
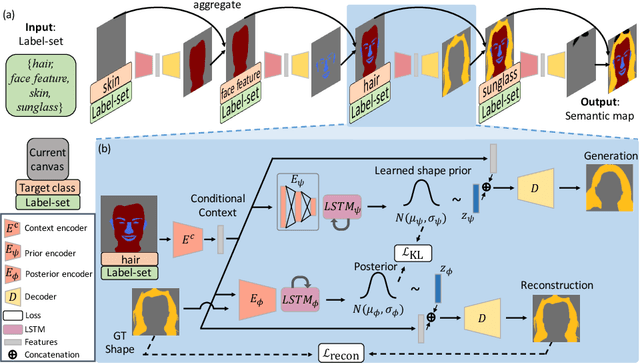

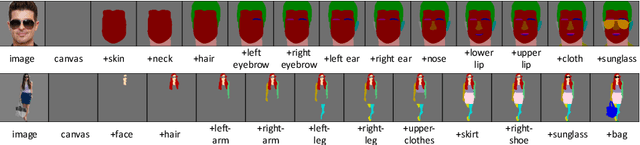
Flexible user controls are desirable for content creation and image editing. A semantic map is commonly used intermediate representation for conditional image generation. Compared to the operation on raw RGB pixels, the semantic map enables simpler user modification. In this work, we specifically target at generating semantic maps given a label-set consisting of desired categories. The proposed framework, SegVAE, synthesizes semantic maps in an iterative manner using conditional variational autoencoder. Quantitative and qualitative experiments demonstrate that the proposed model can generate realistic and diverse semantic maps. We also apply an off-the-shelf image-to-image translation model to generate realistic RGB images to better understand the quality of the synthesized semantic maps. Furthermore, we showcase several real-world image-editing applications including object removal, object insertion, and object replacement.
LayoutMP3D: Layout Annotation of Matterport3D
Mar 30, 2020
Inferring the information of 3D layout from a single equirectangular panorama is crucial for numerous applications of virtual reality or robotics (e.g., scene understanding and navigation). To achieve this, several datasets are collected for the task of 360 layout estimation. To facilitate the learning algorithms for autonomous systems in indoor scenarios, we consider the Matterport3D dataset with their originally provided depth map ground truths and further release our annotations for layout ground truths from a subset of Matterport3D. As Matterport3D contains accurate depth ground truths from time-of-flight (ToF) sensors, our dataset provides both the layout and depth information, which enables the opportunity to explore the environment by integrating both cues.
Visual Question Answering on 360° Images
Jan 10, 2020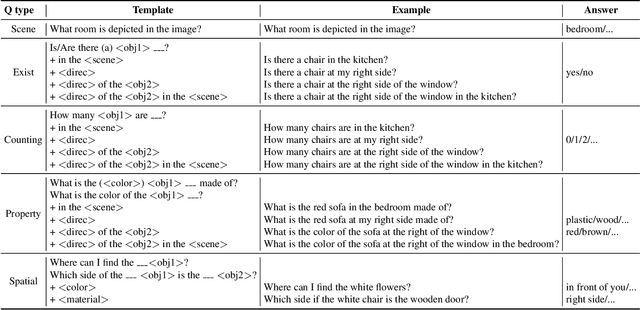
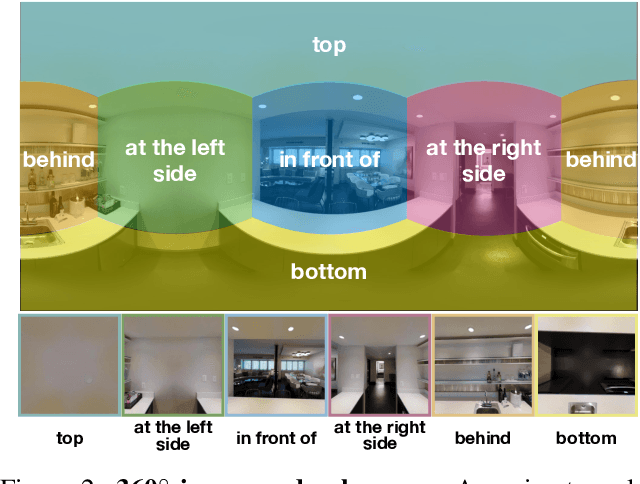
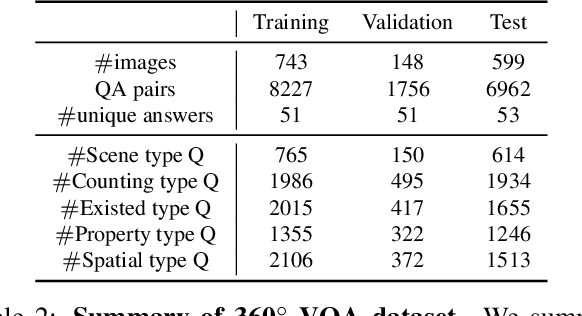
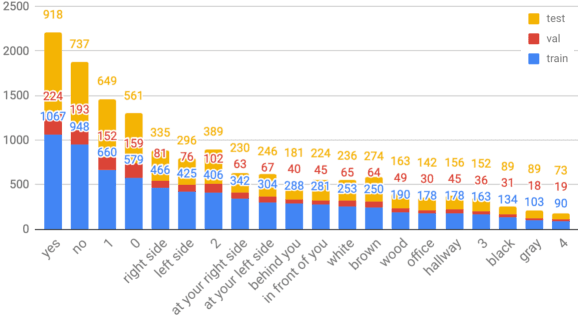
In this work, we introduce VQA 360, a novel task of visual question answering on 360 images. Unlike a normal field-of-view image, a 360 image captures the entire visual content around the optical center of a camera, demanding more sophisticated spatial understanding and reasoning. To address this problem, we collect the first VQA 360 dataset, containing around 17,000 real-world image-question-answer triplets for a variety of question types. We then study two different VQA models on VQA 360, including one conventional model that takes an equirectangular image (with intrinsic distortion) as input and one dedicated model that first projects a 360 image onto cubemaps and subsequently aggregates the information from multiple spatial resolutions. We demonstrate that the cubemap-based model with multi-level fusion and attention diffusion performs favorably against other variants and the equirectangular-based models. Nevertheless, the gap between the humans' and machines' performance reveals the need for more advanced VQA 360 algorithms. We, therefore, expect our dataset and studies to serve as the benchmark for future development in this challenging task. Dataset, code, and pre-trained models are available online.
Bias-Aware Heapified Policy for Active Learning
Nov 18, 2019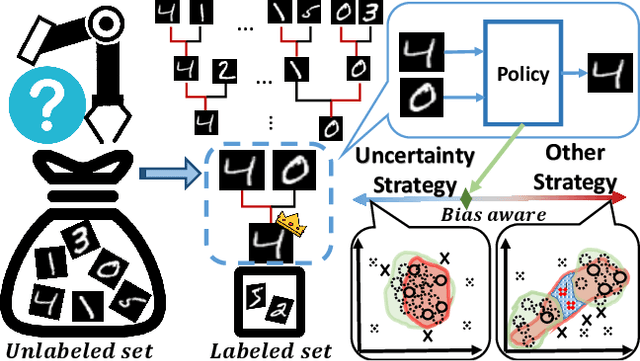
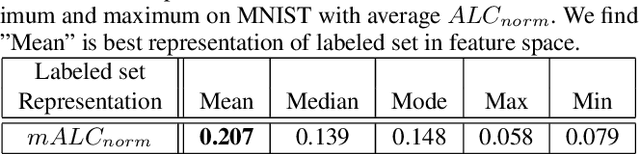
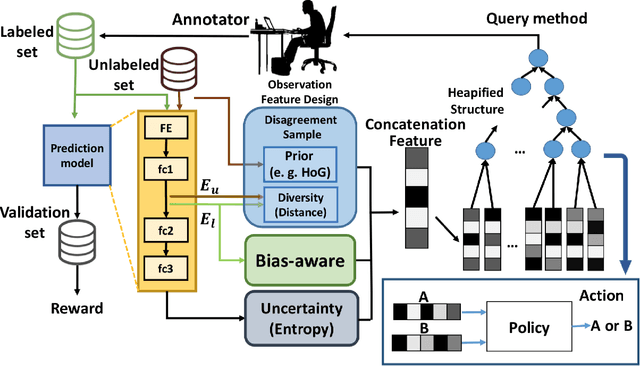
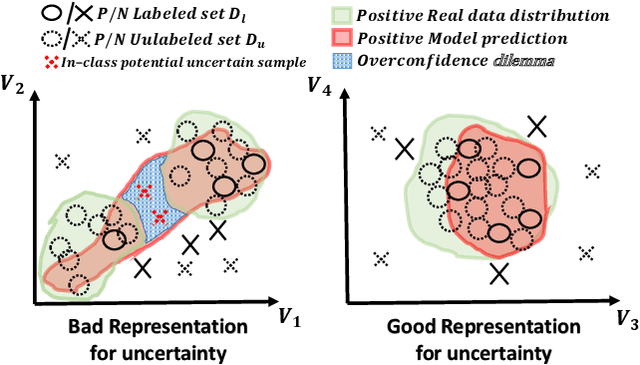
The data efficiency of learning-based algorithms is more and more important since high-quality and clean data is expensive as well as hard to collect. In order to achieve high model performance with the least number of samples, active learning is a technique that queries the most important subset of data from the original dataset. In active learning domain, one of the mainstream research is the heuristic uncertainty-based method which is useful for the learning-based system. Recently, a few works propose to apply policy reinforcement learning (PRL) for querying important data. It seems more general than heuristic uncertainty-based method owing that PRL method depends on data feature which is reliable than human prior. However, there have two problems - sample inefficiency of policy learning and overconfidence, when applying PRL on active learning. To be more precise, sample inefficiency of policy learning occurs when sampling within a large action space, in the meanwhile, class imbalance can lead to the overconfidence. In this paper, we propose a bias-aware policy network called Heapified Active Learning (HAL), which prevents overconfidence, and improves sample efficiency of policy learning by heapified structure without ignoring global inforamtion(overview of the whole unlabeled set). In our experiment, HAL outperforms other baseline methods on MNIST dataset and duplicated MNIST. Last but not least, we investigate the generalization of the HAL policy learned on MNIST dataset by directly applying it on MNIST-M. We show that the agent can generalize and outperform directly-learned policy under constrained labeled sets.
360SD-Net: 360° Stereo Depth Estimation with Learnable Cost Volume
Nov 11, 2019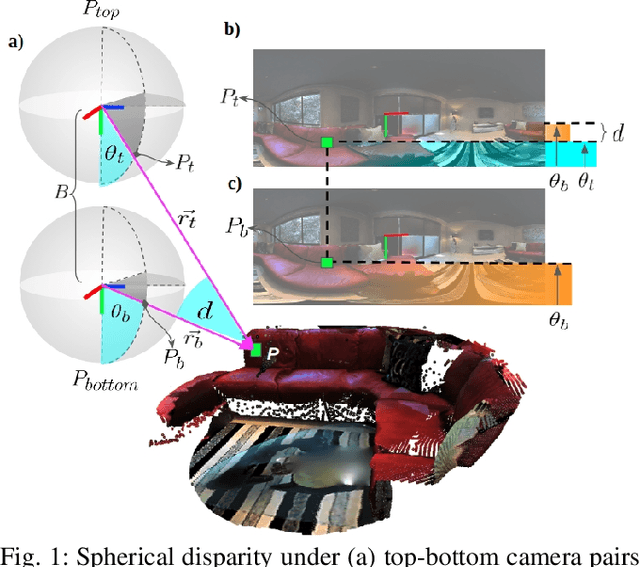
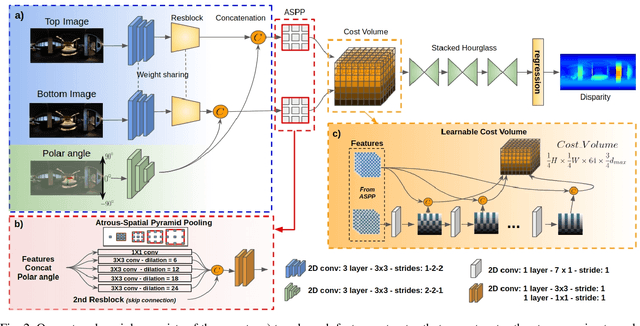
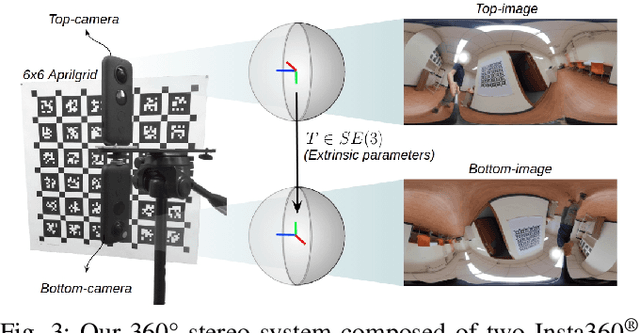
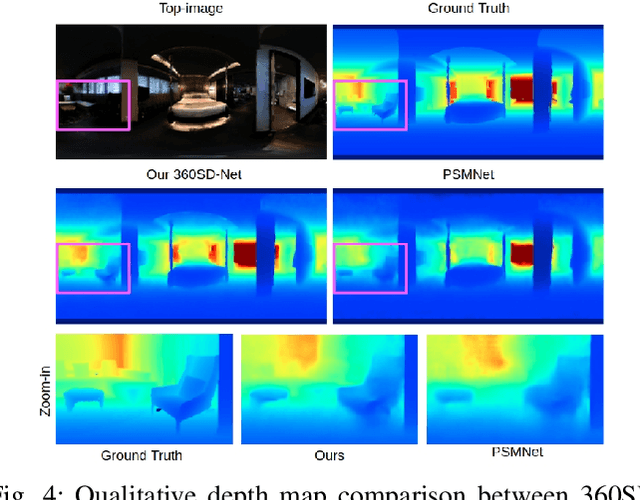
Recently, end-to-end trainable deep neural networks have significantly improved stereo depth estimation for perspective images. However, 360{\deg} images captured under equirectangular projection cannot benefit from directly adopting existing methods due to distortion introduced (i.e., lines in 3D are not projected onto lines in 2D). To tackle this issue, we present a novel architecture specifically designed for spherical disparity using the setting of top-bottom 360{\deg} camera pairs. Moreover, we propose to mitigate the distortion issue by (1) an additional input branch capturing the position and relation of each pixel in the spherical coordinate, and (2) a cost volume built upon a learnable shifting filter. Due to the lack of 360{\deg} stereo data, we collect two 360{\deg} stereo datasets from Matterport3D and Stanford3D for training and evaluation. Extensive experiments and ablation study are provided to validate our method against existing algorithms. Finally, we show promising results on real-world environments capturing images with two consumer-level cameras.
Autonomous UAV Landing System Based on Visual Navigation
Oct 29, 2019

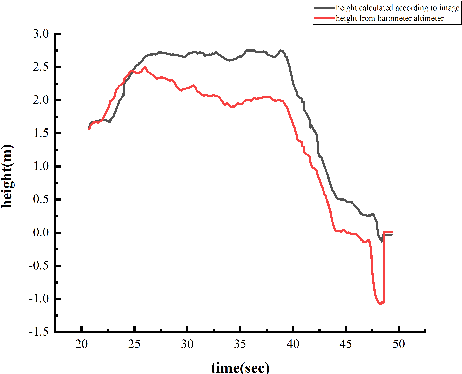
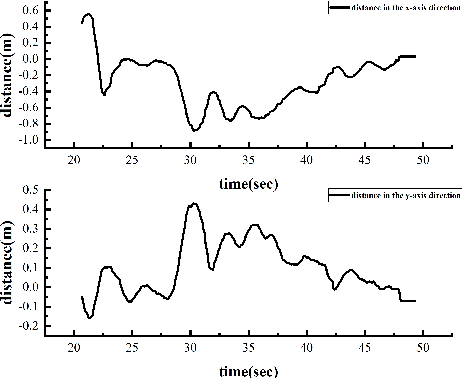
In this paper, we present an autonomous unmanned aerial vehicle (UAV) landing system based on visual navigation. We design the landmark as a topological pattern in order to enable the UAV to distinguish the landmark from the environment easily. In addition, a dynamic thresholding method is developed for image binarization to improve detection efficiency. The relative distance in the horizontal plane is calculated according to effective image information, and the relative height is obtained using a linear interpolation method. The landing experiments are performed on a static and a moving platform, respectively. The experimental results illustrate that our proposed landing system performs robustly and accurately.
360-Indoor: Towards Learning Real-World Objects in 360° Indoor Equirectangular Images
Oct 03, 2019


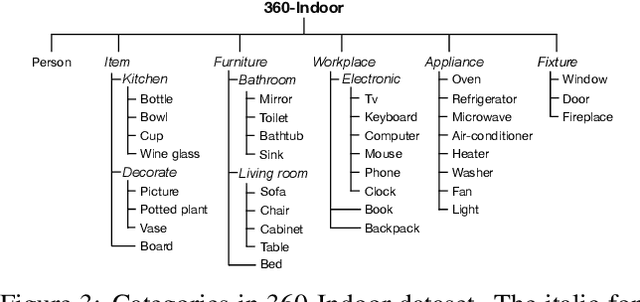
While there are several widely used object detection datasets, current computer vision algorithms are still limited in conventional images. Such images narrow our vision in a restricted region. On the other hand, 360{\deg} images provide a thorough sight. In this paper, our goal is to provide a standard dataset to facilitate the vision and machine learning communities in 360{\deg} domain. To facilitate the research, we present a real-world 360{\deg} panoramic object detection dataset, 360-Indoor, which is a new benchmark for visual object detection and class recognition in 360{\deg} indoor images. It is achieved by gathering images of complex indoor scenes containing common objects and the intensive annotated bounding field-of-view. In addition, 360-Indoor has several distinct properties: (1) the largest category number (37 labels in total). (2) the most complete annotations on average (27 bounding boxes per image). The selected 37 objects are all common in indoor scene. With around 3k images and 90k labels in total, 360-Indoor achieves the largest dataset for detection in 360{\deg} images. In the end, extensive experiments on the state-of-the-art methods for both classification and detection are provided. We will release this dataset in the near future.
Flat2Layout: Flat Representation for Estimating Layout of General Room Types
May 29, 2019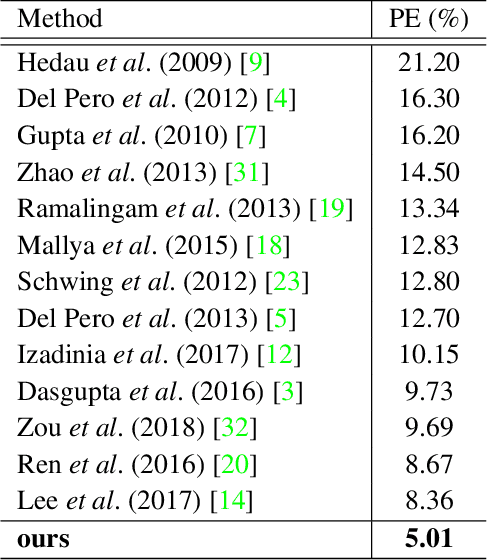


This paper proposes a new approach, Flat2Layout, for estimating general indoor room layout from a single-view RGB image whereas existing methods can only produce layout topologies captured from the box-shaped room. The proposed flat representation encodes the layout information into row vectors which are treated as the training target of the deep model. A dynamic programming based postprocessing is employed to decode the estimated flat output from the deep model into the final room layout. Flat2Layout achieves state-of-the-art performance on existing room layout benchmark. This paper also constructs a benchmark for validating the performance on general layout topologies, where Flat2Layout achieves good performance on general room types. Flat2Layout is applicable on more scenario for layout estimation and would have an impact on applications of Scene Modeling, Robotics, and Augmented Reality.
Radiotherapy Target Contouring with Convolutional Gated Graph Neural Network
Apr 05, 2019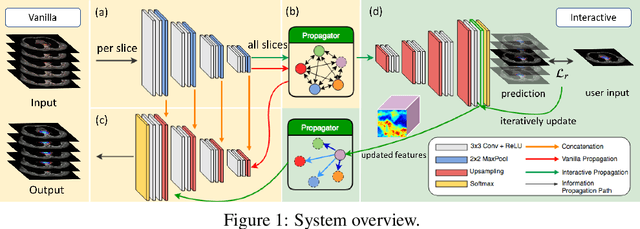
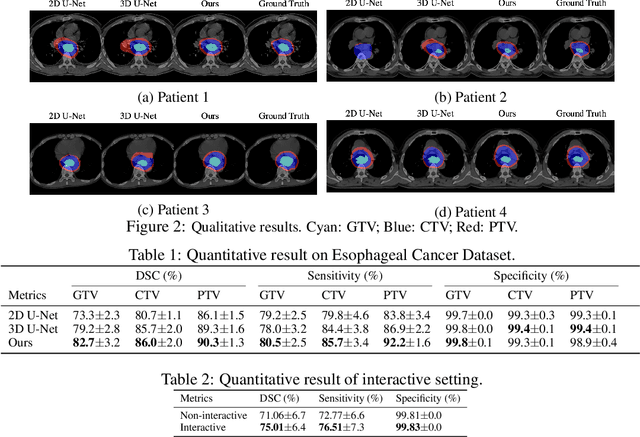
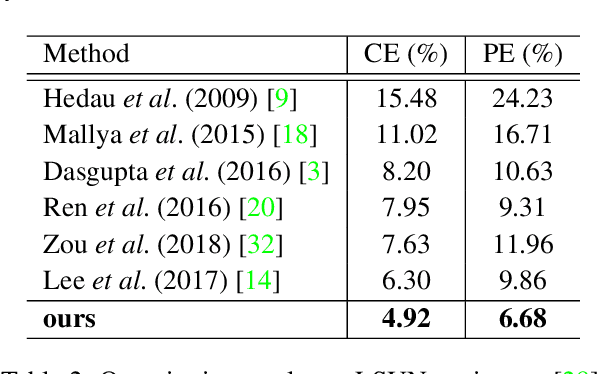
Tomography medical imaging is essential in the clinical workflow of modern cancer radiotherapy. Radiation oncologists identify cancerous tissues, applying delineation on treatment regions throughout all image slices. This kind of task is often formulated as a volumetric segmentation task by means of 3D convolutional networks with considerable computational cost. Instead, inspired by the treating methodology of considering meaningful information across slices, we used Gated Graph Neural Network to frame this problem more efficiently. More specifically, we propose convolutional recurrent Gated Graph Propagator (GGP) to propagate high-level information through image slices, with learnable adjacency weighted matrix. Furthermore, as physicians often investigate a few specific slices to refine their decision, we model this slice-wise interaction procedure to further improve our segmentation result. This can be set by editing any slice effortlessly as updating predictions of other slices using GGP. To evaluate our method, we collect an Esophageal Cancer Radiotherapy Target Treatment Contouring dataset of 81 patients which includes tomography images with radiotherapy target. On this dataset, our convolutional graph network produces state-of-the-art results and outperforms the baselines. With the addition of interactive setting, performance is improved even further. Our method has the potential to be easily applied to diverse kinds of medical tasks with volumetric images. Incorporating both the ability to make a feasible prediction and to consider the human interactive input, the proposed method is suitable for clinical scenarios.