 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurboGR: An Accelerated Training System for Large-Scale Generative Recommendation
May 13, 2026Generative recommendation (GR) has emerged as a promising paradigm that replaces fragmented, scenario-specific architectures with unified Transformer-based models, exhibiting scaling-law behavior where recommendation quality improves systematically with increased model capacity and training data. However, deploying GR at scale on Ascend NPUs faces fundamental system-level challenges. These challenges are further exacerbated on Ascend NPUs due to the absence of high-performance implementations for jagged operators and the architectural mismatch between irregular sparse primitives and NPU's dense-computation-optimized design. In this paper, we present \model, an Ascend-affinity training system for generative recommendation that systematically addresses these bottlenecks through three core innovations: (i) Ascend-affinity jagged acceleration, including fusion operators that eliminate padding redundancy and dynamic load balancing that reduces inter-device imbalance from 47\% to 2.4\%; (ii) distributed communication optimization, comprising hierarchical sparse parallelism, semi-asynchronous training with proven convergence guarantees, and fine-grained pipeline orchestration that sustains 94\% NPU utilization; and (iii) negative sampling optimization via asynchronous offloading, jaggedness-aware FP16 quantization, and intra-batch logit sharing that expand the effective negative space without additional embedding lookups. Evaluated on the KuaiRand-27K dataset, \model supports training at up to 0.2B parameters and achieves 54.71\% MFU with near-linear scalability (0.97).
NestPipe: Large-Scale Recommendation Training on 1,500+ Accelerators via Nested Pipelining
Apr 08, 2026Modern recommendation models have increased to trillions of parameters. As cluster scales expand to O(1k), distributed training bottlenecks shift from computation and memory to data movement, especially lookup and communication latency associated with embeddings. Existing solutions either optimize only one bottleneck or improve throughput by sacrificing training consistency. This paper presents NestPipe, a large-scale decentralized embedding training framework that tackles both bottlenecks while preserving synchronous training semantics. NestPipe exploits two hierarchical sparse parallelism opportunities through nested pipelining. At the inter-batch level, Dual-Buffer Pipelining (DBP) constructs a staleness-free five-stage pipeline through dual-buffer synchronization, mitigating lookup bottlenecks without embedding staleness. At the intra-batch level, we identify the embedding freezing phenomenon, which inspires Frozen-Window Pipelining (FWP) to overlap All2All communication with dense computation via coordinated stream scheduling and key-centric sample clustering. Experiments on production GPU and NPU clusters with 1,536 workers demonstrate that NestPipe achieves up to 3.06x speedup and 94.07% scaling efficiency.
Autonomous UAV Landing System Based on Visual Navigation
Oct 29, 2019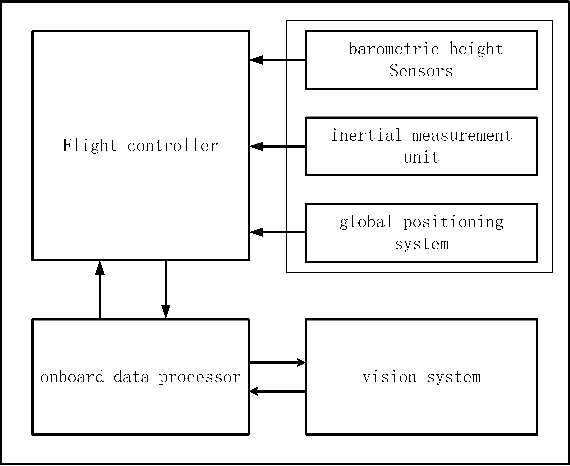

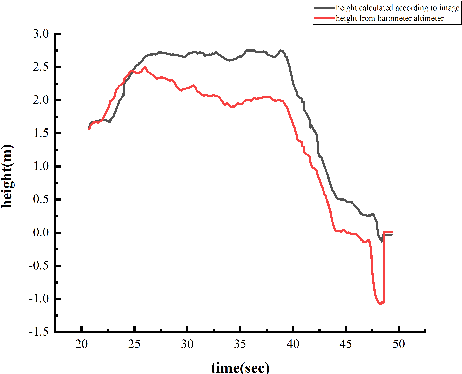
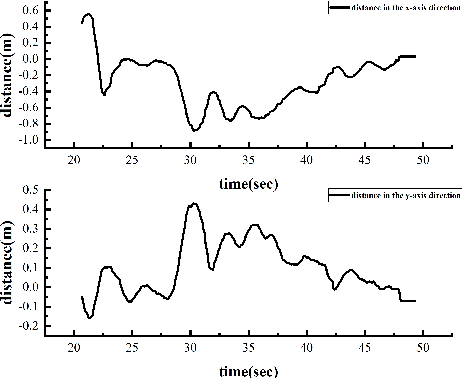
In this paper, we present an autonomous unmanned aerial vehicle (UAV) landing system based on visual navigation. We design the landmark as a topological pattern in order to enable the UAV to distinguish the landmark from the environment easily. In addition, a dynamic thresholding method is developed for image binarization to improve detection efficiency. The relative distance in the horizontal plane is calculated according to effective image information, and the relative height is obtained using a linear interpolation method. The landing experiments are performed on a static and a moving platform, respectively. The experimental results illustrate that our proposed landing system performs robustly and accurately.
Minimizing the Societal Cost of Credit Card Fraud with Limited and Imbalanced Data
Sep 05, 2019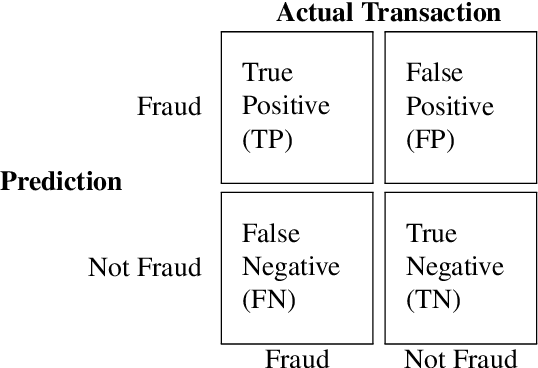
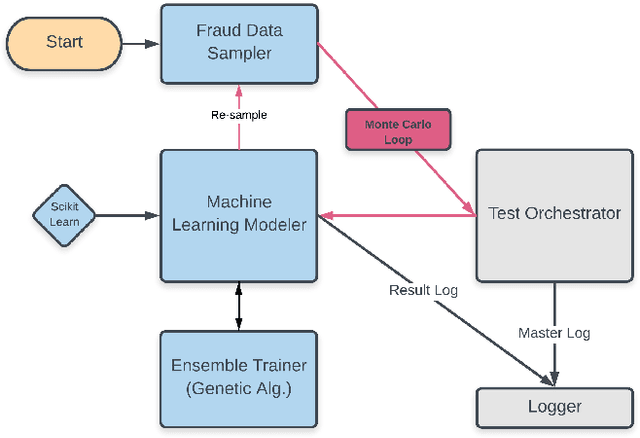
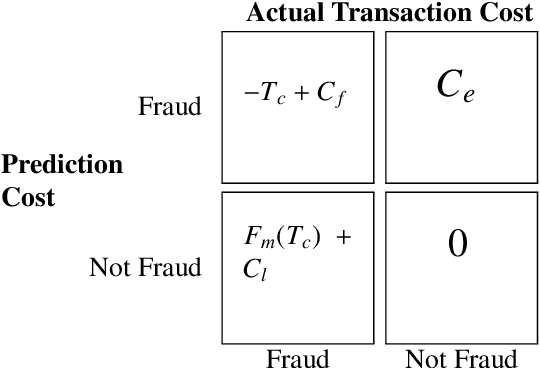
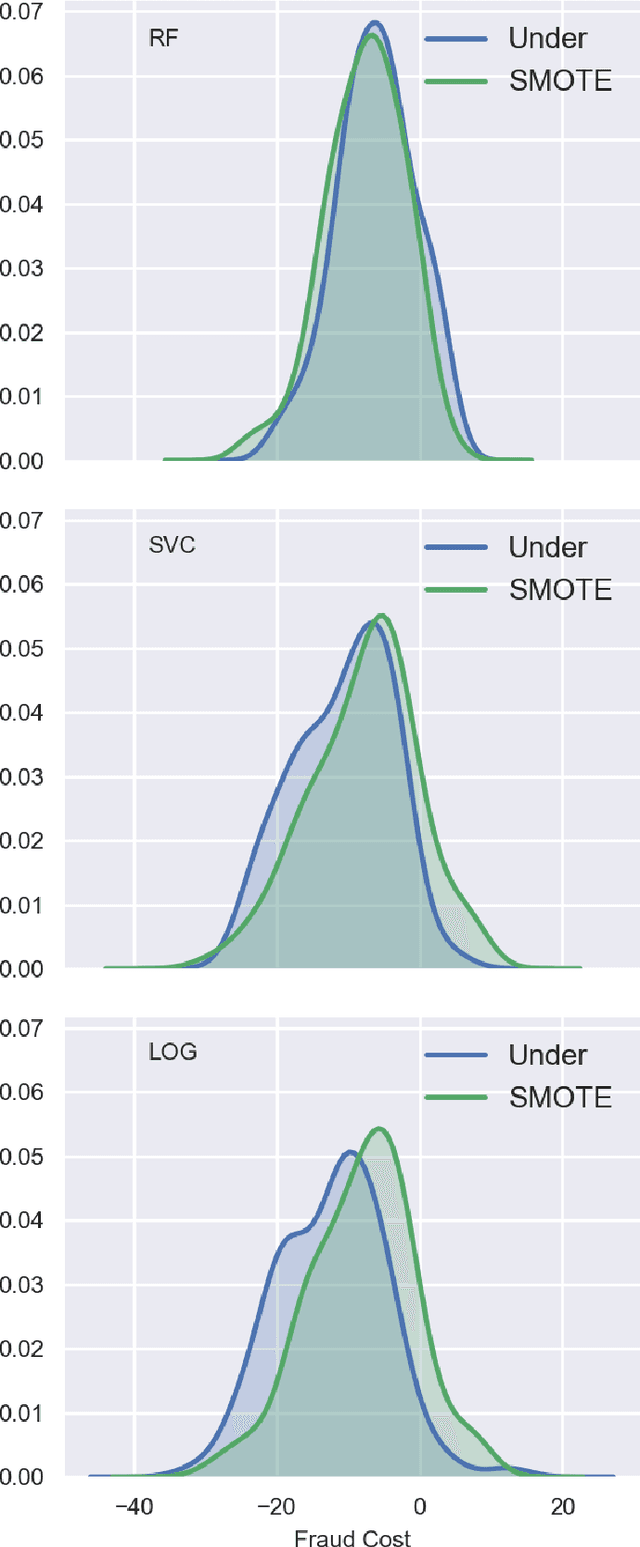
Machine learning has automated much of financial fraud detection, notifying firms of, or even blocking, questionable transactions instantly. However, data imbalance starves traditionally trained models of the content necessary to detect fraud. This study examines three separate factors of credit card fraud detection via machine learning. First, it assesses the potential for different sampling methods, undersampling and Synthetic Minority Oversampling Technique (SMOTE), to improve algorithm performance in data-starved environments. Additionally, five industry-practical machine learning algorithms are evaluated on total fraud cost savings in addition to traditional statistical metrics. Finally, an ensemble of individual models is trained with a genetic algorithm to attempt to generate higher cost efficiency than its components. Monte Carlo performance distributions discerned random undersampling outperformed SMOTE in lowering fraud costs, and that an ensemble was unable to outperform its individual parts. Most notably,the F-1 Score, a traditional metric often used to measure performance with imbalanced data, was uncorrelated with derived cost efficiency. Assuming a realistic cost structure can be derived, cost-based metrics provide an essential supplement to objective statistical evaluation.