 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeST-Prune: Training-Free Spatio-Temporal Token Pruning for Vision-Language Models in Autonomous Driving
Apr 21, 2026Vision-Language Models (VLMs) have become central to autonomous driving systems, yet their deployment is severely bottlenecked by the massive computational overhead of multi-view camera and multi-frame video input. Existing token pruning methods, primarily designed for single-image inputs, treat each frame or view in isolation and thus fail to exploit the inherent spatio-temporal redundancies in driving scenarios. To bridge this gap, we propose ST-Prune, a training-free, plug-and-play framework comprising two complementary modules: Motion-aware Temporal Pruning (MTP) and Ring-view Spatial Pruning (RSP). MTP addresses temporal redundancy by encoding motion volatility and temporal recency as soft constraints within the diversity selection objective, prioritizing dynamic trajectories and current-frame content over static historical background. RSP further resolves spatial redundancy by exploiting the ring-view camera geometry to penalize bilateral cross-view similarity, eliminating duplicate projections and residual background that temporal pruning alone cannot suppress. These two modules together constitute a complete spatio-temporal pruning process, preserving key scene information under strict compression. Validated across four benchmarks spanning perception, prediction, and planning, ST-Prune establishes new state-of-the-art for training-free token pruning. Notably, even at 90\% token reduction, ST-Prune achieves near-lossless performance with certain metrics surpassing the full-model baseline, while maintaining inference speeds comparable to existing pruning approaches.
DanceHA: A Multi-Agent Framework for Document-Level Aspect-Based Sentiment Analysis
Mar 17, 2026Aspect-Based Sentiment Intensity Analysis (ABSIA) has garnered increasing attention, though research largely focuses on domain-specific, sentence-level settings. In contrast, document-level ABSIA--particularly in addressing complex tasks like extracting Aspect-Category-Opinion-Sentiment-Intensity (ACOSI) tuples--remains underexplored. In this work, we introduce DanceHA, a multi-agent framework designed for open-ended, document-level ABSIA with informal writing styles. DanceHA has two main components: Dance, which employs a divide-and-conquer strategy to decompose the long-context ABSIA task into smaller, manageable sub-tasks for collaboration among specialized agents; and HA, Human-AI collaboration for annotation. We release Inf-ABSIA, a multi-domain document-level ABSIA dataset featuring fine-grained and high-accuracy labels from DanceHA. Extensive experiments demonstrate the effectiveness of our agentic framework and show that the multi-agent knowledge in DanceHA can be effectively transferred into student models. Our results highlight the importance of the overlooked informal styles in ABSIA, as they often intensify opinions tied to specific aspects.
Speech Emotion Recognition with Phonation Excitation Information and Articulatory Kinematics
Nov 11, 2025



Speech emotion recognition (SER) has advanced significantly for the sake of deep-learning methods, while textual information further enhances its performance. However, few studies have focused on the physiological information during speech production, which also encompasses speaker traits, including emotional states. To bridge this gap, we conducted a series of experiments to investigate the potential of the phonation excitation information and articulatory kinematics for SER. Due to the scarcity of training data for this purpose, we introduce a portrayed emotional dataset, STEM-E2VA, which includes audio and physiological data such as electroglottography (EGG) and electromagnetic articulography (EMA). EGG and EMA provide information of phonation excitation and articulatory kinematics, respectively. Additionally, we performed emotion recognition using estimated physiological data derived through inversion methods from speech, instead of collected EGG and EMA, to explore the feasibility of applying such physiological information in real-world SER. Experimental results confirm the effectiveness of incorporating physiological information about speech production for SER and demonstrate its potential for practical use in real-world scenarios.
Running-time Analysis of ($μ+λ$) Evolutionary Combinatorial Optimization Based on Multiple-gain Estimation
Jul 03, 2025The running-time analysis of evolutionary combinatorial optimization is a fundamental topic in evolutionary computation. However, theoretical results regarding the $(\mu+\lambda)$ evolutionary algorithm (EA) for combinatorial optimization problems remain relatively scarce compared to those for simple pseudo-Boolean problems. This paper proposes a multiple-gain model to analyze the running time of EAs for combinatorial optimization problems. The proposed model is an improved version of the average gain model, which is a fitness-difference drift approach under the sigma-algebra condition to estimate the running time of evolutionary numerical optimization. The improvement yields a framework for estimating the expected first hitting time of a stochastic process in both average-case and worst-case scenarios. It also introduces novel running-time results of evolutionary combinatorial optimization, including two tighter time complexity upper bounds than the known results in the case of ($\mu+\lambda$) EA for the knapsack problem with favorably correlated weights, a closed-form expression of time complexity upper bound in the case of ($\mu+\lambda$) EA for general $k$-MAX-SAT problems and a tighter time complexity upper bounds than the known results in the case of ($\mu+\lambda$) EA for the traveling salesperson problem. Experimental results indicate that the practical running time aligns with the theoretical results, verifying that the multiple-gain model is an effective tool for running-time analysis of ($\mu+\lambda$) EA for combinatorial optimization problems.
Multiple-gain Estimation for Running Time of Evolutionary Combinatorial Optimization
Jan 13, 2025



The running-time analysis of evolutionary combinatorial optimization is a fundamental topic in evolutionary computation. Its current research mainly focuses on specific algorithms for simplified problems due to the challenge posed by fluctuating fitness values. This paper proposes a multiple-gain model to estimate the fitness trend of population during iterations. The proposed model is an improved version of the average gain model, which is the approach to estimate the running time of evolutionary algorithms for numerical optimization. The improvement yields novel results of evolutionary combinatorial optimization, including a briefer proof for the time complexity upper bound in the case of (1+1) EA for the Onemax problem, two tighter time complexity upper bounds than the known results in the case of (1+$\lambda$) EA for the knapsack problem with favorably correlated weights and a closed-form expression of time complexity upper bound in the case of (1+$\lambda$) EA for general $k$-MAX-SAT problems. The results indicate that the practical running time aligns with the theoretical results, verifying that the multiple-gain model is more general for running-time analysis of evolutionary combinatorial optimization than state-of-the-art methods.
Federated Domain Generalization: A Survey
Jun 02, 2023



Machine learning typically relies on the assumption that training and testing distributions are identical and that data is centrally stored for training and testing. However, in real-world scenarios, distributions may differ significantly and data is often distributed across different devices, organizations, or edge nodes. Consequently, it is imperative to develop models that can effectively generalize to unseen distributions where data is distributed across different domains. In response to this challenge, there has been a surge of interest in federated domain generalization (FDG) in recent years. FDG combines the strengths of federated learning (FL) and domain generalization (DG) techniques to enable multiple source domains to collaboratively learn a model capable of directly generalizing to unseen domains while preserving data privacy. However, generalizing the federated model under domain shifts is a technically challenging problem that has received scant attention in the research area so far. This paper presents the first survey of recent advances in this area. Initially, we discuss the development process from traditional machine learning to domain adaptation and domain generalization, leading to FDG as well as provide the corresponding formal definition. Then, we categorize recent methodologies into four classes: federated domain alignment, data manipulation, learning strategies, and aggregation optimization, and present suitable algorithms in detail for each category. Next, we introduce commonly used datasets, applications, evaluations, and benchmarks. Finally, we conclude this survey by providing some potential research topics for the future.
Ins-ATP: Deep Estimation of ATP for Organoid Based on High Throughput Microscopic Images
Mar 15, 2023



Adenosine triphosphate (ATP) is a high-energy phosphate compound and the most direct energy source in organisms. ATP is an essential biomarker for evaluating cell viability in biology. Researchers often use ATP bioluminescence to measure the ATP of organoid after drug to evaluate the drug efficacy. However, ATP bioluminescence has some limitations, leading to unreliable drug screening results. Performing ATP bioluminescence causes cell lysis of organoids, so it is impossible to observe organoids' long-term viability changes after medication continually. To overcome the disadvantages of ATP bioluminescence, we propose Ins-ATP, a non-invasive strategy, the first organoid ATP estimation model based on the high-throughput microscopic image. Ins-ATP directly estimates the ATP of organoids from high-throughput microscopic images, so that it does not influence the drug reactions of organoids. Therefore, the ATP change of organoids can be observed for a long time to obtain more stable results. Experimental results show that the ATP estimation by Ins-ATP is in good agreement with those determined by ATP bioluminescence. Specifically, the predictions of Ins-ATP are consistent with the results measured by ATP bioluminescence in the efficacy evaluation experiments of different drugs.
Deep Learning-based Multi-Organ CT Segmentation with Adversarial Data Augmentation
Feb 25, 2023In this work, we propose an adversarial attack-based data augmentation method to improve the deep-learning-based segmentation algorithm for the delineation of Organs-At-Risk (OAR) in abdominal Computed Tomography (CT) to facilitate radiation therapy. We introduce Adversarial Feature Attack for Medical Image (AFA-MI) augmentation, which forces the segmentation network to learn out-of-distribution statistics and improve generalization and robustness to noises. AFA-MI augmentation consists of three steps: 1) generate adversarial noises by Fast Gradient Sign Method (FGSM) on the intermediate features of the segmentation network's encoder; 2) inject the generated adversarial noises into the network, intentionally compromising performance; 3) optimize the network with both clean and adversarial features. Experiments are conducted segmenting the heart, left and right kidney, liver, left and right lung, spinal cord, and stomach. We first evaluate the AFA-MI augmentation using nnUnet and TT-Vnet on the test data from a public abdominal dataset and an institutional dataset. In addition, we validate how AFA-MI affects the networks' robustness to the noisy data by evaluating the networks with added Gaussian noises of varying magnitudes to the institutional dataset. Network performance is quantitatively evaluated using Dice Similarity Coefficient (DSC) for volume-based accuracy. Also, Hausdorff Distance (HD) is applied for surface-based accuracy. On the public dataset, nnUnet with AFA-MI achieves DSC = 0.85 and HD = 6.16 millimeters (mm); and TT-Vnet achieves DSC = 0.86 and HD = 5.62 mm. AFA-MI augmentation further improves all contour accuracies up to 0.217 DSC score when tested on images with Gaussian noises. AFA-MI augmentation is therefore demonstrated to improve segmentation performance and robustness in CT multi-organ segmentation.
How to Simplify Search: Classification-wise Pareto Evolution for One-shot Neural Architecture Search
Sep 14, 2021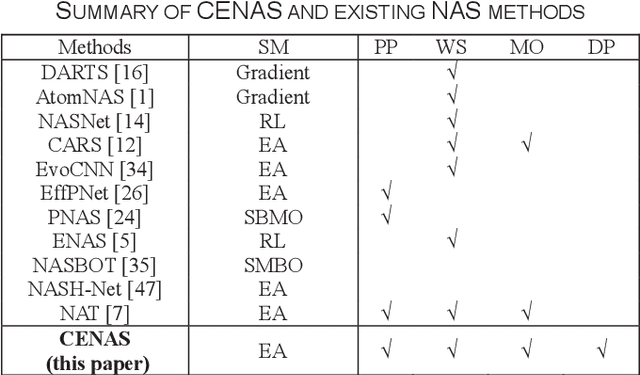
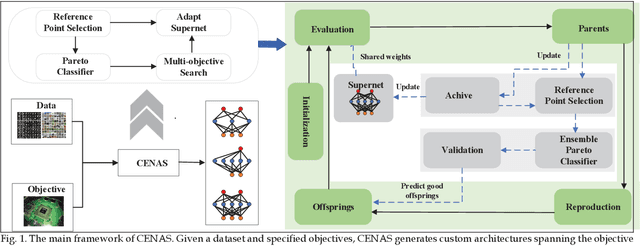
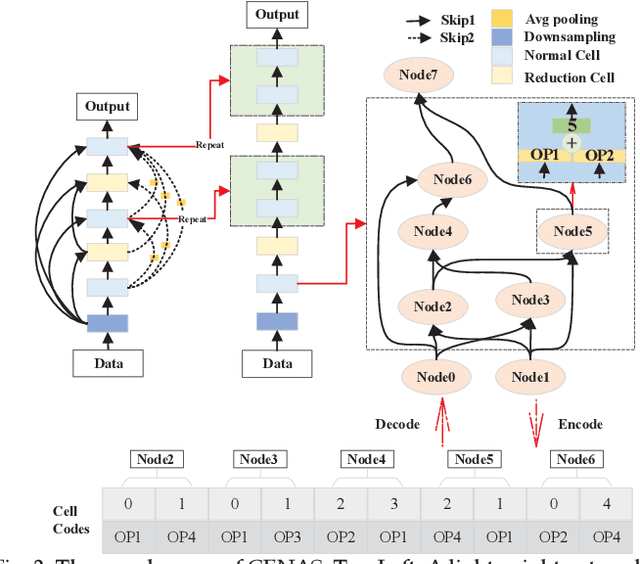
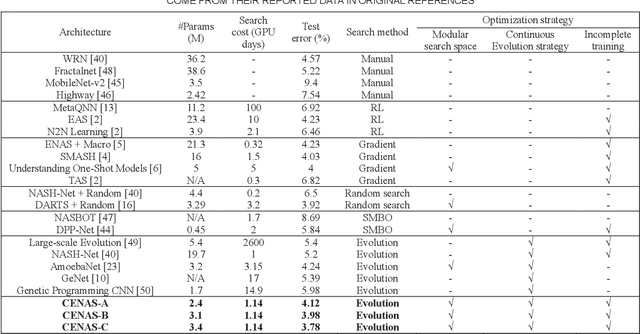
In the deployment of deep neural models, how to effectively and automatically find feasible deep models under diverse design objectives is fundamental. Most existing neural architecture search (NAS) methods utilize surrogates to predict the detailed performance (e.g., accuracy and model size) of a candidate architecture during the search, which however is complicated and inefficient. In contrast, we aim to learn an efficient Pareto classifier to simplify the search process of NAS by transforming the complex multi-objective NAS task into a simple Pareto-dominance classification task. To this end, we propose a classification-wise Pareto evolution approach for one-shot NAS, where an online classifier is trained to predict the dominance relationship between the candidate and constructed reference architectures, instead of using surrogates to fit the objective functions. The main contribution of this study is to change supernet adaption into a Pareto classifier. Besides, we design two adaptive schemes to select the reference set of architectures for constructing classification boundary and regulate the rate of positive samples over negative ones, respectively. We compare the proposed evolution approach with state-of-the-art approaches on widely-used benchmark datasets, and experimental results indicate that the proposed approach outperforms other approaches and have found a number of neural architectures with different model sizes ranging from 2M to 6M under diverse objectives and constraints.
Data Poisoning Attacks on Neighborhood-based Recommender Systems
Dec 01, 2019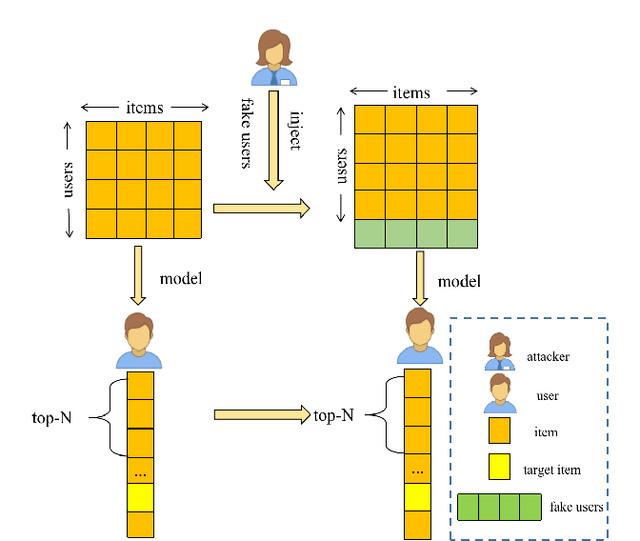
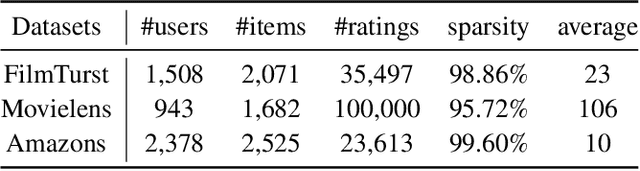

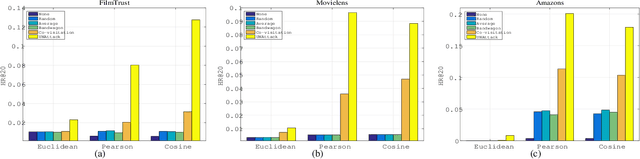
Nowadays, collaborative filtering recommender systems have been widely deployed in many commercial companies to make profit. Neighbourhood-based collaborative filtering is common and effective. To date, despite its effectiveness, there has been little effort to explore their robustness and the impact of data poisoning attacks on their performance. Can the neighbourhood-based recommender systems be easily fooled? To this end, we shed light on the robustness of neighbourhood-based recommender systems and propose a novel data poisoning attack framework encoding the purpose of attack and constraint against them. We firstly illustrate how to calculate the optimal data poisoning attack, namely UNAttack. We inject a few well-designed fake users into the recommender systems such that target items will be recommended to as many normal users as possible. Extensive experiments are conducted on three real-world datasets to validate the effectiveness and the transferability of our proposed method. Besides, some interesting phenomenons can be found. For example, 1) neighbourhood-based recommender systems with Euclidean Distance-based similarity have strong robustness. 2) the fake users can be transferred to attack the state-of-the-art collaborative filtering recommender systems such as Neural Collaborative Filtering and Bayesian Personalized Ranking Matrix Factorization.