 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Speaker Features Learning for Audio-visual Multichannel Speech Separation and Recognition
Jun 14, 2024



This paper proposes joint speaker feature learning methods for zero-shot adaptation of audio-visual multichannel speech separation and recognition systems. xVector and ECAPA-TDNN speaker encoders are connected using purpose-built fusion blocks and tightly integrated with the complete system training. Experiments conducted on LRS3-TED data simulated multichannel overlapped speech suggest that joint speaker feature learning consistently improves speech separation and recognition performance over the baselines without joint speaker feature estimation. Further analyses reveal performance improvements are strongly correlated with increased inter-speaker discrimination measured using cosine similarity. The best-performing joint speaker feature learning adapted system outperformed the baseline fine-tuned WavLM model by statistically significant WER reductions of 21.6% and 25.3% absolute (67.5% and 83.5% relative) on Dev and Test sets after incorporating WavLM features and video modality.
An Initial Investigation of Language Adaptation for TTS Systems under Low-resource Scenarios
Jun 13, 2024Self-supervised learning (SSL) representations from massively multilingual models offer a promising solution for low-resource language speech tasks. Despite advancements, language adaptation in TTS systems remains an open problem. This paper explores the language adaptation capability of ZMM-TTS, a recent SSL-based multilingual TTS system proposed in our previous work. We conducted experiments on 12 languages using limited data with various fine-tuning configurations. We demonstrate that the similarity in phonetics between the pre-training and target languages, as well as the language category, affects the target language's adaptation performance. Additionally, we find that the fine-tuning dataset size and number of speakers influence adaptability. Surprisingly, we also observed that using paired data for fine-tuning is not always optimal compared to audio-only data. Beyond speech intelligibility, our analysis covers speaker similarity, language identification, and predicted MOS.
Enhancing Pre-trained ASR System Fine-tuning for Dysarthric Speech Recognition using Adversarial Data Augmentation
Jan 01, 2024


Automatic recognition of dysarthric speech remains a highly challenging task to date. Neuro-motor conditions and co-occurring physical disabilities create difficulty in large-scale data collection for ASR system development. Adapting SSL pre-trained ASR models to limited dysarthric speech via data-intensive parameter fine-tuning leads to poor generalization. To this end, this paper presents an extensive comparative study of various data augmentation approaches to improve the robustness of pre-trained ASR model fine-tuning to dysarthric speech. These include: a) conventional speaker-independent perturbation of impaired speech; b) speaker-dependent speed perturbation, or GAN-based adversarial perturbation of normal, control speech based on their time alignment against parallel dysarthric speech; c) novel Spectral basis GAN-based adversarial data augmentation operating on non-parallel data. Experiments conducted on the UASpeech corpus suggest GAN-based data augmentation consistently outperforms fine-tuned Wav2vec2.0 and HuBERT models using no data augmentation and speed perturbation across different data expansion operating points by statistically significant word error rate (WER) reductions up to 2.01% and 0.96% absolute (9.03% and 4.63% relative) respectively on the UASpeech test set of 16 dysarthric speakers. After cross-system outputs rescoring, the best system produced the lowest published WER of 16.53% (46.47% on very low intelligibility) on UASpeech.
A Survey of Reasoning with Foundation Models
Dec 26, 2023



Reasoning, a crucial ability for complex problem-solving, plays a pivotal role in various real-world settings such as negotiation, medical diagnosis, and criminal investigation. It serves as a fundamental methodology in the field of Artificial General Intelligence (AGI). With the ongoing development of foundation models, there is a growing interest in exploring their abilities in reasoning tasks. In this paper, we introduce seminal foundation models proposed or adaptable for reasoning, highlighting the latest advancements in various reasoning tasks, methods, and benchmarks. We then delve into the potential future directions behind the emergence of reasoning abilities within foundation models. We also discuss the relevance of multimodal learning, autonomous agents, and super alignment in the context of reasoning. By discussing these future research directions, we hope to inspire researchers in their exploration of this field, stimulate further advancements in reasoning with foundation models, and contribute to the development of AGI.
Towards Automatic Data Augmentation for Disordered Speech Recognition
Dec 14, 2023Automatic recognition of disordered speech remains a highly challenging task to date due to data scarcity. This paper presents a reinforcement learning (RL) based on-the-fly data augmentation approach for training state-of-the-art PyChain TDNN and end-to-end Conformer ASR systems on such data. The handcrafted temporal and spectral mask operations in the standard SpecAugment method that are task and system dependent, together with additionally introduced minimum and maximum cut-offs of these time-frequency masks, are now automatically learned using an RNN-based policy controller and tightly integrated with ASR system training. Experiments on the UASpeech corpus suggest the proposed RL-based data augmentation approach consistently produced performance superior or comparable that obtained using expert or handcrafted SpecAugment policies. Our RL auto-augmented PyChain TDNN system produced an overall WER of 28.79% on the UASpeech test set of 16 dysarthric speakers.
Audio-visual End-to-end Multi-channel Speech Separation, Dereverberation and Recognition
Jul 06, 2023



Accurate recognition of cocktail party speech containing overlapping speakers, noise and reverberation remains a highly challenging task to date. Motivated by the invariance of visual modality to acoustic signal corruption, an audio-visual multi-channel speech separation, dereverberation and recognition approach featuring a full incorporation of visual information into all system components is proposed in this paper. The efficacy of the video input is consistently demonstrated in mask-based MVDR speech separation, DNN-WPE or spectral mapping (SpecM) based speech dereverberation front-end and Conformer ASR back-end. Audio-visual integrated front-end architectures performing speech separation and dereverberation in a pipelined or joint fashion via mask-based WPD are investigated. The error cost mismatch between the speech enhancement front-end and ASR back-end components is minimized by end-to-end jointly fine-tuning using either the ASR cost function alone, or its interpolation with the speech enhancement loss. Experiments were conducted on the mixture overlapped and reverberant speech data constructed using simulation or replay of the Oxford LRS2 dataset. The proposed audio-visual multi-channel speech separation, dereverberation and recognition systems consistently outperformed the comparable audio-only baseline by 9.1% and 6.2% absolute (41.7% and 36.0% relative) word error rate (WER) reductions. Consistent speech enhancement improvements were also obtained on PESQ, STOI and SRMR scores.
Hyper-parameter Adaptation of Conformer ASR Systems for Elderly and Dysarthric Speech Recognition
Jun 27, 2023Automatic recognition of disordered and elderly speech remains highly challenging tasks to date due to data scarcity. Parameter fine-tuning is often used to exploit the large quantities of non-aged and healthy speech pre-trained models, while neural architecture hyper-parameters are set using expert knowledge and remain unchanged. This paper investigates hyper-parameter adaptation for Conformer ASR systems that are pre-trained on the Librispeech corpus before being domain adapted to the DementiaBank elderly and UASpeech dysarthric speech datasets. Experimental results suggest that hyper-parameter adaptation produced word error rate (WER) reductions of 0.45% and 0.67% over parameter-only fine-tuning on DBank and UASpeech tasks respectively. An intuitive correlation is found between the performance improvements by hyper-parameter domain adaptation and the relative utterance length ratio between the source and target domain data.
Factorised Speaker-environment Adaptive Training of Conformer Speech Recognition Systems
Jun 26, 2023



Rich sources of variability in natural speech present significant challenges to current data intensive speech recognition technologies. To model both speaker and environment level diversity, this paper proposes a novel Bayesian factorised speaker-environment adaptive training and test time adaptation approach for Conformer ASR models. Speaker and environment level characteristics are separately modeled using compact hidden output transforms, which are then linearly or hierarchically combined to represent any speaker-environment combination. Bayesian learning is further utilized to model the adaptation parameter uncertainty. Experiments on the 300-hr WHAM noise corrupted Switchboard data suggest that factorised adaptation consistently outperforms the baseline and speaker label only adapted Conformers by up to 3.1% absolute (10.4% relative) word error rate reductions. Further analysis shows the proposed method offers potential for rapid adaption to unseen speaker-environment conditions.
Use of Speech Impairment Severity for Dysarthric Speech Recognition
May 18, 2023A key challenge in dysarthric speech recognition is the speaker-level diversity attributed to both speaker-identity associated factors such as gender, and speech impairment severity. Most prior researches on addressing this issue focused on using speaker-identity only. To this end, this paper proposes a novel set of techniques to use both severity and speaker-identity in dysarthric speech recognition: a) multitask training incorporating severity prediction error; b) speaker-severity aware auxiliary feature adaptation; and c) structured LHUC transforms separately conditioned on speaker-identity and severity. Experiments conducted on UASpeech suggest incorporating additional speech impairment severity into state-of-the-art hybrid DNN, E2E Conformer and pre-trained Wav2vec 2.0 ASR systems produced statistically significant WER reductions up to 4.78% (14.03% relative). Using the best system the lowest published WER of 17.82% (51.25% on very low intelligibility) was obtained on UASpeech.
Exploring Self-supervised Pre-trained ASR Models For Dysarthric and Elderly Speech Recognition
Feb 28, 2023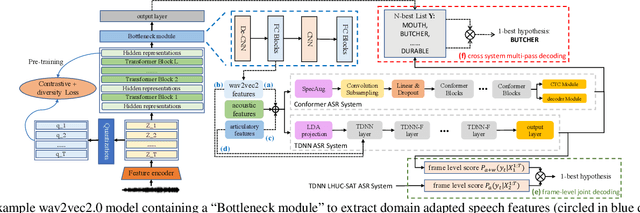
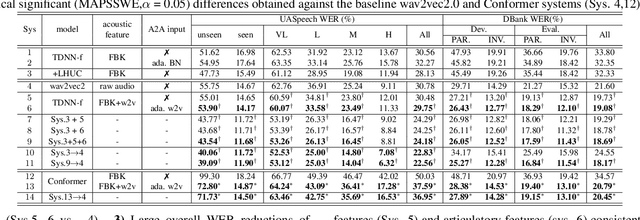


Automatic recognition of disordered and elderly speech remains a highly challenging task to date due to the difficulty in collecting such data in large quantities. This paper explores a series of approaches to integrate domain adapted SSL pre-trained models into TDNN and Conformer ASR systems for dysarthric and elderly speech recognition: a) input feature fusion between standard acoustic frontends and domain adapted wav2vec2.0 speech representations; b) frame-level joint decoding of TDNN systems separately trained using standard acoustic features alone and with additional wav2vec2.0 features; and c) multi-pass decoding involving the TDNN/Conformer system outputs to be rescored using domain adapted wav2vec2.0 models. In addition, domain adapted wav2vec2.0 representations are utilized in acoustic-to-articulatory (A2A) inversion to construct multi-modal dysarthric and elderly speech recognition systems. Experiments conducted on the UASpeech dysarthric and DementiaBank Pitt elderly speech corpora suggest TDNN and Conformer ASR systems integrated domain adapted wav2vec2.0 models consistently outperform the standalone wav2vec2.0 models by statistically significant WER reductions of 8.22% and 3.43% absolute (26.71% and 15.88% relative) on the two tasks respectively. The lowest published WERs of 22.56% (52.53% on very low intelligibility, 39.09% on unseen words) and 18.17% are obtained on the UASpeech test set of 16 dysarthric speakers, and the DementiaBank Pitt test set respectively.