 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning of 3D Structure from Images
Jun 19, 2018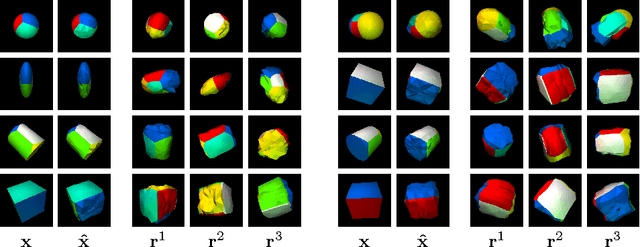
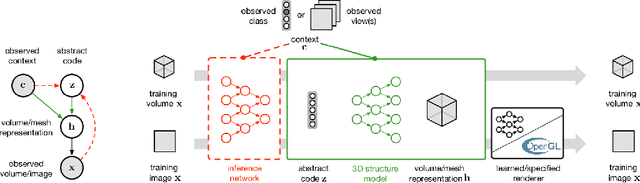


A key goal of computer vision is to recover the underlying 3D structure from 2D observations of the world. In this paper we learn strong deep generative models of 3D structures, and recover these structures from 3D and 2D images via probabilistic inference. We demonstrate high-quality samples and report log-likelihoods on several datasets, including ShapeNet [2], and establish the first benchmarks in the literature. We also show how these models and their inference networks can be trained end-to-end from 2D images. This demonstrates for the first time the feasibility of learning to infer 3D representations of the world in a purely unsupervised manner.
Mix&Match - Agent Curricula for Reinforcement Learning
Jun 05, 2018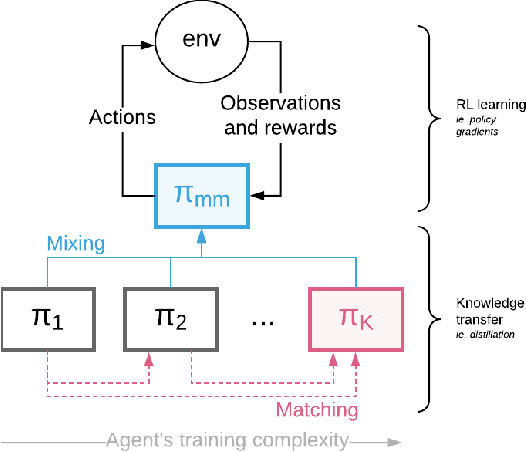
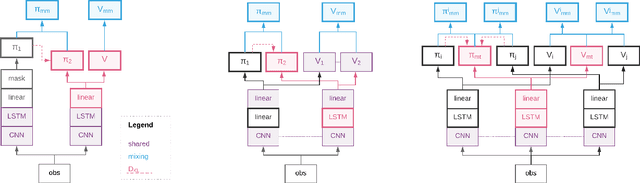
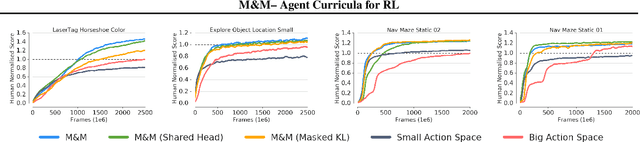
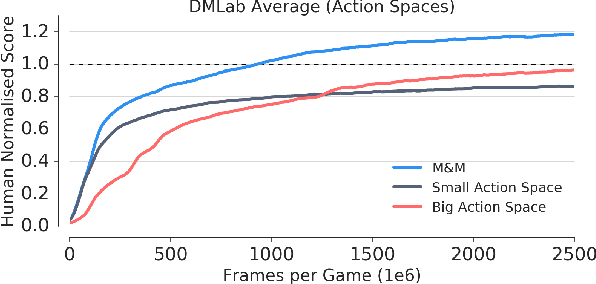
We introduce Mix&Match (M&M) - a training framework designed to facilitate rapid and effective learning in RL agents, especially those that would be too slow or too challenging to train otherwise. The key innovation is a procedure that allows us to automatically form a curriculum over agents. Through such a curriculum we can progressively train more complex agents by, effectively, bootstrapping from solutions found by simpler agents. In contradistinction to typical curriculum learning approaches, we do not gradually modify the tasks or environments presented, but instead use a process to gradually alter how the policy is represented internally. We show the broad applicability of our method by demonstrating significant performance gains in three different experimental setups: (1) We train an agent able to control more than 700 actions in a challenging 3D first-person task; using our method to progress through an action-space curriculum we achieve both faster training and better final performance than one obtains using traditional methods. (2) We further show that M&M can be used successfully to progress through a curriculum of architectural variants defining an agents internal state. (3) Finally, we illustrate how a variant of our method can be used to improve agent performance in a multitask setting.
Population Based Training of Neural Networks
Nov 28, 2017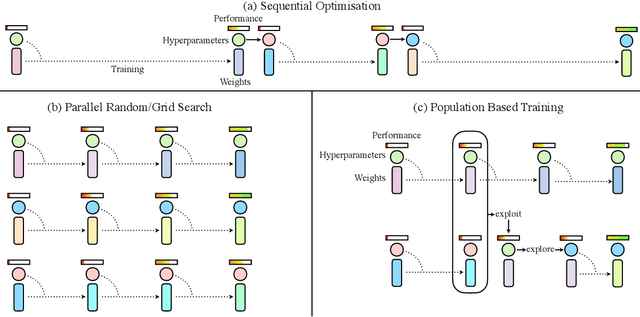

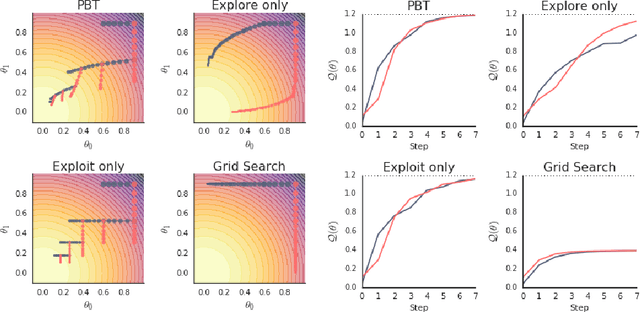
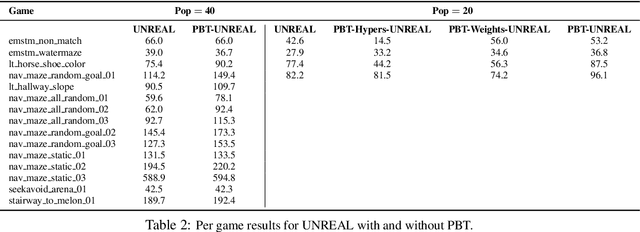
Neural networks dominate the modern machine learning landscape, but their training and success still suffer from sensitivity to empirical choices of hyperparameters such as model architecture, loss function, and optimisation algorithm. In this work we present \emph{Population Based Training (PBT)}, a simple asynchronous optimisation algorithm which effectively utilises a fixed computational budget to jointly optimise a population of models and their hyperparameters to maximise performance. Importantly, PBT discovers a schedule of hyperparameter settings rather than following the generally sub-optimal strategy of trying to find a single fixed set to use for the whole course of training. With just a small modification to a typical distributed hyperparameter training framework, our method allows robust and reliable training of models. We demonstrate the effectiveness of PBT on deep reinforcement learning problems, showing faster wall-clock convergence and higher final performance of agents by optimising over a suite of hyperparameters. In addition, we show the same method can be applied to supervised learning for machine translation, where PBT is used to maximise the BLEU score directly, and also to training of Generative Adversarial Networks to maximise the Inception score of generated images. In all cases PBT results in the automatic discovery of hyperparameter schedules and model selection which results in stable training and better final performance.
Sobolev Training for Neural Networks
Jul 26, 2017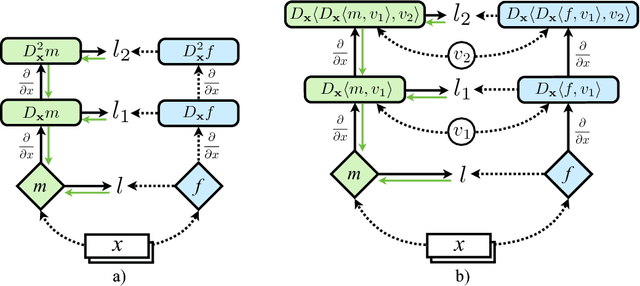
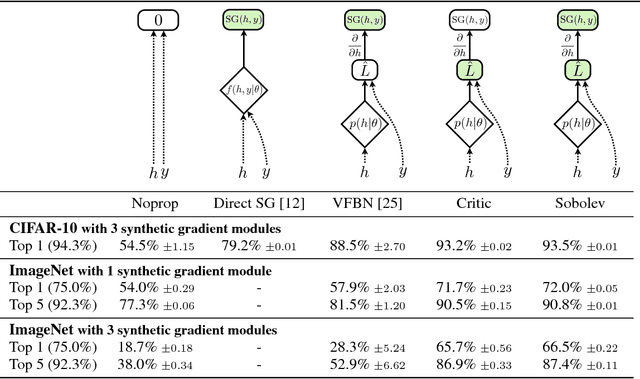
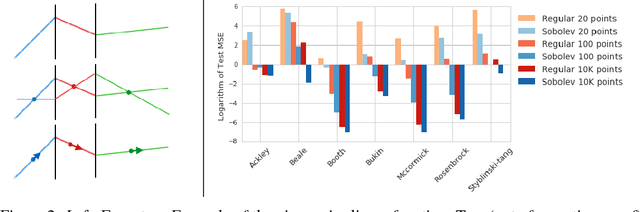
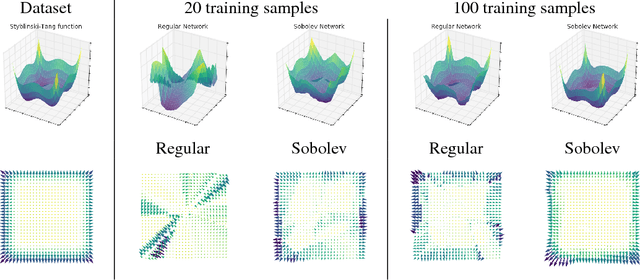
At the heart of deep learning we aim to use neural networks as function approximators - training them to produce outputs from inputs in emulation of a ground truth function or data creation process. In many cases we only have access to input-output pairs from the ground truth, however it is becoming more common to have access to derivatives of the target output with respect to the input - for example when the ground truth function is itself a neural network such as in network compression or distillation. Generally these target derivatives are not computed, or are ignored. This paper introduces Sobolev Training for neural networks, which is a method for incorporating these target derivatives in addition the to target values while training. By optimising neural networks to not only approximate the function's outputs but also the function's derivatives we encode additional information about the target function within the parameters of the neural network. Thereby we can improve the quality of our predictors, as well as the data-efficiency and generalization capabilities of our learned function approximation. We provide theoretical justifications for such an approach as well as examples of empirical evidence on three distinct domains: regression on classical optimisation datasets, distilling policies of an agent playing Atari, and on large-scale applications of synthetic gradients. In all three domains the use of Sobolev Training, employing target derivatives in addition to target values, results in models with higher accuracy and stronger generalisation.
Decoupled Neural Interfaces using Synthetic Gradients
Jul 03, 2017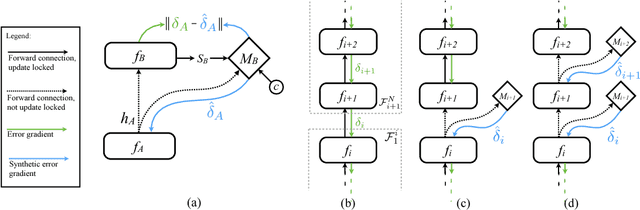
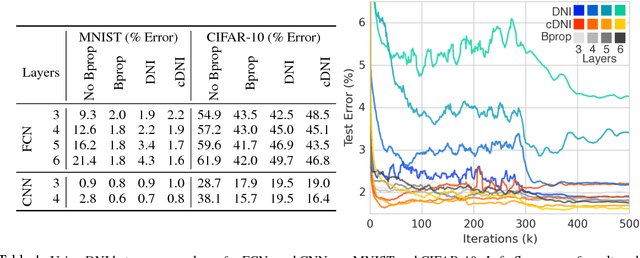
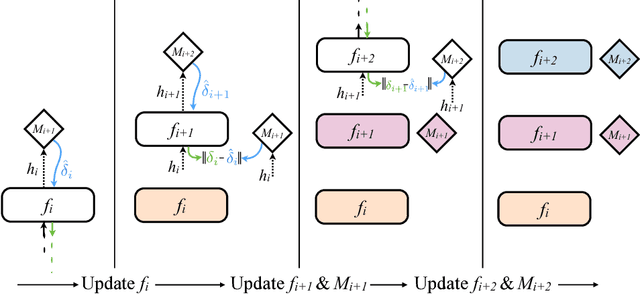

Training directed neural networks typically requires forward-propagating data through a computation graph, followed by backpropagating error signal, to produce weight updates. All layers, or more generally, modules, of the network are therefore locked, in the sense that they must wait for the remainder of the network to execute forwards and propagate error backwards before they can be updated. In this work we break this constraint by decoupling modules by introducing a model of the future computation of the network graph. These models predict what the result of the modelled subgraph will produce using only local information. In particular we focus on modelling error gradients: by using the modelled synthetic gradient in place of true backpropagated error gradients we decouple subgraphs, and can update them independently and asynchronously i.e. we realise decoupled neural interfaces. We show results for feed-forward models, where every layer is trained asynchronously, recurrent neural networks (RNNs) where predicting one's future gradient extends the time over which the RNN can effectively model, and also a hierarchical RNN system with ticking at different timescales. Finally, we demonstrate that in addition to predicting gradients, the same framework can be used to predict inputs, resulting in models which are decoupled in both the forward and backwards pass -- amounting to independent networks which co-learn such that they can be composed into a single functioning corporation.
Grounded Language Learning in a Simulated 3D World
Jun 26, 2017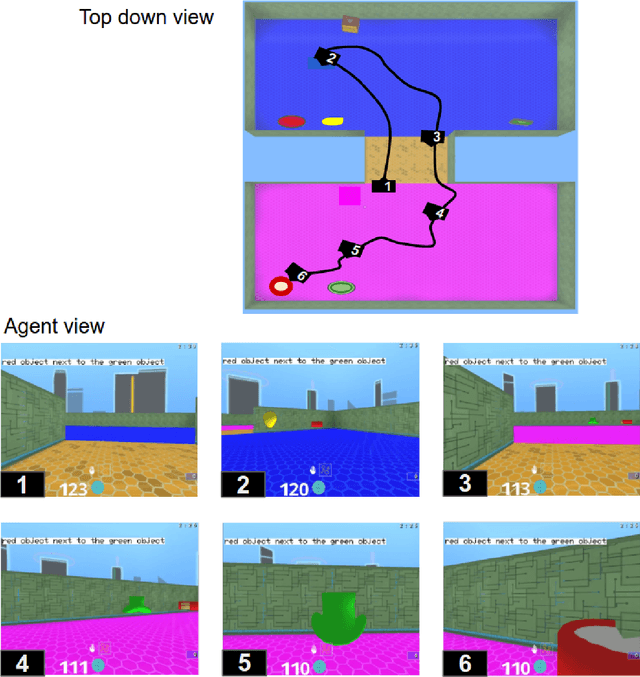

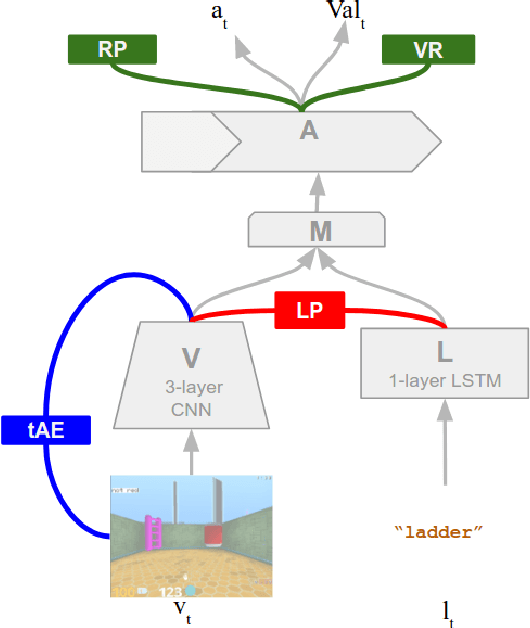
We are increasingly surrounded by artificially intelligent technology that takes decisions and executes actions on our behalf. This creates a pressing need for general means to communicate with, instruct and guide artificial agents, with human language the most compelling means for such communication. To achieve this in a scalable fashion, agents must be able to relate language to the world and to actions; that is, their understanding of language must be grounded and embodied. However, learning grounded language is a notoriously challenging problem in artificial intelligence research. Here we present an agent that learns to interpret language in a simulated 3D environment where it is rewarded for the successful execution of written instructions. Trained via a combination of reinforcement and unsupervised learning, and beginning with minimal prior knowledge, the agent learns to relate linguistic symbols to emergent perceptual representations of its physical surroundings and to pertinent sequences of actions. The agent's comprehension of language extends beyond its prior experience, enabling it to apply familiar language to unfamiliar situations and to interpret entirely novel instructions. Moreover, the speed with which this agent learns new words increases as its semantic knowledge grows. This facility for generalising and bootstrapping semantic knowledge indicates the potential of the present approach for reconciling ambiguous natural language with the complexity of the physical world.
Value-Decomposition Networks For Cooperative Multi-Agent Learning
Jun 16, 2017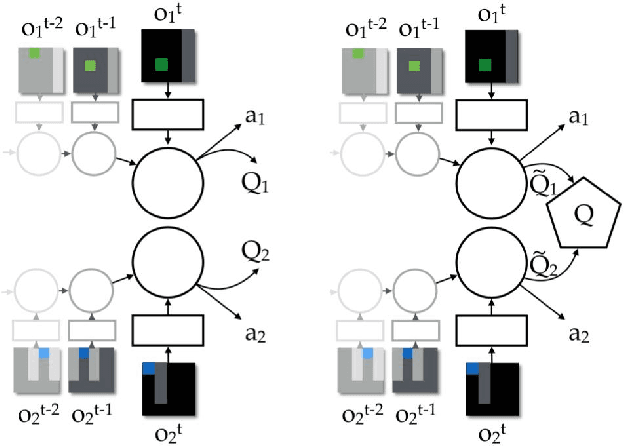
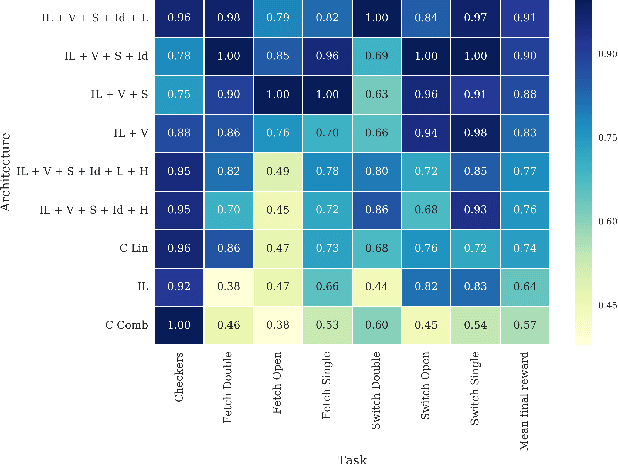
We study the problem of cooperative multi-agent reinforcement learning with a single joint reward signal. This class of learning problems is difficult because of the often large combined action and observation spaces. In the fully centralized and decentralized approaches, we find the problem of spurious rewards and a phenomenon we call the "lazy agent" problem, which arises due to partial observability. We address these problems by training individual agents with a novel value decomposition network architecture, which learns to decompose the team value function into agent-wise value functions. We perform an experimental evaluation across a range of partially-observable multi-agent domains and show that learning such value-decompositions leads to superior results, in particular when combined with weight sharing, role information and information channels.
FeUdal Networks for Hierarchical Reinforcement Learning
Mar 06, 2017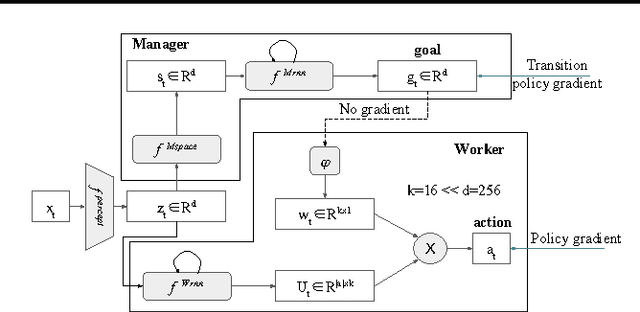
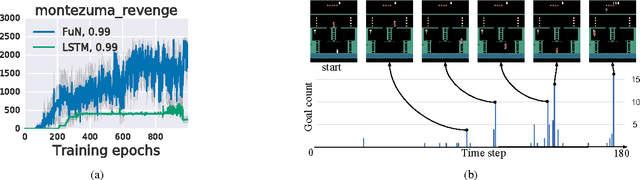

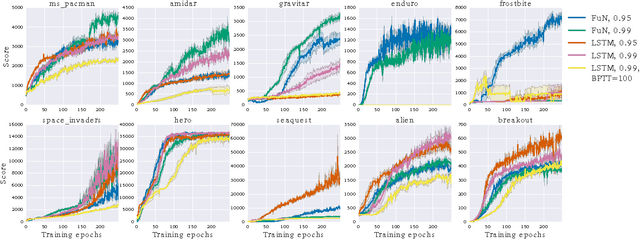
We introduce FeUdal Networks (FuNs): a novel architecture for hierarchical reinforcement learning. Our approach is inspired by the feudal reinforcement learning proposal of Dayan and Hinton, and gains power and efficacy by decoupling end-to-end learning across multiple levels -- allowing it to utilise different resolutions of time. Our framework employs a Manager module and a Worker module. The Manager operates at a lower temporal resolution and sets abstract goals which are conveyed to and enacted by the Worker. The Worker generates primitive actions at every tick of the environment. The decoupled structure of FuN conveys several benefits -- in addition to facilitating very long timescale credit assignment it also encourages the emergence of sub-policies associated with different goals set by the Manager. These properties allow FuN to dramatically outperform a strong baseline agent on tasks that involve long-term credit assignment or memorisation. We demonstrate the performance of our proposed system on a range of tasks from the ATARI suite and also from a 3D DeepMind Lab environment.
Understanding Synthetic Gradients and Decoupled Neural Interfaces
Mar 01, 2017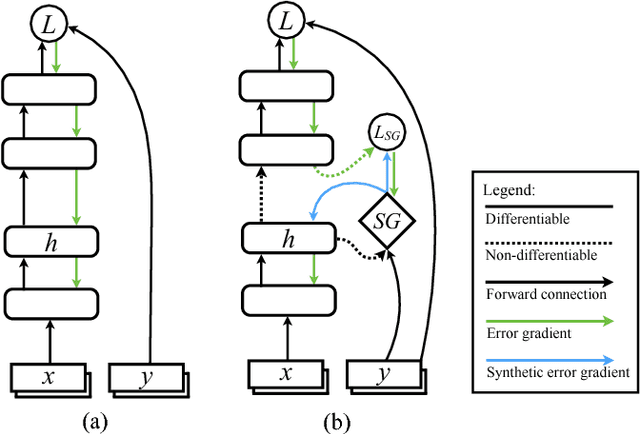
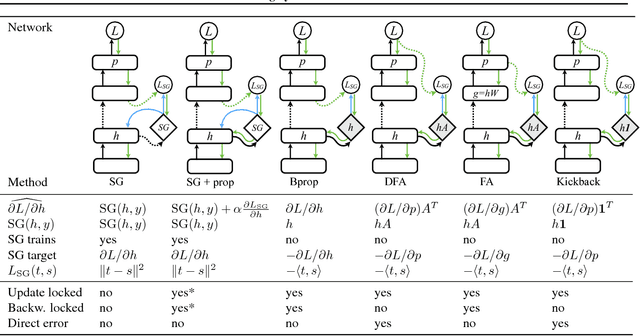
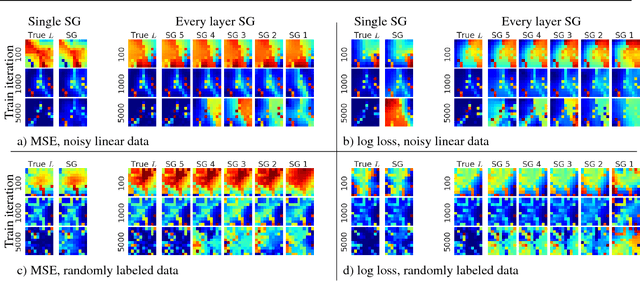
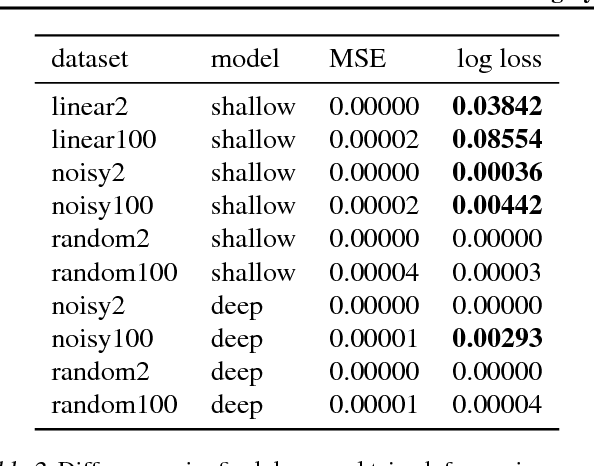
When training neural networks, the use of Synthetic Gradients (SG) allows layers or modules to be trained without update locking - without waiting for a true error gradient to be backpropagated - resulting in Decoupled Neural Interfaces (DNIs). This unlocked ability of being able to update parts of a neural network asynchronously and with only local information was demonstrated to work empirically in Jaderberg et al (2016). However, there has been very little demonstration of what changes DNIs and SGs impose from a functional, representational, and learning dynamics point of view. In this paper, we study DNIs through the use of synthetic gradients on feed-forward networks to better understand their behaviour and elucidate their effect on optimisation. We show that the incorporation of SGs does not affect the representational strength of the learning system for a neural network, and prove the convergence of the learning system for linear and deep linear models. On practical problems we investigate the mechanism by which synthetic gradient estimators approximate the true loss, and, surprisingly, how that leads to drastically different layer-wise representations. Finally, we also expose the relationship of using synthetic gradients to other error approximation techniques and find a unifying language for discussion and comparison.
Reinforcement Learning with Unsupervised Auxiliary Tasks
Nov 16, 2016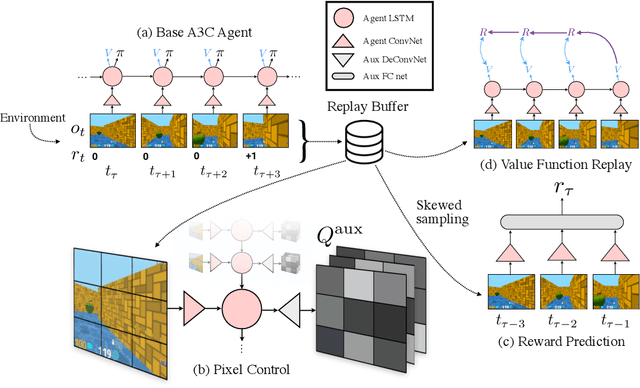
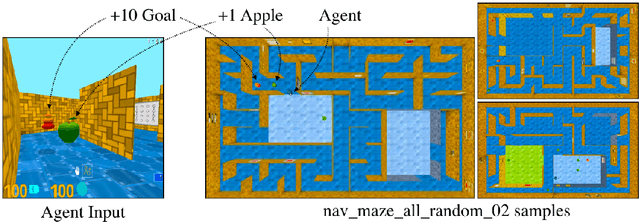
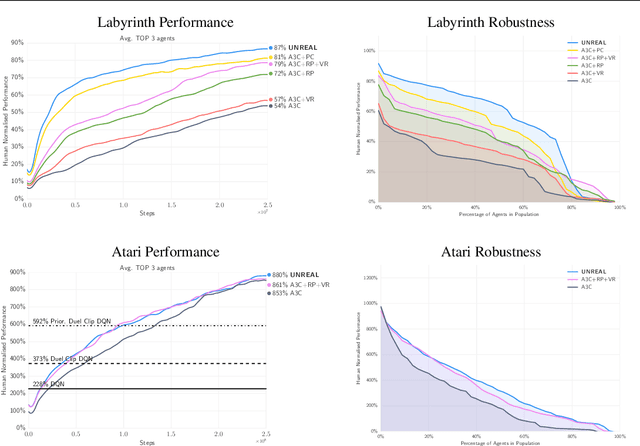
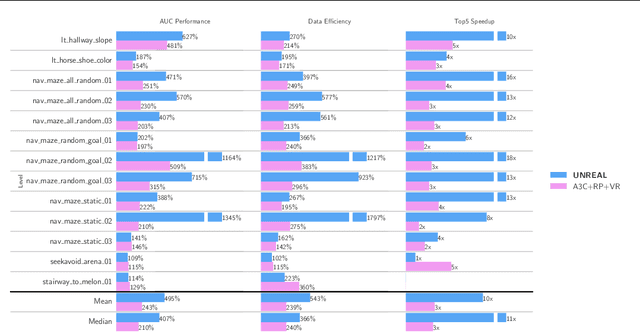
Deep reinforcement learning agents have achieved state-of-the-art results by directly maximising cumulative reward. However, environments contain a much wider variety of possible training signals. In this paper, we introduce an agent that also maximises many other pseudo-reward functions simultaneously by reinforcement learning. All of these tasks share a common representation that, like unsupervised learning, continues to develop in the absence of extrinsic rewards. We also introduce a novel mechanism for focusing this representation upon extrinsic rewards, so that learning can rapidly adapt to the most relevant aspects of the actual task. Our agent significantly outperforms the previous state-of-the-art on Atari, averaging 880\% expert human performance, and a challenging suite of first-person, three-dimensional \emph{Labyrinth} tasks leading to a mean speedup in learning of 10$\times$ and averaging 87\% expert human performance on Labyrinth.