 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning and its Neuroscientific Implications
Jul 07, 2020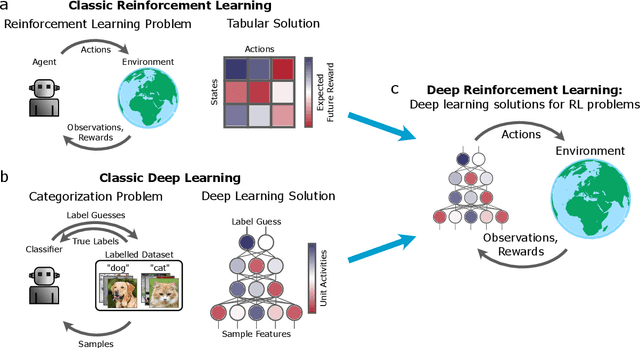
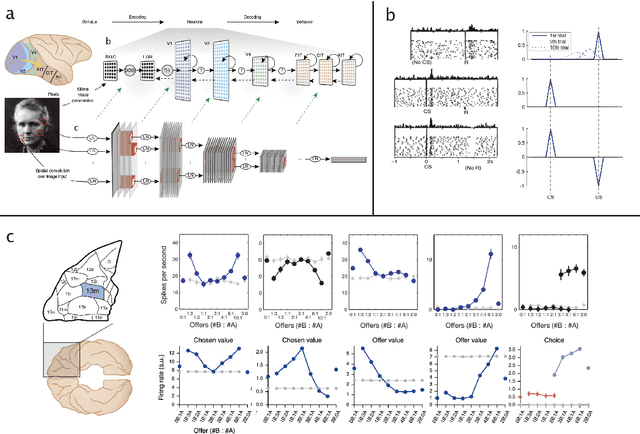
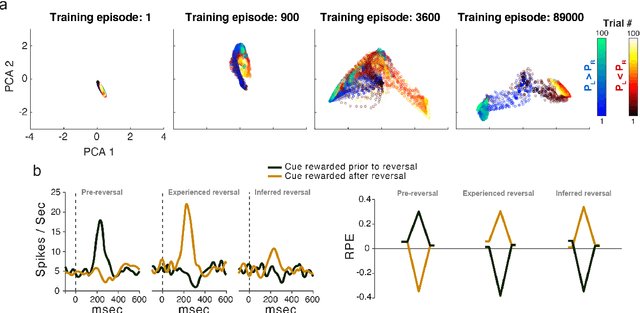
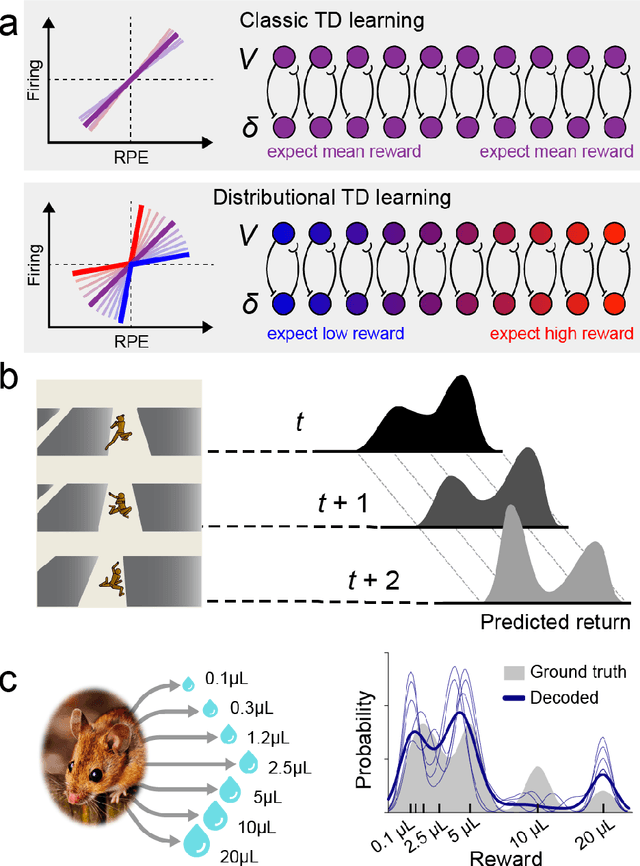
The emergence of powerful artificial intelligence is defining new research directions in neuroscience. To date, this research has focused largely on deep neural networks trained using supervised learning, in tasks such as image classification. However, there is another area of recent AI work which has so far received less attention from neuroscientists, but which may have profound neuroscientific implications: deep reinforcement learning. Deep RL offers a comprehensive framework for studying the interplay among learning, representation and decision-making, offering to the brain sciences a new set of research tools and a wide range of novel hypotheses. In the present review, we provide a high-level introduction to deep RL, discuss some of its initial applications to neuroscience, and survey its wider implications for research on brain and behavior, concluding with a list of opportunities for next-stage research.
The Variational Bandwidth Bottleneck: Stochastic Evaluation on an Information Budget
Apr 24, 2020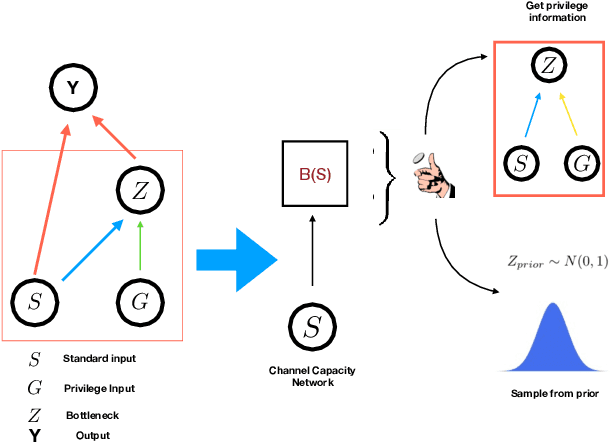

In many applications, it is desirable to extract only the relevant information from complex input data, which involves making a decision about which input features are relevant. The information bottleneck method formalizes this as an information-theoretic optimization problem by maintaining an optimal tradeoff between compression (throwing away irrelevant input information), and predicting the target. In many problem settings, including the reinforcement learning problems we consider in this work, we might prefer to compress only part of the input. This is typically the case when we have a standard conditioning input, such as a state observation, and a "privileged" input, which might correspond to the goal of a task, the output of a costly planning algorithm, or communication with another agent. In such cases, we might prefer to compress the privileged input, either to achieve better generalization (e.g., with respect to goals) or to minimize access to costly information (e.g., in the case of communication). Practical implementations of the information bottleneck based on variational inference require access to the privileged input in order to compute the bottleneck variable, so although they perform compression, this compression operation itself needs unrestricted, lossless access. In this work, we propose the variational bandwidth bottleneck, which decides for each example on the estimated value of the privileged information before seeing it, i.e., only based on the standard input, and then accordingly chooses stochastically, whether to access the privileged input or not. We formulate a tractable approximation to this framework and demonstrate in a series of reinforcement learning experiments that it can improve generalization and reduce access to computationally costly information.
MEMO: A Deep Network for Flexible Combination of Episodic Memories
Jan 29, 2020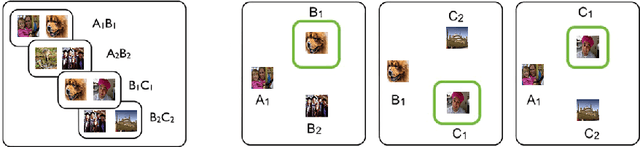
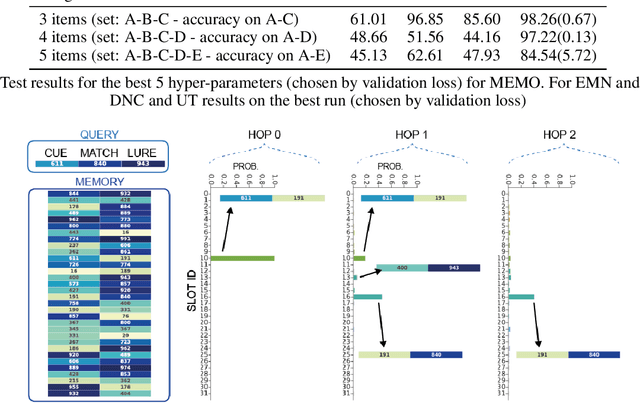
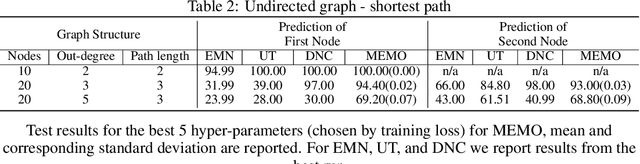

Recent research developing neural network architectures with external memory have often used the benchmark bAbI question and answering dataset which provides a challenging number of tasks requiring reasoning. Here we employed a classic associative inference task from the memory-based reasoning neuroscience literature in order to more carefully probe the reasoning capacity of existing memory-augmented architectures. This task is thought to capture the essence of reasoning -- the appreciation of distant relationships among elements distributed across multiple facts or memories. Surprisingly, we found that current architectures struggle to reason over long distance associations. Similar results were obtained on a more complex task involving finding the shortest path between nodes in a path. We therefore developed MEMO, an architecture endowed with the capacity to reason over longer distances. This was accomplished with the addition of two novel components. First, it introduces a separation between memories (facts) stored in external memory and the items that comprise these facts in external memory. Second, it makes use of an adaptive retrieval mechanism, allowing a variable number of "memory hops" before the answer is produced. MEMO is capable of solving our novel reasoning tasks, as well as match state of the art results in bAbI.
Emergent Systematic Generalization in a Situated Agent
Oct 28, 2019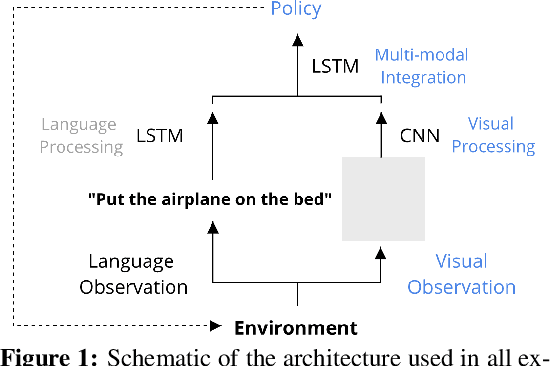
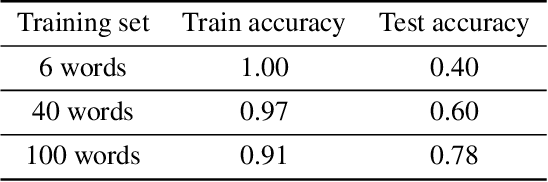
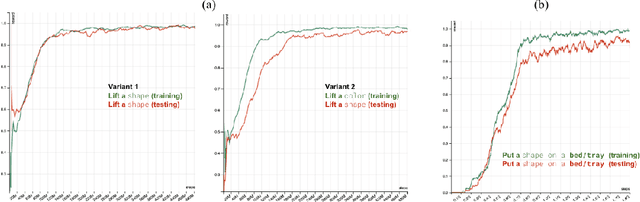
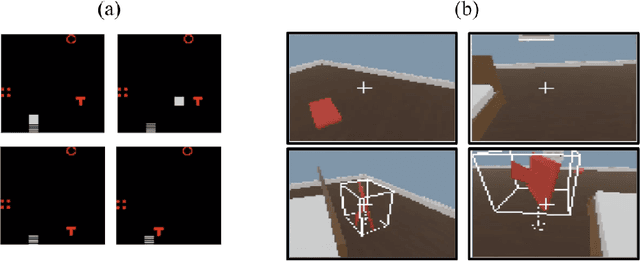
The question of whether deep neural networks are good at generalising beyond their immediate training experience is of critical importance for learning-based approaches to AI. Here, we demonstrate strong emergent systematic generalisation in a neural network agent and isolate the factors that support this ability. In environments ranging from a grid-world to a rich interactive 3D Unity room, we show that an agent can correctly exploit the compositional nature of a symbolic language to interpret never-seen-before instructions. We observe this capacity not only when instructions refer to object properties (colors and shapes) but also verb-like motor skills (lifting and putting) and abstract modifying operations (negation). We identify three factors that can contribute to this facility for systematic generalisation: (a) the number of object/word experiences in the training set; (b) the invariances afforded by a first-person, egocentric perspective; and (c) the variety of visual input experienced by an agent that perceives the world actively over time. Thus, while neural nets trained in idealised or reduced situations may fail to exhibit a compositional or systematic understanding of their experience, this competence can readily emerge when, like human learners, they have access to many examples of richly varying, multi-modal observations as they learn.
Meta-learning of Sequential Strategies
May 08, 2019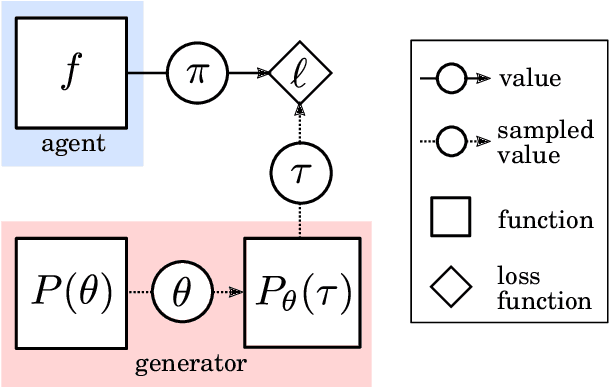
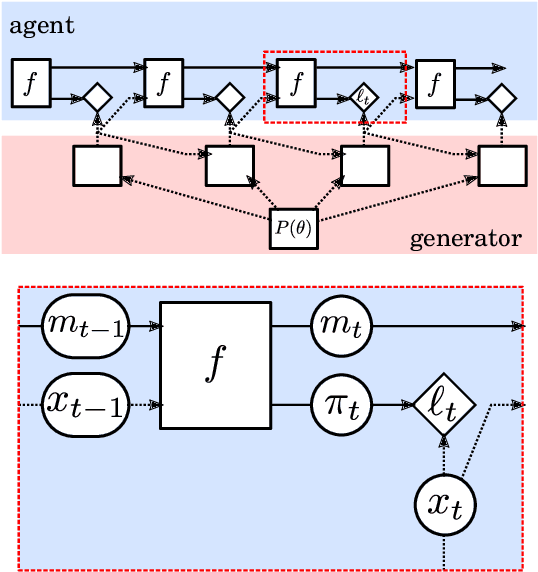
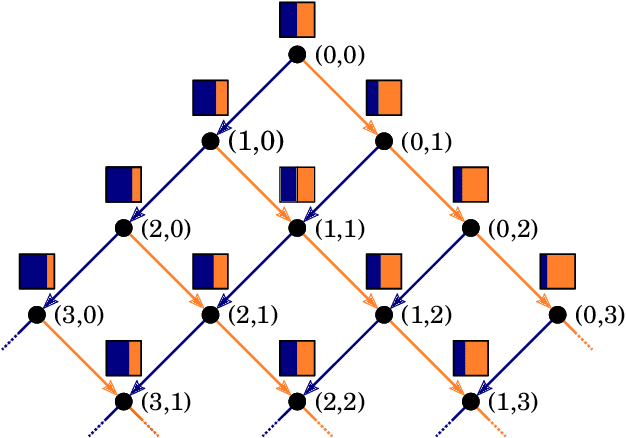
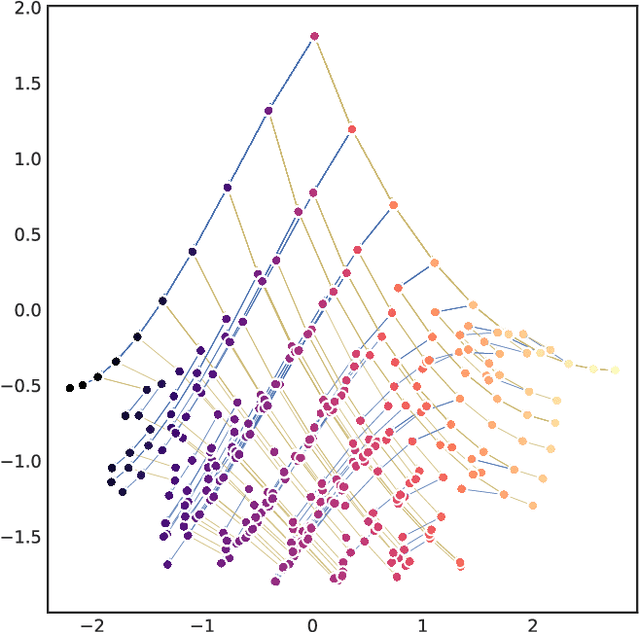
In this report we review memory-based meta-learning as a tool for building sample-efficient strategies that learn from past experience to adapt to any task within a target class. Our goal is to equip the reader with the conceptual foundations of this tool for building new, scalable agents that operate on broad domains. To do so, we present basic algorithmic templates for building near-optimal predictors and reinforcement learners which behave as if they had a probabilistic model that allowed them to efficiently exploit task structure. Furthermore, we recast memory-based meta-learning within a Bayesian framework, showing that the meta-learned strategies are near-optimal because they amortize Bayes-filtered data, where the adaptation is implemented in the memory dynamics as a state-machine of sufficient statistics. Essentially, memory-based meta-learning translates the hard problem of probabilistic sequential inference into a regression problem.
Is coding a relevant metaphor for building AI? A commentary on "Is coding a relevant metaphor for the brain?", by Romain Brette
Apr 18, 2019Brette contends that the neural coding metaphor is an invalid basis for theories of what the brain does. Here, we argue that it is an insufficient guide for building an artificial intelligence that learns to accomplish short- and long-term goals in a complex, changing environment.
InfoBot: Transfer and Exploration via the Information Bottleneck
Apr 04, 2019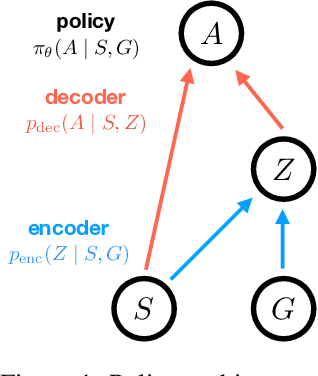



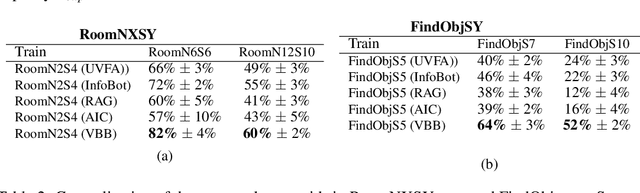
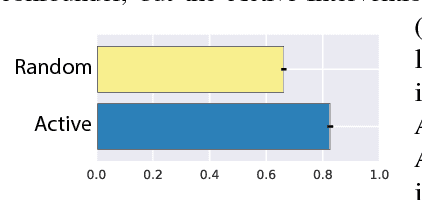
A central challenge in reinforcement learning is discovering effective policies for tasks where rewards are sparsely distributed. We postulate that in the absence of useful reward signals, an effective exploration strategy should seek out {\it decision states}. These states lie at critical junctions in the state space from where the agent can transition to new, potentially unexplored regions. We propose to learn about decision states from prior experience. By training a goal-conditioned policy with an information bottleneck, we can identify decision states by examining where the model actually leverages the goal state. We find that this simple mechanism effectively identifies decision states, even in partially observed settings. In effect, the model learns the sensory cues that correlate with potential subgoals. In new environments, this model can then identify novel subgoals for further exploration, guiding the agent through a sequence of potential decision states and through new regions of the state space.
Multi-Object Representation Learning with Iterative Variational Inference
Mar 01, 2019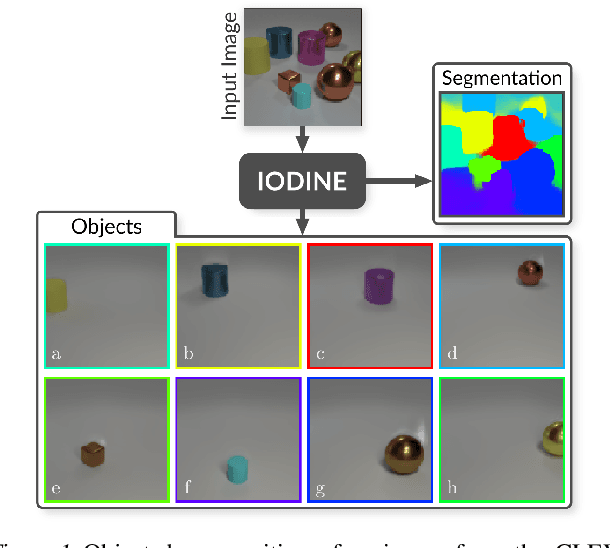

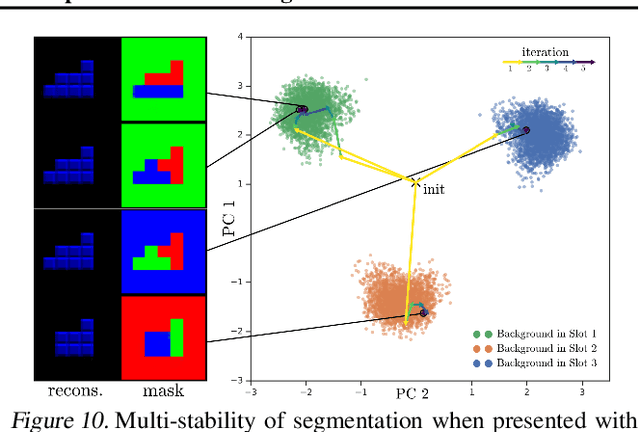

Human perception is structured around objects which form the basis for our higher-level cognition and impressive systematic generalization abilities. Yet most work on representation learning focuses on feature learning without even considering multiple objects, or treats segmentation as an (often supervised) preprocessing step. Instead, we argue for the importance of learning to segment and represent objects jointly. We demonstrate that, starting from the simple assumption that a scene is composed of multiple entities, it is possible to learn to segment images into interpretable objects with disentangled representations. Our method learns -- without supervision -- to inpaint occluded parts, and extrapolates to scenes with more objects and to unseen objects with novel feature combinations. We also show that, due to the use of iterative variational inference, our system is able to learn multi-modal posteriors for ambiguous inputs and extends naturally to sequences.
Causal Reasoning from Meta-reinforcement Learning
Jan 23, 2019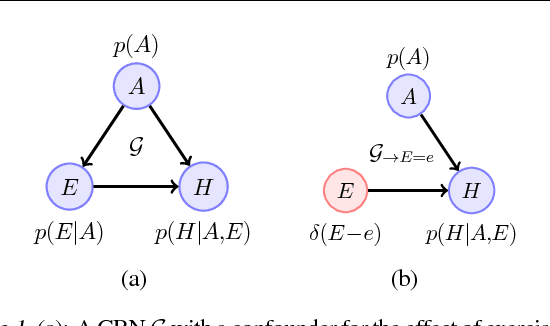


Discovering and exploiting the causal structure in the environment is a crucial challenge for intelligent agents. Here we explore whether causal reasoning can emerge via meta-reinforcement learning. We train a recurrent network with model-free reinforcement learning to solve a range of problems that each contain causal structure. We find that the trained agent can perform causal reasoning in novel situations in order to obtain rewards. The agent can select informative interventions, draw causal inferences from observational data, and make counterfactual predictions. Although established formal causal reasoning algorithms also exist, in this paper we show that such reasoning can arise from model-free reinforcement learning, and suggest that causal reasoning in complex settings may benefit from the more end-to-end learning-based approaches presented here. This work also offers new strategies for structured exploration in reinforcement learning, by providing agents with the ability to perform -- and interpret -- experiments.
Bayesian Action Decoder for Deep Multi-Agent Reinforcement Learning
Nov 04, 2018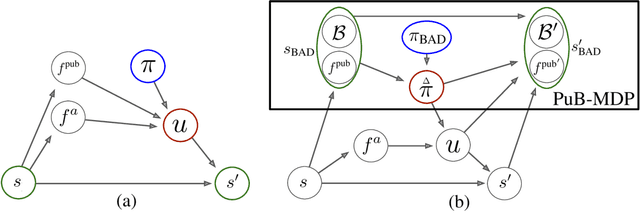
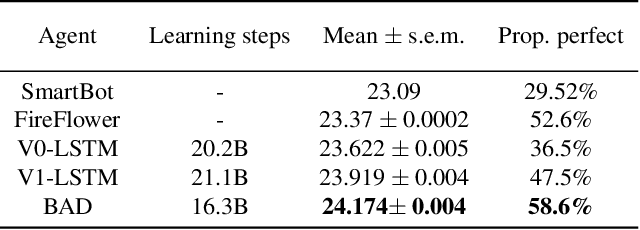
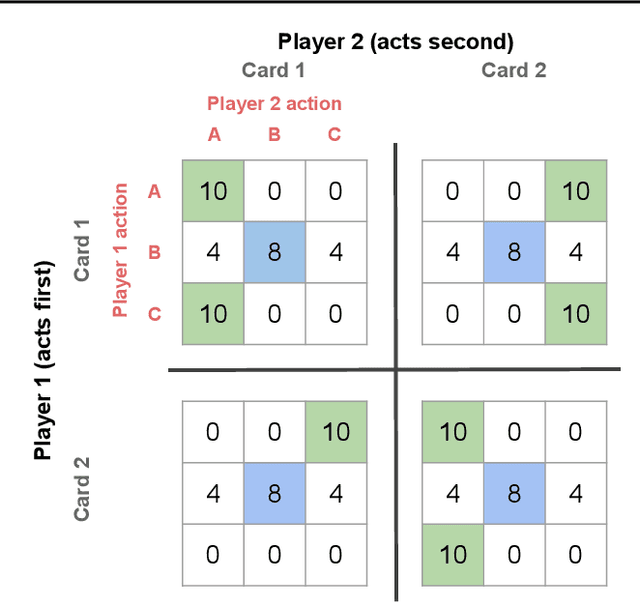
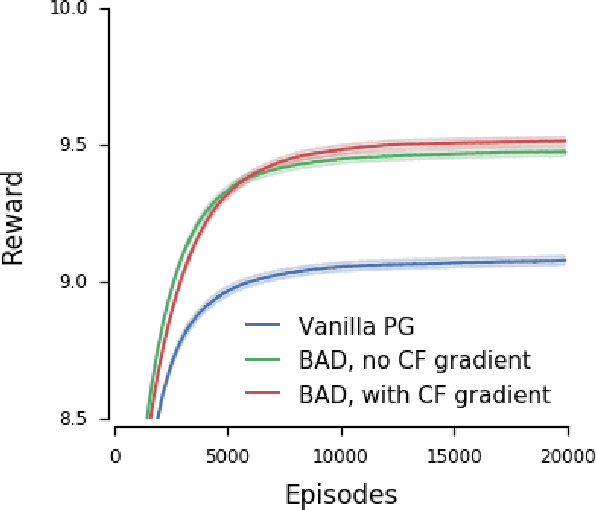
When observing the actions of others, humans carry out inferences about why the others acted as they did, and what this implies about their view of the world. Humans also use the fact that their actions will be interpreted in this manner when observed by others, allowing them to act informatively and thereby communicate efficiently with others. Although learning algorithms have recently achieved superhuman performance in a number of two-player, zero-sum games, scalable multi-agent reinforcement learning algorithms that can discover effective strategies and conventions in complex, partially observable settings have proven elusive. We present the Bayesian action decoder (BAD), a new multi-agent learning method that uses an approximate Bayesian update to obtain a public belief that conditions on the actions taken by all agents in the environment. Together with the public belief, this Bayesian update effectively defines a new Markov decision process, the public belief MDP, in which the action space consists of deterministic partial policies, parameterised by deep neural networks, that can be sampled for a given public state. It exploits the fact that an agent acting only on this public belief state can still learn to use its private information if the action space is augmented to be over partial policies mapping private information into environment actions. The Bayesian update is also closely related to the theory of mind reasoning that humans carry out when observing others' actions. We first validate BAD on a proof-of-principle two-step matrix game, where it outperforms traditional policy gradient methods. We then evaluate BAD on the challenging, cooperative partial-information card game Hanabi, where in the two-player setting the method surpasses all previously published learning and hand-coded approaches.