 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Diverse Solutions in Deep Reinforcement Learning
Mar 12, 2021
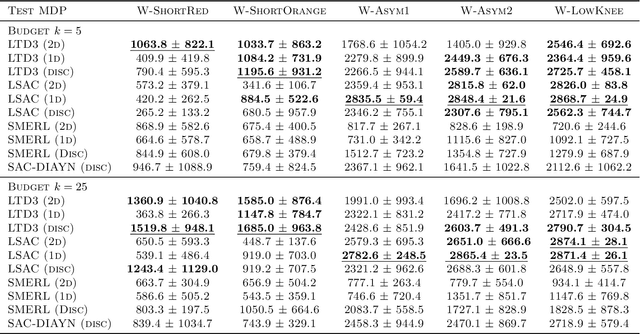
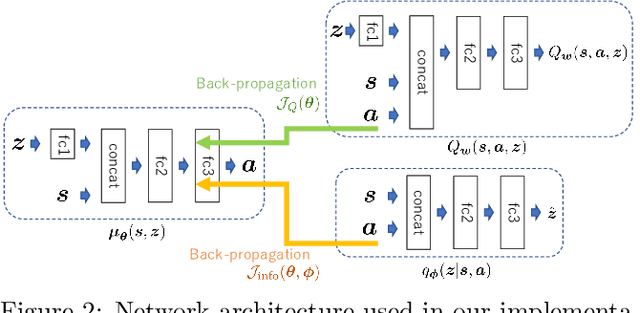
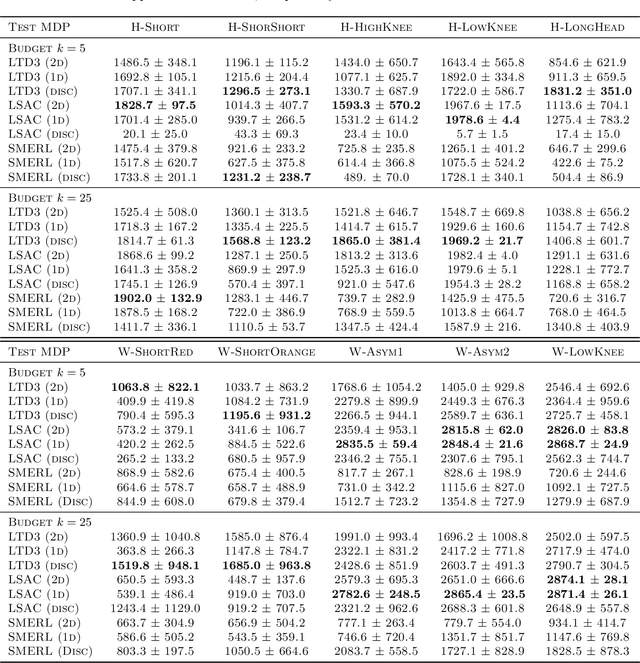
Reinforcement learning (RL) algorithms are typically limited to learning a single solution of a specified task, even though there often exists diverse solutions to a given task. Compared with learning a single solution, learning a set of diverse solutions is beneficial because diverse solutions enable robust few-shot adaptation and allow the user to select a preferred solution. Although previous studies have showed that diverse behaviors can be modeled with a policy conditioned on latent variables, an approach for modeling an infinite set of diverse solutions with continuous latent variables has not been investigated. In this study, we propose an RL method that can learn infinitely many solutions by training a policy conditioned on a continuous or discrete low-dimensional latent variable. Through continuous control tasks, we demonstrate that our method can learn diverse solutions in a data-efficient manner and that the solutions can be used for few-shot adaptation to solve unseen tasks.
Lower-bounded proper losses for weakly supervised classification
Mar 04, 2021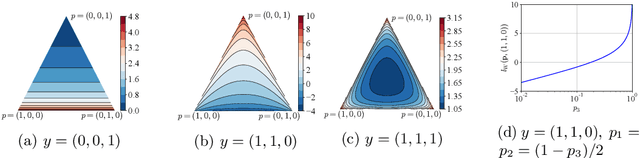
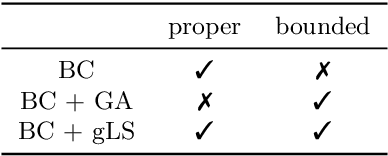

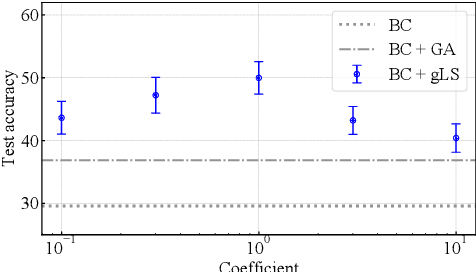
This paper discusses the problem of weakly supervised learning of classification, in which instances are given weak labels that are produced by some label-corruption process. The goal is to derive conditions under which loss functions for weak-label learning are proper and lower-bounded -- two essential requirements for the losses used in class-probability estimation. To this end, we derive a representation theorem for proper losses in supervised learning, which dualizes the Savage representation. We use this theorem to characterize proper weak-label losses and find a condition for them to be lower-bounded. Based on these theoretical findings, we derive a novel regularization scheme called generalized logit squeezing, which makes any proper weak-label loss bounded from below, without losing properness. Furthermore, we experimentally demonstrate the effectiveness of our proposed approach, as compared to improper or unbounded losses. Those results highlight the importance of properness and lower-boundedness. The code is publicly available at https://github.com/yoshum/lower-bounded-proper-losses.
LocalDrop: A Hybrid Regularization for Deep Neural Networks
Mar 01, 2021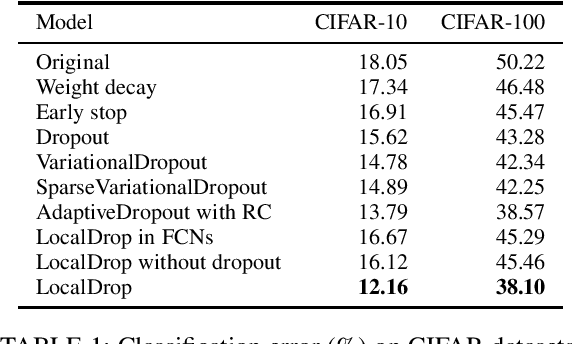
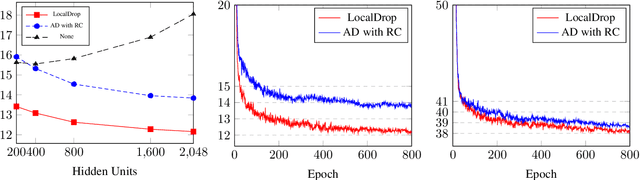
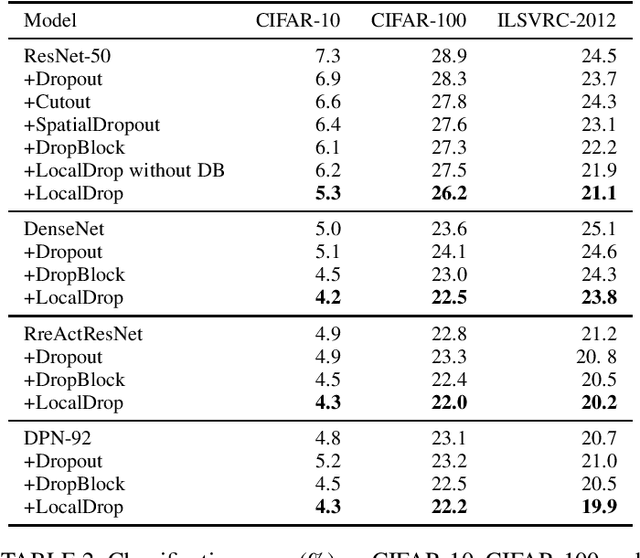
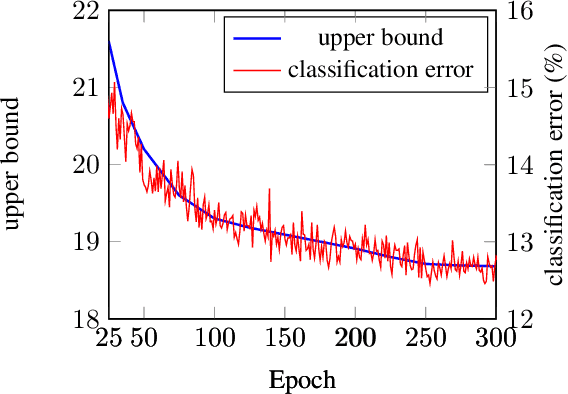
In neural networks, developing regularization algorithms to settle overfitting is one of the major study areas. We propose a new approach for the regularization of neural networks by the local Rademacher complexity called LocalDrop. A new regularization function for both fully-connected networks (FCNs) and convolutional neural networks (CNNs), including drop rates and weight matrices, has been developed based on the proposed upper bound of the local Rademacher complexity by the strict mathematical deduction. The analyses of dropout in FCNs and DropBlock in CNNs with keep rate matrices in different layers are also included in the complexity analyses. With the new regularization function, we establish a two-stage procedure to obtain the optimal keep rate matrix and weight matrix to realize the whole training model. Extensive experiments have been conducted to demonstrate the effectiveness of LocalDrop in different models by comparing it with several algorithms and the effects of different hyperparameters on the final performances.
Incorporating Causal Graphical Prior Knowledge into Predictive Modeling via Simple Data Augmentation
Feb 27, 2021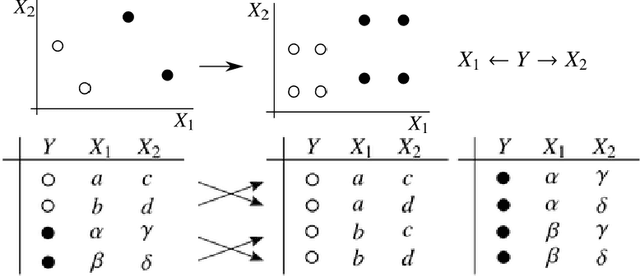
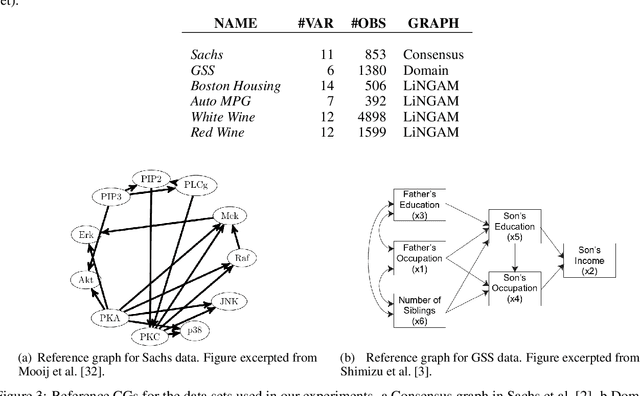

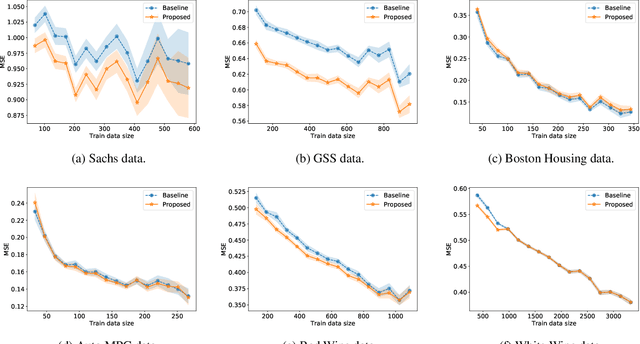
Causal graphs (CGs) are compact representations of the knowledge of the data generating processes behind the data distributions. When a CG is available, e.g., from the domain knowledge, we can infer the conditional independence (CI) relations that should hold in the data distribution. However, it is not straightforward how to incorporate this knowledge into predictive modeling. In this work, we propose a model-agnostic data augmentation method that allows us to exploit the prior knowledge of the CI encoded in a CG for supervised machine learning. We theoretically justify the proposed method by providing an excess risk bound indicating that the proposed method suppresses overfitting by reducing the apparent complexity of the predictor hypothesis class. Using real-world data with CGs provided by domain experts, we experimentally show that the proposed method is effective in improving the prediction accuracy, especially in the small-data regime.
Guided Interpolation for Adversarial Training
Feb 15, 2021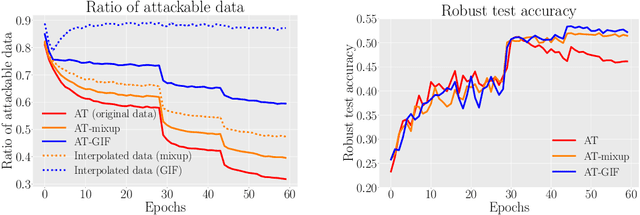

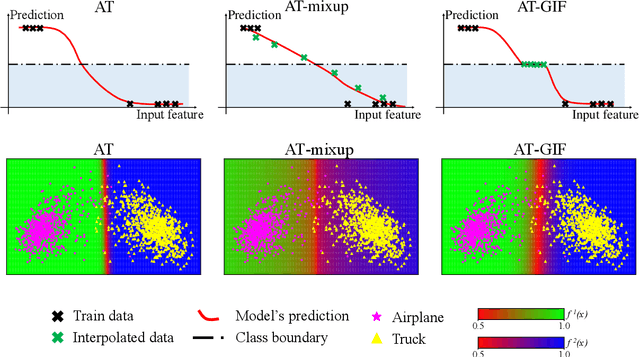

To enhance adversarial robustness, adversarial training learns deep neural networks on the adversarial variants generated by their natural data. However, as the training progresses, the training data becomes less and less attackable, undermining the robustness enhancement. A straightforward remedy is to incorporate more training data, but sometimes incurring an unaffordable cost. In this paper, to mitigate this issue, we propose the guided interpolation framework (GIF): in each epoch, the GIF employs the previous epoch's meta information to guide the data's interpolation. Compared with the vanilla mixup, the GIF can provide a higher ratio of attackable data, which is beneficial to the robustness enhancement; it meanwhile mitigates the model's linear behavior between classes, where the linear behavior is favorable to generalization but not to the robustness. As a result, the GIF encourages the model to predict invariantly in the cluster of each class. Experiments demonstrate that the GIF can indeed enhance adversarial robustness on various adversarial training methods and various datasets.
Learning from Similarity-Confidence Data
Feb 13, 2021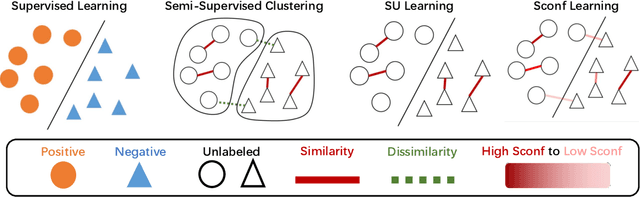

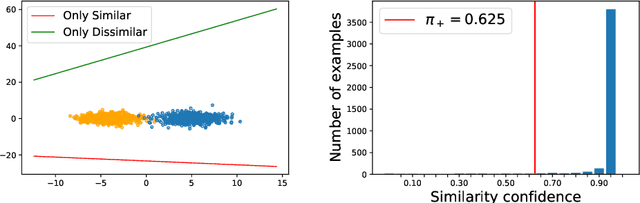
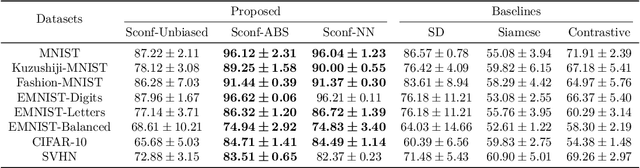
Weakly supervised learning has drawn considerable attention recently to reduce the expensive time and labor consumption of labeling massive data. In this paper, we investigate a novel weakly supervised learning problem of learning from similarity-confidence (Sconf) data, where we aim to learn an effective binary classifier from only unlabeled data pairs equipped with confidence that illustrates their degree of similarity (two examples are similar if they belong to the same class). To solve this problem, we propose an unbiased estimator of the classification risk that can be calculated from only Sconf data and show that the estimation error bound achieves the optimal convergence rate. To alleviate potential overfitting when flexible models are used, we further employ a risk correction scheme on the proposed risk estimator. Experimental results demonstrate the effectiveness of the proposed methods.
CIFS: Improving Adversarial Robustness of CNNs via Channel-wise Importance-based Feature Selection
Feb 10, 2021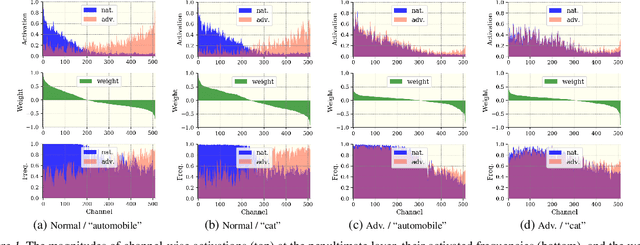
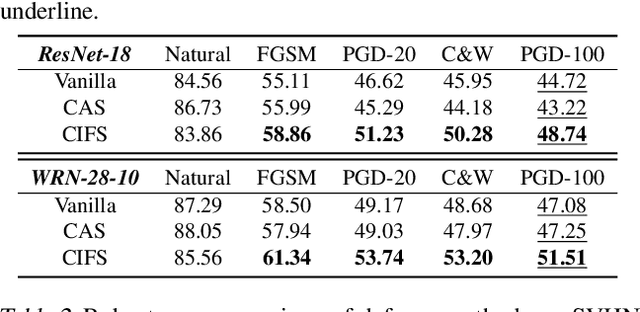
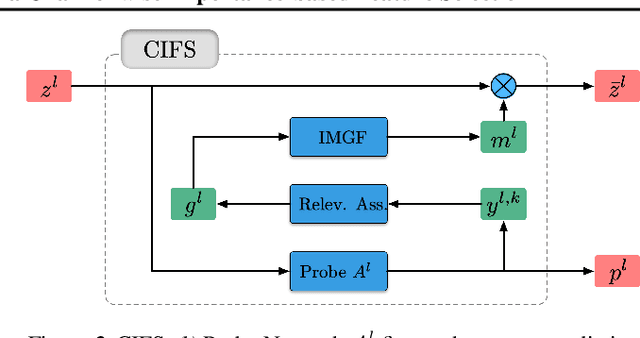
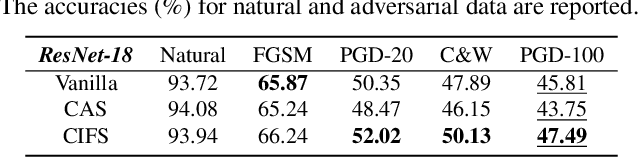
We investigate the adversarial robustness of CNNs from the perspective of channel-wise activations. By comparing \textit{non-robust} (normally trained) and \textit{robustified} (adversarially trained) models, we observe that adversarial training (AT) robustifies CNNs by aligning the channel-wise activations of adversarial data with those of their natural counterparts. However, the channels that are \textit{negatively-relevant} (NR) to predictions are still over-activated when processing adversarial data. Besides, we also observe that AT does not result in similar robustness for all classes. For the robust classes, channels with larger activation magnitudes are usually more \textit{positively-relevant} (PR) to predictions, but this alignment does not hold for the non-robust classes. Given these observations, we hypothesize that suppressing NR channels and aligning PR ones with their relevances further enhances the robustness of CNNs under AT. To examine this hypothesis, we introduce a novel mechanism, i.e., \underline{C}hannel-wise \underline{I}mportance-based \underline{F}eature \underline{S}election (CIFS). The CIFS manipulates channels' activations of certain layers by generating non-negative multipliers to these channels based on their relevances to predictions. Extensive experiments on benchmark datasets including CIFAR10 and SVHN clearly verify the hypothesis and CIFS's effectiveness of robustifying CNNs.
Understanding the Interaction of Adversarial Training with Noisy Labels
Feb 09, 2021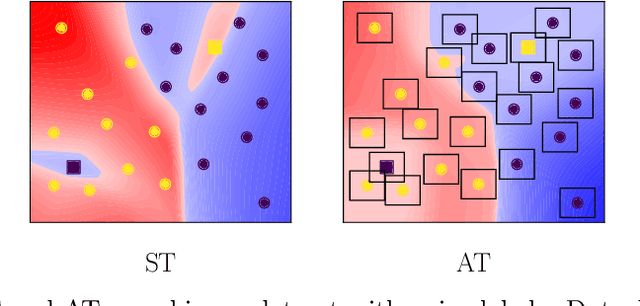
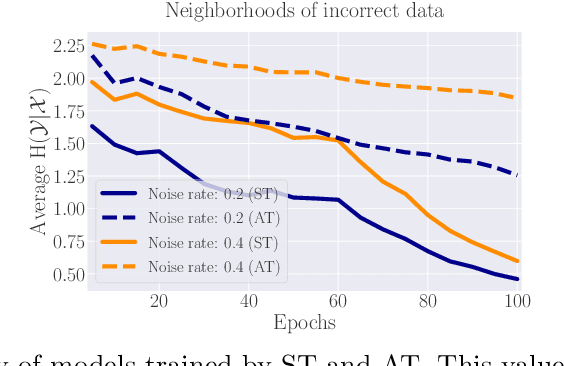
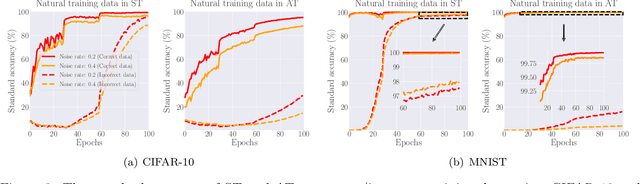
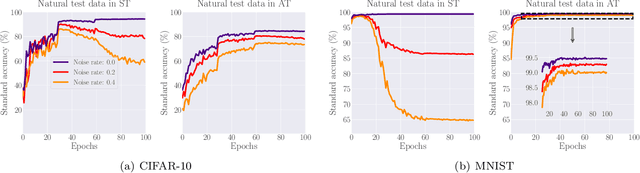
Noisy labels (NL) and adversarial examples both undermine trained models, but interestingly they have hitherto been studied independently. A recent adversarial training (AT) study showed that the number of projected gradient descent (PGD) steps to successfully attack a point (i.e., find an adversarial example in its proximity) is an effective measure of the robustness of this point. Given that natural data are clean, this measure reveals an intrinsic geometric property -- how far a point is from its class boundary. Based on this breakthrough, in this paper, we figure out how AT would interact with NL. Firstly, we find if a point is too close to its noisy-class boundary (e.g., one step is enough to attack it), this point is likely to be mislabeled, which suggests to adopt the number of PGD steps as a new criterion for sample selection for correcting NL. Secondly, we confirm AT with strong smoothing effects suffers less from NL (without NL corrections) than standard training (ST), which suggests AT itself is an NL correction. Hence, AT with NL is helpful for improving even the natural accuracy, which again illustrates the superiority of AT as a general-purpose robust learning criterion.
Learning Diverse-Structured Networks for Adversarial Robustness
Feb 08, 2021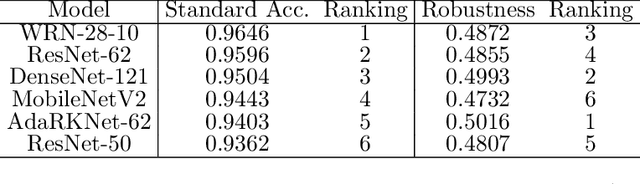
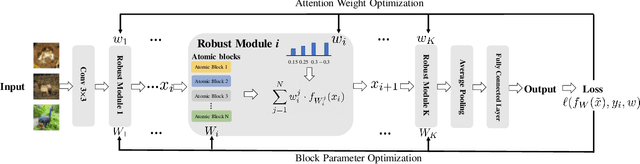
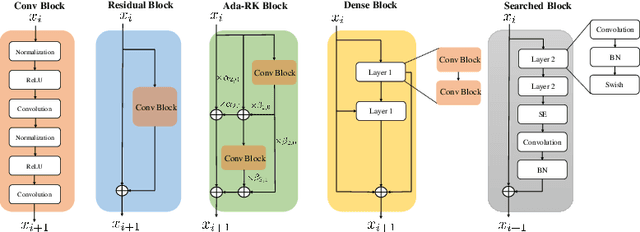
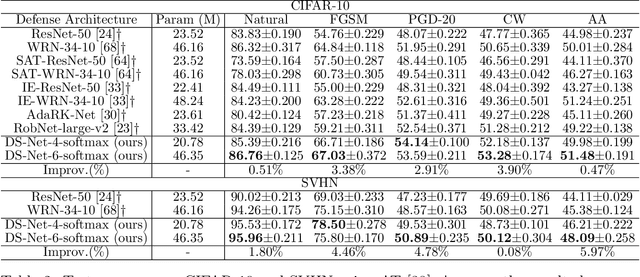
In adversarial training (AT), the main focus has been the objective and optimizer while the model has been less studied, so that the models being used are still those classic ones in standard training (ST). Classic network architectures (NAs) are generally worse than searched NAs in ST, which should be the same in AT. In this paper, we argue that NA and AT cannot be handled independently, since given a dataset, the optimal NA in ST would be no longer optimal in AT. That being said, AT is time-consuming itself; if we directly search NAs in AT over large search spaces, the computation will be practically infeasible. Thus, we propose a diverse-structured network (DS-Net), to significantly reduce the size of the search space: instead of low-level operations, we only consider predefined atomic blocks, where an atomic block is a time-tested building block like the residual block. There are only a few atomic blocks and thus we can weight all atomic blocks rather than find the best one in a searched block of DS-Net, which is an essential trade-off between exploring diverse structures and exploiting the best structures. Empirical results demonstrate the advantages of DS-Net, i.e., weighting the atomic blocks.
Learning Noise Transition Matrix from Only Noisy Labels via Total Variation Regularization
Feb 04, 2021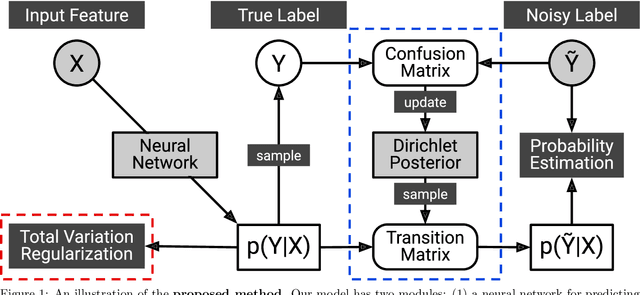
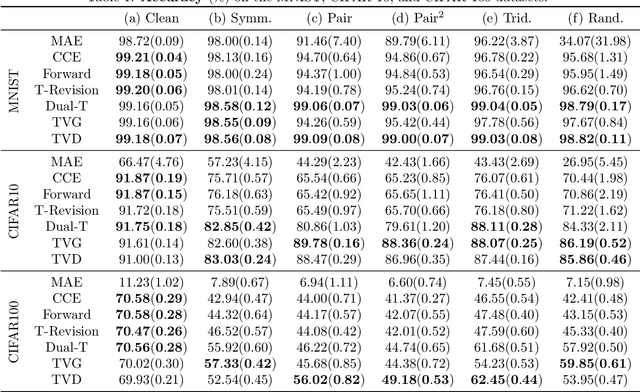
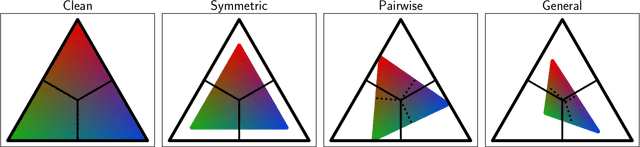
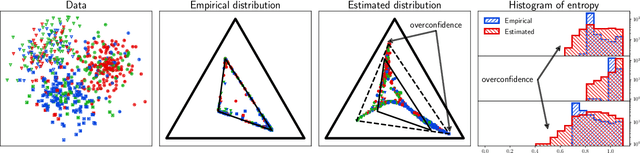
Many weakly supervised classification methods employ a noise transition matrix to capture the class-conditional label corruption. To estimate the transition matrix from noisy data, existing methods often need to estimate the noisy class-posterior, which could be unreliable due to the overconfidence of neural networks. In this work, we propose a theoretically grounded method that can estimate the noise transition matrix and learn a classifier simultaneously, without relying on the error-prone noisy class-posterior estimation. Concretely, inspired by the characteristics of the stochastic label corruption process, we propose total variation regularization, which encourages the predicted probabilities to be more distinguishable from each other. Under mild assumptions, the proposed method yields a consistent estimator of the transition matrix. We show the effectiveness of the proposed method through experiments on benchmark and real-world datasets.