 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtomic Fact-Checking Increases Clinician Trust in Large Language Model Recommendations for Oncology Decision Support: A Randomized Controlled Trial
May 05, 2026Question: Does atomic fact-checking, which decomposes AI treatment recommendations into individually verifiable claims linked to source guideline documents, increase clinician trust compared to traditional explainability approaches? Findings: In this randomized trial of 356 clinicians generating 7,476 trust ratings, atomic fact-checking produced a large effect on trust (Cohen's d = 0.94), increasing the proportion of clinicians expressing trust from 26.9% to 66.5%. Traditional transparency mechanisms showed a dose-response gradient of improvement over baseline (d = 0.25 to 0.50). Meaning: Decomposing AI recommendations into individually verifiable claims linked to source guidelines produces substantially higher clinician trust than traditional explainability approaches in high-stakes clinical decisions.
Agentic clinical reasoning over longitudinal myeloma records: a retrospective evaluation against expert consensus
Apr 27, 2026Multiple myeloma is managed through sequential lines of therapy over years to decades, with each decision depending on cumulative disease history distributed across dozens to hundreds of heterogeneous clinical documents. Whether LLM-based systems can synthesise this evidence at a level approaching expert agreement has not been established. A retrospective evaluation was conducted on longitudinal clinical records of 811 myeloma patients treated at a tertiary centre (2001-2026), covering 44,962 documents and 1,334,677 laboratory values, with external validation on MIMIC-IV. An agentic reasoning system was compared against single-pass retrieval-augmented generation (RAG), iterative RAG, and full-context input on 469 patient-question pairs from 48 templates at three complexity levels. Reference labels came from double annotation by four oncologists with senior haematologist adjudication. Iterative RAG and full-context input converged on a shared ceiling (75.4% vs 75.8%, p = 1.00). The agentic system reached 79.6% concordance (95% CI 76.4-82.8), exceeding both baselines (+3.8 and +4.2 pp; p = 0.006 and 0.007). Gains rose with question complexity, reaching +9.4 pp on criteria-based synthesis (p = 0.032), and with record length, reaching +13.5 pp in the top decile (n = 10). The system error rate (12.2%) was comparable to expert disagreement (13.6%), but severity was inverted: 57.8% of system errors were clinically significant versus 18.8% of expert disagreements. Agentic reasoning was the only approach to exceed the shared ceiling, with gains concentrated on the most complex questions and longest records. The greater clinical consequence of residual system errors indicates that prospective evaluation in routine care is required before these findings translate into patient benefit.
Evaluation of GPT-4 for chest X-ray impression generation: A reader study on performance and perception
Nov 12, 2023



The remarkable generative capabilities of multimodal foundation models are currently being explored for a variety of applications. Generating radiological impressions is a challenging task that could significantly reduce the workload of radiologists. In our study we explored and analyzed the generative abilities of GPT-4 for Chest X-ray impression generation. To generate and evaluate impressions of chest X-rays based on different input modalities (image, text, text and image), a blinded radiological report was written for 25-cases of the publicly available NIH-dataset. GPT-4 was given image, finding section or both sequentially to generate an input dependent impression. In a blind randomized reading, 4-radiologists rated the impressions and were asked to classify the impression origin (Human, AI), providing justification for their decision. Lastly text model evaluation metrics and their correlation with the radiological score (summation of the 4 dimensions) was assessed. According to the radiological score, the human-written impression was rated highest, although not significantly different to text-based impressions. The automated evaluation metrics showed moderate to substantial correlations to the radiological score for the image impressions, however individual scores were highly divergent among inputs, indicating insufficient representation of radiological quality. Detection of AI-generated impressions varied by input and was 61% for text-based impressions. Impressions classified as AI-generated had significantly worse radiological scores even when written by a radiologist, indicating potential bias. Our study revealed significant discrepancies between a radiological assessment and common automatic evaluation metrics depending on the model input. The detection of AI-generated findings is subject to bias that highly rated impressions are perceived as human-written.
Efficient, high-performance pancreatic segmentation using multi-scale feature extraction
Sep 02, 2020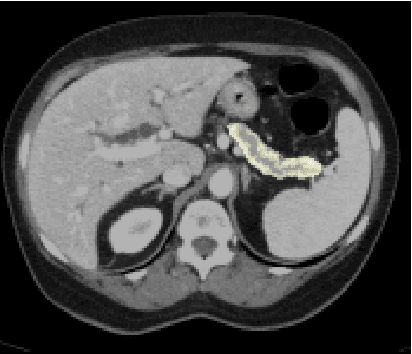

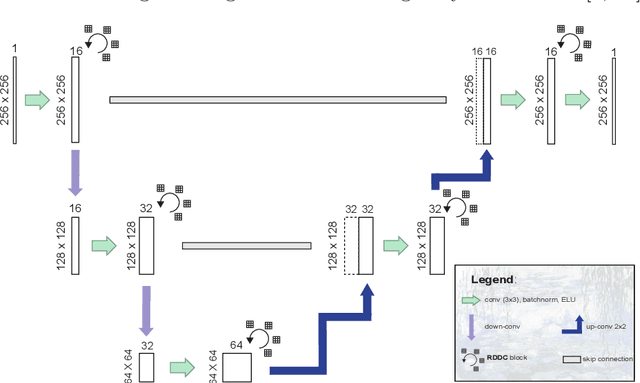

For artificial intelligence-based image analysis methods to reach clinical applicability, the development of high-performance algorithms is crucial. For example, existent segmentation algorithms based on natural images are neither efficient in their parameter use nor optimized for medical imaging. Here we present MoNet, a highly optimized neural-network-based pancreatic segmentation algorithm focused on achieving high performance by efficient multi-scale image feature utilization.