 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Deviation Types and Learning for Hindsight Rationality in Extensive-Form Games: Corrections
May 24, 2022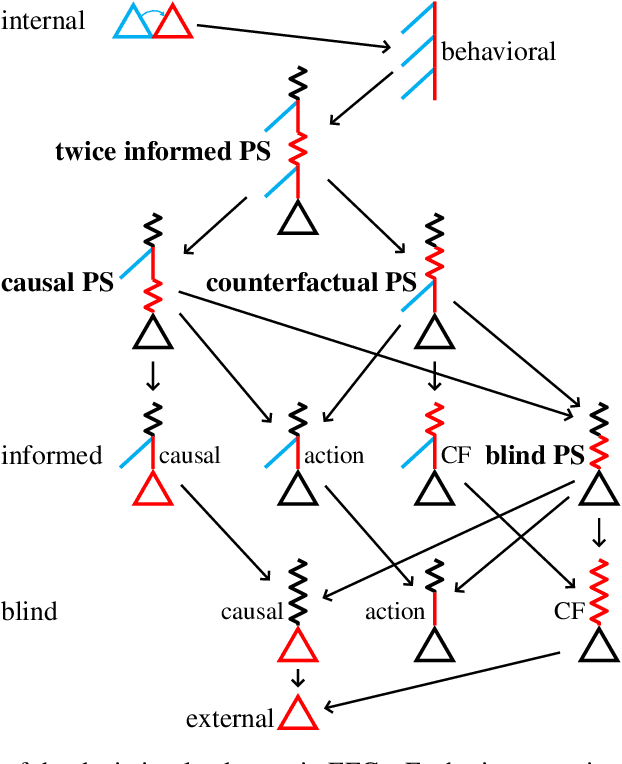
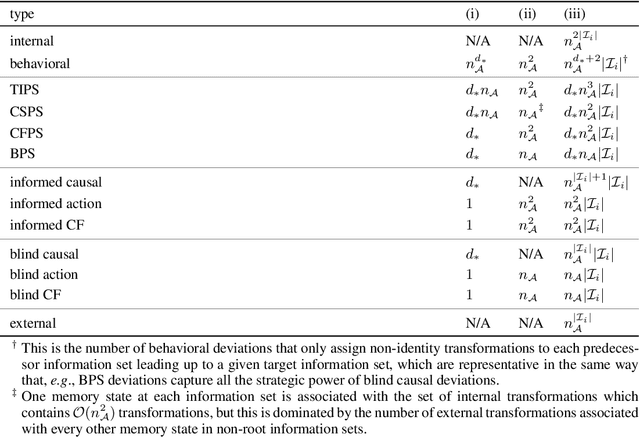
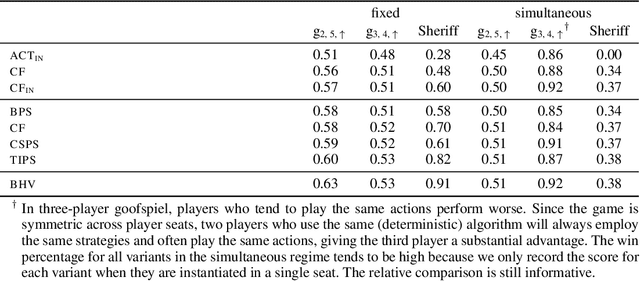

Hindsight rationality is an approach to playing general-sum games that prescribes no-regret learning dynamics for individual agents with respect to a set of deviations, and further describes jointly rational behavior among multiple agents with mediated equilibria. To develop hindsight rational learning in sequential decision-making settings, we formalize behavioral deviations as a general class of deviations that respect the structure of extensive-form games. Integrating the idea of time selection into counterfactual regret minimization (CFR), we introduce the extensive-form regret minimization (EFR) algorithm that achieves hindsight rationality for any given set of behavioral deviations with computation that scales closely with the complexity of the set. We identify behavioral deviation subsets, the partial sequence deviation types, that subsume previously studied types and lead to efficient EFR instances in games with moderate lengths. In addition, we present a thorough empirical analysis of EFR instantiated with different deviation types in benchmark games, where we find that stronger types typically induce better performance.
Anytime PSRO for Two-Player Zero-Sum Games
Jan 28, 2022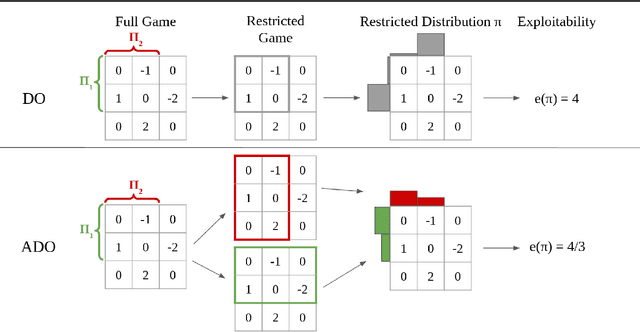

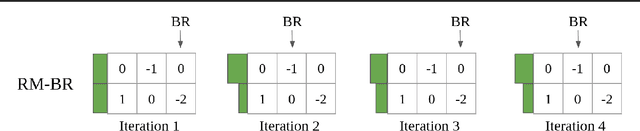

Policy space response oracles (PSRO) is a multi-agent reinforcement learning algorithm that has achieved state-of-the-art performance in very large two-player zero-sum games. PSRO is based on the tabular double oracle (DO) method, an algorithm that is guaranteed to converge to a Nash equilibrium, but may increase exploitability from one iteration to the next. We propose anytime double oracle (ADO), a tabular double oracle algorithm for 2-player zero-sum games that is guaranteed to converge to a Nash equilibrium while decreasing exploitability from one iteration to the next. Unlike DO, in which the restricted distribution is based on the restricted game formed by each player's strategy sets, ADO finds the restricted distribution for each player that minimizes its exploitability against any policy in the full, unrestricted game. We also propose a method of finding this restricted distribution via a no-regret algorithm updated against best responses, called RM-BR DO. Finally, we propose anytime PSRO (APSRO), a version of ADO that calculates best responses via reinforcement learning. In experiments on Leduc poker and random normal form games, we show that our methods achieve far lower exploitability than DO and PSRO and decrease exploitability monotonically.
Player of Games
Dec 06, 2021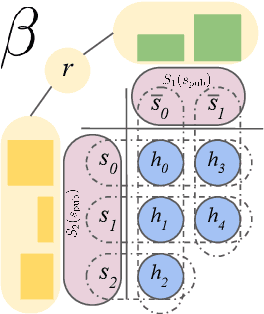

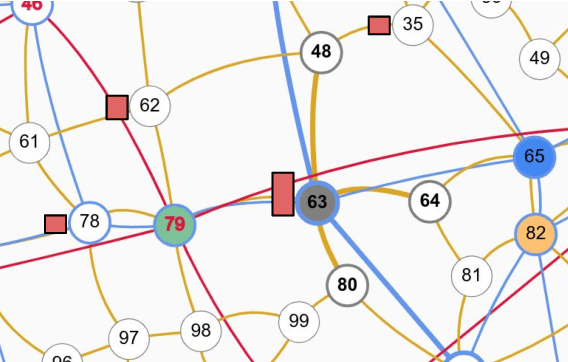
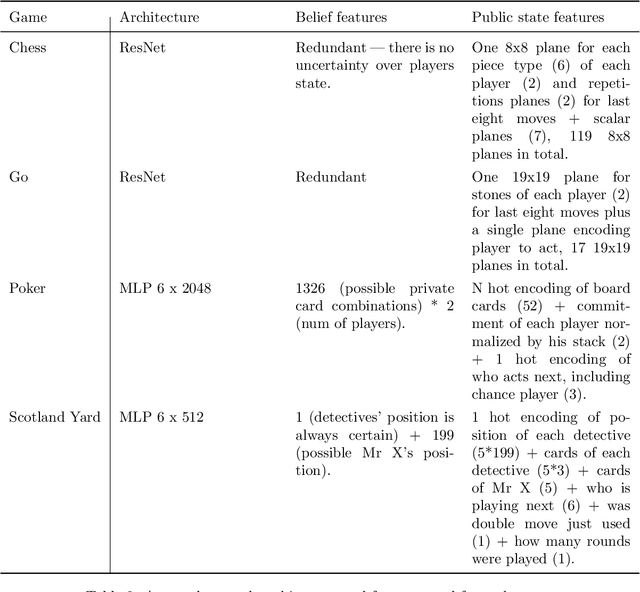
Games have a long history of serving as a benchmark for progress in artificial intelligence. Recently, approaches using search and learning have shown strong performance across a set of perfect information games, and approaches using game-theoretic reasoning and learning have shown strong performance for specific imperfect information poker variants. We introduce Player of Games, a general-purpose algorithm that unifies previous approaches, combining guided search, self-play learning, and game-theoretic reasoning. Player of Games is the first algorithm to achieve strong empirical performance in large perfect and imperfect information games -- an important step towards truly general algorithms for arbitrary environments. We prove that Player of Games is sound, converging to perfect play as available computation time and approximation capacity increases. Player of Games reaches strong performance in chess and Go, beats the strongest openly available agent in heads-up no-limit Texas hold'em poker (Slumbot), and defeats the state-of-the-art agent in Scotland Yard, an imperfect information game that illustrates the value of guided search, learning, and game-theoretic reasoning.
Dynamic population-based meta-learning for multi-agent communication with natural language
Oct 27, 2021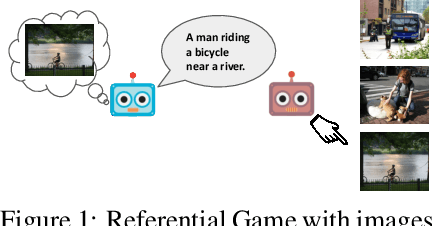
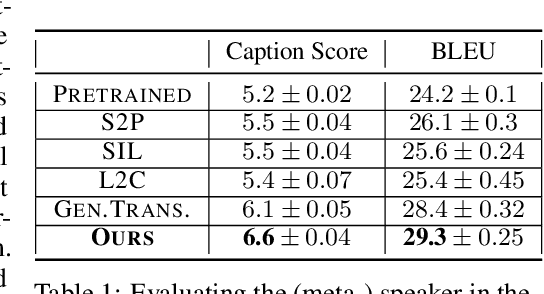
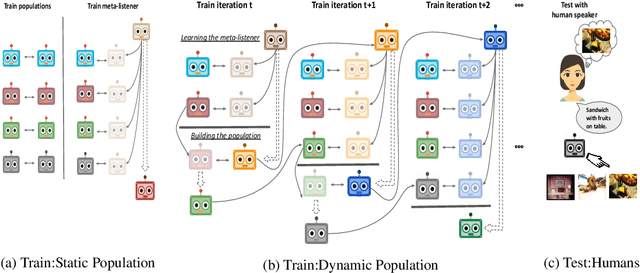
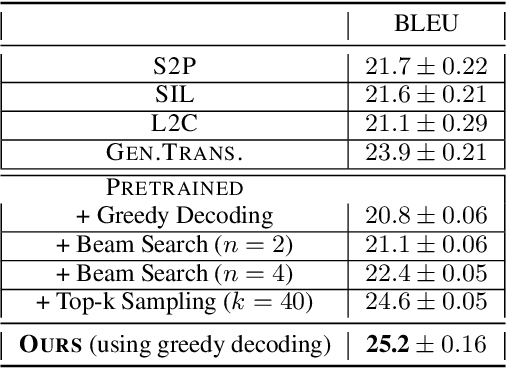
In this work, our goal is to train agents that can coordinate with seen, unseen as well as human partners in a multi-agent communication environment involving natural language. Previous work using a single set of agents has shown great progress in generalizing to known partners, however it struggles when coordinating with unfamiliar agents. To mitigate that, recent work explored the use of population-based approaches, where multiple agents interact with each other with the goal of learning more generic protocols. These methods, while able to result in good coordination between unseen partners, still only achieve so in cases of simple languages, thus failing to adapt to human partners using natural language. We attribute this to the use of static populations and instead propose a dynamic population-based meta-learning approach that builds such a population in an iterative manner. We perform a holistic evaluation of our method on two different referential games, and show that our agents outperform all prior work when communicating with seen partners and humans. Furthermore, we analyze the natural language generation skills of our agents, where we find that our agents also outperform strong baselines. Finally, we test the robustness of our agents when communicating with out-of-population agents and carefully test the importance of each component of our method through ablation studies.
Multi-Agent Training beyond Zero-Sum with Correlated Equilibrium Meta-Solvers
Jun 22, 2021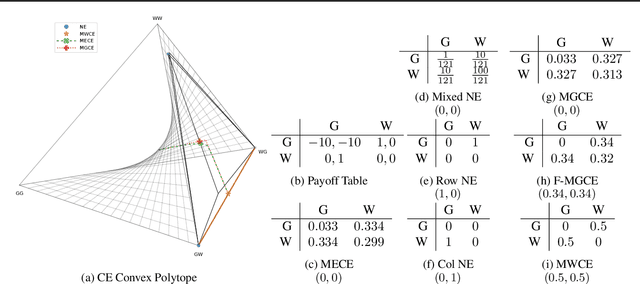
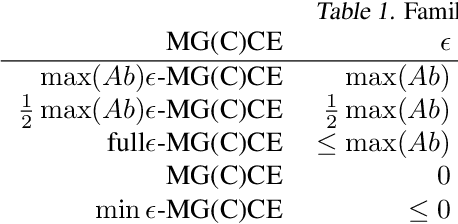
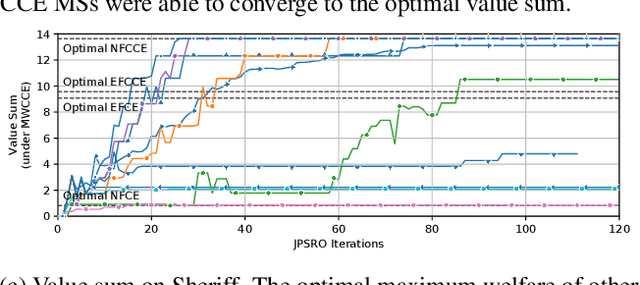
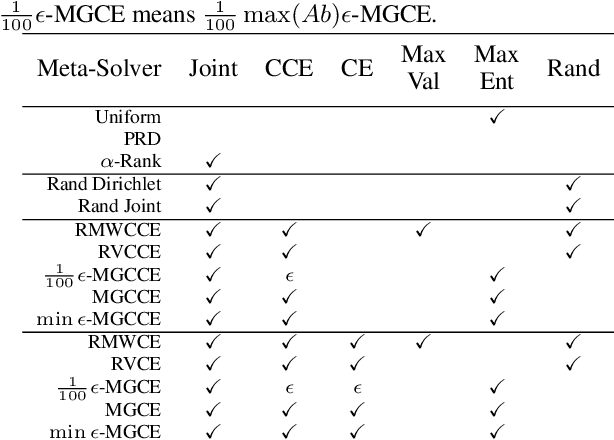
Two-player, constant-sum games are well studied in the literature, but there has been limited progress outside of this setting. We propose Joint Policy-Space Response Oracles (JPSRO), an algorithm for training agents in n-player, general-sum extensive form games, which provably converges to an equilibrium. We further suggest correlated equilibria (CE) as promising meta-solvers, and propose a novel solution concept Maximum Gini Correlated Equilibrium (MGCE), a principled and computationally efficient family of solutions for solving the correlated equilibrium selection problem. We conduct several experiments using CE meta-solvers for JPSRO and demonstrate convergence on n-player, general-sum games.
Efficient Deviation Types and Learning for Hindsight Rationality in Extensive-Form Games
Feb 13, 2021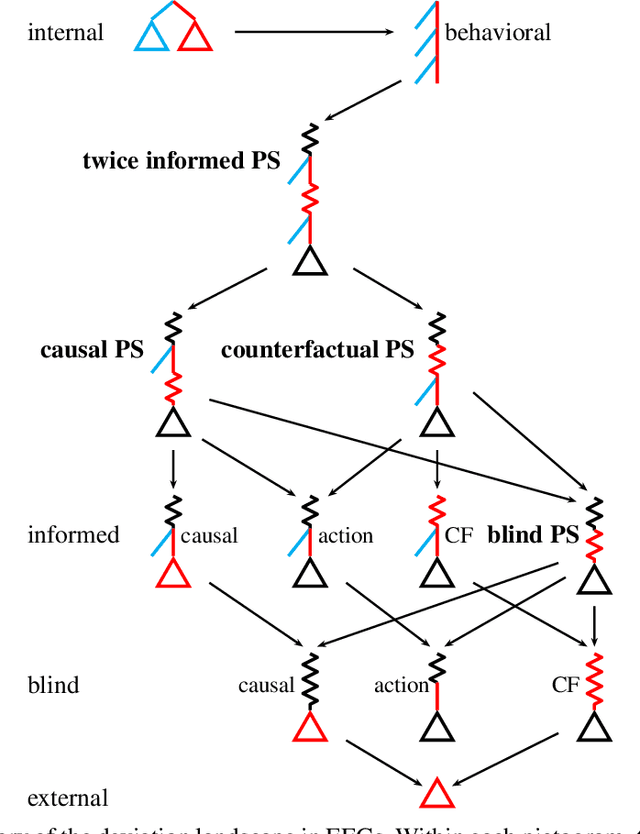

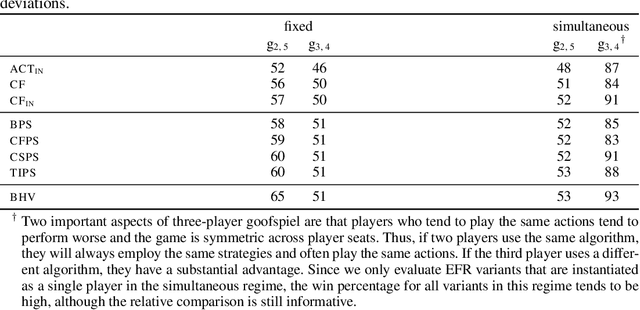
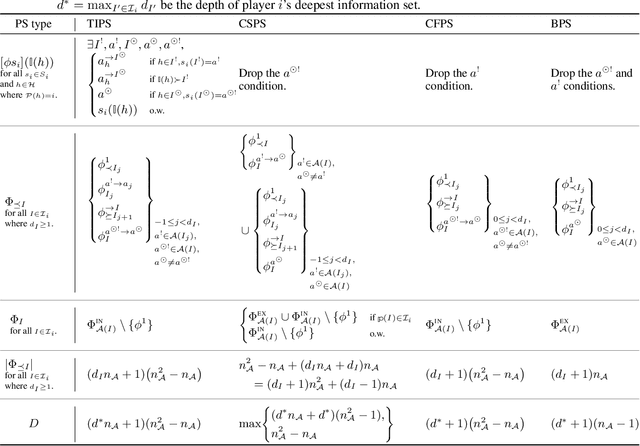
Hindsight rationality is an approach to playing multi-agent, general-sum games that prescribes no-regret learning dynamics and describes jointly rational behavior with mediated equilibria. We explore the space of deviation types in extensive-form games (EFGs) and discover powerful types that are efficient to compute in games with moderate lengths. Specifically, we identify four new types of deviations that subsume previously studied types within a broader class we call partial sequence deviations. Integrating the idea of time selection regret minimization into counterfactual regret minimization (CFR), we introduce the extensive-form regret minimization (EFR) algorithm that is hindsight rational for a general and natural class of deviations in EFGs. We provide instantiations and regret bounds for EFR that correspond to each partial sequence deviation type. In addition, we present a thorough empirical analysis of EFR's performance with different deviation types in common benchmark games. As theory suggests, instantiating EFR with stronger deviations leads to behavior that tends to outperform that of weaker deviations.
Solving Common-Payoff Games with Approximate Policy Iteration
Jan 11, 2021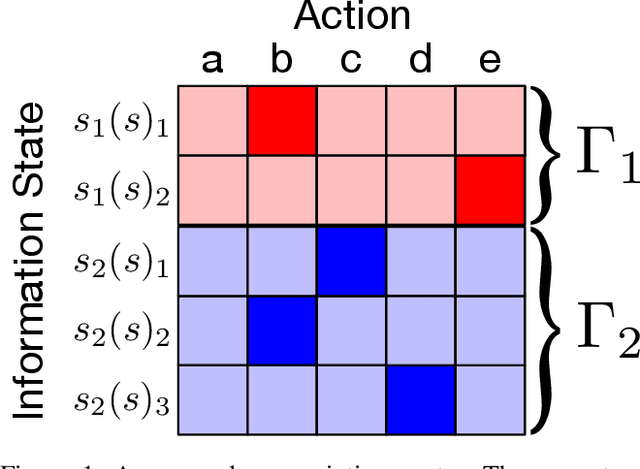
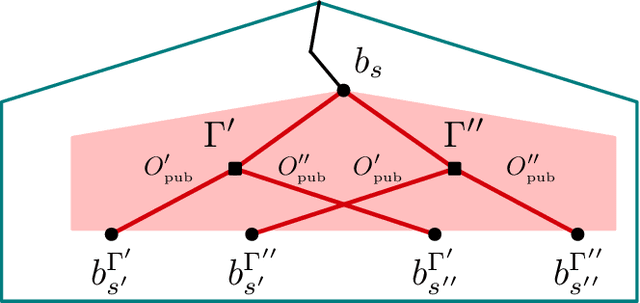
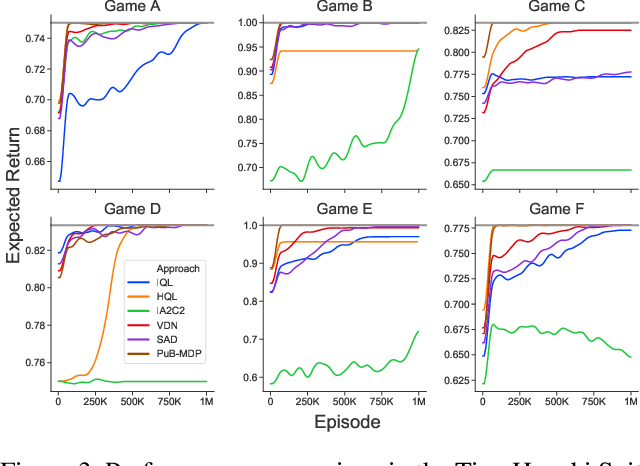
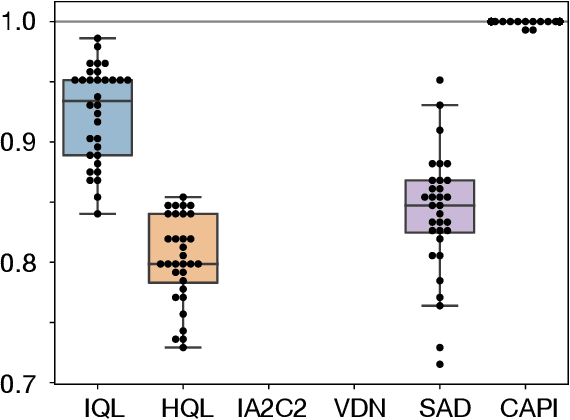
For artificially intelligent learning systems to have widespread applicability in real-world settings, it is important that they be able to operate decentrally. Unfortunately, decentralized control is difficult -- computing even an epsilon-optimal joint policy is a NEXP complete problem. Nevertheless, a recently rediscovered insight -- that a team of agents can coordinate via common knowledge -- has given rise to algorithms capable of finding optimal joint policies in small common-payoff games. The Bayesian action decoder (BAD) leverages this insight and deep reinforcement learning to scale to games as large as two-player Hanabi. However, the approximations it uses to do so prevent it from discovering optimal joint policies even in games small enough to brute force optimal solutions. This work proposes CAPI, a novel algorithm which, like BAD, combines common knowledge with deep reinforcement learning. However, unlike BAD, CAPI prioritizes the propensity to discover optimal joint policies over scalability. While this choice precludes CAPI from scaling to games as large as Hanabi, empirical results demonstrate that, on the games to which CAPI does scale, it is capable of discovering optimal joint policies even when other modern multi-agent reinforcement learning algorithms are unable to do so. Code is available at https://github.com/ssokota/capi .
Hindsight and Sequential Rationality of Correlated Play
Dec 17, 2020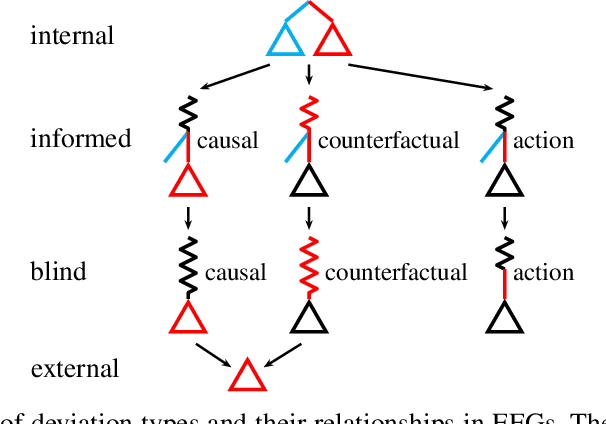
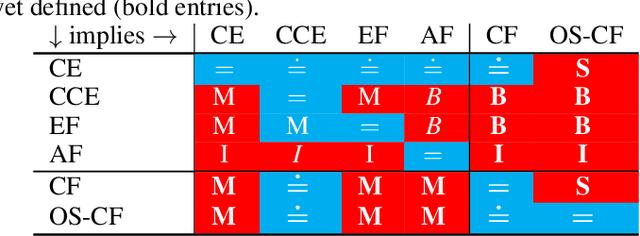
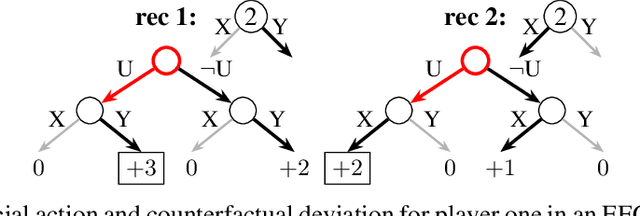
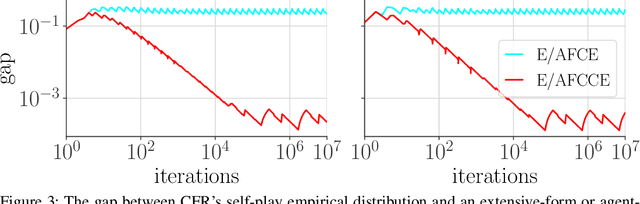
Driven by recent successes in two-player, zero-sum game solving and playing, artificial intelligence work on games has increasingly focused on algorithms that produce equilibrium-based strategies. However, this approach has been less effective at producing competent players in general-sum games or those with more than two players than in two-player, zero-sum games. An appealing alternative is to consider adaptive algorithms that ensure strong performance in hindsight relative to what could have been achieved with modified behavior. This approach also leads to a game-theoretic analysis, but in the correlated play that arises from joint learning dynamics rather than factored agent behavior at equilibrium. We develop and advocate for this hindsight rationality framing of learning in general sequential decision-making settings. To this end, we re-examine mediated equilibrium and deviation types in extensive-form games, thereby gaining a more complete understanding and resolving past misconceptions. We present a set of examples illustrating the distinct strengths and weaknesses of each type of equilibrium in the literature, and prove that no tractable concept subsumes all others. This line of inquiry culminates in the definition of the deviation and equilibrium classes that correspond to algorithms in the counterfactual regret minimization (CFR) family, relating them to all others in the literature. Examining CFR in greater detail further leads to a new recursive definition of rationality in correlated play that extends sequential rationality in a way that naturally applies to hindsight evaluation.
Negotiating Team Formation Using Deep Reinforcement Learning
Oct 20, 2020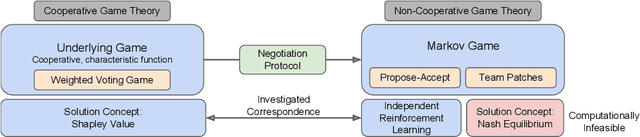
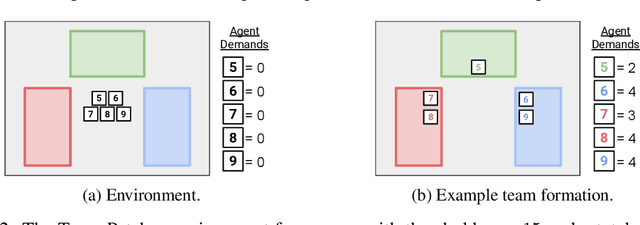
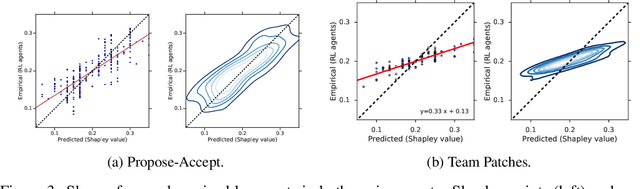
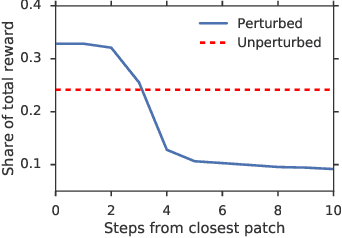
When autonomous agents interact in the same environment, they must often cooperate to achieve their goals. One way for agents to cooperate effectively is to form a team, make a binding agreement on a joint plan, and execute it. However, when agents are self-interested, the gains from team formation must be allocated appropriately to incentivize agreement. Various approaches for multi-agent negotiation have been proposed, but typically only work for particular negotiation protocols. More general methods usually require human input or domain-specific data, and so do not scale. To address this, we propose a framework for training agents to negotiate and form teams using deep reinforcement learning. Importantly, our method makes no assumptions about the specific negotiation protocol, and is instead completely experience driven. We evaluate our approach on both non-spatial and spatially extended team-formation negotiation environments, demonstrating that our agents beat hand-crafted bots and reach negotiation outcomes consistent with fair solutions predicted by cooperative game theory. Additionally, we investigate how the physical location of agents influences negotiation outcomes.
The Advantage Regret-Matching Actor-Critic
Aug 27, 2020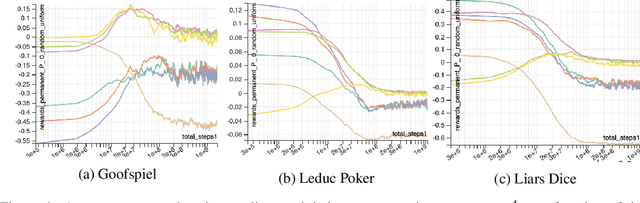
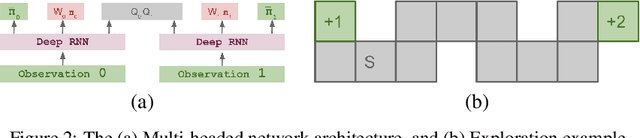
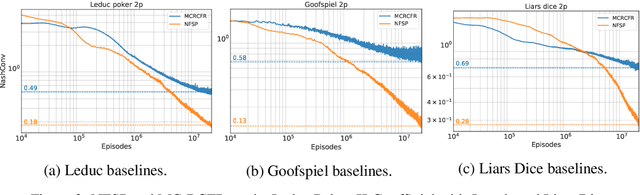
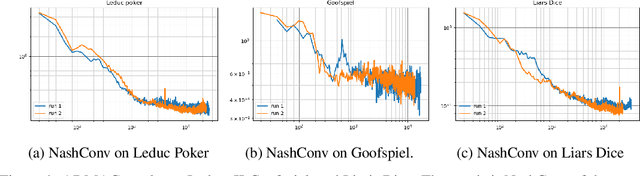
Regret minimization has played a key role in online learning, equilibrium computation in games, and reinforcement learning (RL). In this paper, we describe a general model-free RL method for no-regret learning based on repeated reconsideration of past behavior. We propose a model-free RL algorithm, the AdvantageRegret-Matching Actor-Critic (ARMAC): rather than saving past state-action data, ARMAC saves a buffer of past policies, replaying through them to reconstruct hindsight assessments of past behavior. These retrospective value estimates are used to predict conditional advantages which, combined with regret matching, produces a new policy. In particular, ARMAC learns from sampled trajectories in a centralized training setting, without requiring the application of importance sampling commonly used in Monte Carlo counterfactual regret (CFR) minimization; hence, it does not suffer from excessive variance in large environments. In the single-agent setting, ARMAC shows an interesting form of exploration by keeping past policies intact. In the multiagent setting, ARMAC in self-play approaches Nash equilibria on some partially-observable zero-sum benchmarks. We provide exploitability estimates in the significantly larger game of betting-abstracted no-limit Texas Hold'em.