 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero Collapse: A Failure Mode of Policy Gradient Methods in Discontinuous Reward Environments
May 29, 2026Bidding in repeated auctions is a central challenge for reinforcement learning (RL), combining continuous control with the strategic complexities of digital advertising. While policy gradient and value-based methods seem well-suited for these settings, they often struggle with the discontinuous, "cliff-like" nature of auction reward landscapes. In a first-price auction, for example, a bidder receives zero reward until they cross a specific threshold, after which the reward decreases as the bid increases. This creates a landscape of flat, zero-reward regions separated by sharp boundaries. We identify a fundamental failure mode in this setting termed "zero collapse." We show that stochastic exploration and gradient-based updates can cause policies to overshoot optimal high-reward regions and enter flat, zero-reward regimes. Once there, the lack of an informative gradient signal makes recovery extremely sample-inefficient, effectively trapping the agent. We find that actor-critic methods are particularly susceptible, as biased value estimates can accelerate this movement toward unstable regions. Our contributions include: (1) a mechanistic explanation of how discontinuous rewards lead to vanishing signals and zero collapse; (2) an analysis of the interaction between policy stochasticity and step size; and (3) an empirical demonstration of this phenomenon across REINFORCE and actor-critic variants. We propose practical mitigation strategies involving initialization and architectural choices to improve stability. Finally, we introduce a formal RL framework for auction environments highlighting their unique structural properties.
Distilling Game Code World Model Generation into Lightweight Large Language Models
May 23, 2026Large Language Models (LLMs) have shown great ability in generating executable code from natural language, opening the possibility of automatically constructing environments for AI agents. Recent work on Code World Models (CWMs) demonstrates that LLMs can translate game rules into Python implementations compatible with solvers like Monte Carlo Tree Search. We study this problem in game settings, where generated environments must implement rules, legal actions, state transitions, observations, and rewards. We refer to these game-specific executable models as Game Code World Models (GameCWMs). However, current approaches to generating code world models rely on frontier models and inference-time refinement loops, limiting accessibility and scalability. This work investigates whether GameCWM generation capabilities can be distilled into smaller models through post-training. We introduce: (1) a curated dataset of 30 games spanning perfect and imperfect information games, (2) a verification framework that evaluates generated code against structural and semantic game properties, and (3) a post-training pipeline combining Supervised Fine-Tuning (SFT) with Reinforcement Learning with Verifiable Rewards (RLVR). We experiment with Qwen2.5-3B-Instruct and find that SFT can increase syntactic correctness, while RLVR can improve execution-level adherence to game rules, thereby improving Qwen's ability to generate valid GameCWMs in both perfect and imperfect information games. Overall, our pipeline makes Qwen2.5-3B-Instruct more capable of generating valid GameCWMs, thereby offering a scalable path toward automatic environment generation from natural language.
TempusBench: An Evaluation Framework for Time-Series Forecasting
Apr 13, 2026Foundation models have transformed natural language processing and computer vision, and a rapidly growing literature on time-series foundation models (TSFMs) seeks to replicate this success in forecasting. While recent open-source models demonstrate the promise of TSFMs, the field lacks a comprehensive and community-accepted model evaluation framework. We see at least four major issues impeding progress on the development of such a framework. First, current evaluation frameworks consist of benchmark forecasting tasks derived from often outdated datasets (e.g., M3), many of which lack clear metadata and overlap with the corpora used to pre-train TSFMs. Second, existing frameworks evaluate models along a narrowly defined set of benchmark forecasting tasks such as forecast horizon length or domain, but overlook core statistical properties such as non-stationarity and seasonality. Third, domain-specific models (e.g., XGBoost) are often compared unfairly, as existing frameworks neglect a systematic and consistent hyperparameter tuning convention for all models. Fourth, visualization tools for interpreting comparative performance are lacking. To address these issues, we introduce TempusBench, an open-source evaluation framework for TSFMs. TempusBench consists of 1) new datasets which are not included in existing TSFM pretraining corpora, 2) a set of novel benchmark tasks that go beyond existing ones, 3) a model evaluation pipeline with a standardized hyperparameter tuning protocol, and 4) a tensorboard-based visualization interface. We provide access to our code on GitHub: https://github.com/Smlcrm/TempusBench.
Spectral Collapse Drives Loss of Plasticity in Deep Continual Learning
Sep 26, 2025

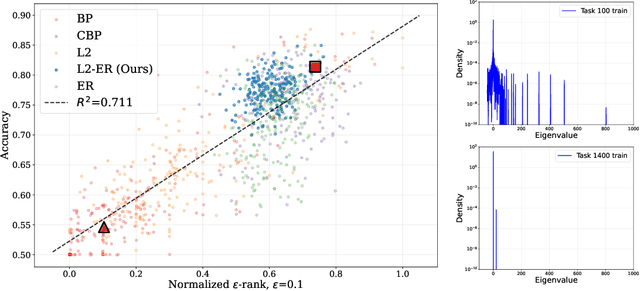

We investigate why deep neural networks suffer from \emph{loss of plasticity} in deep continual learning, failing to learn new tasks without reinitializing parameters. We show that this failure is preceded by Hessian spectral collapse at new-task initialization, where meaningful curvature directions vanish and gradient descent becomes ineffective. To characterize the necessary condition for successful training, we introduce the notion of $\tau$-trainability and show that current plasticity preserving algorithms can be unified under this framework. Targeting spectral collapse directly, we then discuss the Kronecker factored approximation of the Hessian, which motivates two regularization enhancements: maintaining high effective feature rank and applying $L2$ penalties. Experiments on continual supervised and reinforcement learning tasks confirm that combining these two regularizers effectively preserves plasticity.
Bi-Level Policy Optimization with Nyström Hypergradients
May 16, 2025The dependency of the actor on the critic in actor-critic (AC) reinforcement learning means that AC can be characterized as a bilevel optimization (BLO) problem, also called a Stackelberg game. This characterization motivates two modifications to vanilla AC algorithms. First, the critic's update should be nested to learn a best response to the actor's policy. Second, the actor should update according to a hypergradient that takes changes in the critic's behavior into account. Computing this hypergradient involves finding an inverse Hessian vector product, a process that can be numerically unstable. We thus propose a new algorithm, Bilevel Policy Optimization with Nystr\"om Hypergradients (BLPO), which uses nesting to account for the nested structure of BLO, and leverages the Nystr\"om method to compute the hypergradient. Theoretically, we prove BLPO converges to (a point that satisfies the necessary conditions for) a local strong Stackelberg equilibrium in polynomial time with high probability, assuming a linear parametrization of the critic's objective. Empirically, we demonstrate that BLPO performs on par with or better than PPO on a variety of discrete and continuous control tasks.
Efficient Inverse Multiagent Learning
Feb 20, 2025

In this paper, we study inverse game theory (resp. inverse multiagent learning) in which the goal is to find parameters of a game's payoff functions for which the expected (resp. sampled) behavior is an equilibrium. We formulate these problems as generative-adversarial (i.e., min-max) optimization problems, for which we develop polynomial-time algorithms to solve, the former of which relies on an exact first-order oracle, and the latter, a stochastic one. We extend our approach to solve inverse multiagent simulacral learning in polynomial time and number of samples. In these problems, we seek a simulacrum, meaning parameters and an associated equilibrium that replicate the given observations in expectation. We find that our approach outperforms the widely-used ARIMA method in predicting prices in Spanish electricity markets based on time-series data.
A Unifying View of Linear Function Approximation in Off-Policy RL Through Matrix Splitting and Preconditioning
Jan 03, 2025Traditionally, TD and FQI are viewed as differing in the number of updates toward the target value function: TD makes one update, FQI makes an infinite number, and Partial Fitted Q-Iteration (PFQI) performs a finite number, such as the use of a target network in Deep Q-Networks (DQN) in the OPE setting. This perspective, however, fails to capture the convergence connections between these algorithms and may lead to incorrect conclusions, for example, that the convergence of TD implies the convergence of FQI. In this paper, we focus on linear value function approximation and offer a new perspective, unifying TD, FQI, and PFQI as the same iterative method for solving the Least Squares Temporal Difference (LSTD) system, but using different preconditioners and matrix splitting schemes. TD uses a constant preconditioner, FQI employs a data-feature adaptive preconditioner, and PFQI transitions between the two. Then, we reveal that in the context of linear function approximation, increasing the number of updates under the same target value function essentially represents a transition from using a constant preconditioner to data-feature adaptive preconditioner. This unifying perspective also simplifies the analyses of the convergence conditions for these algorithms and clarifies many issues. Consequently, we fully characterize the convergence of each algorithm without assuming specific properties of the chosen features (e.g., linear independence). We also examine how common assumptions about feature representations affect convergence, and discover new conditions on features that are important for convergence. These convergence conditions allow us to establish the convergence connections between these algorithms and to address important questions.
Interpolating Between Softmax Policy Gradient and Neural Replicator Dynamics with Capped Implicit Exploration
Jun 04, 2022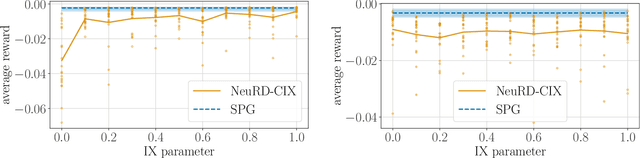
Neural replicator dynamics (NeuRD) is an alternative to the foundational softmax policy gradient (SPG) algorithm motivated by online learning and evolutionary game theory. The NeuRD expected update is designed to be nearly identical to that of SPG, however, we show that the Monte Carlo updates differ in a substantial way: the importance correction accounting for a sampled action is nullified in the SPG update, but not in the NeuRD update. Naturally, this causes the NeuRD update to have higher variance than its SPG counterpart. Building on implicit exploration algorithms in the adversarial bandit setting, we introduce capped implicit exploration (CIX) estimates that allow us to construct NeuRD-CIX, which interpolates between this aspect of NeuRD and SPG. We show how CIX estimates can be used in a black-box reduction to construct bandit algorithms with regret bounds that hold with high probability and the benefits this entails for NeuRD-CIX in sequential decision-making settings. Our analysis reveals a bias--variance tradeoff between SPG and NeuRD, and shows how theory predicts that NeuRD-CIX will perform well more consistently than NeuRD while retaining NeuRD's advantages over SPG in non-stationary environments.
Robust No-Regret Learning in Min-Max Stackelberg Games
Apr 13, 2022
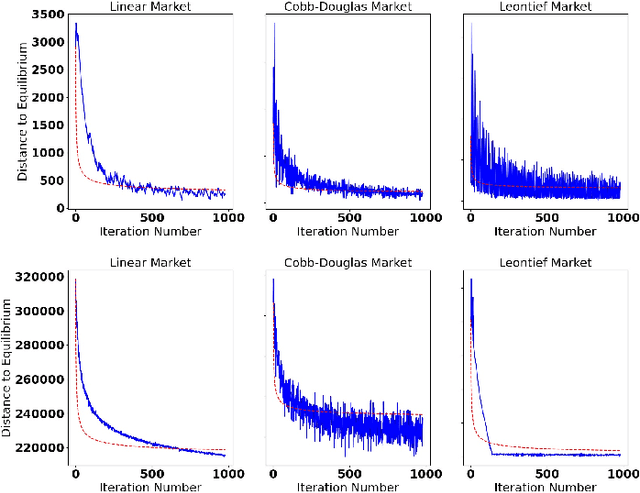
The behavior of no-regret learning algorithms is well understood in two-player min-max (i.e, zero-sum) games. In this paper, we investigate the behavior of no-regret learning in min-max games with dependent strategy sets, where the strategy of the first player constrains the behavior of the second. Such games are best understood as sequential, i.e., min-max Stackelberg, games. We consider two settings, one in which only the first player chooses their actions using a no-regret algorithm while the second player best responds, and one in which both players use no-regret algorithms. For the former case, we show that no-regret dynamics converge to a Stackelberg equilibrium. For the latter case, we introduce a new type of regret, which we call Lagrangian regret, and show that if both players minimize their Lagrangian regrets, then play converges to a Stackelberg equilibrium. We then observe that online mirror descent (OMD) dynamics in these two settings correspond respectively to a known nested (i.e., sequential) gradient descent-ascent (GDA) algorithm and a new simultaneous GDA-like algorithm, thereby establishing convergence of these algorithms to Stackelberg equilibrium. Finally, we analyze the robustness of OMD dynamics to perturbations by investigating online min-max Stackelberg games. We prove that OMD dynamics are robust for a large class of online min-max games with independent strategy sets. In the dependent case, we demonstrate the robustness of OMD dynamics experimentally by simulating them in online Fisher markets, a canonical example of a min-max Stackelberg game with dependent strategy sets.
Convex-Concave Min-Max Stackelberg Games
Oct 05, 2021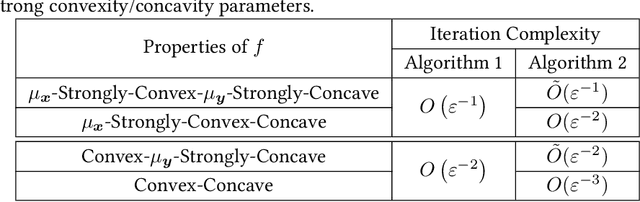
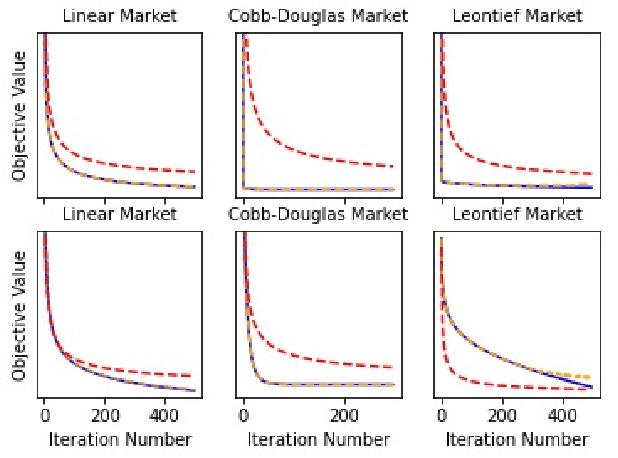

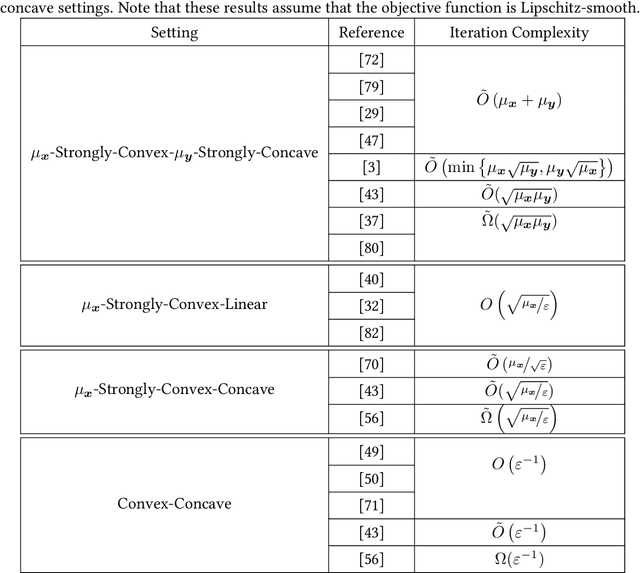
Min-max optimization problems (i.e., min-max games) have been attracting a great deal of attention because of their applicability to a wide range of machine learning problems. Although significant progress has been made recently, the literature to date has focused on games with independent strategy sets; little is known about solving games with dependent strategy sets, which can be characterized as min-max Stackelberg games. We introduce two first-order methods that solve a large class of convex-concave min-max Stackelberg games, and show that our methods converge in polynomial time. Min-max Stackelberg games were first studied by Wald, under the posthumous name of Wald's maximin model, a variant of which is the main paradigm used in robust optimization, which means that our methods can likewise solve many convex robust optimization problems. We observe that the computation of competitive equilibria in Fisher markets also comprises a min-max Stackelberg game. Further, we demonstrate the efficacy and efficiency of our algorithms in practice by computing competitive equilibria in Fisher markets with varying utility structures. Our experiments suggest potential ways to extend our theoretical results, by demonstrating how different smoothness properties can affect the convergence rate of our algorithms.