 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchor & Transform: Learning Sparse Representations of Discrete Objects
Mar 18, 2020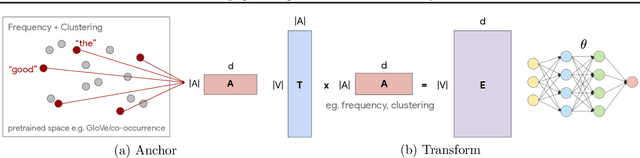
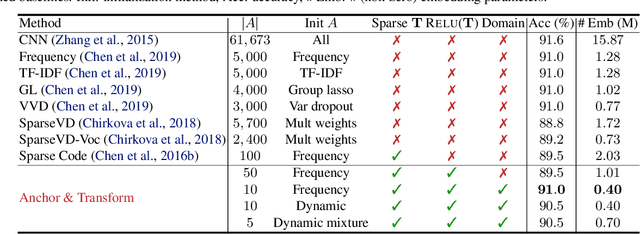

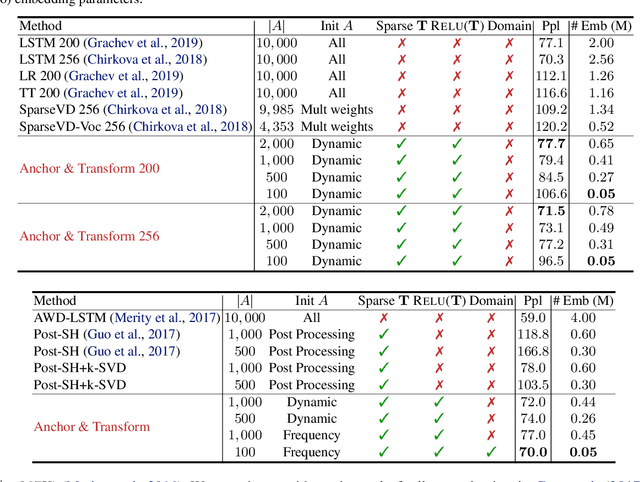
Learning continuous representations of discrete objects such as text, users, and URLs lies at the heart of many applications including language and user modeling. When using discrete objects as input to neural networks, we often ignore the underlying structures (e.g. natural groupings and similarities) and embed the objects independently into individual vectors. As a result, existing methods do not scale to large vocabulary sizes. In this paper, we design a Bayesian nonparametric prior for embeddings that encourages sparsity and leverages natural groupings among objects. We derive an approximate inference algorithm based on Small Variance Asymptotics which yields a simple and natural algorithm for learning a small set of anchor embeddings and a sparse transformation matrix. We call our method Anchor & Transform (ANT) as the embeddings of discrete objects are a sparse linear combination of the anchors, weighted according to the transformation matrix. ANT is scalable, flexible, end-to-end trainable, and allows the user to incorporate domain knowledge about object relationships. On text classification and language modeling benchmarks, ANT demonstrates stronger performance with fewer parameters as compared to existing compression baselines.
Adaptive Federated Optimization
Feb 29, 2020
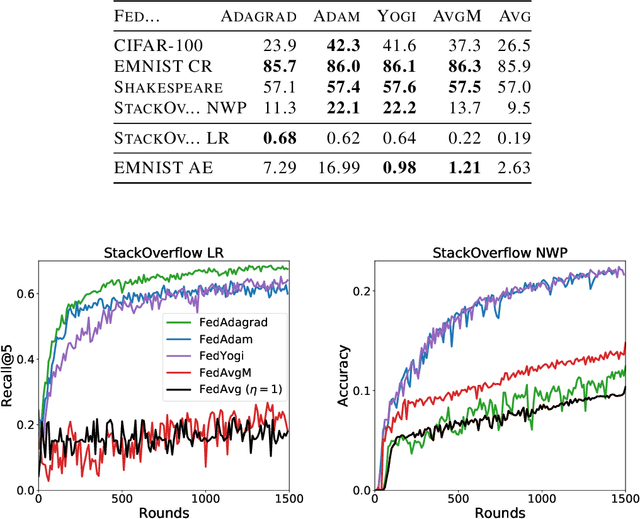
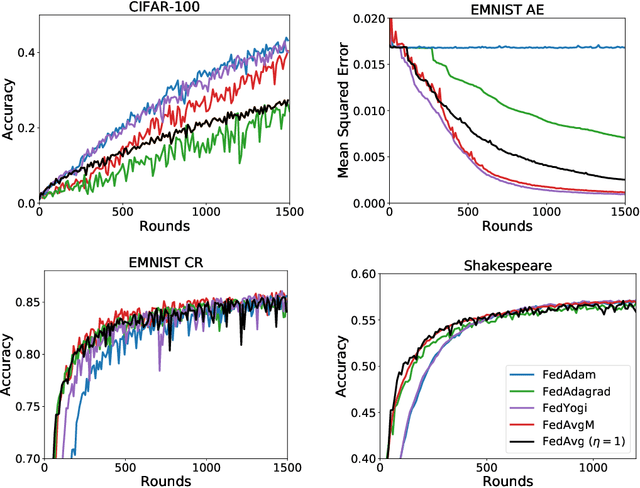
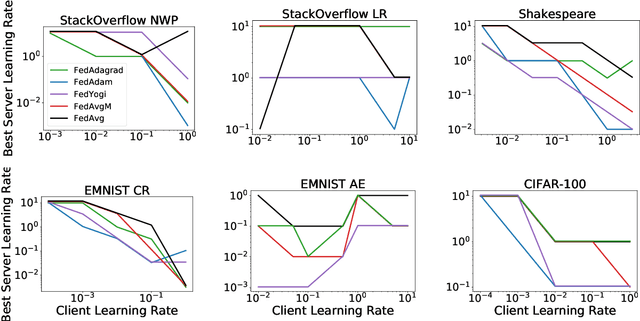
Federated learning is a distributed machine learning paradigm in which a large number of clients coordinate with a central server to learn a model without sharing their own training data. Due to the heterogeneity of the client datasets, standard federated optimization methods such as Federated Averaging (FedAvg) are often difficult to tune and exhibit unfavorable convergence behavior. In non-federated settings, adaptive optimization methods have had notable success in combating such issues. In this work, we propose federated versions of adaptive optimizers, including Adagrad, Adam, and Yogi, and analyze their convergence in the presence of heterogeneous data for general nonconvex settings. Our results highlight the interplay between client heterogeneity and communication efficiency. We also perform extensive experiments on these methods and show that the use of adaptive optimizers can significantly improve the performance of federated learning.
Towards Modular Algorithm Induction
Feb 27, 2020
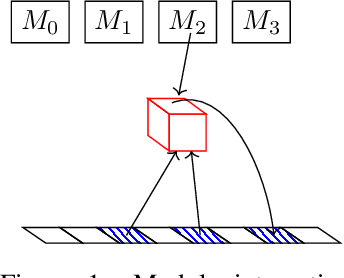
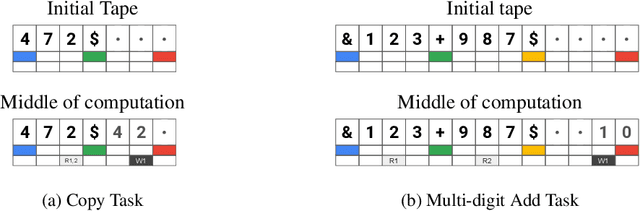
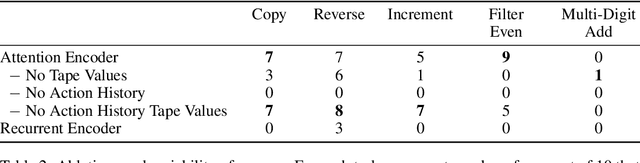
We present a modular neural network architecture Main that learns algorithms given a set of input-output examples. Main consists of a neural controller that interacts with a variable-length input tape and learns to compose modules together with their corresponding argument choices. Unlike previous approaches, Main uses a general domain-agnostic mechanism for selection of modules and their arguments. It uses a general input tape layout together with a parallel history tape to indicate most recently used locations. Finally, it uses a memoryless controller with a length-invariant self-attention based input tape encoding to allow for random access to tape locations. The Main architecture is trained end-to-end using reinforcement learning from a set of input-output examples. We evaluate Main on five algorithmic tasks and show that it can learn policies that generalizes perfectly to inputs of much longer lengths than the ones used for training.
Differentiable Reasoning over a Virtual Knowledge Base
Feb 25, 2020
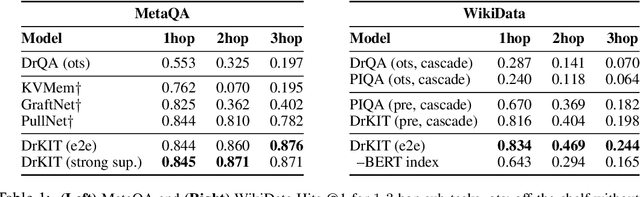
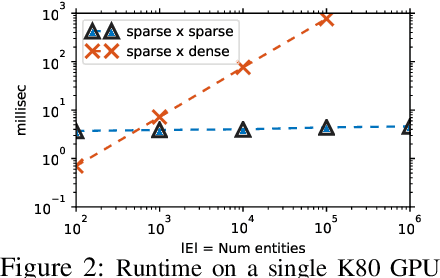
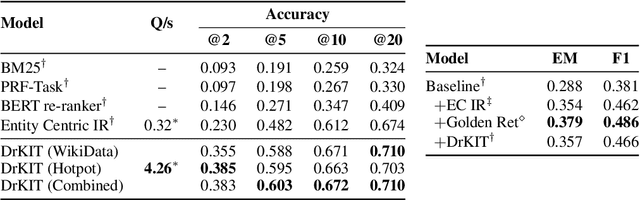
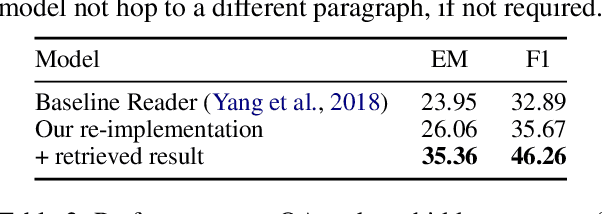
We consider the task of answering complex multi-hop questions using a corpus as a virtual knowledge base (KB). In particular, we describe a neural module, DrKIT, that traverses textual data like a KB, softly following paths of relations between mentions of entities in the corpus. At each step the module uses a combination of sparse-matrix TFIDF indices and a maximum inner product search (MIPS) on a special index of contextual representations of the mentions. This module is differentiable, so the full system can be trained end-to-end using gradient based methods, starting from natural language inputs. We also describe a pretraining scheme for the contextual representation encoder by generating hard negative examples using existing knowledge bases. We show that DrKIT improves accuracy by 9 points on 3-hop questions in the MetaQA dataset, cutting the gap between text-based and KB-based state-of-the-art by 70%. On HotpotQA, DrKIT leads to a 10% improvement over a BERT-based re-ranking approach to retrieving the relevant passages required to answer a question. DrKIT is also very efficient, processing 10-100x more queries per second than existing multi-hop systems.
Differentiable Bandit Exploration
Feb 17, 2020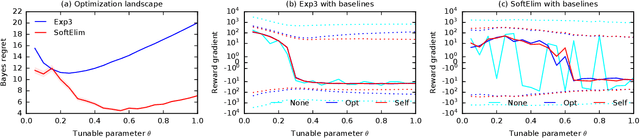
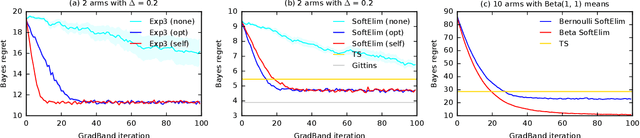
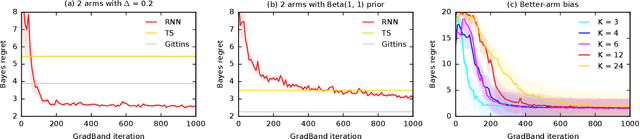
We learn bandit policies that maximize the average reward over bandit instances drawn from an unknown distribution $\mathcal{P}$, from a sample from $\mathcal{P}$. Our approach is an instance of meta-learning and its appeal is that the properties of $\mathcal{P}$ can be exploited without restricting it. We parameterize our policies in a differentiable way and optimize them by policy gradients - an approach that is easy to implement and pleasantly general. Then the challenge is to design effective gradient estimators and good policy classes. To make policy gradients practical, we introduce novel variance reduction techniques. We experiment with various bandit policy classes, including neural networks and a novel soft-elimination policy. The latter has regret guarantees and is a natural starting point for our optimization. Our experiments highlight the versatility of our approach. We also observe that neural network policies can learn implicit biases, which are only expressed through sampled bandit instances during training.
FedDANE: A Federated Newton-Type Method
Jan 07, 2020
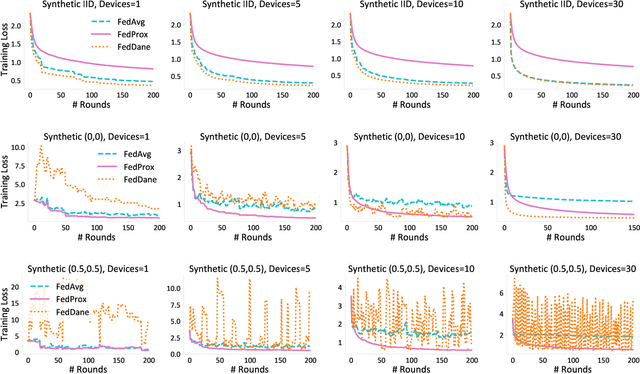
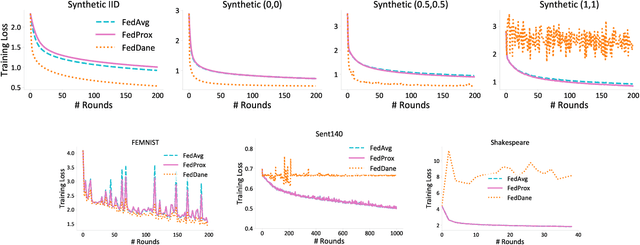
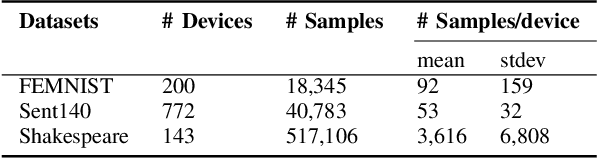
Federated learning aims to jointly learn statistical models over massively distributed remote devices. In this work, we propose FedDANE, an optimization method that we adapt from DANE, a method for classical distributed optimization, to handle the practical constraints of federated learning. We provide convergence guarantees for this method when learning over both convex and non-convex functions. Despite encouraging theoretical results, we find that the method has underwhelming performance empirically. In particular, through empirical simulations on both synthetic and real-world datasets, FedDANE consistently underperforms baselines of FedAvg and FedProx in realistic federated settings. We identify low device participation and statistical device heterogeneity as two underlying causes of this underwhelming performance, and conclude by suggesting several directions of future work.
Multi-step Entity-centric Information Retrieval for Multi-Hop Question Answering
Sep 17, 2019
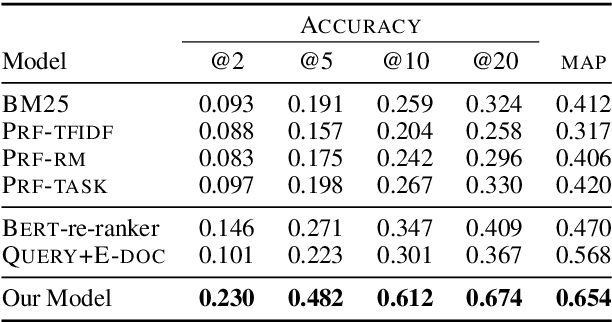
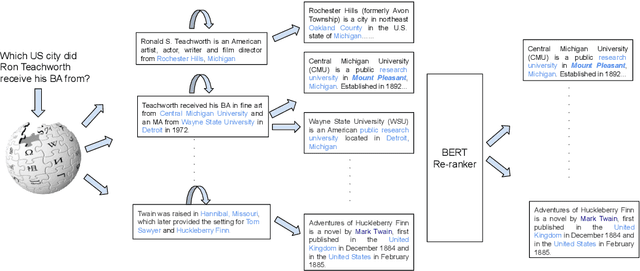
Multi-hop question answering (QA) requires an information retrieval (IR) system that can find \emph{multiple} supporting evidence needed to answer the question, making the retrieval process very challenging. This paper introduces an IR technique that uses information of entities present in the initially retrieved evidence to learn to `\emph{hop}' to other relevant evidence. In a setting, with more than \textbf{5 million} Wikipedia paragraphs, our approach leads to significant boost in retrieval performance. The retrieved evidence also increased the performance of an existing QA model (without any training) on the \hotpot benchmark by \textbf{10.59} F1.
Developing Creative AI to Generate Sculptural Objects
Aug 20, 2019

We explore the intersection of human and machine creativity by generating sculptural objects through machine learning. This research raises questions about both the technical details of automatic art generation and the interaction between AI and people, as both artists and the audience of art. We introduce two algorithms for generating 3D point clouds and then discuss their actualization as sculpture and incorporation into a holistic art installation. Specifically, the Amalgamated DeepDream (ADD) algorithm solves the sparsity problem caused by the naive DeepDream-inspired approach and generates creative and printable point clouds. The Partitioned DeepDream (PDD) algorithm further allows us to explore more diverse 3D object creation by combining point cloud clustering algorithms and ADD.
The Myths of Our Time: Fake News
Aug 05, 2019



While the purpose of most fake news is misinformation and political propaganda, our team sees it as a new type of myth that is created by people in the age of internet identities and artificial intelligence. Seeking insights on the fear and desire hidden underneath these modified or generated stories, we use machine learning methods to generate fake articles and present them in the form of an online news blog. This paper aims to share the details of our pipeline and the techniques used for full generation of fake news, from dataset collection to presentation as a media art project on the internet.
* 5 pages, 5 figures, in proceedings of International Symposium on Electronic Art 2019 (ISEA)
Randomized Exploration in Generalized Linear Bandits
Jun 21, 2019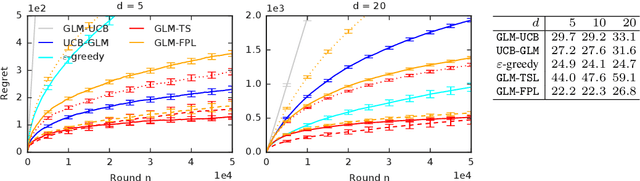
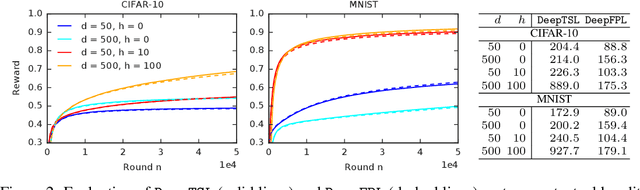
We study two randomized algorithms for generalized linear bandits, GLM-TSL and GLM-FPL. GLM-TSL samples a generalized linear model (GLM) from the Laplace approximation to the posterior distribution. GLM-FPL, a new algorithm proposed in this work, fits a GLM to a randomly perturbed history of past rewards. We prove a $\tilde{O}(d \sqrt{n} + d^2)$ upper bound on the $n$-round regret of GLM-TSL, where $d$ is the number of features. This is the first regret bound of a Thompson sampling-like algorithm in GLM bandits where the leading term is $\tilde{O}(d \sqrt{n})$. We apply both GLM-TSL and GLM-FPL to logistic and neural network bandits, and show that they perform well empirically. In more complex models, GLM-FPL is significantly faster. Our results showcase the role of randomization, beyond posterior sampling, in exploration.