 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fast Methane Detection Pipeline on Board Satellites Based on Mag1c-SAS and LinkNet
Jun 02, 2026Methane is a potent greenhouse gas, and detecting leaks early via hyperspectral satellite imagery can help climate change mitigation efforts. Meanwhile, many existing hyperspectral missions only capture areas manually targeted by operators, thus missing potential events of interest. To overcome slow downlink rates cost-effectively, onboard detection is a viable solution. However, traditional methane detection methods are too computationally demanding for resource-limited onboard hardware. This work accelerates methane detection by focusing on efficient, low-power algorithms. In particular, we test fast target detection ACE and CEM methods that have not been previously used for methane detection and propose Mag1c-SAS -- a significantly faster variant of the current state-of-the-art Mag1c algorithm. To explore their detection potential, we integrate them with a machine learning model based on U-Net and LinkNet. We evaluate our methods on the STARCOP dataset and a novel EMIT-MSeg dataset, which we introduce and open-source alongside a high-quality annotation strategy. The proposed Mag1c-SAS approach proves highly effective by operating ~80x faster than the original Mag1c approach, providing a visually similar, but noisier result. When additionally paired with the lightweight LinkNet approach, it effectively reduces noise, achieving AUPRC score improvements of over 30 pp on EMIT-MSeg compared to the baseline Mag1c approach, and an F1 score on STARCOP ~4 pp higher. We evaluate two novel band selection strategies and confirm the system's onboard viability through hardware profiling, demonstrating marginal power consumption and efficient CPU/RAM utilization. We release the final system in a user-friendly and lightweight PyPI library at: https://pypi.org/project/onboard-methane-detection/, alongside all experimental code, models, and data at: https://github.com/zaitra/methane-filters-benchmark.
Fully Automatic Trace Gas Plume Detection
May 05, 2026Future imaging spectrometers will increase data volumes by orders of magnitude, requiring automated detection of trace gas point sources. We present a fully automated framework that combines machine learning-based morphological analysis with physics-based spectroscopic fitting to detect plumes without human participation. Applied to EMIT imaging spectrometer data, the system operates in two modes: "daily digest" that runs automatically on all downlinked data, flagging the largest events for immediate response, and a retrospective analysis that identifies plumes missed by prior human review. The daily digest demonstrates that a significant fraction of the largest plumes can be detected automatically with negligible false positives, while retrospective analysis suggests at least 25% of plumes may have been overlooked. In addition to the previously observed methane point sources, we extend detection to three understudied trace gases: NH3, NO2 and the first observations of carbon monoxide (CO) plume in EMIT imagery.
Operational machine learning for remote spectroscopic detection of CH$_{4}$ point sources
Nov 11, 2025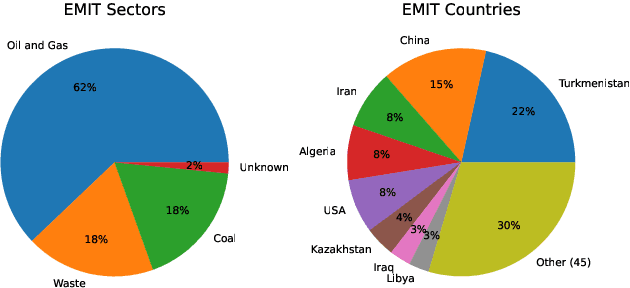
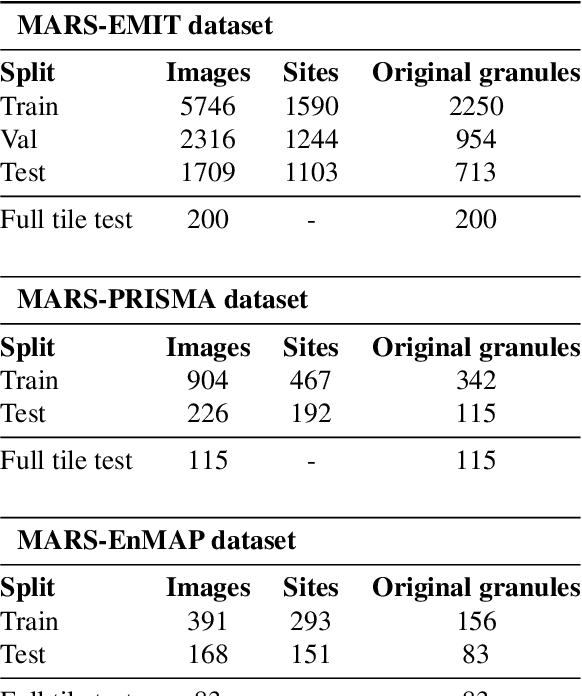
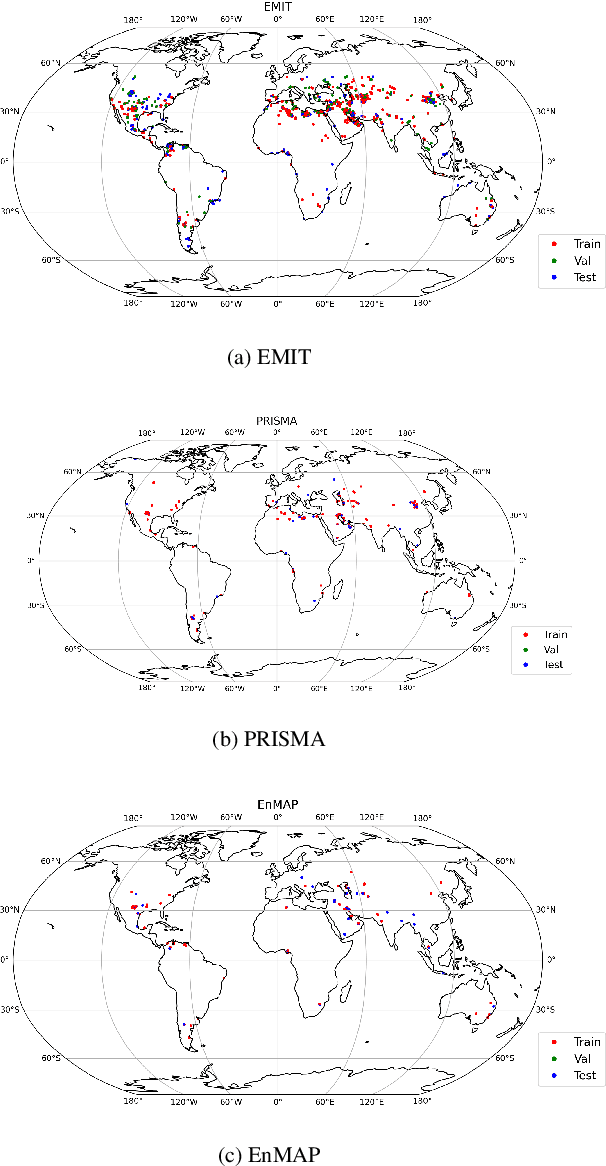
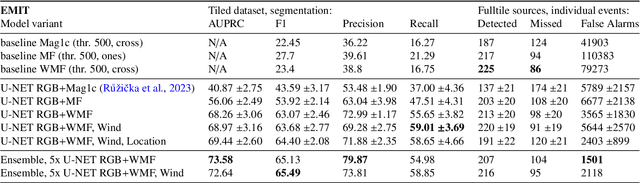
Mitigating anthropogenic methane sources is one the most cost-effective levers to slow down global warming. While satellite-based imaging spectrometers, such as EMIT, PRISMA, and EnMAP, can detect these point sources, current methane retrieval methods based on matched filters still produce a high number of false detections requiring laborious manual verification. This paper describes the operational deployment of a machine learning system for detecting methane emissions within the Methane Alert and Response System (MARS) of the United Nations Environment Programme's International Methane Emissions Observatory. We created the largest and most diverse global dataset of annotated methane plumes from three imaging spectrometer missions and quantitatively compared different deep learning model configurations. Focusing on the requirements for operational deployment, we extended prior evaluation methodologies from small tiled datasets to full granule evaluation. This revealed that deep learning models still produce a large number of false detections, a problem we address with model ensembling, which reduced false detections by over 74%. Deployed in the MARS pipeline, our system processes scenes and proposes plumes to analysts, accelerating the detection and analysis process. During seven months of operational deployment, it facilitated the verification of 1,351 distinct methane leaks, resulting in 479 stakeholder notifications. We further demonstrate the model's utility in verifying mitigation success through case studies in Libya, Argentina, Oman, and Azerbaijan. Our work represents a critical step towards a global AI-assisted methane leak detection system, which is required to process the dramatically higher data volumes expected from new and current imaging spectrometers.
Optimizing Methane Detection On Board Satellites: Speed, Accuracy, and Low-Power Solutions for Resource-Constrained Hardware
Jul 02, 2025Methane is a potent greenhouse gas, and detecting its leaks early via hyperspectral satellite imagery can help mitigate climate change. Meanwhile, many existing missions operate in manual tasking regimes only, thus missing potential events of interest. To overcome slow downlink rates cost-effectively, onboard detection is a viable solution. However, traditional methane enhancement methods are too computationally demanding for resource-limited onboard hardware. This work accelerates methane detection by focusing on efficient, low-power algorithms. We test fast target detection methods (ACE, CEM) that have not been previously used for methane detection and propose a Mag1c-SAS - a significantly faster variant of the current state-of-the-art algorithm for methane detection: Mag1c. To explore their true detection potential, we integrate them with a machine learning model (U-Net, LinkNet). Our results identify two promising candidates (Mag1c-SAS and CEM), both acceptably accurate for the detection of strong plumes and computationally efficient enough for onboard deployment: one optimized more for accuracy, the other more for speed, achieving up to ~100x and ~230x faster computation than original Mag1c on resource-limited hardware. Additionally, we propose and evaluate three band selection strategies. One of them can outperform the method traditionally used in the field while using fewer channels, leading to even faster processing without compromising accuracy. This research lays the foundation for future advancements in onboard methane detection with minimal hardware requirements, improving timely data delivery. The produced code, data, and models are open-sourced and can be accessed from https://github.com/zaitra/methane-filters-benchmark.
HyperspectralViTs: General Hyperspectral Models for On-board Remote Sensing
Oct 24, 2024



On-board processing of hyperspectral data with machine learning models would enable unprecedented amount of autonomy for a wide range of tasks, for example methane detection or mineral identification. This can enable early warning system and could allow new capabilities such as automated scheduling across constellations of satellites. Classical methods suffer from high false positive rates and previous deep learning models exhibit prohibitive computational requirements. We propose fast and accurate machine learning architectures which support end-to-end training with data of high spectral dimension without relying on hand-crafted products or spectral band compression preprocessing. We evaluate our models on two tasks related to hyperspectral data processing. With our proposed general architectures, we improve the F1 score of the previous methane detection state-of-the-art models by 27% on a newly created synthetic dataset and by 13% on the previously released large benchmark dataset. We also demonstrate that training models on the synthetic dataset improves performance of models finetuned on the dataset of real events by 6.9% in F1 score in contrast with training from scratch. On a newly created dataset for mineral identification, our models provide 3.5% improvement in the F1 score in contrast to the default versions of the models. With our proposed models we improve the inference speed by 85% in contrast to previous classical and deep learning approaches by removing the dependency on classically computed features. With our architecture, one capture from the EMIT sensor can be processed within 30 seconds on realistic proxy of the ION-SCV 004 satellite.
Fast model inference and training on-board of Satellites
Jul 17, 2023



Artificial intelligence onboard satellites has the potential to reduce data transmission requirements, enable real-time decision-making and collaboration within constellations. This study deploys a lightweight foundational model called RaVAEn on D-Orbit's ION SCV004 satellite. RaVAEn is a variational auto-encoder (VAE) that generates compressed latent vectors from small image tiles, enabling several downstream tasks. In this work we demonstrate the reliable use of RaVAEn onboard a satellite, achieving an encoding time of 0.110s for tiles of a 4.8x4.8 km$^2$ area. In addition, we showcase fast few-shot training onboard a satellite using the latent representation of data. We compare the deployment of the model on the on-board CPU and on the available Myriad vision processing unit (VPU) accelerator. To our knowledge, this work shows for the first time the deployment of a multi-task model on-board a CubeSat and the on-board training of a machine learning model.
Unsupervised Wildfire Change Detection based on Contrastive Learning
Nov 26, 2022



The accurate characterization of the severity of the wildfire event strongly contributes to the characterization of the fuel conditions in fire-prone areas, and provides valuable information for disaster response. The aim of this study is to develop an autonomous system built on top of high-resolution multispectral satellite imagery, with an advanced deep learning method for detecting burned area change. This work proposes an initial exploration of using an unsupervised model for feature extraction in wildfire scenarios. It is based on the contrastive learning technique SimCLR, which is trained to minimize the cosine distance between augmentations of images. The distance between encoded images can also be used for change detection. We propose changes to this method that allows it to be used for unsupervised burned area detection and following downstream tasks. We show that our proposed method outperforms the tested baseline approaches.
Tighter Variational Bounds are Not Necessarily Better. A Research Report on Implementation, Ablation Study, and Extensions
Sep 23, 2022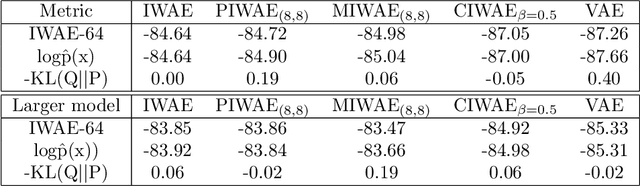
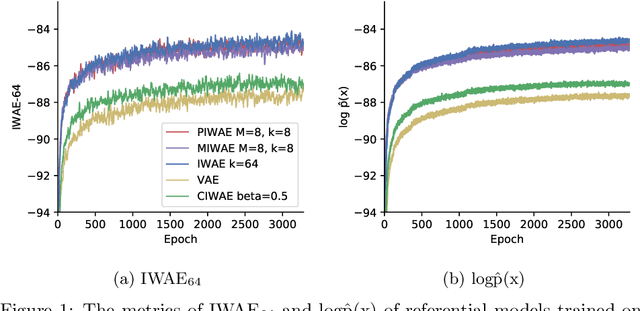
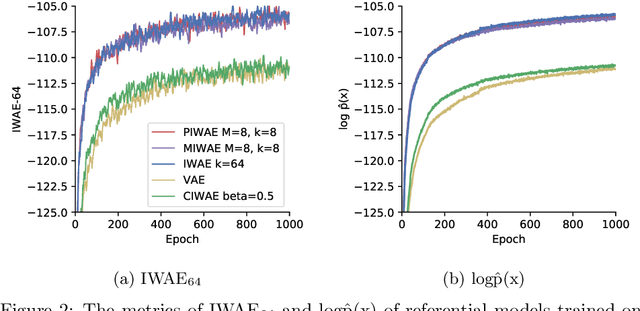

This report explains, implements and extends the works presented in "Tighter Variational Bounds are Not Necessarily Better" (T Rainforth et al., 2018). We provide theoretical and empirical evidence that increasing the number of importance samples $K$ in the importance weighted autoencoder (IWAE) (Burda et al., 2016) degrades the signal-to-noise ratio (SNR) of the gradient estimator in the inference network and thereby affecting the full learning process. In other words, even though increasing $K$ decreases the standard deviation of the gradients, it also reduces the magnitude of the true gradient faster, thereby increasing the relative variance of the gradient updates. Extensive experiments are performed to understand the importance of $K$. These experiments suggest that tighter variational bounds are beneficial for the generative network, whereas looser bounds are preferable for the inference network. With these insights, three methods are implemented and studied: the partially importance weighted autoencoder (PIWAE), the multiply importance weighted autoencoder (MIWAE) and the combination importance weighted autoencoder (CIWAE). Each of these three methods entails IWAE as a special case but employs the importance weights in different ways to ensure a higher SNR of the gradient estimators. In our research study and analysis, the efficacy of these algorithms is tested on multiple datasets such as MNIST and Omniglot. Finally, we demonstrate that the three presented IWAE variations are able to generate approximate posterior distributions that are much closer to the true posterior distribution than for the IWAE, while matching the performance of the IWAE generative network or potentially outperforming it in the case of PIWAE.
Unsupervised Change Detection of Extreme Events Using ML On-Board
Nov 04, 2021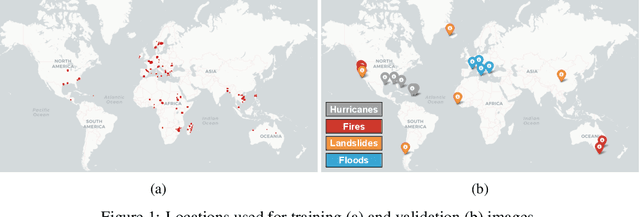
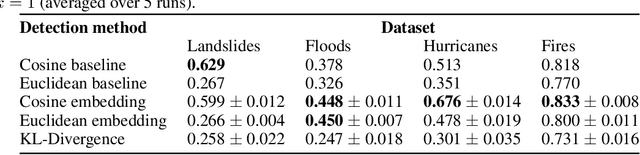

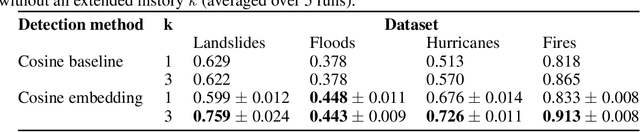
In this paper, we introduce RaVAEn, a lightweight, unsupervised approach for change detection in satellite data based on Variational Auto-Encoders (VAEs) with the specific purpose of on-board deployment. Applications such as disaster management enormously benefit from the rapid availability of satellite observations. Traditionally, data analysis is performed on the ground after all data is transferred - downlinked - to a ground station. Constraint on the downlink capabilities therefore affects any downstream application. In contrast, RaVAEn pre-processes the sampled data directly on the satellite and flags changed areas to prioritise for downlink, shortening the response time. We verified the efficacy of our system on a dataset composed of time series of catastrophic events - which we plan to release alongside this publication - demonstrating that RaVAEn outperforms pixel-wise baselines. Finally we tested our approach on resource-limited hardware for assessing computational and memory limitations.
Deep Active Learning in Remote Sensing for data efficient Change Detection
Aug 25, 2020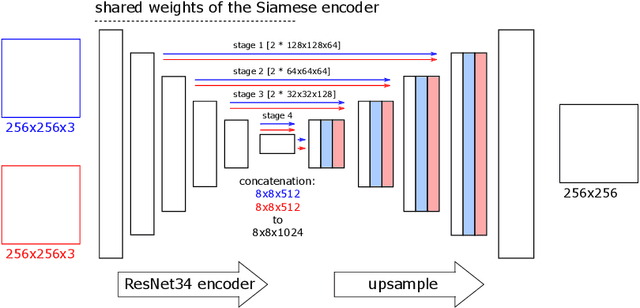


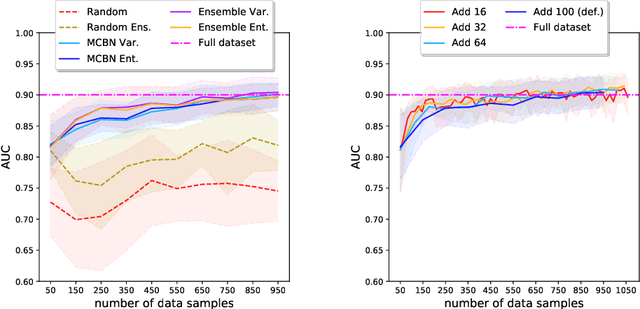
We investigate active learning in the context of deep neural network models for change detection and map updating. Active learning is a natural choice for a number of remote sensing tasks, including the detection of local surface changes: changes are on the one hand rare and on the other hand their appearance is varied and diffuse, making it hard to collect a representative training set in advance. In the active learning setting, one starts from a minimal set of training examples and progressively chooses informative samples that are annotated by a user and added to the training set. Hence, a core component of an active learning system is a mechanism to estimate model uncertainty, which is then used to pick uncertain, informative samples. We study different mechanisms to capture and quantify this uncertainty when working with deep networks, based on the variance or entropy across explicit or implicit model ensembles. We show that active learning successfully finds highly informative samples and automatically balances the training distribution, and reaches the same performance as a model supervised with a large, pre-annotated training set, with $\approx$99% fewer annotated samples.