 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThompson Sampling with a Mixture Prior
Jun 10, 2021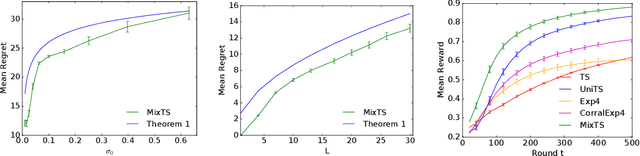
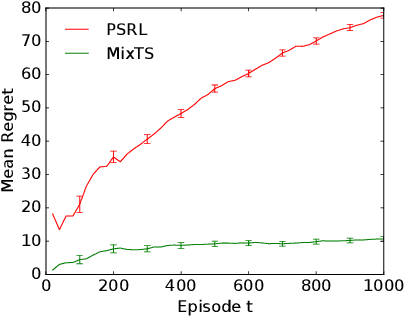
We study Thompson sampling (TS) in online decision-making problems where the uncertain environment is sampled from a mixture distribution. This is relevant to multi-task settings, where a learning agent is faced with different classes of problems. We incorporate this structure in a natural way by initializing TS with a mixture prior -- dubbed MixTS -- and develop a novel, general technique for analyzing the regret of TS with such priors. We apply this technique to derive Bayes regret bounds for MixTS in both linear bandits and tabular Markov decision processes (MDPs). Our regret bounds reflect the structure of the problem and depend on the number of components and confidence width of each component of the prior. Finally, we demonstrate the empirical effectiveness of MixTS in both synthetic and real-world experiments.
Case-based Reasoning for Natural Language Queries over Knowledge Bases
Apr 18, 2021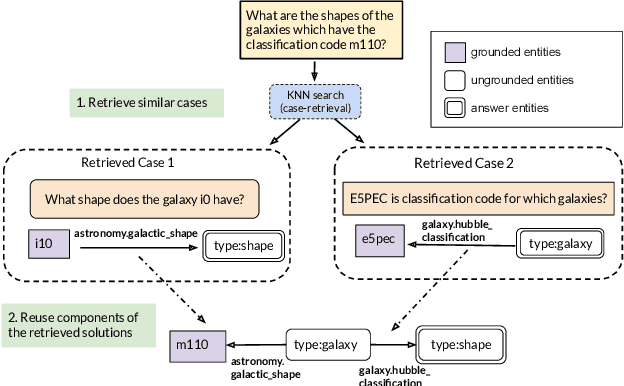
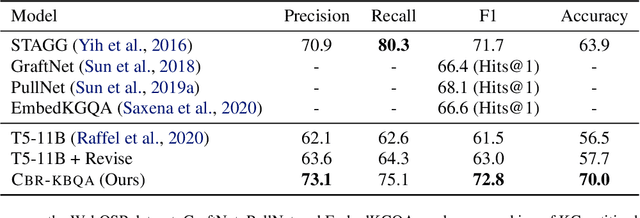
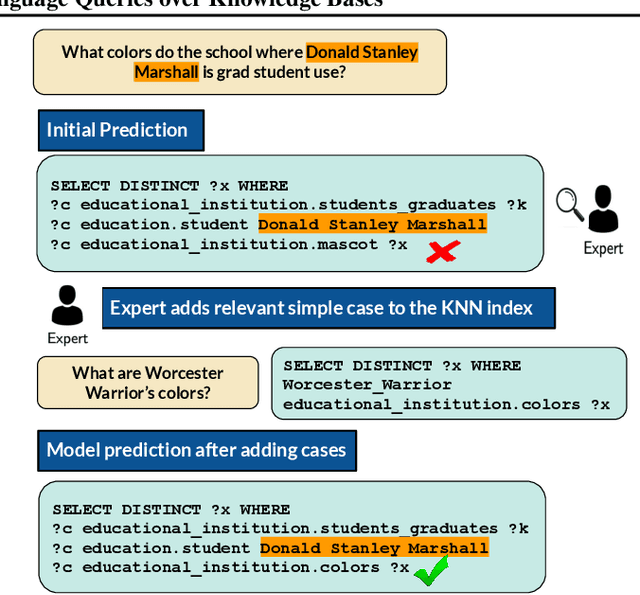
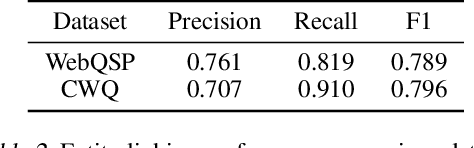
It is often challenging for a system to solve a new complex problem from scratch, but much easier if the system can access other similar problems and description of their solutions -- a paradigm known as case-based reasoning (CBR). We propose a neuro-symbolic CBR approach for question answering over large knowledge bases (CBR-KBQA). While the idea of CBR is tempting, composing a solution from cases is nontrivial, when individual cases only contain partial logic to the full solution. To resolve this, CBR-KBQA consists of two modules: a non-parametric memory that stores cases (question and logical forms) and a parametric model which can generate logical forms by retrieving relevant cases from memory. Through experiments, we show that CBR-KBQA can effectively derive novel combination of relations not presented in case memory that is required to answer compositional questions. On several KBQA datasets that test compositional generalization, CBR-KBQA achieves competitive performance. For example, on the challenging ComplexWebQuestions dataset, CBR-KBQA outperforms the current state of the art by 11% accuracy. Furthermore, we show that CBR-KBQA is capable of using new cases \emph{without} any further training. Just by incorporating few human-labeled examples in the non-parametric case memory, CBR-KBQA is able to successfully generate queries containing unseen KB relations.
Exact and Approximate Hierarchical Clustering Using A*
Apr 14, 2021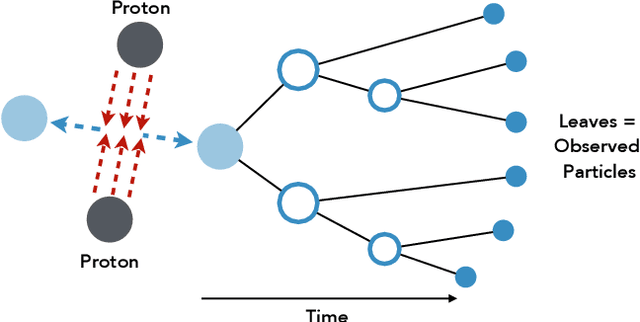
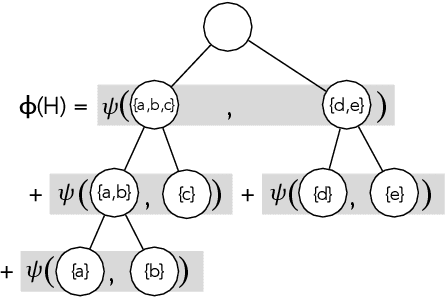
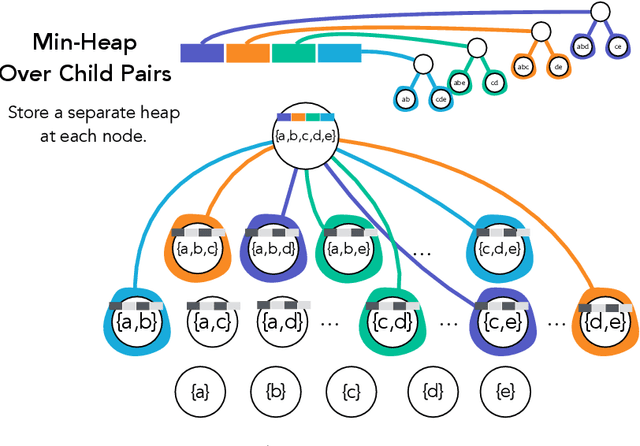
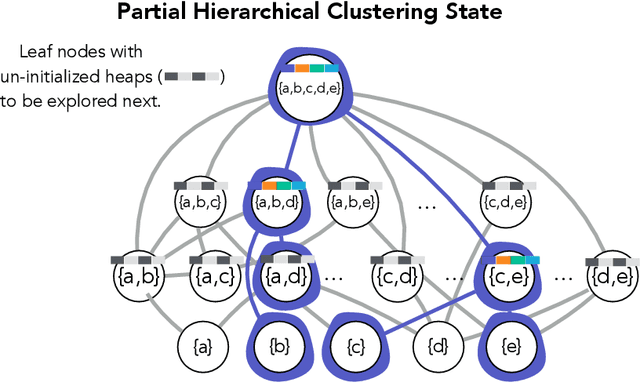
Hierarchical clustering is a critical task in numerous domains. Many approaches are based on heuristics and the properties of the resulting clusterings are studied post hoc. However, in several applications, there is a natural cost function that can be used to characterize the quality of the clustering. In those cases, hierarchical clustering can be seen as a combinatorial optimization problem. To that end, we introduce a new approach based on A* search. We overcome the prohibitively large search space by combining A* with a novel \emph{trellis} data structure. This combination results in an exact algorithm that scales beyond previous state of the art, from a search space with $10^{12}$ trees to $10^{15}$ trees, and an approximate algorithm that improves over baselines, even in enormous search spaces that contain more than $10^{1000}$ trees. We empirically demonstrate that our method achieves substantially higher quality results than baselines for a particle physics use case and other clustering benchmarks. We describe how our method provides significantly improved theoretical bounds on the time and space complexity of A* for clustering.
Model-Agnostic Graph Regularization for Few-Shot Learning
Feb 14, 2021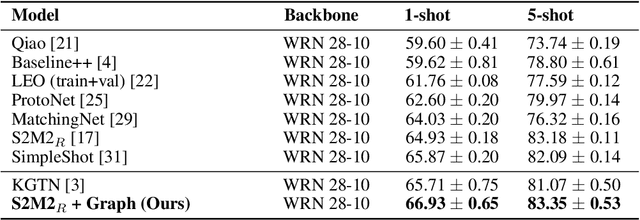
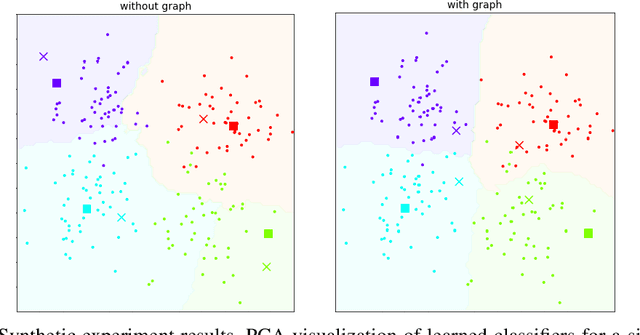
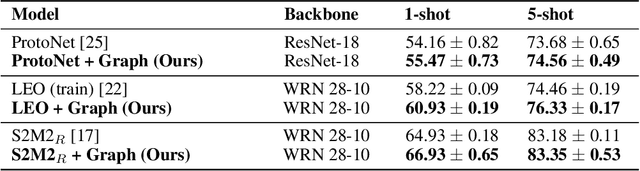
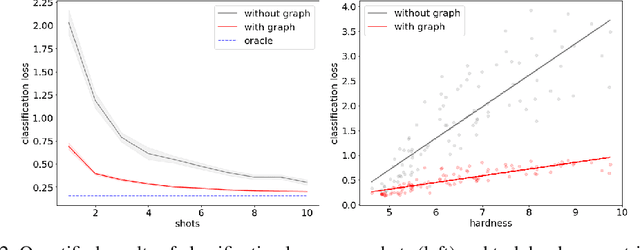
In many domains, relationships between categories are encoded in the knowledge graph. Recently, promising results have been achieved by incorporating knowledge graph as side information in hard classification tasks with severely limited data. However, prior models consist of highly complex architectures with many sub-components that all seem to impact performance. In this paper, we present a comprehensive empirical study on graph embedded few-shot learning. We introduce a graph regularization approach that allows a deeper understanding of the impact of incorporating graph information between labels. Our proposed regularization is widely applicable and model-agnostic, and boosts the performance of any few-shot learning model, including fine-tuning, metric-based, and optimization-based meta-learning. Our approach improves the performance of strong base learners by up to 2% on Mini-ImageNet and 6.7% on ImageNet-FS, outperforming state-of-the-art graph embedded methods. Additional analyses reveal that graph regularizing models result in a lower loss for more difficult tasks, such as those with fewer shots and less informative support examples.
Meta-Thompson Sampling
Feb 11, 2021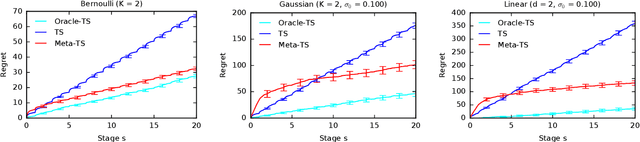
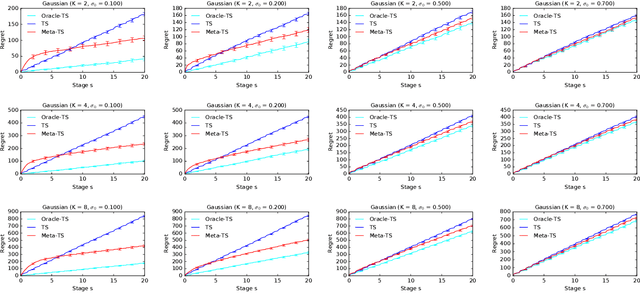
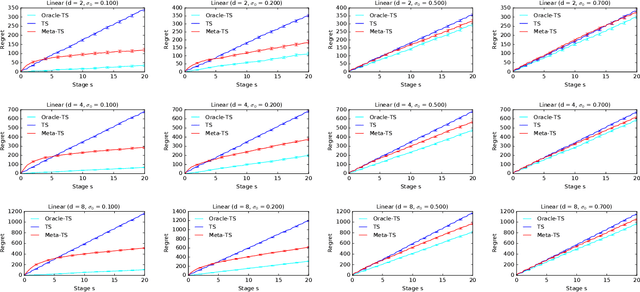
Efficient exploration in multi-armed bandits is a fundamental online learning problem. In this work, we propose a variant of Thompson sampling that learns to explore better as it interacts with problem instances drawn from an unknown prior distribution. Our algorithm meta-learns the prior and thus we call it Meta-TS. We propose efficient implementations of Meta-TS and analyze it in Gaussian bandits. Our analysis shows the benefit of meta-learning the prior and is of a broader interest, because we derive the first prior-dependent upper bound on the Bayes regret of Thompson sampling. This result is complemented by empirical evaluation, which shows that Meta-TS quickly adapts to the unknown prior.
Non-Stationary Latent Bandits
Dec 01, 2020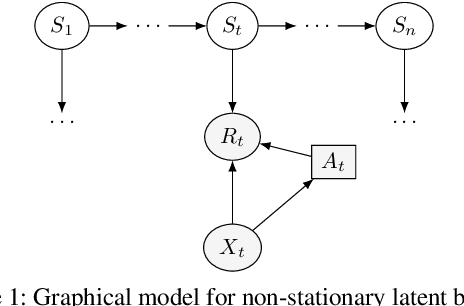
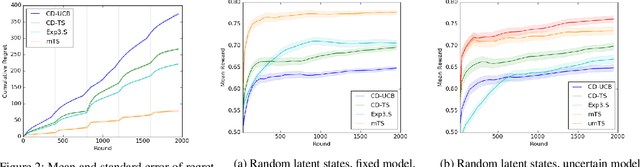
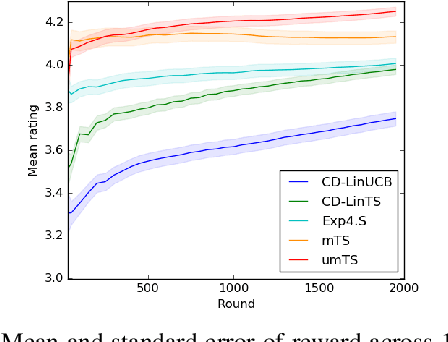
Users of recommender systems often behave in a non-stationary fashion, due to their evolving preferences and tastes over time. In this work, we propose a practical approach for fast personalization to non-stationary users. The key idea is to frame this problem as a latent bandit, where the prototypical models of user behavior are learned offline and the latent state of the user is inferred online from its interactions with the models. We call this problem a non-stationary latent bandit. We propose Thompson sampling algorithms for regret minimization in non-stationary latent bandits, analyze them, and evaluate them on a real-world dataset. The main strength of our approach is that it can be combined with rich offline-learned models, which can be misspecified, and are subsequently fine-tuned online using posterior sampling. In this way, we naturally combine the strengths of offline and online learning.
Latent Programmer: Discrete Latent Codes for Program Synthesis
Dec 01, 2020

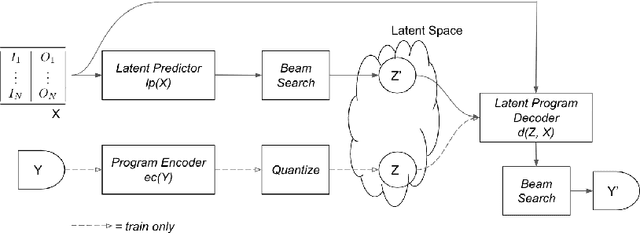

In many sequence learning tasks, such as program synthesis and document summarization, a key problem is searching over a large space of possible output sequences. We propose to learn representations of the outputs that are specifically meant for search: rich enough to specify the desired output but compact enough to make search more efficient. Discrete latent codes are appealing for this purpose, as they naturally allow sophisticated combinatorial search strategies. The latent codes are learned using a self-supervised learning principle, in which first a discrete autoencoder is trained on the output sequences, and then the resulting latent codes are used as intermediate targets for the end-to-end sequence prediction task. Based on these insights, we introduce the \emph{Latent Programmer}, a program synthesis method that first predicts a discrete latent code from input/output examples, and then generates the program in the target language. We evaluate the Latent Programmer on two domains: synthesis of string transformation programs, and generation of programs from natural language descriptions. We demonstrate that the discrete latent representation significantly improves synthesis accuracy.
Modifying Memories in Transformer Models
Dec 01, 2020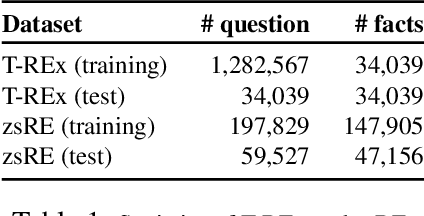

Large Transformer models have achieved impressive performance in many natural language tasks. In particular, Transformer based language models have been shown to have great capabilities in encoding factual knowledge in their vast amount of parameters. While the tasks of improving the memorization and generalization of Transformers have been widely studied, it is not well known how to make transformers forget specific old facts and memorize new ones. In this paper, we propose a new task of \emph{explicitly modifying specific factual knowledge in Transformer models while ensuring the model performance does not degrade on the unmodified facts}. This task is useful in many scenarios, such as updating stale knowledge, protecting privacy, and eliminating unintended biases stored in the models. We benchmarked several approaches that provide natural baseline performances on this task. This leads to the discovery of key components of a Transformer model that are especially effective for knowledge modifications. The work also provides insights into the role that different training phases (such as pretraining and fine-tuning) play towards memorization and knowledge modification.
Federated Composite Optimization
Nov 17, 2020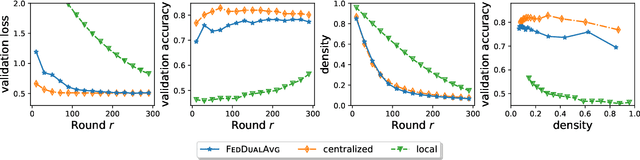
Federated Learning (FL) is a distributed learning paradigm which scales on-device learning collaboratively and privately. Standard FL algorithms such as Federated Averaging (FedAvg) are primarily geared towards smooth unconstrained settings. In this paper, we study the Federated Composite Optimization (FCO) problem, where the objective function in FL includes an additive (possibly) non-smooth component. Such optimization problems are fundamental to machine learning and arise naturally in the context of regularization (e.g., sparsity, low-rank, monotonicity, and constraint). To tackle this problem, we propose different primal/dual averaging approaches and study their communication and computation complexities. Of particular interest is Federated Dual Averaging (FedDualAvg), a federated variant of the dual averaging algorithm. FedDualAvg uses a novel double averaging procedure, which involves gradient averaging step in standard dual averaging and an average of client updates akin to standard federated averaging. Our theoretical analysis and empirical experiments demonstrate that FedDualAvg outperforms baselines for FCO.
Scalable Bottom-Up Hierarchical Clustering
Nov 04, 2020

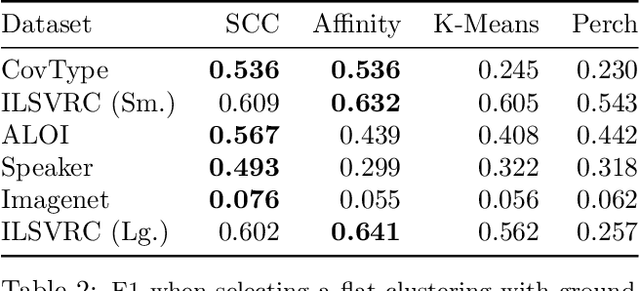
Bottom-up algorithms such as the classic hierarchical agglomerative clustering, are highly effective for hierarchical as well as flat clustering. However, the large number of rounds and their sequential nature limit the scalability of agglomerative clustering. In this paper, we present an alternative round-based bottom-up hierarchical clustering, the Sub-Cluster Component Algorithm (SCC), that scales gracefully to massive datasets. Our method builds many sub-clusters in parallel in a given round and requires many fewer rounds -- usually an order of magnitude smaller than classic agglomerative clustering. Our theoretical analysis shows that, under a modest separability assumption, SCC will contain the optimal flat clustering. SCC also provides a 2-approx solution to the DP-means objective, thereby introducing a novel application of hierarchical clustering methods. Empirically, SCC finds better hierarchies and flat clusterings even when the data does not satisfy the separability assumption. We demonstrate the scalability of our method by applying it to a dataset of 30 billion points and showing that SCC produces higher quality clusterings than the state-of-the-art.