 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical brain parcellation with uncertainty
Sep 16, 2020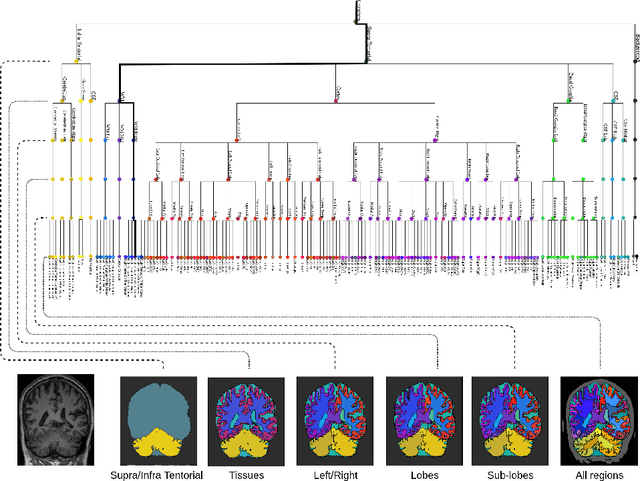
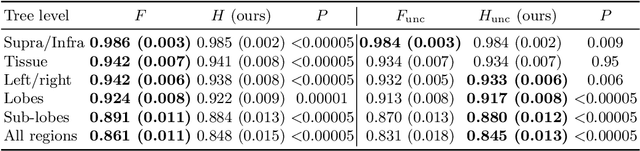
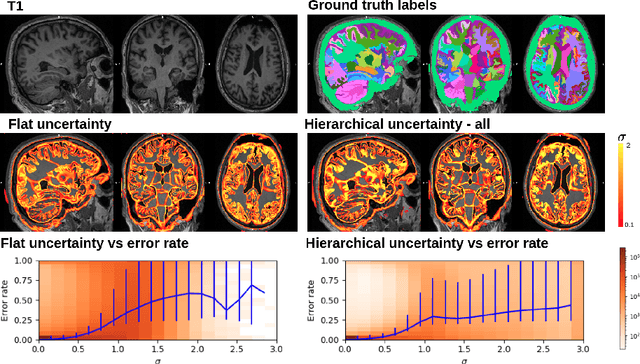
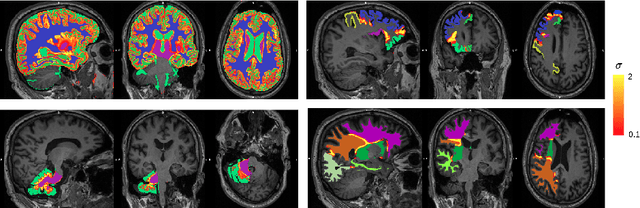
Many atlases used for brain parcellation are hierarchically organised, progressively dividing the brain into smaller sub-regions. However, state-of-the-art parcellation methods tend to ignore this structure and treat labels as if they are `flat'. We introduce a hierarchically-aware brain parcellation method that works by predicting the decisions at each branch in the label tree. We further show how this method can be used to model uncertainty separately for every branch in this label tree. Our method exceeds the performance of flat uncertainty methods, whilst also providing decomposed uncertainty estimates that enable us to obtain self-consistent parcellations and uncertainty maps at any level of the label hierarchy. We demonstrate a simple way these decision-specific uncertainty maps may be used to provided uncertainty-thresholded tissue maps at any level of the label tree.
Combining multimodal information for Metal Artefact Reduction: An unsupervised deep learning framework
Apr 20, 2020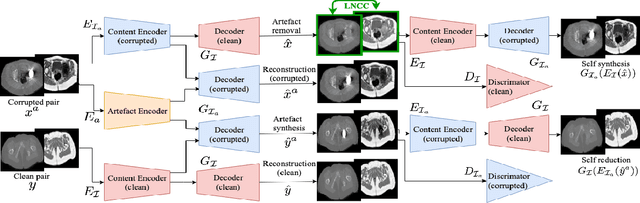
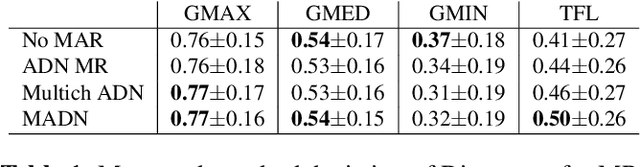
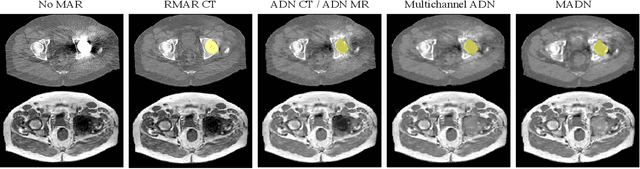
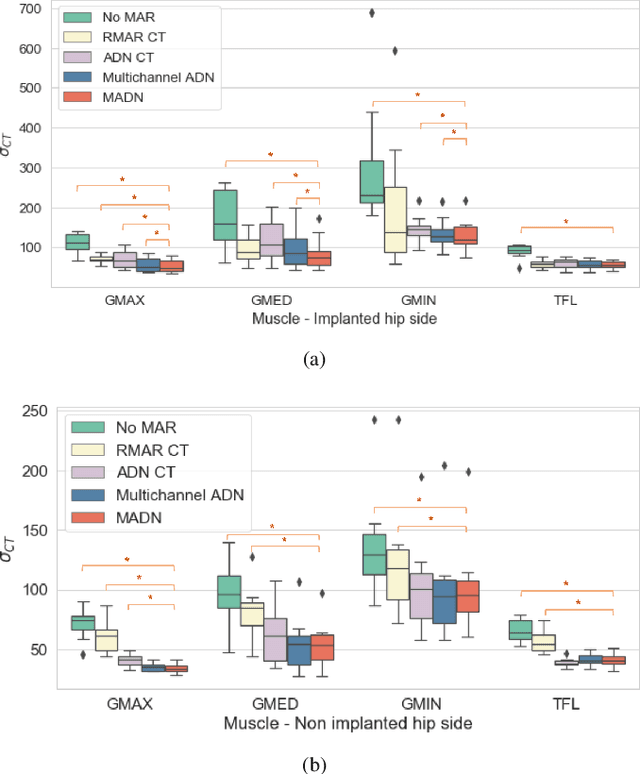
Metal artefact reduction (MAR) techniques aim at removing metal-induced noise from clinical images. In Computed Tomography (CT), supervised deep learning approaches have been shown effective but limited in generalisability, as they mostly rely on synthetic data. In Magnetic Resonance Imaging (MRI) instead, no method has yet been introduced to correct the susceptibility artefact, still present even in MAR-specific acquisitions. In this work, we hypothesise that a multimodal approach to MAR would improve both CT and MRI. Given their different artefact appearance, their complementary information can compensate for the corrupted signal in either modality. We thus propose an unsupervised deep learning method for multimodal MAR. We introduce the use of Locally Normalised Cross Correlation as a loss term to encourage the fusion of multimodal information. Experiments show that our approach favours a smoother correction in the CT, while promoting signal recovery in the MRI.
Automatic Right Ventricle Segmentation using Multi-Label Fusion in Cardiac MRI
Apr 05, 2020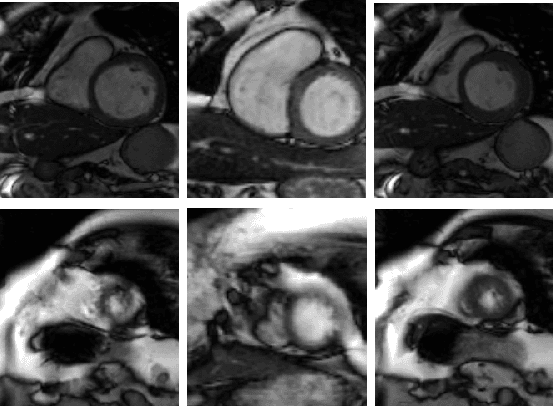

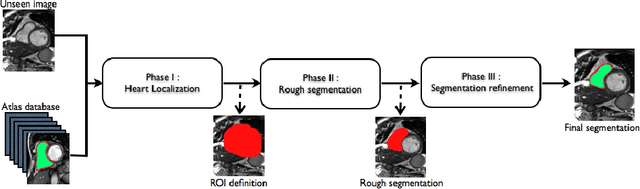
Accurate segmentation of the right ventricle (RV) is a crucial step in the assessment of the ventricular structure and function. Yet, due to its complex anatomy and motion segmentation of the RV has not been as largely studied as the left ventricle. This paper presents a fully automatic method for the segmentation of the RV in cardiac magnetic resonance images (MRI). The method uses a coarse-to-fine segmentation strategy in combination with a multi-atlas propagation segmentation framework. Based on a cross correlation metric, our method selects the best atlases for propagation allowing the refinement of the segmentation at each iteration of the propagation. The proposed method was evaluated on 32 cardiac MRI datasets provided by the RV Segmentation Challenge in Cardiac MRI.
The Future of Digital Health with Federated Learning
Mar 18, 2020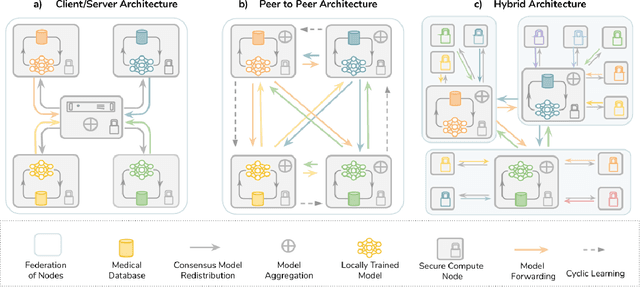
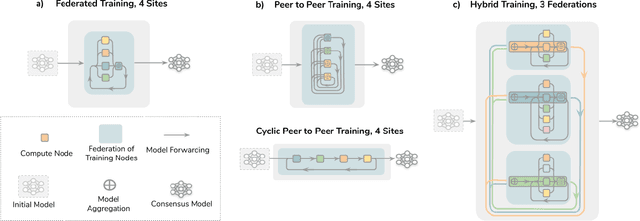
Data-driven Machine Learning has emerged as a promising approach for building accurate and robust statistical models from medical data, which is collected in huge volumes by modern healthcare systems. Existing medical data is not fully exploited by ML primarily because it sits in data silos and privacy concerns restrict access to this data. However, without access to sufficient data, ML will be prevented from reaching its full potential and, ultimately, from making the transition from research to clinical practice. This paper considers key factors contributing to this issue, explores how Federated Learning (FL) may provide a solution for the future of digital health and highlights the challenges and considerations that need to be addressed.
Neuromorphologicaly-preserving Volumetric data encoding using VQ-VAE
Feb 13, 2020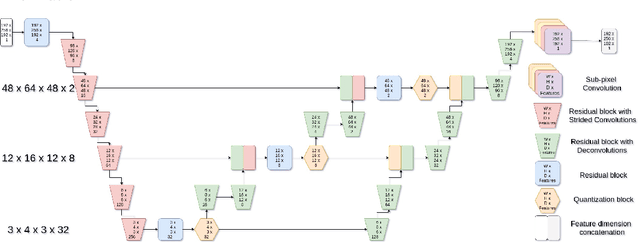
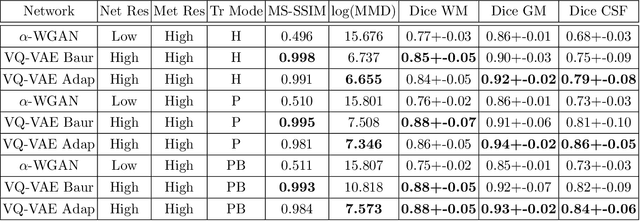
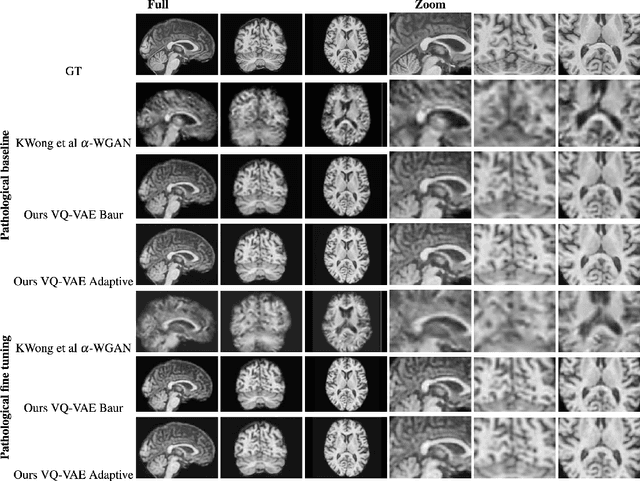
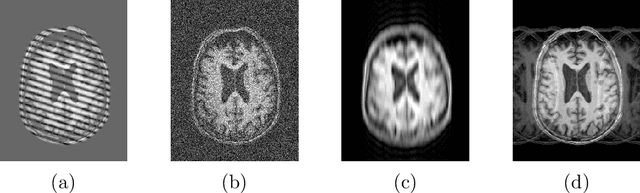
The increasing efficiency and compactness of deep learning architectures, together with hardware improvements, have enabled the complex and high-dimensional modelling of medical volumetric data at higher resolutions. Recently, Vector-Quantised Variational Autoencoders (VQ-VAE) have been proposed as an efficient generative unsupervised learning approach that can encode images to a small percentage of their initial size, while preserving their decoded fidelity. Here, we show a VQ-VAE inspired network can efficiently encode a full-resolution 3D brain volume, compressing the data to $0.825\%$ of the original size while maintaining image fidelity, and significantly outperforming the previous state-of-the-art. We then demonstrate that VQ-VAE decoded images preserve the morphological characteristics of the original data through voxel-based morphology and segmentation experiments. Lastly, we show that such models can be pre-trained and then fine-tuned on different datasets without the introduction of bias.
A Heteroscedastic Uncertainty Model for Decoupling Sources of MRI Image Quality
Jan 31, 2020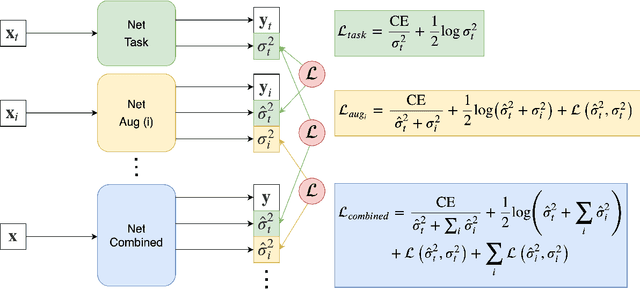
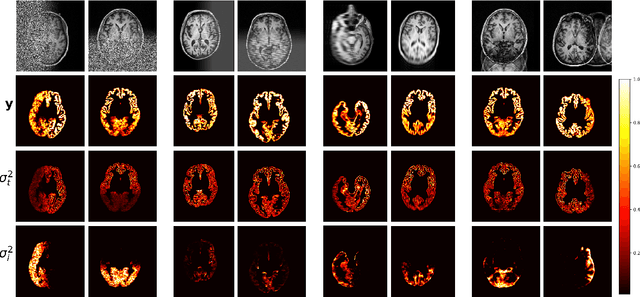
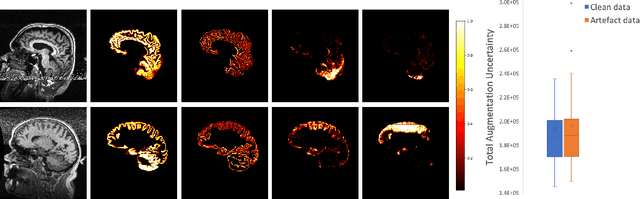
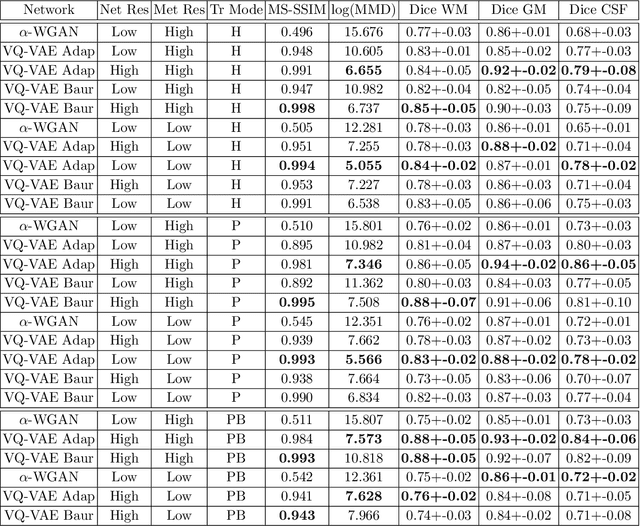
Quality control (QC) of medical images is essential to ensure that downstream analyses such as segmentation can be performed successfully. Currently, QC is predominantly performed visually at significant time and operator cost. We aim to automate the process by formulating a probabilistic network that estimates uncertainty through a heteroscedastic noise model, hence providing a proxy measure of task-specific image quality that is learnt directly from the data. By augmenting the training data with different types of simulated k-space artefacts, we propose a novel cascading CNN architecture based on a student-teacher framework to decouple sources of uncertainty related to different k-space augmentations in an entirely self-supervised manner. This enables us to predict separate uncertainty quantities for the different types of data degradation. While the uncertainty measures reflect the presence and severity of image artefacts, the network also provides the segmentation predictions given the quality of the data. We show models trained with simulated artefacts provide informative measures of uncertainty on real-world images and we validate our uncertainty predictions on problematic images identified by human-raters.
On the Initialization of Long Short-Term Memory Networks
Dec 22, 2019
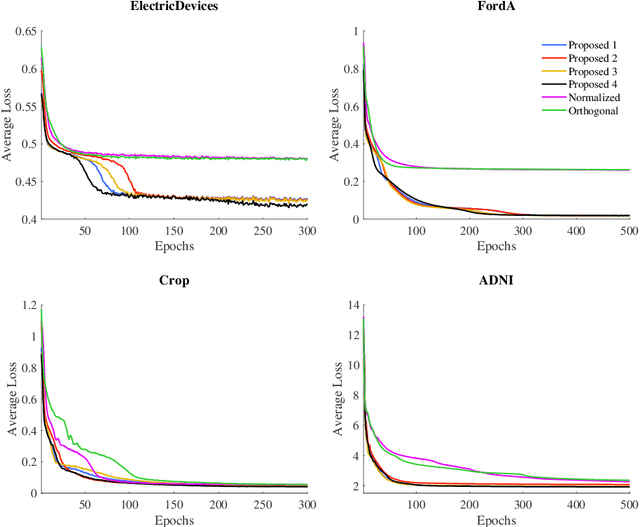
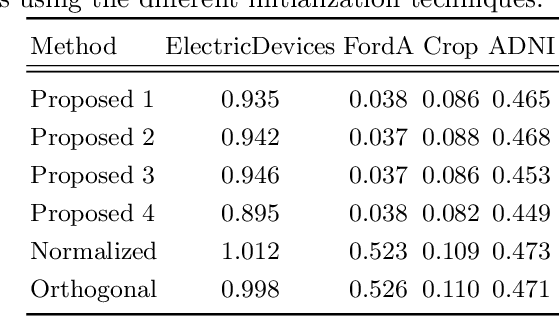
Weight initialization is important for faster convergence and stability of deep neural networks training. In this paper, a robust initialization method is developed to address the training instability in long short-term memory (LSTM) networks. It is based on a normalized random initialization of the network weights that aims at preserving the variance of the network input and output in the same range. The method is applied to standard LSTMs for univariate time series regression and to LSTMs robust to missing values for multivariate disease progression modeling. The results show that in all cases, the proposed initialization method outperforms the state-of-the-art initialization techniques in terms of training convergence and generalization performance of the obtained solution.
Privacy-preserving Federated Brain Tumour Segmentation
Oct 02, 2019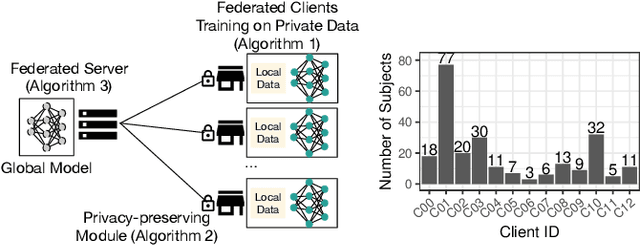
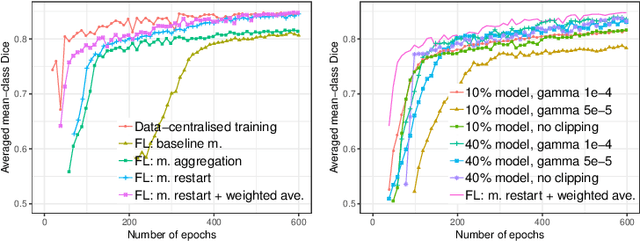
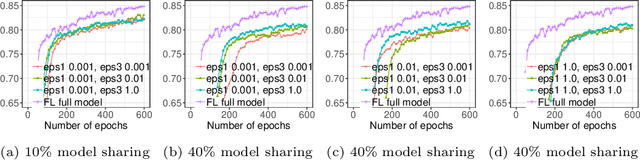
Due to medical data privacy regulations, it is often infeasible to collect and share patient data in a centralised data lake. This poses challenges for training machine learning algorithms, such as deep convolutional networks, which often require large numbers of diverse training examples. Federated learning sidesteps this difficulty by bringing code to the patient data owners and only sharing intermediate model training updates among them. Although a high-accuracy model could be achieved by appropriately aggregating these model updates, the model shared could indirectly leak the local training examples. In this paper, we investigate the feasibility of applying differential-privacy techniques to protect the patient data in a federated learning setup. We implement and evaluate practical federated learning systems for brain tumour segmentation on the BraTS dataset. The experimental results show that there is a trade-off between model performance and privacy protection costs.
Multi-Domain Adaptation in Brain MRI through Paired Consistency and Adversarial Learning
Sep 17, 2019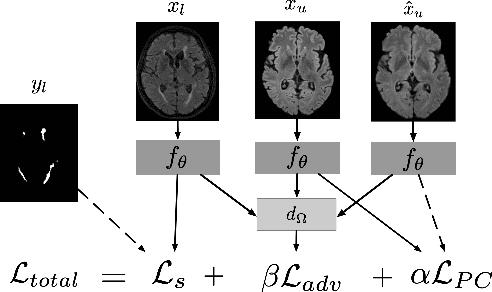
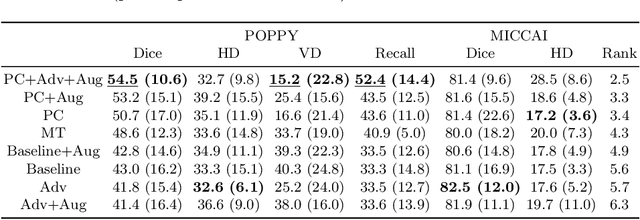
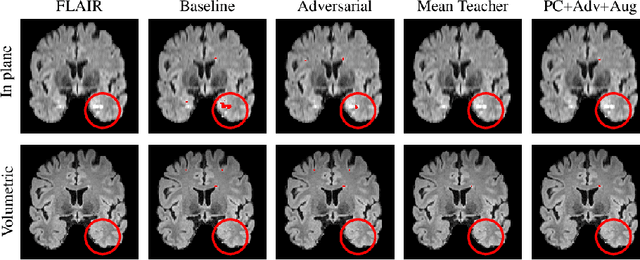
Supervised learning algorithms trained on medical images will often fail to generalize across changes in acquisition parameters. Recent work in domain adaptation addresses this challenge and successfully leverages labeled data in a source domain to perform well on an unlabeled target domain. Inspired by recent work in semi-supervised learning we introduce a novel method to adapt from one source domain to $n$ target domains (as long as there is paired data covering all domains). Our multi-domain adaptation method utilises a consistency loss combined with adversarial learning. We provide results on white matter lesion hyperintensity segmentation from brain MRIs using the MICCAI 2017 challenge data as the source domain and two target domains. The proposed method significantly outperforms other domain adaptation baselines.
Let's agree to disagree: learning highly debatable multirater labelling
Sep 04, 2019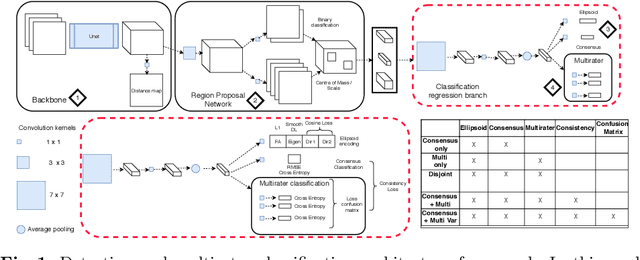
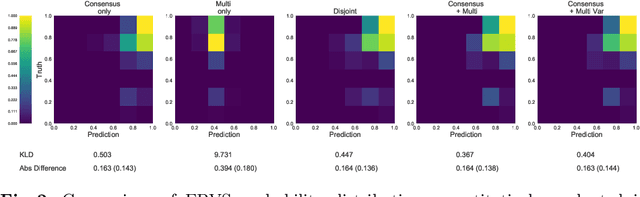
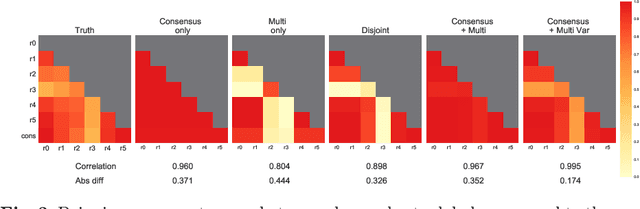
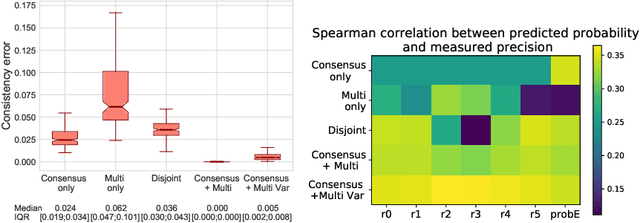
Classification and differentiation of small pathological objects may greatly vary among human raters due to differences in training, expertise and their consistency over time. In a radiological setting, objects commonly have high within-class appearance variability whilst sharing certain characteristics across different classes, making their distinction even more difficult. As an example, markers of cerebral small vessel disease, such as enlarged perivascular spaces (EPVS) and lacunes, can be very varied in their appearance while exhibiting high inter-class similarity, making this task highly challenging for human raters. In this work, we investigate joint models of individual rater behaviour and multirater consensus in a deep learning setting, and apply it to a brain lesion object-detection task. Results show that jointly modelling both individual and consensus estimates leads to significant improvements in performance when compared to directly predicting consensus labels, while also allowing the characterization of human-rater consistency.