 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Cascade Model for Multi-Document Reading Comprehension
Nov 28, 2018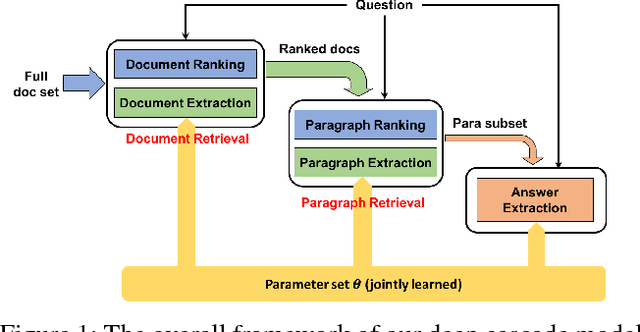
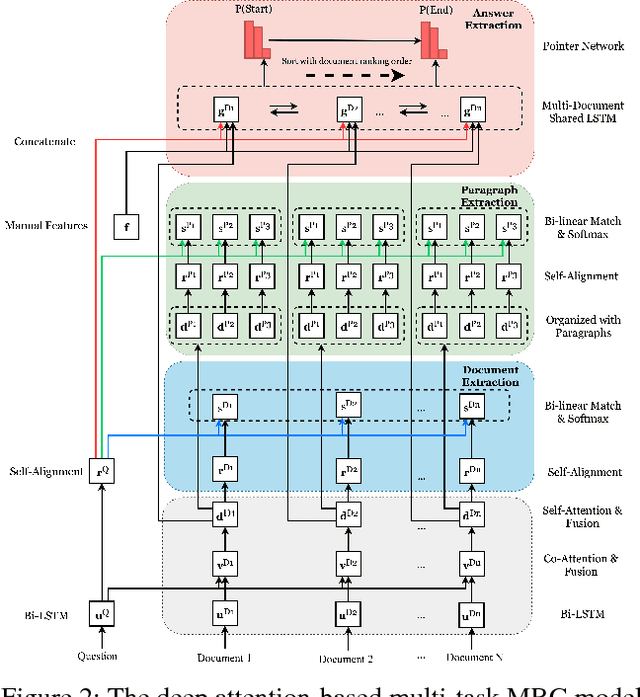
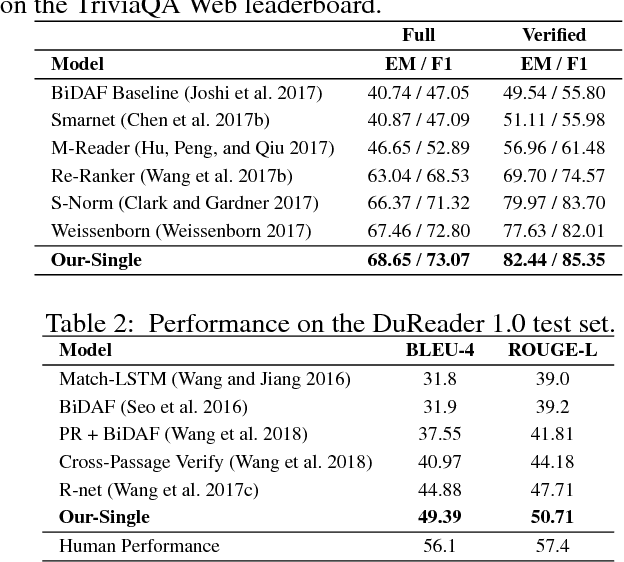
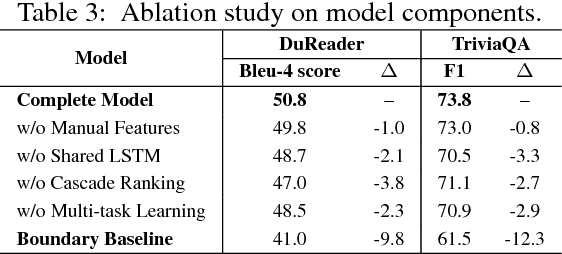
A fundamental trade-off between effectiveness and efficiency needs to be balanced when designing an online question answering system. Effectiveness comes from sophisticated functions such as extractive machine reading comprehension (MRC), while efficiency is obtained from improvements in preliminary retrieval components such as candidate document selection and paragraph ranking. Given the complexity of the real-world multi-document MRC scenario, it is difficult to jointly optimize both in an end-to-end system. To address this problem, we develop a novel deep cascade learning model, which progressively evolves from the document-level and paragraph-level ranking of candidate texts to more precise answer extraction with machine reading comprehension. Specifically, irrelevant documents and paragraphs are first filtered out with simple functions for efficiency consideration. Then we jointly train three modules on the remaining texts for better tracking the answer: the document extraction, the paragraph extraction and the answer extraction. Experiment results show that the proposed method outperforms the previous state-of-the-art methods on two large-scale multi-document benchmark datasets, i.e., TriviaQA and DuReader. In addition, our online system can stably serve typical scenarios with millions of daily requests in less than 50ms.
"Bilingual Expert" Can Find Translation Errors
Aug 03, 2018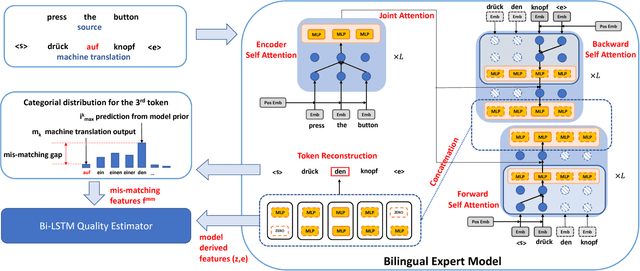
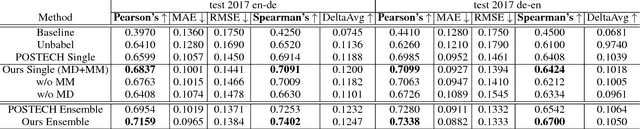
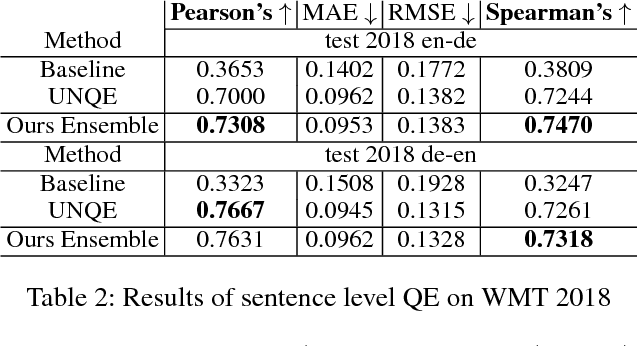
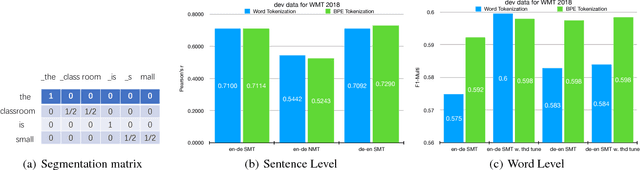
Recent advances in statistical machine translation via the adoption of neural sequence-to-sequence models empower the end-to-end system to achieve state-of-the-art in many WMT benchmarks. The performance of such machine translation (MT) system is usually evaluated by automatic metric BLEU when the golden references are provided for validation. However, for model inference or production deployment, the golden references are prohibitively available or require expensive human annotation with bilingual expertise. In order to address the issue of quality evaluation (QE) without reference, we propose a general framework for automatic evaluation of translation output for most WMT quality evaluation tasks. We first build a conditional target language model with a novel bidirectional transformer, named neural bilingual expert model, which is pre-trained on large parallel corpora for feature extraction. For QE inference, the bilingual expert model can simultaneously produce the joint latent representation between the source and the translation, and real-valued measurements of possible erroneous tokens based on the prior knowledge learned from parallel data. Subsequently, the features will further be fed into a simple Bi-LSTM predictive model for quality evaluation. The experimental results show that our approach achieves the state-of-the-art performance in the quality estimation track of WMT 2017/2018.
Perceive Your Users in Depth: Learning Universal User Representations from Multiple E-commerce Tasks
May 28, 2018

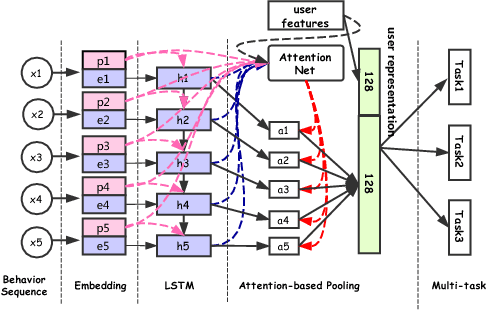
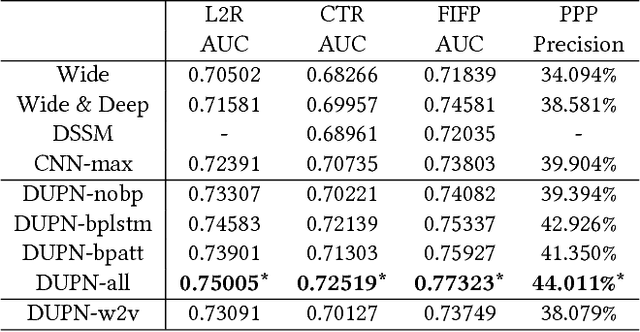
Tasks such as search and recommendation have become increas- ingly important for E-commerce to deal with the information over- load problem. To meet the diverse needs of di erent users, person- alization plays an important role. In many large portals such as Taobao and Amazon, there are a bunch of di erent types of search and recommendation tasks operating simultaneously for person- alization. However, most of current techniques address each task separately. This is suboptimal as no information about users shared across di erent tasks. In this work, we propose to learn universal user representations across multiple tasks for more e ective personalization. In partic- ular, user behavior sequences (e.g., click, bookmark or purchase of products) are modeled by LSTM and attention mechanism by integrating all the corresponding content, behavior and temporal information. User representations are shared and learned in an end-to-end setting across multiple tasks. Bene ting from better information utilization of multiple tasks, the user representations are more e ective to re ect their interests and are more general to be transferred to new tasks. We refer this work as Deep User Perception Network (DUPN) and conduct an extensive set of o ine and online experiments. Across all tested ve di erent tasks, our DUPN consistently achieves better results by giving more e ective user representations. Moreover, we deploy DUPN in large scale operational tasks in Taobao. Detailed implementations, e.g., incre- mental model updating, are also provided to address the practical issues for the real world applications.
A Multi-task Learning Approach for Improving Product Title Compression with User Search Log Data
Jan 05, 2018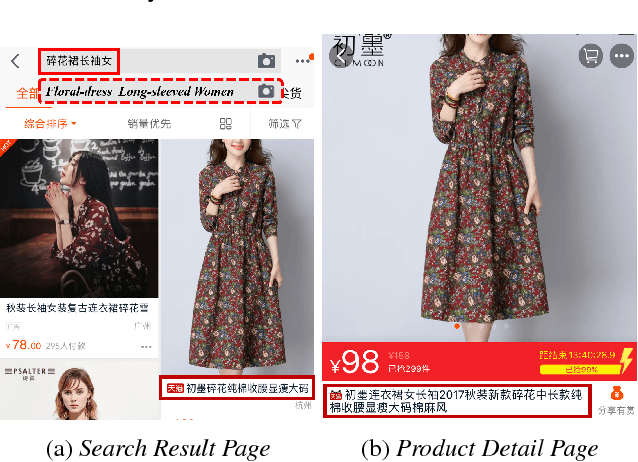


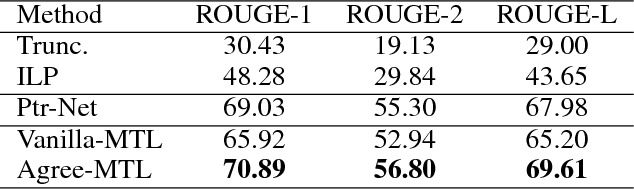
It is a challenging and practical research problem to obtain effective compression of lengthy product titles for E-commerce. This is particularly important as more and more users browse mobile E-commerce apps and more merchants make the original product titles redundant and lengthy for Search Engine Optimization. Traditional text summarization approaches often require a large amount of preprocessing costs and do not capture the important issue of conversion rate in E-commerce. This paper proposes a novel multi-task learning approach for improving product title compression with user search log data. In particular, a pointer network-based sequence-to-sequence approach is utilized for title compression with an attentive mechanism as an extractive method and an attentive encoder-decoder approach is utilized for generating user search queries. The encoding parameters (i.e., semantic embedding of original titles) are shared among the two tasks and the attention distributions are jointly optimized. An extensive set of experiments with both human annotated data and online deployment demonstrate the advantage of the proposed research for both compression qualities and online business values.
Cascade Ranking for Operational E-commerce Search
Jun 07, 2017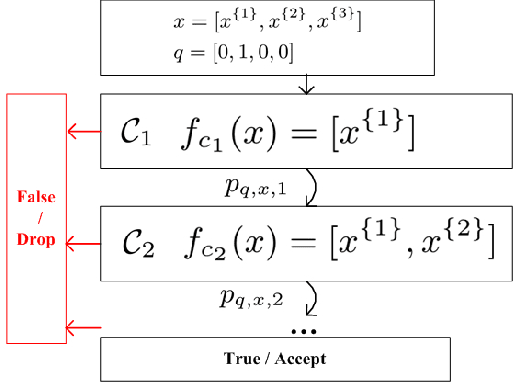
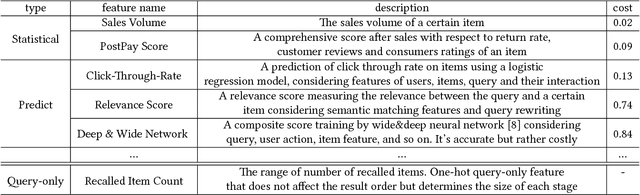
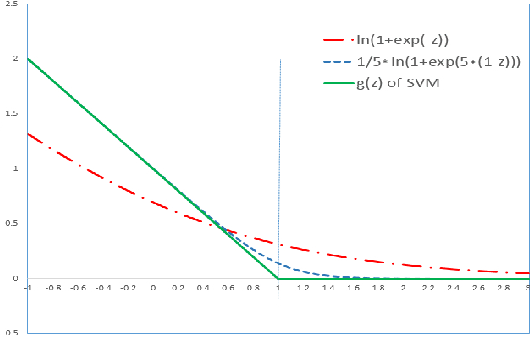

In the 'Big Data' era, many real-world applications like search involve the ranking problem for a large number of items. It is important to obtain effective ranking results and at the same time obtain the results efficiently in a timely manner for providing good user experience and saving computational costs. Valuable prior research has been conducted for learning to efficiently rank like the cascade ranking (learning) model, which uses a sequence of ranking functions to progressively filter some items and rank the remaining items. However, most existing research of learning to efficiently rank in search is studied in a relatively small computing environments with simulated user queries. This paper presents novel research and thorough study of designing and deploying a Cascade model in a Large-scale Operational E-commerce Search application (CLOES), which deals with hundreds of millions of user queries per day with hundreds of servers. The challenge of the real-world application provides new insights for research: 1). Real-world search applications often involve multiple factors of preferences or constraints with respect to user experience and computational costs such as search accuracy, search latency, size of search results and total CPU cost, while most existing search solutions only address one or two factors; 2). Effectiveness of e-commerce search involves multiple types of user behaviors such as click and purchase, while most existing cascade ranking in search only models the click behavior. Based on these observations, a novel cascade ranking model is designed and deployed in an operational e-commerce search application. An extensive set of experiments demonstrate the advantage of the proposed work to address multiple factors of effectiveness, efficiency and user experience in the real-world application.
A Joint Probabilistic Classification Model of Relevant and Irrelevant Sentences in Mathematical Word Problems
Nov 21, 2014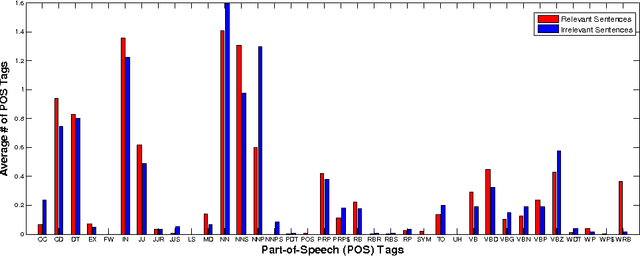


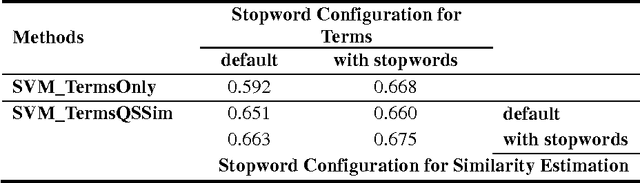
Estimating the difficulty level of math word problems is an important task for many educational applications. Identification of relevant and irrelevant sentences in math word problems is an important step for calculating the difficulty levels of such problems. This paper addresses a novel application of text categorization to identify two types of sentences in mathematical word problems, namely relevant and irrelevant sentences. A novel joint probabilistic classification model is proposed to estimate the joint probability of classification decisions for all sentences of a math word problem by utilizing the correlation among all sentences along with the correlation between the question sentence and other sentences, and sentence text. The proposed model is compared with i) a SVM classifier which makes independent classification decisions for individual sentences by only using the sentence text and ii) a novel SVM classifier that considers the correlation between the question sentence and other sentences along with the sentence text. An extensive set of experiments demonstrates the effectiveness of the joint probabilistic classification model for identifying relevant and irrelevant sentences as well as the novel SVM classifier that utilizes the correlation between the question sentence and other sentences. Furthermore, empirical results and analysis show that i) it is highly beneficial not to remove stopwords and ii) utilizing part of speech tagging does not make a significant improvement although it has been shown to be effective for the related task of math word problem type classification.
A Bayesian Approach toward Active Learning for Collaborative Filtering
Jul 11, 2012
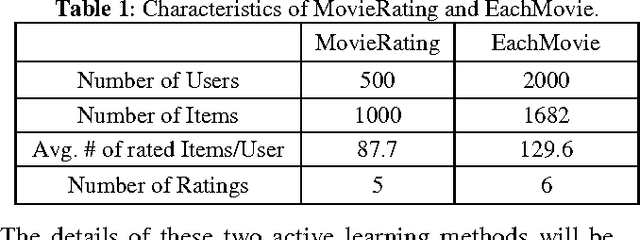
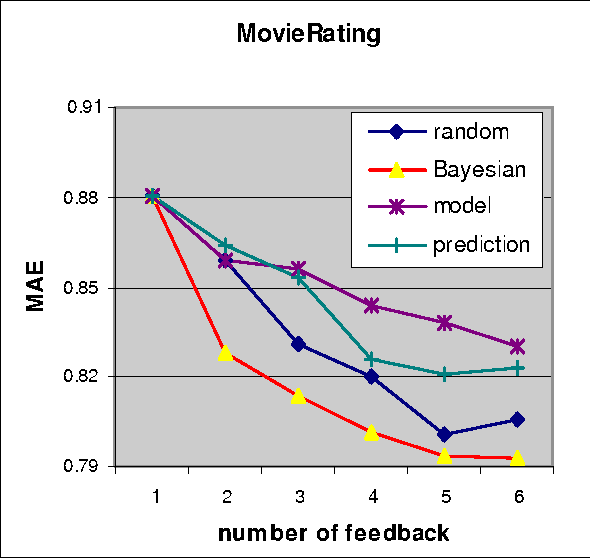
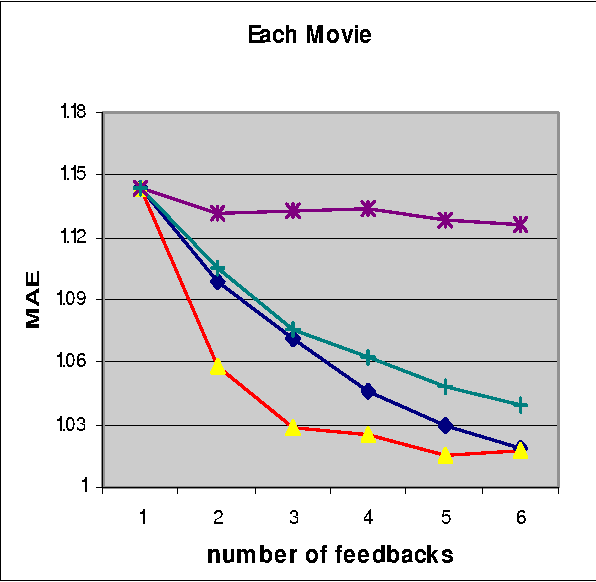
Collaborative filtering is a useful technique for exploiting the preference patterns of a group of users to predict the utility of items for the active user. In general, the performance of collaborative filtering depends on the number of rated examples given by the active user. The more the number of rated examples given by the active user, the more accurate the predicted ratings will be. Active learning provides an effective way to acquire the most informative rated examples from active users. Previous work on active learning for collaborative filtering only considers the expected loss function based on the estimated model, which can be misleading when the estimated model is inaccurate. This paper takes one step further by taking into account of the posterior distribution of the estimated model, which results in more robust active learning algorithm. Empirical studies with datasets of movie ratings show that when the number of ratings from the active user is restricted to be small, active learning methods only based on the estimated model don't perform well while the active learning method using the model distribution achieves substantially better performance.
Robust Nonnegative Matrix Factorization via $L_1$ Norm Regularization
Apr 11, 2012
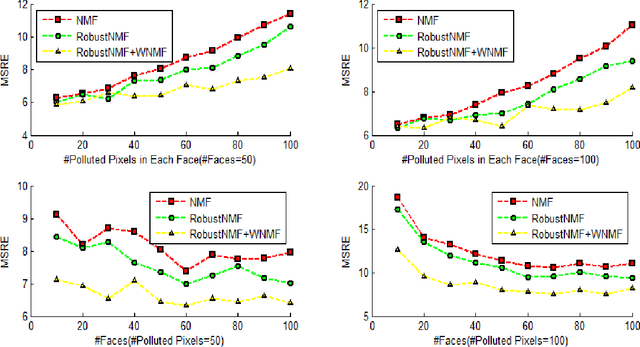

Nonnegative Matrix Factorization (NMF) is a widely used technique in many applications such as face recognition, motion segmentation, etc. It approximates the nonnegative data in an original high dimensional space with a linear representation in a low dimensional space by using the product of two nonnegative matrices. In many applications data are often partially corrupted with large additive noise. When the positions of noise are known, some existing variants of NMF can be applied by treating these corrupted entries as missing values. However, the positions are often unknown in many real world applications, which prevents the usage of traditional NMF or other existing variants of NMF. This paper proposes a Robust Nonnegative Matrix Factorization (RobustNMF) algorithm that explicitly models the partial corruption as large additive noise without requiring the information of positions of noise. In practice, large additive noise can be used to model outliers. In particular, the proposed method jointly approximates the clean data matrix with the product of two nonnegative matrices and estimates the positions and values of outliers/noise. An efficient iterative optimization algorithm with a solid theoretical justification has been proposed to learn the desired matrix factorization. Experimental results demonstrate the advantages of the proposed algorithm.