 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal-Spatial Tubelet Embedding for Cloud-Robust MSI Reconstruction using MSI-SAR Fusion: A Multi-Head Self-Attention Video Vision Transformer Approach
Dec 10, 2025Cloud cover in multispectral imagery (MSI) significantly hinders early-season crop mapping by corrupting spectral information. Existing Vision Transformer(ViT)-based time-series reconstruction methods, like SMTS-ViT, often employ coarse temporal embeddings that aggregate entire sequences, causing substantial information loss and reducing reconstruction accuracy. To address these limitations, a Video Vision Transformer (ViViT)-based framework with temporal-spatial fusion embedding for MSI reconstruction in cloud-covered regions is proposed in this study. Non-overlapping tubelets are extracted via 3D convolution with constrained temporal span $(t=2)$, ensuring local temporal coherence while reducing cross-day information degradation. Both MSI-only and SAR-MSI fusion scenarios are considered during the experiments. Comprehensive experiments on 2020 Traill County data demonstrate notable performance improvements: MTS-ViViT achieves a 2.23\% reduction in MSE compared to the MTS-ViT baseline, while SMTS-ViViT achieves a 10.33\% improvement with SAR integration over the SMTS-ViT baseline. The proposed framework effectively enhances spectral reconstruction quality for robust agricultural monitoring.
NegBLEURT Forest: Leveraging Inconsistencies for Detecting Jailbreak Attacks
Nov 14, 2025



Jailbreak attacks designed to bypass safety mechanisms pose a serious threat by prompting LLMs to generate harmful or inappropriate content, despite alignment with ethical guidelines. Crafting universal filtering rules remains difficult due to their inherent dependence on specific contexts. To address these challenges without relying on threshold calibration or model fine-tuning, this work introduces a semantic consistency analysis between successful and unsuccessful responses, demonstrating that a negation-aware scoring approach captures meaningful patterns. Building on this insight, a novel detection framework called NegBLEURT Forest is proposed to evaluate the degree of alignment between outputs elicited by adversarial prompts and expected safe behaviors. It identifies anomalous responses using the Isolation Forest algorithm, enabling reliable jailbreak detection. Experimental results show that the proposed method consistently achieves top-tier performance, ranking first or second in accuracy across diverse models using the crafted dataset, while competing approaches exhibit notable sensitivity to model and data variations.
Enhancing Large Multimodal Models with Adaptive Sparsity and KV Cache Compression
Jul 28, 2025Large multimodal models (LMMs) have advanced significantly by integrating visual encoders with extensive language models, enabling robust reasoning capabilities. However, compressing LMMs for deployment on edge devices remains a critical challenge. In this work, we propose an adaptive search algorithm that optimizes sparsity and KV cache compression to enhance LMM efficiency. Utilizing the Tree-structured Parzen Estimator, our method dynamically adjusts pruning ratios and KV cache quantization bandwidth across different LMM layers, using model performance as the optimization objective. This approach uniquely combines pruning with key-value cache quantization and incorporates a fast pruning technique that eliminates the need for additional fine-tuning or weight adjustments, achieving efficient compression without compromising accuracy. Comprehensive evaluations on benchmark datasets, including LLaVA-1.5 7B and 13B, demonstrate our method superiority over state-of-the-art techniques such as SparseGPT and Wanda across various compression levels. Notably, our framework automatic allocation of KV cache compression resources sets a new standard in LMM optimization, delivering memory efficiency without sacrificing much performance.
Vision Transformer-Based Time-Series Image Reconstruction for Cloud-Filling Applications
Jun 24, 2025Cloud cover in multispectral imagery (MSI) poses significant challenges for early season crop mapping, as it leads to missing or corrupted spectral information. Synthetic aperture radar (SAR) data, which is not affected by cloud interference, offers a complementary solution, but lack sufficient spectral detail for precise crop mapping. To address this, we propose a novel framework, Time-series MSI Image Reconstruction using Vision Transformer (ViT), to reconstruct MSI data in cloud-covered regions by leveraging the temporal coherence of MSI and the complementary information from SAR from the attention mechanism. Comprehensive experiments, using rigorous reconstruction evaluation metrics, demonstrate that Time-series ViT framework significantly outperforms baselines that use non-time-series MSI and SAR or time-series MSI without SAR, effectively enhancing MSI image reconstruction in cloud-covered regions.
Exploring the Impact of Temperature on Large Language Models:Hot or Cold?
Jun 08, 2025



The sampling temperature, a critical hyperparameter in large language models (LLMs), modifies the logits before the softmax layer, thereby reshaping the distribution of output tokens. Recent studies have challenged the Stochastic Parrots analogy by demonstrating that LLMs are capable of understanding semantics rather than merely memorizing data and that randomness, modulated by sampling temperature, plays a crucial role in model inference. In this study, we systematically evaluated the impact of temperature in the range of 0 to 2 on data sets designed to assess six different capabilities, conducting statistical analyses on open source models of three different sizes: small (1B--4B), medium (6B--13B), and large (40B--80B). Our findings reveal distinct skill-specific effects of temperature on model performance, highlighting the complexity of optimal temperature selection in practical applications. To address this challenge, we propose a BERT-based temperature selector that takes advantage of these observed effects to identify the optimal temperature for a given prompt. We demonstrate that this approach can significantly improve the performance of small and medium models in the SuperGLUE datasets. Furthermore, our study extends to FP16 precision inference, revealing that temperature effects are consistent with those observed in 4-bit quantized models. By evaluating temperature effects up to 4.0 in three quantized models, we find that the Mutation Temperature -- the point at which significant performance changes occur -- increases with model size.
Can Compressed LLMs Truly Act? An Empirical Evaluation of Agentic Capabilities in LLM Compression
May 26, 2025



Post-training compression reduces the computational and memory costs of large language models (LLMs), enabling resource-efficient deployment. However, existing compression benchmarks only focus on language modeling (e.g., perplexity) and natural language understanding tasks (e.g., GLUE accuracy), ignoring the agentic capabilities - workflow, tool use/function call, long-context understanding and real-world application. We introduce the Agent Compression Benchmark (ACBench), the first comprehensive benchmark for evaluating how compression impacts LLMs' agentic abilities. ACBench spans (1) 12 tasks across 4 capabilities (e.g., WorfBench for workflow generation, Needle-in-Haystack for long-context retrieval), (2) quantization (GPTQ, AWQ) and pruning (Wanda, SparseGPT), and (3) 15 models, including small (Gemma-2B), standard (Qwen2.5 7B-32B), and distilled reasoning LLMs (DeepSeek-R1-Distill). Our experiments reveal compression tradeoffs: 4-bit quantization preserves workflow generation and tool use (1%-3% drop) but degrades real-world application accuracy by 10%-15%. We introduce ERank, Top-k Ranking Correlation and Energy to systematize analysis. ACBench provides actionable insights for optimizing LLM compression in agentic scenarios. The code can be found in https://github.com/pprp/ACBench.
Small Language Models in the Real World: Insights from Industrial Text Classification
May 21, 2025With the emergence of ChatGPT, Transformer models have significantly advanced text classification and related tasks. Decoder-only models such as Llama exhibit strong performance and flexibility, yet they suffer from inefficiency on inference due to token-by-token generation, and their effectiveness in text classification tasks heavily depends on prompt quality. Moreover, their substantial GPU resource requirements often limit widespread adoption. Thus, the question of whether smaller language models are capable of effectively handling text classification tasks emerges as a topic of significant interest. However, the selection of appropriate models and methodologies remains largely underexplored. In this paper, we conduct a comprehensive evaluation of prompt engineering and supervised fine-tuning methods for transformer-based text classification. Specifically, we focus on practical industrial scenarios, including email classification, legal document categorization, and the classification of extremely long academic texts. We examine the strengths and limitations of smaller models, with particular attention to both their performance and their efficiency in Video Random-Access Memory (VRAM) utilization, thereby providing valuable insights for the local deployment and application of compact models in industrial settings.
Is LLM the Silver Bullet to Low-Resource Languages Machine Translation?
Mar 31, 2025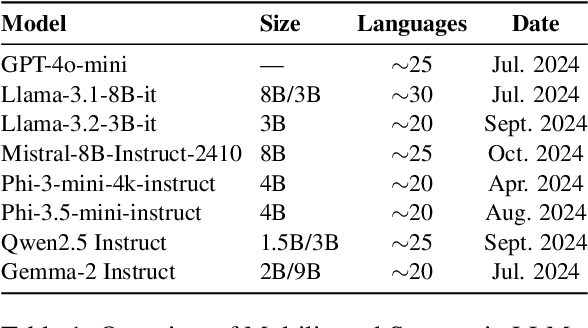
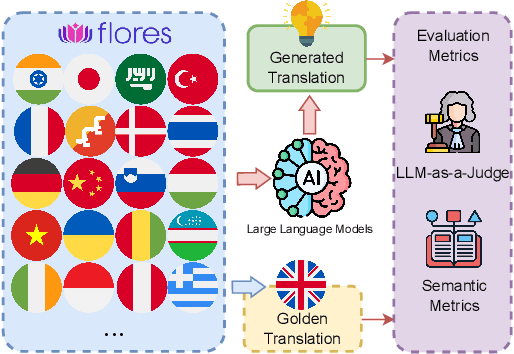
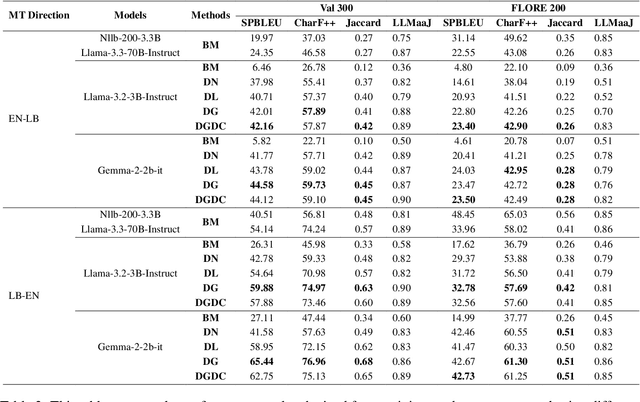
Low-Resource Languages (LRLs) present significant challenges in natural language processing due to their limited linguistic resources and underrepresentation in standard datasets. While recent advancements in Large Language Models (LLMs) and Neural Machine Translation (NMT) have substantially improved translation capabilities for high-resource languages, performance disparities persist for LRLs, particularly impacting privacy-sensitive and resource-constrained scenarios. This paper systematically evaluates the limitations of current LLMs across 200 languages using benchmarks such as FLORES-200. We also explore alternative data sources, including news articles and bilingual dictionaries, and demonstrate how knowledge distillation from large pre-trained models can significantly improve smaller LRL translations. Additionally, we investigate various fine-tuning strategies, revealing that incremental enhancements markedly reduce performance gaps on smaller LLMs.
Delta Decompression for MoE-based LLMs Compression
Feb 24, 2025



Mixture-of-Experts (MoE) architectures in large language models (LLMs) achieve exceptional performance, but face prohibitive storage and memory requirements. To address these challenges, we present $D^2$-MoE, a new delta decompression compressor for reducing the parameters of MoE LLMs. Based on observations of expert diversity, we decompose their weights into a shared base weight and unique delta weights. Specifically, our method first merges each expert's weight into the base weight using the Fisher information matrix to capture shared components. Then, we compress delta weights through Singular Value Decomposition (SVD) by exploiting their low-rank properties. Finally, we introduce a semi-dynamical structured pruning strategy for the base weights, combining static and dynamic redundancy analysis to achieve further parameter reduction while maintaining input adaptivity. In this way, our $D^2$-MoE successfully compact MoE LLMs to high compression ratios without additional training. Extensive experiments highlight the superiority of our approach, with over 13% performance gains than other compressors on Mixtral|Phi-3.5|DeepSeek|Qwen2 MoE LLMs at 40$\sim$60% compression rates. Codes are available in https://github.com/lliai/D2MoE.
LPZero: Language Model Zero-cost Proxy Search from Zero
Oct 07, 2024



In spite of the outstanding performance, Neural Architecture Search (NAS) is criticized for massive computation. Recently, Zero-shot NAS has emerged as a promising approach by exploiting Zero-cost (ZC) proxies, which markedly reduce computational demands. Despite this, existing ZC proxies heavily rely on expert knowledge and incur significant trial-and-error costs. Particularly in NLP tasks, most existing ZC proxies fail to surpass the performance of the naive baseline. To address these challenges, we introduce a novel framework, \textbf{LPZero}, which is the first to automatically design ZC proxies for various tasks, achieving higher ranking consistency than human-designed proxies. Specifically, we model the ZC proxy as a symbolic equation and incorporate a unified proxy search space that encompasses existing ZC proxies, which are composed of a predefined set of mathematical symbols. To heuristically search for the best ZC proxy, LPZero incorporates genetic programming to find the optimal symbolic composition. We propose a \textit{Rule-based Pruning Strategy (RPS),} which preemptively eliminates unpromising proxies, thereby mitigating the risk of proxy degradation. Extensive experiments on FlexiBERT, GPT-2, and LLaMA-7B demonstrate LPZero's superior ranking ability and performance on downstream tasks compared to current approaches.