 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeGo-Code: Can Modular Curriculum Learning Advance Complex Code Generation? Insights from Text-to-SQL
Apr 20, 2026Recently, code-oriented large language models (LLMs) have demonstrated strong capabilities in translating natural language into executable code. Text-to-SQL is a significant application of this ability, enabling non-technical users to interact with relational databases using natural language. However, state-of-the-art models continue to struggle with highly complex logic, particularly deeply nested statements involving multiple joins and conditions, as well as with real-world database schemas that are noisy or poorly structured. In this paper, we investigate whether curriculum learning can improve the performance of code-based LLMs on Text-to-SQL tasks. Employing benchmarks including Spider and BIRD, we fine-tune models under different curriculum strategies. Our experiments show that naive curriculum, simply ordering training samples by complexity in a single epoch, fails to surpass standard fine-tuning due to catastrophic forgetting. To overcome this, we propose a Modular Adapter Composition (MAC) strategy. By sequentially training tier-specific adapters on incremental complexity levels (Easy to Extra-Hard), we create a scaffolded learning environment that improves performance on complex queries. Our approach not only produces measurable performance gains on the Spider and BIRD benchmarks but also provides a flexible, "Lego-like" architecture, allowing models to be composed and deployed based on specific schema difficulty requirements. These findings demonstrate that structured, modular learning is a superior alternative to monolithic fine-tuning for mastering the syntax and logic of complex code generation.
Empirical Evaluation of PDF Parsing and Chunking for Financial Question Answering with RAG
Apr 13, 2026PDF files are primarily intended for human reading rather than automated processing. In addition, the heterogeneous content of PDFs, such as text, tables, and images, poses significant challenges for parsing and information extraction. To address these difficulties, both practitioners and researchers are increasingly developing new methods, including the promising Retrieval-Augmented Generation (RAG) systems to automated PDF processing. However, there is no comprehensive study investigating how different components and design choices affect the performance of a RAG system for understanding PDFs. In this paper, we propose such a study (1) by focusing on Question Answering, a specific language understanding task, and (2) by leveraging two benchmarks from the financial domain, including TableQuest, our newly generated, publicly available benchmark. We systematically examine multiple PDF parsers and chunking strategies (with varied overlap), along with their potential synergies in preserving document structure and ensuring answer correctness. Overall, our results offer practical guidelines for building robust RAG pipelines for PDF understanding.
AHaSIS: Shared Task on Sentiment Analysis for Arabic Dialects
Nov 17, 2025The hospitality industry in the Arab world increasingly relies on customer feedback to shape services, driving the need for advanced Arabic sentiment analysis tools. To address this challenge, the Sentiment Analysis on Arabic Dialects in the Hospitality Domain shared task focuses on Sentiment Detection in Arabic Dialects. This task leverages a multi-dialect, manually curated dataset derived from hotel reviews originally written in Modern Standard Arabic (MSA) and translated into Saudi and Moroccan (Darija) dialects. The dataset consists of 538 sentiment-balanced reviews spanning positive, neutral, and negative categories. Translations were validated by native speakers to ensure dialectal accuracy and sentiment preservation. This resource supports the development of dialect-aware NLP systems for real-world applications in customer experience analysis. More than 40 teams have registered for the shared task, with 12 submitting systems during the evaluation phase. The top-performing system achieved an F1 score of 0.81, demonstrating the feasibility and ongoing challenges of sentiment analysis across Arabic dialects.
M-DAIGT: A Shared Task on Multi-Domain Detection of AI-Generated Text
Nov 14, 2025The generation of highly fluent text by Large Language Models (LLMs) poses a significant challenge to information integrity and academic research. In this paper, we introduce the Multi-Domain Detection of AI-Generated Text (M-DAIGT) shared task, which focuses on detecting AI-generated text across multiple domains, particularly in news articles and academic writing. M-DAIGT comprises two binary classification subtasks: News Article Detection (NAD) (Subtask 1) and Academic Writing Detection (AWD) (Subtask 2). To support this task, we developed and released a new large-scale benchmark dataset of 30,000 samples, balanced between human-written and AI-generated texts. The AI-generated content was produced using a variety of modern LLMs (e.g., GPT-4, Claude) and diverse prompting strategies. A total of 46 unique teams registered for the shared task, of which four teams submitted final results. All four teams participated in both Subtask 1 and Subtask 2. We describe the methods employed by these participating teams and briefly discuss future directions for M-DAIGT.
AraReasoner: Evaluating Reasoning-Based LLMs for Arabic NLP
Jun 11, 2025Large language models (LLMs) have shown remarkable progress in reasoning abilities and general natural language processing (NLP) tasks, yet their performance on Arabic data, characterized by rich morphology, diverse dialects, and complex script, remains underexplored. This paper presents a comprehensive benchmarking study of multiple reasoning-focused LLMs, with a special emphasis on the newly introduced DeepSeek models, across a suite of fifteen Arabic NLP tasks. We experiment with various strategies, including zero-shot, few-shot, and fine-tuning. This allows us to systematically evaluate performance on datasets covering a range of applications to examine their capacity for linguistic reasoning under different levels of complexity. Our experiments reveal several key findings. First, carefully selecting just three in-context examples delivers an average uplift of over 13 F1 points on classification tasks-boosting sentiment analysis from 35.3% to 87.5% and paraphrase detection from 56.1% to 87.0%. Second, reasoning-focused DeepSeek architectures outperform a strong GPT o4-mini baseline by an average of 12 F1 points on complex inference tasks in the zero-shot setting. Third, LoRA-based fine-tuning yields up to an additional 8 points in F1 and BLEU compared to equivalent increases in model scale. The code is available at https://anonymous.4open.science/r/AraReasoner41299
Is LLM the Silver Bullet to Low-Resource Languages Machine Translation?
Mar 31, 2025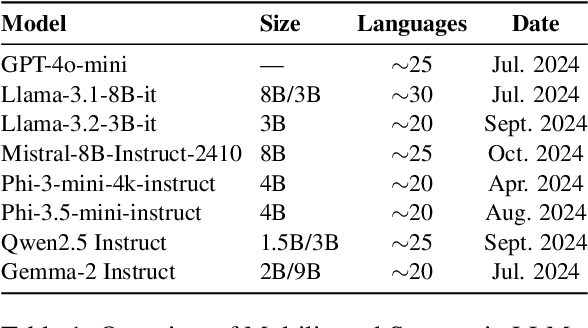
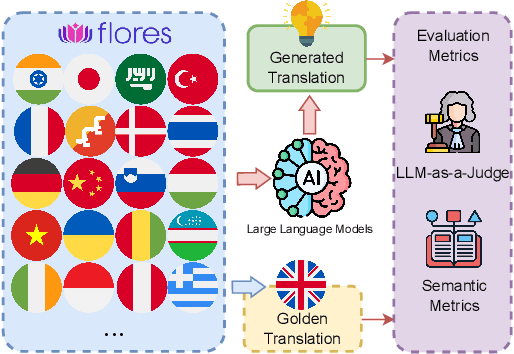
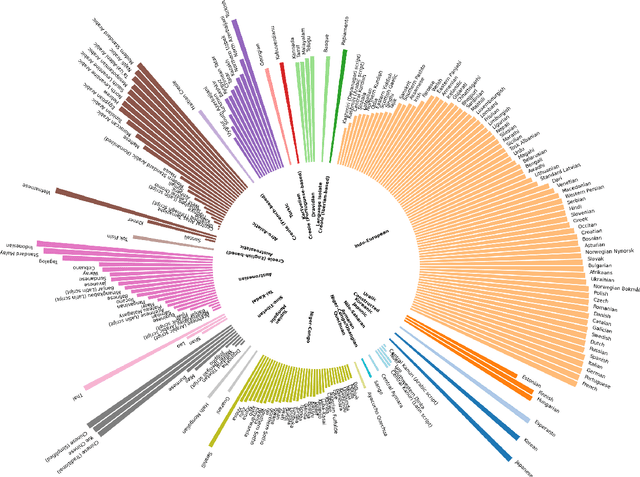
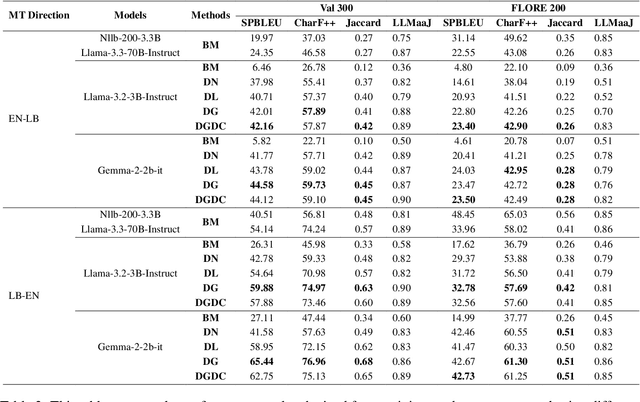
Low-Resource Languages (LRLs) present significant challenges in natural language processing due to their limited linguistic resources and underrepresentation in standard datasets. While recent advancements in Large Language Models (LLMs) and Neural Machine Translation (NMT) have substantially improved translation capabilities for high-resource languages, performance disparities persist for LRLs, particularly impacting privacy-sensitive and resource-constrained scenarios. This paper systematically evaluates the limitations of current LLMs across 200 languages using benchmarks such as FLORES-200. We also explore alternative data sources, including news articles and bilingual dictionaries, and demonstrate how knowledge distillation from large pre-trained models can significantly improve smaller LRL translations. Additionally, we investigate various fine-tuning strategies, revealing that incremental enhancements markedly reduce performance gaps on smaller LLMs.
Dialect2SQL: A Novel Text-to-SQL Dataset for Arabic Dialects with a Focus on Moroccan Darija
Jan 20, 2025



The task of converting natural language questions (NLQs) into executable SQL queries, known as text-to-SQL, has gained significant interest in recent years, as it enables non-technical users to interact with relational databases. Many benchmarks, such as SPIDER and WikiSQL, have contributed to the development of new models and the evaluation of their performance. In addition, other datasets, like SEDE and BIRD, have introduced more challenges and complexities to better map real-world scenarios. However, these datasets primarily focus on high-resource languages such as English and Chinese. In this work, we introduce Dialect2SQL, the first large-scale, cross-domain text-to-SQL dataset in an Arabic dialect. It consists of 9,428 NLQ-SQL pairs across 69 databases in various domains. Along with SQL-related challenges such as long schemas, dirty values, and complex queries, our dataset also incorporates the complexities of the Moroccan dialect, which is known for its diverse source languages, numerous borrowed words, and unique expressions. This demonstrates that our dataset will be a valuable contribution to both the text-to-SQL community and the development of resources for low-resource languages.
CallNavi: A Study and Challenge on Function Calling Routing and Invocation in Large Language Models
Jan 09, 2025



Interacting with a software system via a chatbot can be challenging, especially when the chatbot needs to generate API calls, in the right order and with the right parameters, to communicate with the system. API calling in chatbot systems poses significant challenges, particularly in complex, multi-step tasks requiring accurate API selection and execution. We contribute to this domain in three ways: first, by introducing a novel dataset designed to assess models on API function selection, parameter generation, and nested API calls; second, by benchmarking state-of-the-art language models across varying levels of complexity to evaluate their performance in API function generation and parameter accuracy; and third, by proposing an enhanced API routing method that combines general-purpose large language models for API selection with fine-tuned models for parameter generation and some prompt engineering approach. These approaches lead to substantial improvements in handling complex API tasks, offering practical advancements for real-world API-driven chatbot systems.
DreamFactory: Pioneering Multi-Scene Long Video Generation with a Multi-Agent Framework
Aug 21, 2024Current video generation models excel at creating short, realistic clips, but struggle with longer, multi-scene videos. We introduce \texttt{DreamFactory}, an LLM-based framework that tackles this challenge. \texttt{DreamFactory} leverages multi-agent collaboration principles and a Key Frames Iteration Design Method to ensure consistency and style across long videos. It utilizes Chain of Thought (COT) to address uncertainties inherent in large language models. \texttt{DreamFactory} generates long, stylistically coherent, and complex videos. Evaluating these long-form videos presents a challenge. We propose novel metrics such as Cross-Scene Face Distance Score and Cross-Scene Style Consistency Score. To further research in this area, we contribute the Multi-Scene Videos Dataset containing over 150 human-rated videos.
AraFinNLP 2024: The First Arabic Financial NLP Shared Task
Jul 13, 2024



The expanding financial markets of the Arab world require sophisticated Arabic NLP tools. To address this need within the banking domain, the Arabic Financial NLP (AraFinNLP) shared task proposes two subtasks: (i) Multi-dialect Intent Detection and (ii) Cross-dialect Translation and Intent Preservation. This shared task uses the updated ArBanking77 dataset, which includes about 39k parallel queries in MSA and four dialects. Each query is labeled with one or more of a common 77 intents in the banking domain. These resources aim to foster the development of robust financial Arabic NLP, particularly in the areas of machine translation and banking chat-bots. A total of 45 unique teams registered for this shared task, with 11 of them actively participated in the test phase. Specifically, 11 teams participated in Subtask 1, while only 1 team participated in Subtask 2. The winning team of Subtask 1 achieved F1 score of 0.8773, and the only team submitted in Subtask 2 achieved a 1.667 BLEU score.