 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Last Visible Pixel: Probing Fine-Scale Perception in Vision-Language Models
Jun 05, 2026Recent vision-language models (VLMs) excel at multimodal understanding and reasoning, yet their fine-grained visual perception remains underexplored. A natural extension of ``How many r are there in Strawberry?'' asks: how small a visual pattern can a VLM reliably perceive? As such, we introduce FineSightBench, a new benchmark that systematically probes this limit by separating perception tasks (pixel-level recognition of letters, shapes, objects) from reasoning tasks (spatial reasoning, counting, ordering over small targets) across controlled scales of 4--48px. Through comprehensive experiments and detailed failure mode analysis on state-of-the-art models, we reveal a sharp dissociation: perception saturates around 12px, while reasoning remains limited even at larger scales, with persistent numeracy and sequence errors. These findings expose fundamental deficiencies in VLMs' fine-scale visual reasoning that demand more rigorous evaluation.
Agent Skill Framework: Perspectives on the Potential of Small Language Models in Industrial Environments
Feb 18, 2026Agent Skill framework, now widely and officially supported by major players such as GitHub Copilot, LangChain, and OpenAI, performs especially well with proprietary models by improving context engineering, reducing hallucinations, and boosting task accuracy. Based on these observations, an investigation is conducted to determine whether the Agent Skill paradigm provides similar benefits to small language models (SLMs). This question matters in industrial scenarios where continuous reliance on public APIs is infeasible due to data-security and budget constraints requirements, and where SLMs often show limited generalization in highly customized scenarios. This work introduces a formal mathematical definition of the Agent Skill process, followed by a systematic evaluation of language models of varying sizes across multiple use cases. The evaluation encompasses two open-source tasks and a real-world insurance claims data set. The results show that tiny models struggle with reliable skill selection, while moderately sized SLMs (approximately 12B - 30B) parameters) benefit substantially from the Agent Skill approach. Moreover, code-specialized variants at around 80B parameters achieve performance comparable to closed-source baselines while improving GPU efficiency. Collectively, these findings provide a comprehensive and nuanced characterization of the capabilities and constraints of the framework, while providing actionable insights for the effective deployment of Agent Skills in SLM-centered environments.
NegBLEURT Forest: Leveraging Inconsistencies for Detecting Jailbreak Attacks
Nov 14, 2025



Jailbreak attacks designed to bypass safety mechanisms pose a serious threat by prompting LLMs to generate harmful or inappropriate content, despite alignment with ethical guidelines. Crafting universal filtering rules remains difficult due to their inherent dependence on specific contexts. To address these challenges without relying on threshold calibration or model fine-tuning, this work introduces a semantic consistency analysis between successful and unsuccessful responses, demonstrating that a negation-aware scoring approach captures meaningful patterns. Building on this insight, a novel detection framework called NegBLEURT Forest is proposed to evaluate the degree of alignment between outputs elicited by adversarial prompts and expected safe behaviors. It identifies anomalous responses using the Isolation Forest algorithm, enabling reliable jailbreak detection. Experimental results show that the proposed method consistently achieves top-tier performance, ranking first or second in accuracy across diverse models using the crafted dataset, while competing approaches exhibit notable sensitivity to model and data variations.
Is LLM the Silver Bullet to Low-Resource Languages Machine Translation?
Mar 31, 2025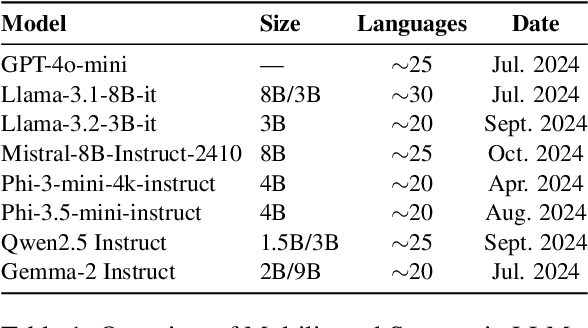
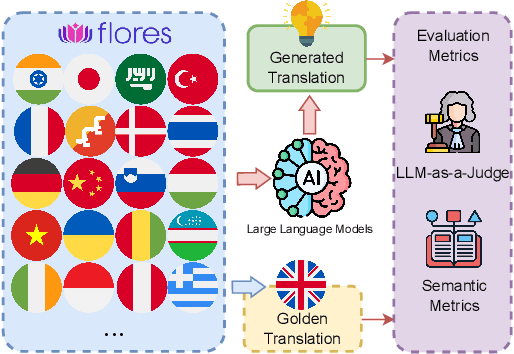
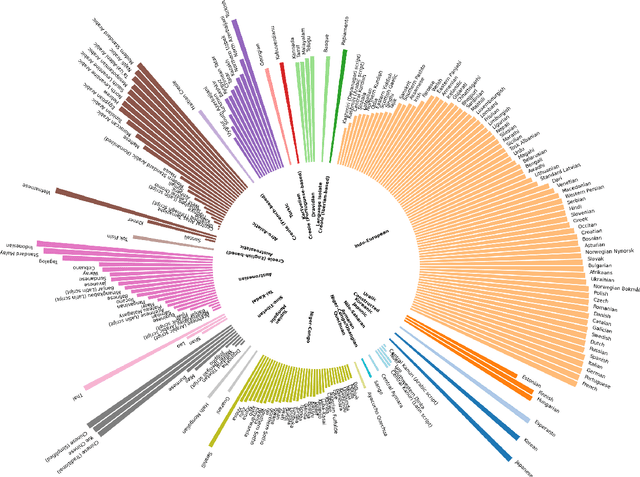
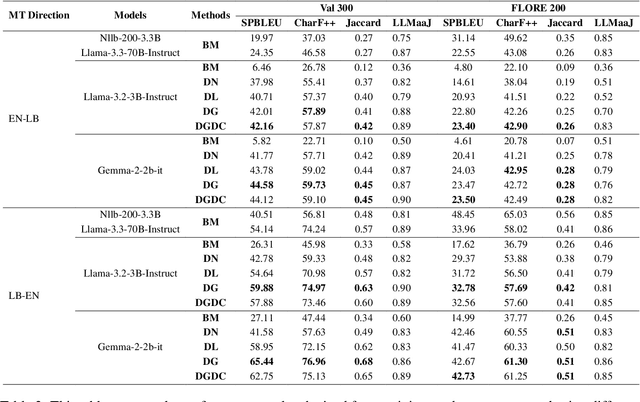
Low-Resource Languages (LRLs) present significant challenges in natural language processing due to their limited linguistic resources and underrepresentation in standard datasets. While recent advancements in Large Language Models (LLMs) and Neural Machine Translation (NMT) have substantially improved translation capabilities for high-resource languages, performance disparities persist for LRLs, particularly impacting privacy-sensitive and resource-constrained scenarios. This paper systematically evaluates the limitations of current LLMs across 200 languages using benchmarks such as FLORES-200. We also explore alternative data sources, including news articles and bilingual dictionaries, and demonstrate how knowledge distillation from large pre-trained models can significantly improve smaller LRL translations. Additionally, we investigate various fine-tuning strategies, revealing that incremental enhancements markedly reduce performance gaps on smaller LLMs.