 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Necessity of Setting Temperature in LLM-as-a-Judge
Mar 30, 2026LLM-as-a-Judge has emerged as an effective and low-cost paradigm for evaluating text quality and factual correctness. Prior studies have shown substantial agreement between LLM judges and human experts, even on tasks that are difficult to assess automatically. In practice, researchers commonly employ fixed temperature configurations during the evaluation process-with values of 0.1 and 1.0 being the most prevalent choices-a convention that is largely empirical rather than principled. However, recent researches suggest that LLM performance exhibits non-trivial sensitivity to temperature settings, that lower temperatures do not universally yield optimal outcomes, and that such effects are highly task-dependent. This raises a critical research question: does temperature influence judge performance in LLM centric evaluation? To address this, we systematically investigate the relationship between temperature and judge performance through a series of controlled experiments, and further adopt a causal inference framework within our empirical statistical analysis to rigorously examine the direct causal effect of temperature on judge behavior, offering actionable engineering insights for the design of LLM-centric evaluation pipelines.
Agent Skill Framework: Perspectives on the Potential of Small Language Models in Industrial Environments
Feb 18, 2026Agent Skill framework, now widely and officially supported by major players such as GitHub Copilot, LangChain, and OpenAI, performs especially well with proprietary models by improving context engineering, reducing hallucinations, and boosting task accuracy. Based on these observations, an investigation is conducted to determine whether the Agent Skill paradigm provides similar benefits to small language models (SLMs). This question matters in industrial scenarios where continuous reliance on public APIs is infeasible due to data-security and budget constraints requirements, and where SLMs often show limited generalization in highly customized scenarios. This work introduces a formal mathematical definition of the Agent Skill process, followed by a systematic evaluation of language models of varying sizes across multiple use cases. The evaluation encompasses two open-source tasks and a real-world insurance claims data set. The results show that tiny models struggle with reliable skill selection, while moderately sized SLMs (approximately 12B - 30B) parameters) benefit substantially from the Agent Skill approach. Moreover, code-specialized variants at around 80B parameters achieve performance comparable to closed-source baselines while improving GPU efficiency. Collectively, these findings provide a comprehensive and nuanced characterization of the capabilities and constraints of the framework, while providing actionable insights for the effective deployment of Agent Skills in SLM-centered environments.
NegBLEURT Forest: Leveraging Inconsistencies for Detecting Jailbreak Attacks
Nov 14, 2025



Jailbreak attacks designed to bypass safety mechanisms pose a serious threat by prompting LLMs to generate harmful or inappropriate content, despite alignment with ethical guidelines. Crafting universal filtering rules remains difficult due to their inherent dependence on specific contexts. To address these challenges without relying on threshold calibration or model fine-tuning, this work introduces a semantic consistency analysis between successful and unsuccessful responses, demonstrating that a negation-aware scoring approach captures meaningful patterns. Building on this insight, a novel detection framework called NegBLEURT Forest is proposed to evaluate the degree of alignment between outputs elicited by adversarial prompts and expected safe behaviors. It identifies anomalous responses using the Isolation Forest algorithm, enabling reliable jailbreak detection. Experimental results show that the proposed method consistently achieves top-tier performance, ranking first or second in accuracy across diverse models using the crafted dataset, while competing approaches exhibit notable sensitivity to model and data variations.
Exploring the Impact of Temperature on Large Language Models:Hot or Cold?
Jun 08, 2025



The sampling temperature, a critical hyperparameter in large language models (LLMs), modifies the logits before the softmax layer, thereby reshaping the distribution of output tokens. Recent studies have challenged the Stochastic Parrots analogy by demonstrating that LLMs are capable of understanding semantics rather than merely memorizing data and that randomness, modulated by sampling temperature, plays a crucial role in model inference. In this study, we systematically evaluated the impact of temperature in the range of 0 to 2 on data sets designed to assess six different capabilities, conducting statistical analyses on open source models of three different sizes: small (1B--4B), medium (6B--13B), and large (40B--80B). Our findings reveal distinct skill-specific effects of temperature on model performance, highlighting the complexity of optimal temperature selection in practical applications. To address this challenge, we propose a BERT-based temperature selector that takes advantage of these observed effects to identify the optimal temperature for a given prompt. We demonstrate that this approach can significantly improve the performance of small and medium models in the SuperGLUE datasets. Furthermore, our study extends to FP16 precision inference, revealing that temperature effects are consistent with those observed in 4-bit quantized models. By evaluating temperature effects up to 4.0 in three quantized models, we find that the Mutation Temperature -- the point at which significant performance changes occur -- increases with model size.
Small Language Models in the Real World: Insights from Industrial Text Classification
May 21, 2025With the emergence of ChatGPT, Transformer models have significantly advanced text classification and related tasks. Decoder-only models such as Llama exhibit strong performance and flexibility, yet they suffer from inefficiency on inference due to token-by-token generation, and their effectiveness in text classification tasks heavily depends on prompt quality. Moreover, their substantial GPU resource requirements often limit widespread adoption. Thus, the question of whether smaller language models are capable of effectively handling text classification tasks emerges as a topic of significant interest. However, the selection of appropriate models and methodologies remains largely underexplored. In this paper, we conduct a comprehensive evaluation of prompt engineering and supervised fine-tuning methods for transformer-based text classification. Specifically, we focus on practical industrial scenarios, including email classification, legal document categorization, and the classification of extremely long academic texts. We examine the strengths and limitations of smaller models, with particular attention to both their performance and their efficiency in Video Random-Access Memory (VRAM) utilization, thereby providing valuable insights for the local deployment and application of compact models in industrial settings.
Is LLM the Silver Bullet to Low-Resource Languages Machine Translation?
Mar 31, 2025
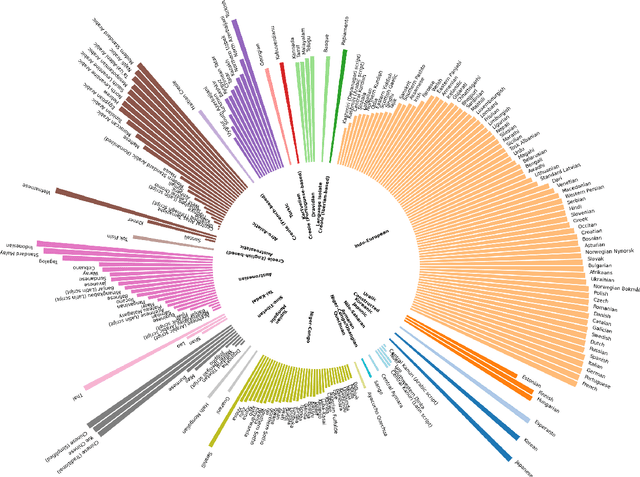
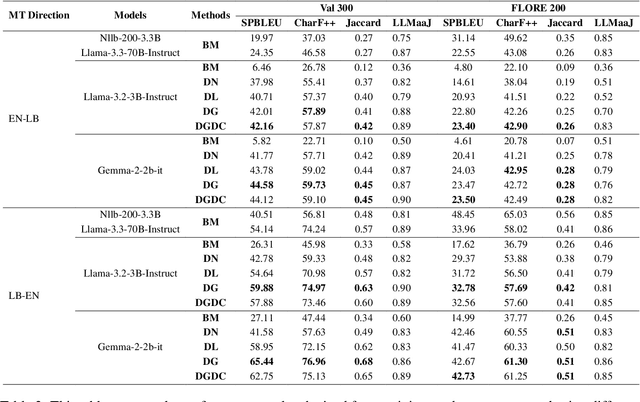
Low-Resource Languages (LRLs) present significant challenges in natural language processing due to their limited linguistic resources and underrepresentation in standard datasets. While recent advancements in Large Language Models (LLMs) and Neural Machine Translation (NMT) have substantially improved translation capabilities for high-resource languages, performance disparities persist for LRLs, particularly impacting privacy-sensitive and resource-constrained scenarios. This paper systematically evaluates the limitations of current LLMs across 200 languages using benchmarks such as FLORES-200. We also explore alternative data sources, including news articles and bilingual dictionaries, and demonstrate how knowledge distillation from large pre-trained models can significantly improve smaller LRL translations. Additionally, we investigate various fine-tuning strategies, revealing that incremental enhancements markedly reduce performance gaps on smaller LLMs.