 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHotelQuEST: Balancing Quality and Efficiency in Agentic Search
Feb 27, 2026Agentic search has emerged as a promising paradigm for adaptive retrieval systems powered by large language models (LLMs). However, existing benchmarks primarily focus on quality, overlooking efficiency factors that are critical for real-world deployment. Moreover, real-world user queries often contain underspecified preferences, a challenge that remains largely underexplored in current agentic search evaluation. As a result, many agentic search systems remain impractical despite their impressive performance. In this work, we introduce HotelQuEST, a benchmark comprising 214 hotel search queries that range from simple factual requests to complex queries, enabling evaluation across the full spectrum of query difficulty. We further address the challenge of evaluating underspecified user preferences by collecting clarifications that make annotators' implicit preferences explicit for evaluation. We find that LLM-based agents achieve higher accuracy than traditional retrievers, but at substantially higher costs due to redundant tool calls and suboptimal routing that fails to match query complexity to model capability. Our analysis exposes inefficiencies in current agentic search systems and demonstrates substantial potential for cost-aware optimization.
X-Cross: Dynamic Integration of Language Models for Cross-Domain Sequential Recommendation
Apr 29, 2025



As new products are emerging daily, recommendation systems are required to quickly adapt to possible new domains without needing extensive retraining. This work presents ``X-Cross'' -- a novel cross-domain sequential-recommendation model that recommends products in new domains by integrating several domain-specific language models; each model is fine-tuned with low-rank adapters (LoRA). Given a recommendation prompt, operating layer by layer, X-Cross dynamically refines the representation of each source language model by integrating knowledge from all other models. These refined representations are propagated from one layer to the next, leveraging the activations from each domain adapter to ensure domain-specific nuances are preserved while enabling adaptability across domains. Using Amazon datasets for sequential recommendation, X-Cross achieves performance comparable to a model that is fine-tuned with LoRA, while using only 25% of the additional parameters. In cross-domain tasks, such as adapting from Toys domain to Tools, Electronics or Sports, X-Cross demonstrates robust performance, while requiring about 50%-75% less fine-tuning data than LoRA to make fine-tuning effective. Furthermore, X-Cross achieves significant improvement in accuracy over alternative cross-domain baselines. Overall, X-Cross enables scalable and adaptive cross-domain recommendations, reducing computational overhead and providing an efficient solution for data-constrained environments.
Unsupervised Search Algorithm Configuration using Query Performance Prediction
Oct 03, 2022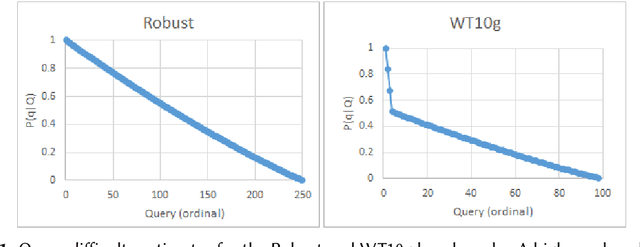
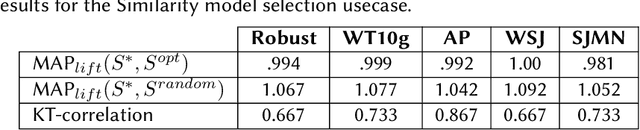
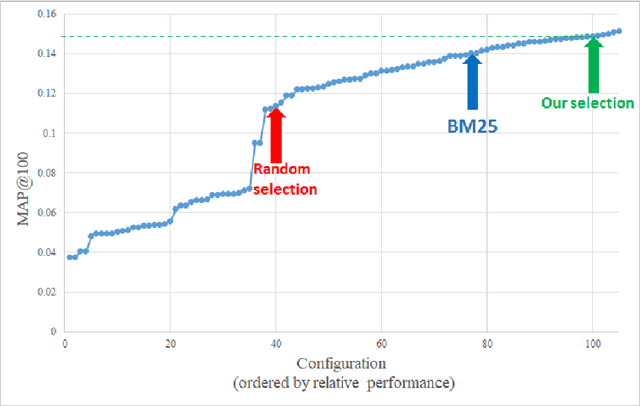
Search engine configuration can be quite difficult for inexpert developers. Instead, an auto-configuration approach can be used to speed up development time. Yet, such an automatic process usually requires relevance labels to train a supervised model. In this work, we suggest a simple solution based on query performance prediction that requires no relevance labels but only a sample of queries in a given domain. Using two example usecases we demonstrate the merits of our solution.
Learning to Diversify for Product Question Generation
Jul 06, 2022
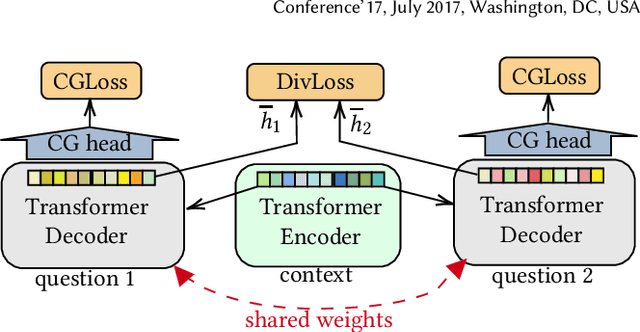

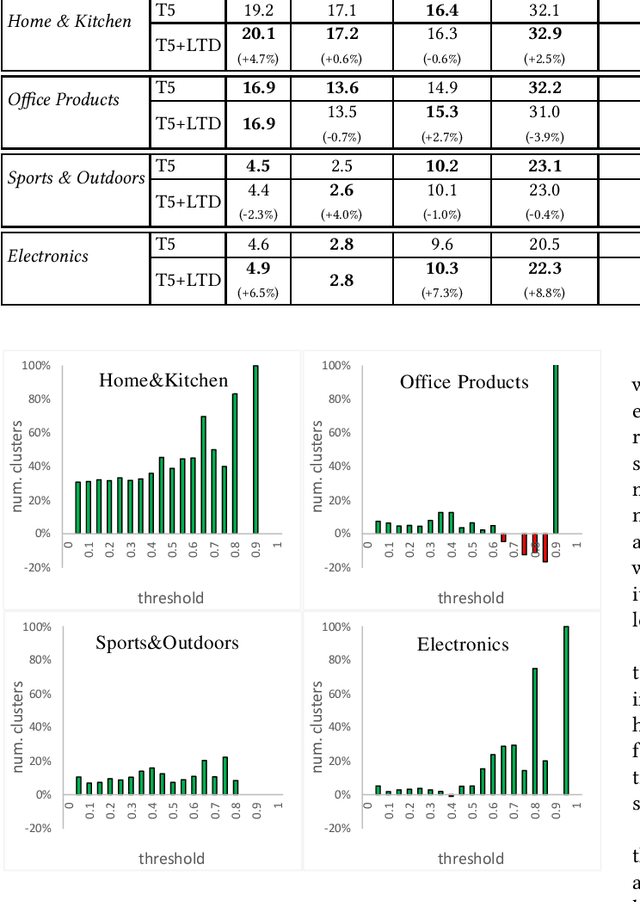
We address the product question generation task. For a given product description, our goal is to generate questions that reflect potential user information needs that are either missing or not well covered in the description. Moreover, we wish to cover diverse user information needs that may span a multitude of product types. To this end, we first show how the T5 pre-trained Transformer encoder-decoder model can be fine-tuned for the task. Yet, while the T5 generated questions have a reasonable quality compared to the state-of-the-art method for the task (KPCNet), many of such questions are still too general, resulting in a sub-optimal global question diversity. As an alternative, we propose a novel learning-to-diversify (LTD) fine-tuning approach that allows to enrich the language learned by the underlying Transformer model. Our empirical evaluation shows that, using our approach significantly improves the global diversity of the underlying Transformer model, while preserves, as much as possible, its generation relevance.
tBDFS: Temporal Graph Neural Network Leveraging DFS
Jun 12, 2022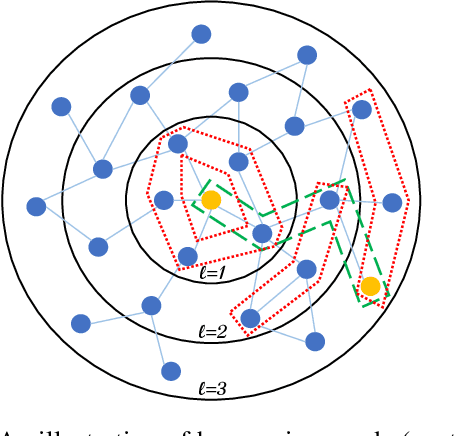
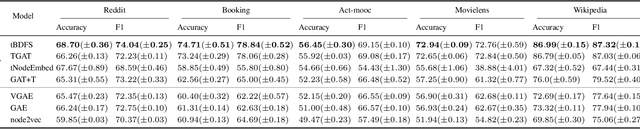

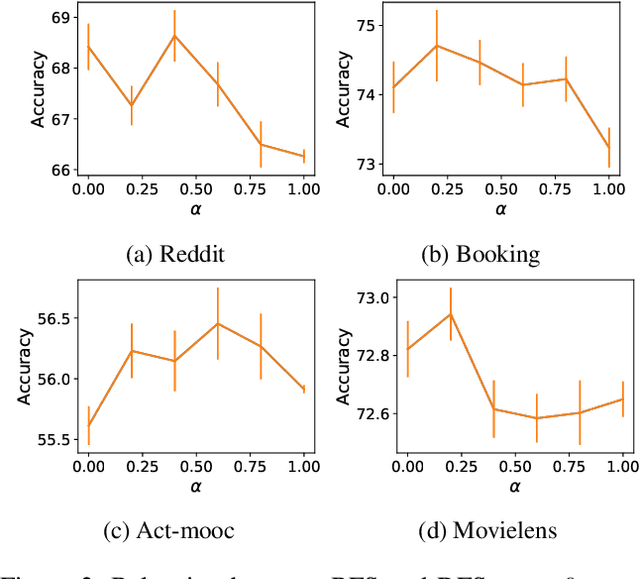
Temporal graph neural networks (temporal GNNs) have been widely researched, reaching state-of-the-art results on multiple prediction tasks. A common approach employed by most previous works is to apply a layer that aggregates information from the historical neighbors of a node. Taking a different research direction, in this work, we propose tBDFS -- a novel temporal GNN architecture. tBDFS applies a layer that efficiently aggregates information from temporal paths to a given (target) node in the graph. For each given node, the aggregation is applied in two stages: (1) A single representation is learned for each temporal path ending in that node, and (2) all path representations are aggregated into a final node representation. Overall, our goal is not to add new information to a node, but rather observe the same exact information in a new perspective. This allows our model to directly observe patterns that are path-oriented rather than neighborhood-oriented. This can be thought as a Depth-First Search (DFS) traversal over the temporal graph, compared to the popular Breath-First Search (BFS) traversal that is applied in previous works. We evaluate tBDFS over multiple link prediction tasks and show its favorable performance compared to state-of-the-art baselines. To the best of our knowledge, we are the first to apply a temporal-DFS neural network.
Sequential Modeling with Multiple Attributes for Watchlist Recommendation in E-Commerce
Oct 24, 2021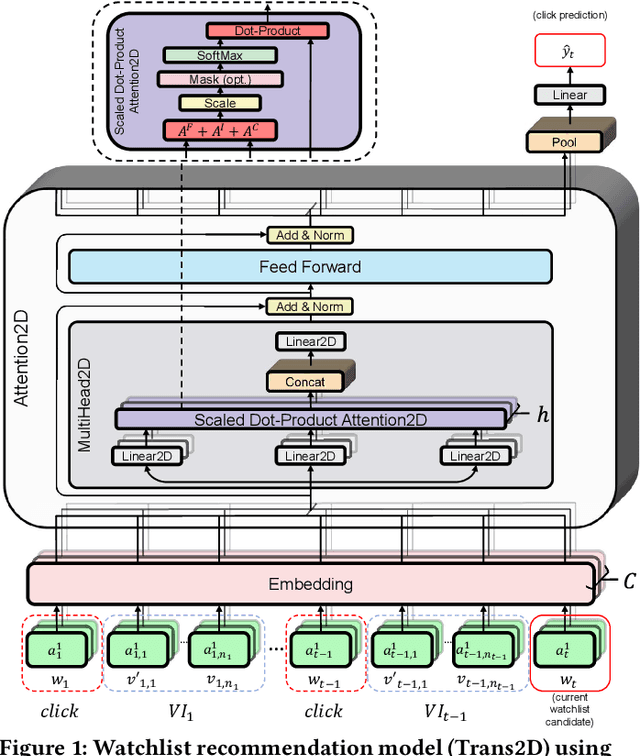
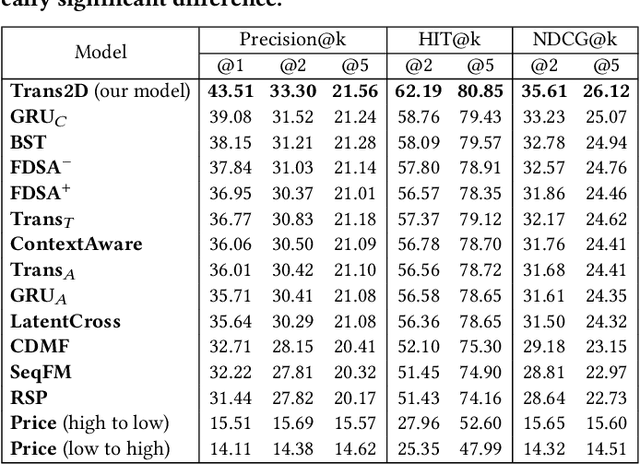

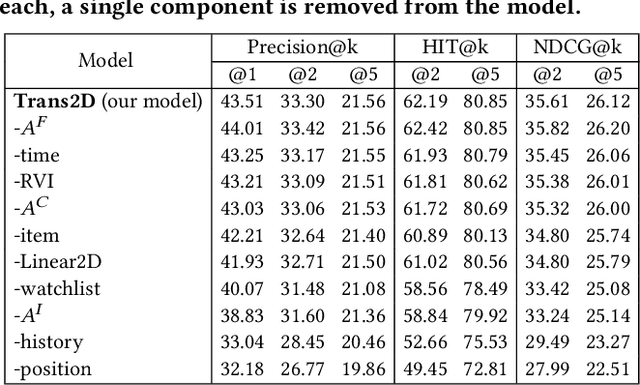
In e-commerce, the watchlist enables users to track items over time and has emerged as a primary feature, playing an important role in users' shopping journey. Watchlist items typically have multiple attributes whose values may change over time (e.g., price, quantity). Since many users accumulate dozens of items on their watchlist, and since shopping intents change over time, recommending the top watchlist items in a given context can be valuable. In this work, we study the watchlist functionality in e-commerce and introduce a novel watchlist recommendation task. Our goal is to prioritize which watchlist items the user should pay attention to next by predicting the next items the user will click. We cast this task as a specialized sequential recommendation task and discuss its characteristics. Our proposed recommendation model, Trans2D, is built on top of the Transformer architecture, where we further suggest a novel extended attention mechanism (Attention2D) that allows to learn complex item-item, attribute-attribute and item-attribute patterns from sequential-data with multiple item attributes. Using a large-scale watchlist dataset from eBay, we evaluate our proposed model, where we demonstrate its superiority compared to multiple state-of-the-art baselines, many of which are adapted for this task.
PreSizE: Predicting Size in E-Commerce using Transformers
May 04, 2021
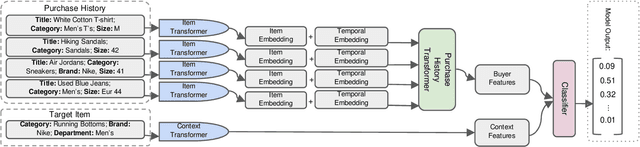
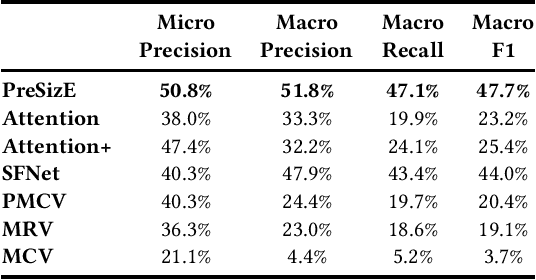
Recent advances in the e-commerce fashion industry have led to an exploration of novel ways to enhance buyer experience via improved personalization. Predicting a proper size for an item to recommend is an important personalization challenge, and is being studied in this work. Earlier works in this field either focused on modeling explicit buyer fitment feedback or modeling of only a single aspect of the problem (e.g., specific category, brand, etc.). More recent works proposed richer models, either content-based or sequence-based, better accounting for content-based aspects of the problem or better modeling the buyer's online journey. However, both these approaches fail in certain scenarios: either when encountering unseen items (sequence-based models) or when encountering new users (content-based models). To address the aforementioned gaps, we propose PreSizE - a novel deep learning framework which utilizes Transformers for accurate size prediction. PreSizE models the effect of both content-based attributes, such as brand and category, and the buyer's purchase history on her size preferences. Using an extensive set of experiments on a large-scale e-commerce dataset, we demonstrate that PreSizE is capable of achieving superior prediction performance compared to previous state-of-the-art baselines. By encoding item attributes, PreSizE better handles cold-start cases with unseen items, and cases where buyers have little past purchase data. As a proof of concept, we demonstrate that size predictions made by PreSizE can be effectively integrated into an existing production recommender system yielding very effective features and significantly improving recommendations.
Conversational Document Prediction to Assist Customer Care Agents
Oct 05, 2020
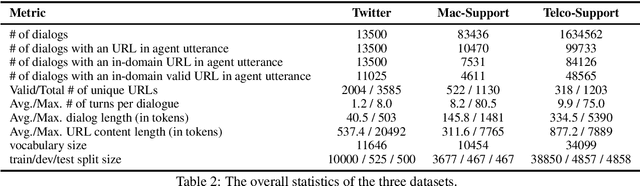

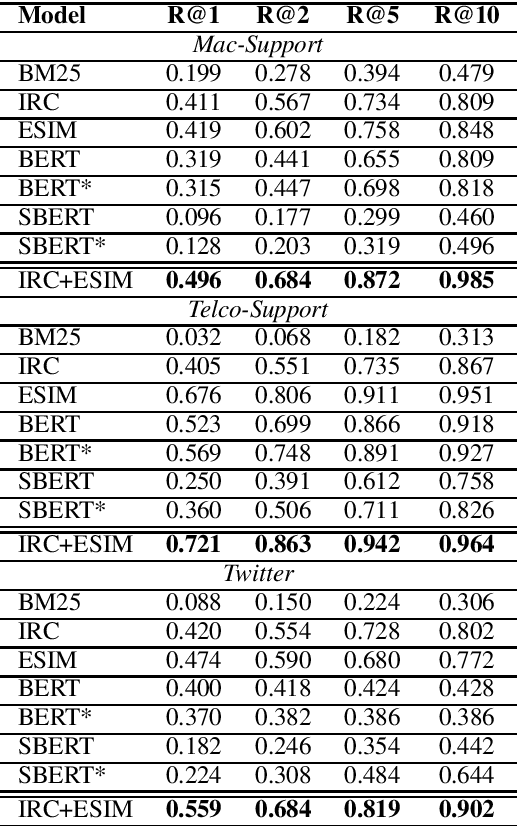
A frequent pattern in customer care conversations is the agents responding with appropriate webpage URLs that address users' needs. We study the task of predicting the documents that customer care agents can use to facilitate users' needs. We also introduce a new public dataset which supports the aforementioned problem. Using this dataset and two others, we investigate state-of-the art deep learning (DL) and information retrieval (IR) models for the task. Additionally, we analyze the practicality of such systems in terms of inference time complexity. Our show that an hybrid IR+DL approach provides the best of both worlds.
A Study of Human Summaries of Scientific Articles
Feb 10, 2020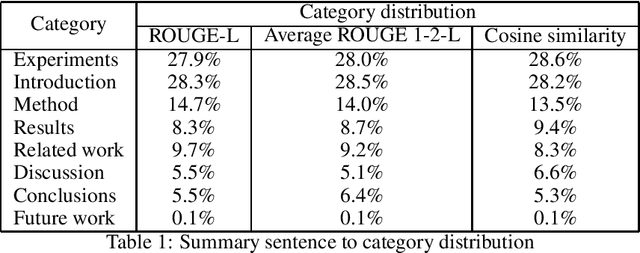

Researchers and students face an explosion of newly published papers which may be relevant to their work. This led to a trend of sharing human summaries of scientific papers. We analyze the summaries shared in one of these platforms Shortscience.org. The goal is to characterize human summaries of scientific papers, and use some of the insights obtained to improve and adapt existing automatic summarization systems to the domain of scientific papers.
A Summarization System for Scientific Documents
Aug 29, 2019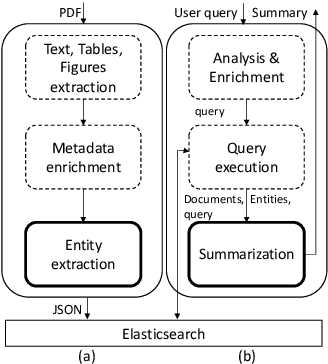
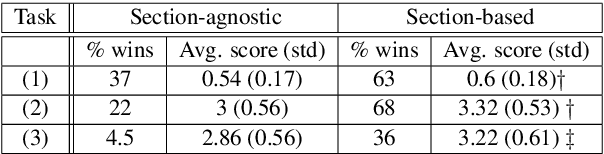
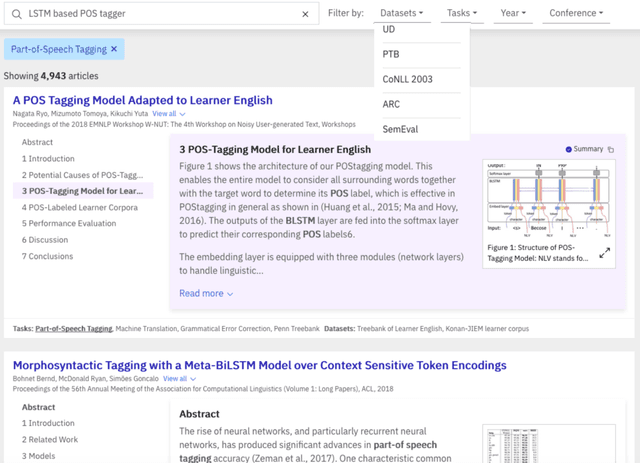
We present a novel system providing summaries for Computer Science publications. Through a qualitative user study, we identified the most valuable scenarios for discovery, exploration and understanding of scientific documents. Based on these findings, we built a system that retrieves and summarizes scientific documents for a given information need, either in form of a free-text query or by choosing categorized values such as scientific tasks, datasets and more. Our system ingested 270,000 papers, and its summarization module aims to generate concise yet detailed summaries. We validated our approach with human experts.