 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGranite-speech: open-source speech-aware LLMs with strong English ASR capabilities
May 14, 2025Granite-speech LLMs are compact and efficient speech language models specifically designed for English ASR and automatic speech translation (AST). The models were trained by modality aligning the 2B and 8B parameter variants of granite-3.3-instruct to speech on publicly available open-source corpora containing audio inputs and text targets consisting of either human transcripts for ASR or automatically generated translations for AST. Comprehensive benchmarking shows that on English ASR, which was our primary focus, they outperform several competitors' models that were trained on orders of magnitude more proprietary data, and they keep pace on English-to-X AST for major European languages, Japanese, and Chinese. The speech-specific components are: a conformer acoustic encoder using block attention and self-conditioning trained with connectionist temporal classification, a windowed query-transformer speech modality adapter used to do temporal downsampling of the acoustic embeddings and map them to the LLM text embedding space, and LoRA adapters to further fine-tune the text LLM. Granite-speech-3.3 operates in two modes: in speech mode, it performs ASR and AST by activating the encoder, projector, and LoRA adapters; in text mode, it calls the underlying granite-3.3-instruct model directly (without LoRA), essentially preserving all the text LLM capabilities and safety. Both models are freely available on HuggingFace (https://huggingface.co/ibm-granite/granite-speech-3.3-2b and https://huggingface.co/ibm-granite/granite-speech-3.3-8b) and can be used for both research and commercial purposes under a permissive Apache 2.0 license.
A new data augmentation method for intent classification enhancement and its application on spoken conversation datasets
Feb 21, 2022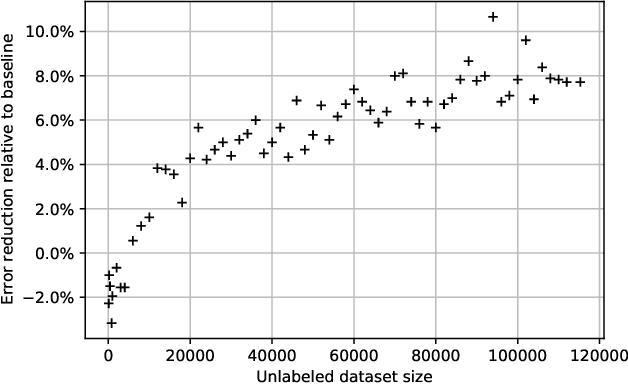
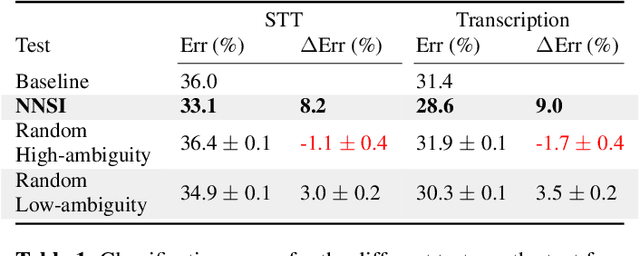
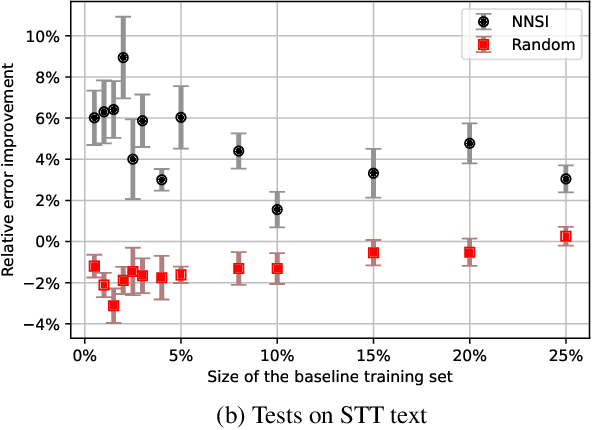
Intent classifiers are vital to the successful operation of virtual agent systems. This is especially so in voice activated systems where the data can be noisy with many ambiguous directions for user intents. Before operation begins, these classifiers are generally lacking in real-world training data. Active learning is a common approach used to help label large amounts of collected user input. However, this approach requires many hours of manual labeling work. We present the Nearest Neighbors Scores Improvement (NNSI) algorithm for automatic data selection and labeling. The NNSI reduces the need for manual labeling by automatically selecting highly-ambiguous samples and labeling them with high accuracy. This is done by integrating the classifier's output from a semantically similar group of text samples. The labeled samples can then be added to the training set to improve the accuracy of the classifier. We demonstrated the use of NNSI on two large-scale, real-life voice conversation systems. Evaluation of our results showed that our method was able to select and label useful samples with high accuracy. Adding these new samples to the training data significantly improved the classifiers and reduced error rates by up to 10%.