 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Precision of CNNs for Magnetic Resonance Spectral Modeling
Sep 10, 2024


Magnetic resonance spectroscopic imaging is a widely available imaging modality that can non-invasively provide a metabolic profile of the tissue of interest, yet is challenging to integrate clinically. One major reason is the expensive, expert data processing and analysis that is required. Using machine learning to predict MRS-related quantities offers avenues around this problem, but deep learning models bring their own challenges, especially model trust. Current research trends focus primarily on mean error metrics, but comprehensive precision metrics are also needed, e.g. standard deviations, confidence intervals, etc.. This work highlights why more comprehensive error characterization is important and how to improve the precision of CNNs for spectral modeling, a quantitative task. The results highlight advantages and trade-offs of these techniques that should be considered when addressing such regression tasks with CNNs. Detailed insights into the underlying mechanisms of each technique, and how they interact with other techniques, are discussed in depth.
Deep Quality Estimation: Creating Surrogate Models for Human Quality Ratings
May 17, 2022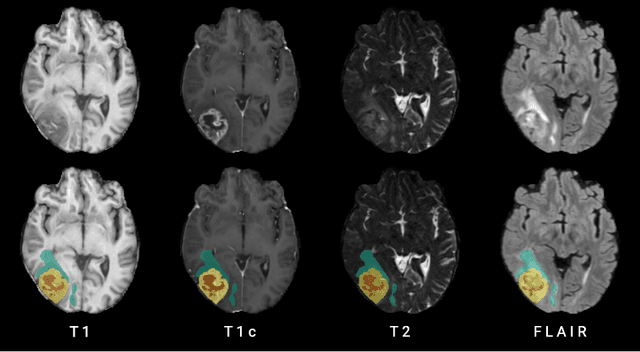
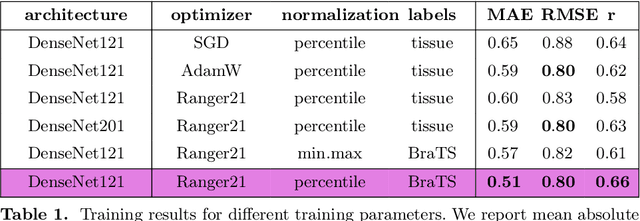
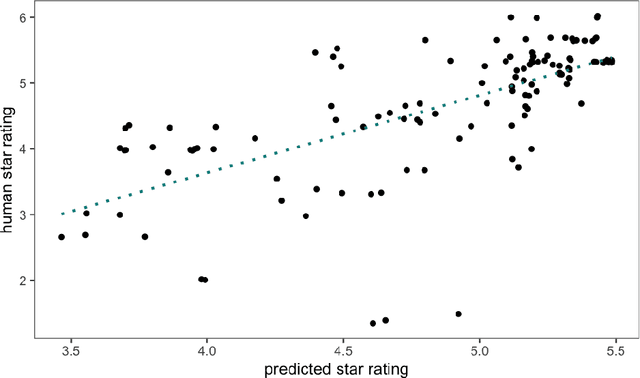
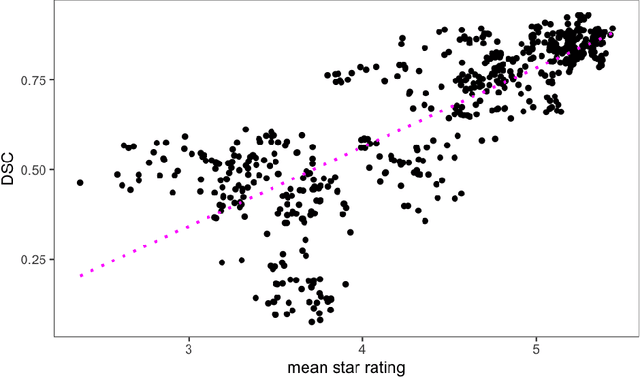
Human ratings are abstract representations of segmentation quality. To approximate human quality ratings on scarce expert data, we train surrogate quality estimation models. We evaluate on a complex multi-class segmentation problem, specifically glioma segmentation following the BraTS annotation protocol. The training data features quality ratings from 15 expert neuroradiologists on a scale ranging from 1 to 6 stars for various computer-generated and manual 3D annotations. Even though the networks operate on 2D images and with scarce training data, we can approximate segmentation quality within a margin of error comparable to human intra-rater reliability. Segmentation quality prediction has broad applications. While an understanding of segmentation quality is imperative for successful clinical translation of automatic segmentation quality algorithms, it can play an essential role in training new segmentation models. Due to the split-second inference times, it can be directly applied within a loss function or as a fully-automatic dataset curation mechanism in a federated learning setting.
Face Super-Resolution Guided by 3D Facial Priors
Jul 18, 2020
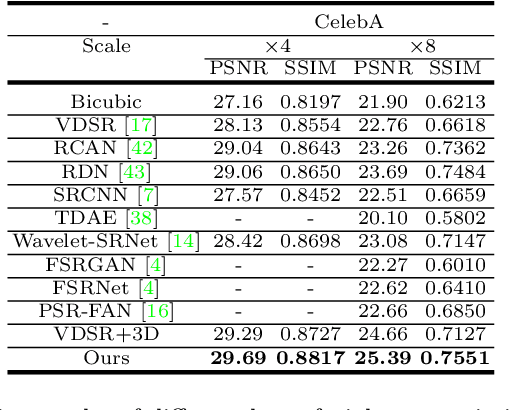
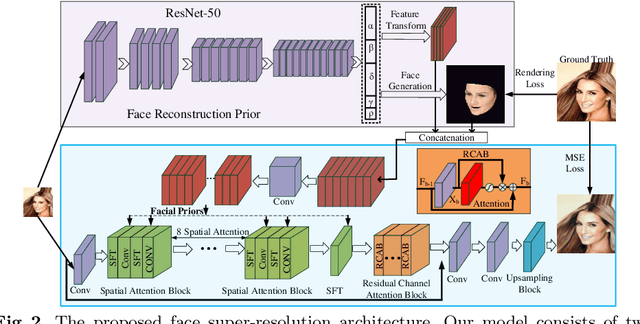
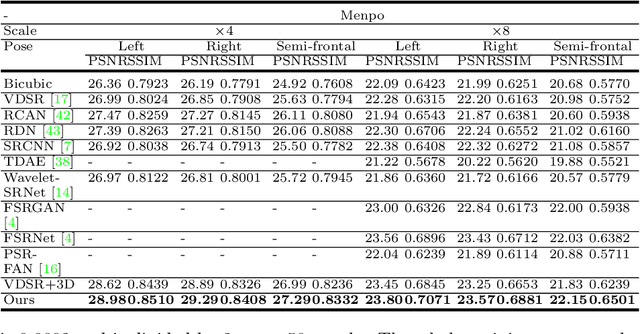
State-of-the-art face super-resolution methods employ deep convolutional neural networks to learn a mapping between low- and high- resolution facial patterns by exploring local appearance knowledge. However, most of these methods do not well exploit facial structures and identity information, and struggle to deal with facial images that exhibit large pose variations. In this paper, we propose a novel face super-resolution method that explicitly incorporates 3D facial priors which grasp the sharp facial structures. Our work is the first to explore 3D morphable knowledge based on the fusion of parametric descriptions of face attributes (e.g., identity, facial expression, texture, illumination, and face pose). Furthermore, the priors can easily be incorporated into any network and are extremely efficient in improving the performance and accelerating the convergence speed. Firstly, a 3D face rendering branch is set up to obtain 3D priors of salient facial structures and identity knowledge. Secondly, the Spatial Attention Module is used to better exploit this hierarchical information (i.e., intensity similarity, 3D facial structure, and identity content) for the super-resolution problem. Extensive experiments demonstrate that the proposed 3D priors achieve superior face super-resolution results over the state-of-the-arts.