 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCDDFuse: Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion
Nov 26, 2022



Multi-modality (MM) image fusion aims to render fused images that maintain the merits of different modalities, e.g., functional highlight and detailed textures. To tackle the challenge in modeling cross-modality features and decomposing desirable modality-specific and modality-shared features, we propose a novel Correlation-Driven feature Decomposition Fusion (CDDFuse) network for end-to-end MM feature decomposition and image fusion. In the first stage of the two-stage architectures, CDDFuse uses Restormer blocks to extract cross-modality shallow features. We then introduce a dual-branch Transformer-CNN feature extractor with Lite Transformer (LT) blocks leveraging long-range attention to handle low-frequency global features and Invertible Neural Networks (INN) blocks focusing on extracting high-frequency local information. Upon the embedded semantic information, the low-frequency features should be correlated while the high-frequency features should be uncorrelated. Thus, we propose a correlation-driven loss for better feature decomposition. In the second stage, the LT-based global fusion and INN-based local fusion layers output the fused image. Extensive experiments demonstrate that our CDDFuse achieves promising results in multiple fusion tasks, including infrared-visible image fusion and medical image fusion. We also show that CDDFuse can boost the performance in downstream infrared-visible semantic segmentation and object detection in a unified benchmark.
DiffDreamer: Consistent Single-view Perpetual View Generation with Conditional Diffusion Models
Nov 22, 2022



Perpetual view generation -- the task of generating long-range novel views by flying into a given image -- has been a novel yet promising task. We introduce DiffDreamer, an unsupervised framework capable of synthesizing novel views depicting a long camera trajectory while training solely on internet-collected images of nature scenes. We demonstrate that image-conditioned diffusion models can effectively perform long-range scene extrapolation while preserving both local and global consistency significantly better than prior GAN-based methods. Project page: https://primecai.github.io/diffdreamer .
Advancing Learned Video Compression with In-loop Frame Prediction
Nov 18, 2022Recent years have witnessed an increasing interest in end-to-end learned video compression. Most previous works explore temporal redundancy by detecting and compressing a motion map to warp the reference frame towards the target frame. Yet, it failed to adequately take advantage of the historical priors in the sequential reference frames. In this paper, we propose an Advanced Learned Video Compression (ALVC) approach with the in-loop frame prediction module, which is able to effectively predict the target frame from the previously compressed frames, without consuming any bit-rate. The predicted frame can serve as a better reference than the previously compressed frame, and therefore it benefits the compression performance. The proposed in-loop prediction module is a part of the end-to-end video compression and is jointly optimized in the whole framework. We propose the recurrent and the bi-directional in-loop prediction modules for compressing P-frames and B-frames, respectively. The experiments show the state-of-the-art performance of our ALVC approach in learned video compression. We also outperform the default hierarchical B mode of x265 in terms of PSNR and beat the slowest mode of the SSIM-tuned x265 on MS-SSIM. The project page: https://github.com/RenYang-home/ALVC.
Piecewise Planar Hulls for Semi-Supervised Learning of 3D Shape and Pose from 2D Images
Nov 14, 2022



We study the problem of estimating 3D shape and pose of an object in terms of keypoints, from a single 2D image. The shape and pose are learned directly from images collected by categories and their partial 2D keypoint annotations.. In this work, we first propose an end-to-end training framework for intermediate 2D keypoints extraction and final 3D shape and pose estimation. The proposed framework is then trained using only the weak supervision of the intermediate 2D keypoints. Additionally, we devise a semi-supervised training framework that benefits from both labeled and unlabeled data. To leverage the unlabeled data, we introduce and exploit the \emph{piece-wise planar hull} prior of the canonical object shape. These planar hulls are defined manually once per object category, with the help of the keypoints. On the one hand, the proposed method learns to segment these planar hulls from the labeled data. On the other hand, it simultaneously enforces the consistency between predicted keypoints and the segmented hulls on the unlabeled data. The enforced consistency allows us to efficiently use the unlabeled data for the task at hand. The proposed method achieves comparable results with fully supervised state-of-the-art methods by using only half of the annotations. Our source code will be made publicly available.
PyNet-V2 Mobile: Efficient On-Device Photo Processing With Neural Networks
Nov 08, 2022The increased importance of mobile photography created a need for fast and performant RAW image processing pipelines capable of producing good visual results in spite of the mobile camera sensor limitations. While deep learning-based approaches can efficiently solve this problem, their computational requirements usually remain too large for high-resolution on-device image processing. To address this limitation, we propose a novel PyNET-V2 Mobile CNN architecture designed specifically for edge devices, being able to process RAW 12MP photos directly on mobile phones under 1.5 second and producing high perceptual photo quality. To train and to evaluate the performance of the proposed solution, we use the real-world Fujifilm UltraISP dataset consisting on thousands of RAW-RGB image pairs captured with a professional medium-format 102MP Fujifilm camera and a popular Sony mobile camera sensor. The results demonstrate that the PyNET-V2 Mobile model can substantially surpass the quality of tradition ISP pipelines, while outperforming the previously introduced neural network-based solutions designed for fast image processing. Furthermore, we show that the proposed architecture is also compatible with the latest mobile AI accelerators such as NPUs or APUs that can be used to further reduce the latency of the model to as little as 0.5 second. The dataset, code and pre-trained models used in this paper are available on the project website: https://github.com/gmalivenko/PyNET-v2
MicroISP: Processing 32MP Photos on Mobile Devices with Deep Learning
Nov 08, 2022



While neural networks-based photo processing solutions can provide a better image quality compared to the traditional ISP systems, their application to mobile devices is still very limited due to their very high computational complexity. In this paper, we present a novel MicroISP model designed specifically for edge devices, taking into account their computational and memory limitations. The proposed solution is capable of processing up to 32MP photos on recent smartphones using the standard mobile ML libraries and requiring less than 1 second to perform the inference, while for FullHD images it achieves real-time performance. The architecture of the model is flexible, allowing to adjust its complexity to devices of different computational power. To evaluate the performance of the model, we collected a novel Fujifilm UltraISP dataset consisting of thousands of paired photos captured with a normal mobile camera sensor and a professional 102MP medium-format FujiFilm GFX100 camera. The experiments demonstrated that, despite its compact size, the MicroISP model is able to provide comparable or better visual results than the traditional mobile ISP systems, while outperforming the previously proposed efficient deep learning based solutions. Finally, this model is also compatible with the latest mobile AI accelerators, achieving good runtime and low power consumption on smartphone NPUs and APUs. The code, dataset and pre-trained models are available on the project website: https://people.ee.ethz.ch/~ihnatova/microisp.html
Towards Versatile Embodied Navigation
Oct 30, 2022With the emergence of varied visual navigation tasks (e.g, image-/object-/audio-goal and vision-language navigation) that specify the target in different ways, the community has made appealing advances in training specialized agents capable of handling individual navigation tasks well. Given plenty of embodied navigation tasks and task-specific solutions, we address a more fundamental question: can we learn a single powerful agent that masters not one but multiple navigation tasks concurrently? First, we propose VXN, a large-scale 3D dataset that instantiates four classic navigation tasks in standardized, continuous, and audiovisual-rich environments. Second, we propose Vienna, a versatile embodied navigation agent that simultaneously learns to perform the four navigation tasks with one model. Building upon a full-attentive architecture, Vienna formulates various navigation tasks as a unified, parse-and-query procedure: the target description, augmented with four task embeddings, is comprehensively interpreted into a set of diversified goal vectors, which are refined as the navigation progresses, and used as queries to retrieve supportive context from episodic history for decision making. This enables the reuse of knowledge across navigation tasks with varying input domains/modalities. We empirically demonstrate that, compared with learning each visual navigation task individually, our multitask agent achieves comparable or even better performance with reduced complexity.
TripletTrack: 3D Object Tracking using Triplet Embeddings and LSTM
Oct 28, 2022



3D object tracking is a critical task in autonomous driving systems. It plays an essential role for the system's awareness about the surrounding environment. At the same time there is an increasing interest in algorithms for autonomous cars that solely rely on inexpensive sensors, such as cameras. In this paper we investigate the use of triplet embeddings in combination with motion representations for 3D object tracking. We start from an off-the-shelf 3D object detector, and apply a tracking mechanism where objects are matched by an affinity score computed on local object feature embeddings and motion descriptors. The feature embeddings are trained to include information about the visual appearance and monocular 3D object characteristics, while motion descriptors provide a strong representation of object trajectories. We will show that our approach effectively re-identifies objects, and also behaves reliably and accurately in case of occlusions, missed detections and can detect re-appearance across different field of views. Experimental evaluation shows that our approach outperforms state-of-the-art on nuScenes by a large margin. We also obtain competitive results on KITTI.
* Accepted to CVPR 2022 Workshop on Autonomous Driving
Masked Vision-Language Transformer in Fashion
Oct 27, 2022We present a masked vision-language transformer (MVLT) for fashion-specific multi-modal representation. Technically, we simply utilize vision transformer architecture for replacing the BERT in the pre-training model, making MVLT the first end-to-end framework for the fashion domain. Besides, we designed masked image reconstruction (MIR) for a fine-grained understanding of fashion. MVLT is an extensible and convenient architecture that admits raw multi-modal inputs without extra pre-processing models (e.g., ResNet), implicitly modeling the vision-language alignments. More importantly, MVLT can easily generalize to various matching and generative tasks. Experimental results show obvious improvements in retrieval (rank@5: 17%) and recognition (accuracy: 3%) tasks over the Fashion-Gen 2018 winner Kaleido-BERT. Code is made available at https://github.com/GewelsJI/MVLT.
Multi-View Photometric Stereo Revisited
Oct 14, 2022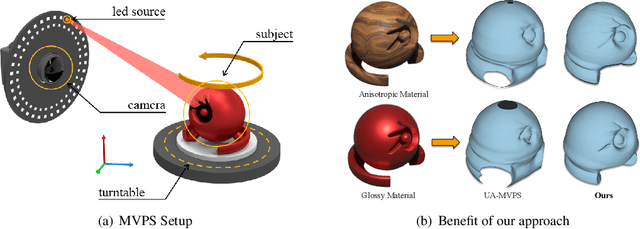

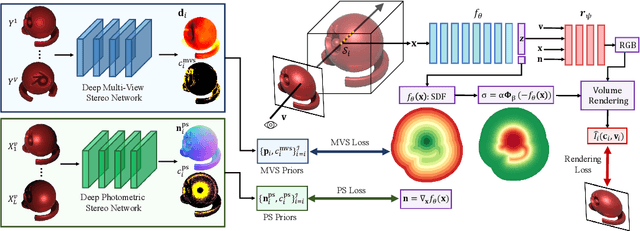
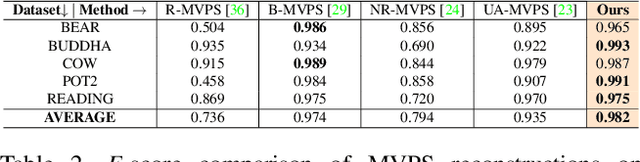
Multi-view photometric stereo (MVPS) is a preferred method for detailed and precise 3D acquisition of an object from images. Although popular methods for MVPS can provide outstanding results, they are often complex to execute and limited to isotropic material objects. To address such limitations, we present a simple, practical approach to MVPS, which works well for isotropic as well as other object material types such as anisotropic and glossy. The proposed approach in this paper exploits the benefit of uncertainty modeling in a deep neural network for a reliable fusion of photometric stereo (PS) and multi-view stereo (MVS) network predictions. Yet, contrary to the recently proposed state-of-the-art, we introduce neural volume rendering methodology for a trustworthy fusion of MVS and PS measurements. The advantage of introducing neural volume rendering is that it helps in the reliable modeling of objects with diverse material types, where existing MVS methods, PS methods, or both may fail. Furthermore, it allows us to work on neural 3D shape representation, which has recently shown outstanding results for many geometric processing tasks. Our suggested new loss function aims to fits the zero level set of the implicit neural function using the most certain MVS and PS network predictions coupled with weighted neural volume rendering cost. The proposed approach shows state-of-the-art results when tested extensively on several benchmark datasets.