 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaming the Judge: Unfaithful Chain-of-Thought Can Undermine Agent Evaluation
Jan 21, 2026Large language models (LLMs) are increasingly used as judges to evaluate agent performance, particularly in non-verifiable settings where judgments rely on agent trajectories including chain-of-thought (CoT) reasoning. This paradigm implicitly assumes that the agent's CoT faithfully reflects both its internal reasoning and the underlying environment state. We show this assumption is brittle: LLM judges are highly susceptible to manipulation of agent reasoning traces. By systematically rewriting agent CoTs while holding actions and observations fixed, we demonstrate that manipulated reasoning alone can inflate false positive rates of state-of-the-art VLM judges by up to 90% across 800 trajectories spanning diverse web tasks. We study manipulation strategies spanning style-based approaches that alter only the presentation of reasoning and content-based approaches that fabricate signals of task progress, and find that content-based manipulations are consistently more effective. We evaluate prompting-based techniques and scaling judge-time compute, which reduce but do not fully eliminate susceptibility to manipulation. Our findings reveal a fundamental vulnerability in LLM-based evaluation and highlight the need for judging mechanisms that verify reasoning claims against observable evidence.
Skill-Aware Data Selection and Fine-Tuning for Data-Efficient Reasoning Distillation
Jan 15, 2026Large reasoning models such as DeepSeek-R1 and their distilled variants achieve strong performance on complex reasoning tasks. Yet, distilling these models often demands large-scale data for supervised fine-tuning (SFT), motivating the pursuit of data-efficient training methods. To address this, we propose a skill-centric distillation framework that efficiently transfers reasoning ability to weaker models with two components: (1) Skill-based data selection, which prioritizes examples targeting the student model's weaker skills, and (2) Skill-aware fine-tuning, which encourages explicit skill decomposition during problem solving. With only 1,000 training examples selected from a 100K teacher-generated corpus, our method surpasses random SFT baselines by +1.6% on Qwen3-4B and +1.4% on Qwen3-8B across five mathematical reasoning benchmarks. Further analysis confirms that these gains concentrate on skills emphasized during training, highlighting the effectiveness of skill-centric training for efficient reasoning distillation.
IndexTTS 2.5 Technical Report
Jan 08, 2026In prior work, we introduced IndexTTS 2, a zero-shot neural text-to-speech foundation model comprising two core components: a transformer-based Text-to-Semantic (T2S) module and a non-autoregressive Semantic-to-Mel (S2M) module, which together enable faithful emotion replication and establish the first autoregressive duration-controllable generative paradigm. Building upon this, we present IndexTTS 2.5, which significantly enhances multilingual coverage, inference speed, and overall synthesis quality through four key improvements: 1) Semantic Codec Compression: we reduce the semantic codec frame rate from 50 Hz to 25 Hz, halving sequence length and substantially lowering both training and inference costs; 2) Architectural Upgrade: we replace the U-DiT-based backbone of the S2M module with a more efficient Zipformer-based modeling architecture, achieving notable parameter reduction and faster mel-spectrogram generation; 3) Multilingual Extension: We propose three explicit cross-lingual modeling strategies, boundary-aware alignment, token-level concatenation, and instruction-guided generation, establishing practical design principles for zero-shot multilingual emotional TTS that supports Chinese, English, Japanese, and Spanish, and enables robust emotion transfer even without target-language emotional training data; 4) Reinforcement Learning Optimization: we apply GRPO in post-training of the T2S module, improving pronunciation accuracy and natrualness. Experiments show that IndexTTS 2.5 not only supports broader language coverage but also replicates emotional prosody in unseen languages under the same zero-shot setting. IndexTTS 2.5 achieves a 2.28 times improvement in RTF while maintaining comparable WER and speaker similarity to IndexTTS 2.
Index-ASR Technical Report
Dec 31, 2025Automatic speech recognition (ASR) has witnessed remarkable progress in recent years, largely driven by the emergence of LLM-based ASR paradigm. Despite their strong performance on a variety of open-source benchmarks, existing LLM-based ASR systems still suffer from two critical limitations. First, they are prone to hallucination errors, often generating excessively long and repetitive outputs that are not well grounded in the acoustic input. Second, they provide limited support for flexible and fine-grained contextual customization. To address these challenges, we propose Index-ASR, a large-scale LLM-based ASR system designed to simultaneously enhance robustness and support customizable hotword recognition. The core idea of Index-ASR lies in the integration of LLM and large-scale training data enriched with background noise and contextual information. Experimental results show that our Index-ASR achieves strong performance on both open-source benchmarks and in-house test sets, highlighting its robustness and practicality for real-world ASR applications.
Blur-Robust Detection via Feature Restoration: An End-to-End Framework for Prior-Guided Infrared UAV Target Detection
Nov 18, 2025Infrared unmanned aerial vehicle (UAV) target images often suffer from motion blur degradation caused by rapid sensor movement, significantly reducing contrast between target and background. Generally, detection performance heavily depends on the discriminative feature representation between target and background. Existing methods typically treat deblurring as a preprocessing step focused on visual quality, while neglecting the enhancement of task-relevant features crucial for detection. Improving feature representation for detection under blur conditions remains challenging. In this paper, we propose a novel Joint Feature-Domain Deblurring and Detection end-to-end framework, dubbed JFD3. We design a dual-branch architecture with shared weights, where the clear branch guides the blurred branch to enhance discriminative feature representation. Specifically, we first introduce a lightweight feature restoration network, where features from the clear branch serve as feature-level supervision to guide the blurred branch, thereby enhancing its distinctive capability for detection. We then propose a frequency structure guidance module that refines the structure prior from the restoration network and integrates it into shallow detection layers to enrich target structural information. Finally, a feature consistency self-supervised loss is imposed between the dual-branch detection backbones, driving the blurred branch to approximate the feature representations of the clear one. Wealso construct a benchmark, named IRBlurUAV, containing 30,000 simulated and 4,118 real infrared UAV target images with diverse motion blur. Extensive experiments on IRBlurUAV demonstrate that JFD3 achieves superior detection performance while maintaining real-time efficiency.
Heterogeneous Complementary Distillation
Nov 14, 2025Knowledge distillation (KD)transfers the dark knowledge from a complex teacher to a compact student. However, heterogeneous architecture distillation, such as Vision Transformer (ViT) to ResNet18, faces challenges due to differences in spatial feature representations.Traditional KD methods are mostly designed for homogeneous architectures and hence struggle to effectively address the disparity. Although heterogeneous KD approaches have been developed recently to solve these issues, they often incur high computational costs and complex designs, or overly rely on logit alignment, which limits their ability to leverage the complementary features. To overcome these limitations, we propose Heterogeneous Complementary Distillation (HCD),a simple yet effective framework that integrates complementary teacher and student features to align representations in shared logits.These logits are decomposed and constrained to facilitate diverse knowledge transfer to the student. Specifically, HCD processes the student's intermediate features through convolutional projector and adaptive pooling, concatenates them with teacher's feature from the penultimate layer and then maps them via the Complementary Feature Mapper (CFM) module, comprising fully connected layer,to produce shared logits.We further introduce Sub-logit Decoupled Distillation (SDD) that partitions the shared logits into n sub-logits, which are fused with teacher's logits to rectify classification.To ensure sub-logit diversity and reduce redundant knowledge transfer, we propose an Orthogonality Loss (OL).By preserving student-specific strengths and leveraging teacher knowledge,HCD enhances robustness and generalization in students.Extensive experiments on the CIFAR-100, Fine-grained (e.g., CUB200)and ImageNet-1K datasets demonstrate that HCD outperforms state-of-the-art KD methods,establishing it as an effective solution for heterogeneous KD.
Seeing the Forest and the Trees: Query-Aware Tokenizer for Long-Video Multimodal Language Models
Nov 14, 2025Despite the recent advances in the video understanding ability of multimodal large language models (MLLMs), long video understanding remains a challenge. One of the main issues is that the number of vision tokens grows linearly with video length, which causes an explosion in attention cost, memory, and latency. To solve this challenge, we present Query-aware Token Selector (\textbf{QTSplus}), a lightweight yet powerful visual token selection module that serves as an information gate between the vision encoder and LLMs. Given a text query and video tokens, QTSplus dynamically selects the most important visual evidence for the input text query by (i) scoring visual tokens via cross-attention, (ii) \emph{predicting} an instance-specific retention budget based on the complexity of the query, and (iii) \emph{selecting} Top-$n$ tokens with a differentiable straight-through estimator during training and a hard gate at inference. Furthermore, a small re-encoder preserves temporal order using absolute time information, enabling second-level localization while maintaining global coverage. Integrated into Qwen2.5-VL, QTSplus compresses the vision stream by up to \textbf{89\%} and reduces end-to-end latency by \textbf{28\%} on long videos. The evaluation on eight long video understanding benchmarks shows near-parity accuracy overall when compared with the original Qwen models and outperforms the original model by \textbf{+20.5} and \textbf{+5.6} points respectively on TempCompass direction and order accuracies. These results show that QTSplus is an effective, general mechanism for scaling MLLMs to real-world long-video scenarios while preserving task-relevant evidence. We will make all code, data, and trained models' weights publicly available.
GUI-360$^\circ$: A Comprehensive Dataset and Benchmark for Computer-Using Agents
Nov 10, 2025We introduce GUI-360$^\circ$, a large-scale, comprehensive dataset and benchmark suite designed to advance computer-using agents (CUAs). CUAs present unique challenges and is constrained by three persistent gaps: a scarcity of real-world CUA tasks, the lack of automated collection-and-annotation pipelines for multi-modal trajectories, and the absence of a unified benchmark that jointly evaluates GUI grounding, screen parsing, and action prediction. GUI-360$^\circ$ addresses these gaps with an LLM-augmented, largely automated pipeline for query sourcing, environment-template construction, task instantiation, batched execution, and LLM-driven quality filtering. The released corpus contains over 1.2M executed action steps across thousands of trajectories in popular Windows office applications, and includes full-resolution screenshots, accessibility metadata when available, instantiated goals, intermediate reasoning traces, and both successful and failed action trajectories. The dataset supports three canonical tasks, GUI grounding, screen parsing, and action prediction, and a hybrid GUI+API action space that reflects modern agent designs. Benchmarking state-of-the-art vision--language models on GUI-360$^\circ$ reveals substantial out-of-the-box shortcomings in grounding and action prediction; supervised fine-tuning and reinforcement learning yield significant gains but do not close the gap to human-level reliability. We release GUI-360$^\circ$ and accompanying code to facilitate reproducible research and accelerate progress on robust desktop CUAs. The full dataset has been made public on https://huggingface.co/datasets/vyokky/GUI-360.
GUI-360: A Comprehensive Dataset and Benchmark for Computer-Using Agents
Nov 06, 2025We introduce GUI-360$^\circ$, a large-scale, comprehensive dataset and benchmark suite designed to advance computer-using agents (CUAs). CUAs present unique challenges and is constrained by three persistent gaps: a scarcity of real-world CUA tasks, the lack of automated collection-and-annotation pipelines for multi-modal trajectories, and the absence of a unified benchmark that jointly evaluates GUI grounding, screen parsing, and action prediction. GUI-360$^\circ$ addresses these gaps with an LLM-augmented, largely automated pipeline for query sourcing, environment-template construction, task instantiation, batched execution, and LLM-driven quality filtering. The released corpus contains over 1.2M executed action steps across thousands of trajectories in popular Windows office applications, and includes full-resolution screenshots, accessibility metadata when available, instantiated goals, intermediate reasoning traces, and both successful and failed action trajectories. The dataset supports three canonical tasks, GUI grounding, screen parsing, and action prediction, and a hybrid GUI+API action space that reflects modern agent designs. Benchmarking state-of-the-art vision--language models on GUI-360$^\circ$ reveals substantial out-of-the-box shortcomings in grounding and action prediction; supervised fine-tuning and reinforcement learning yield significant gains but do not close the gap to human-level reliability. We release GUI-360$^\circ$ and accompanying code to facilitate reproducible research and accelerate progress on robust desktop CUAs. The full dataset has been made public on https://huggingface.co/datasets/vyokky/GUI-360.
LiveOIBench: Can Large Language Models Outperform Human Contestants in Informatics Olympiads?
Oct 10, 2025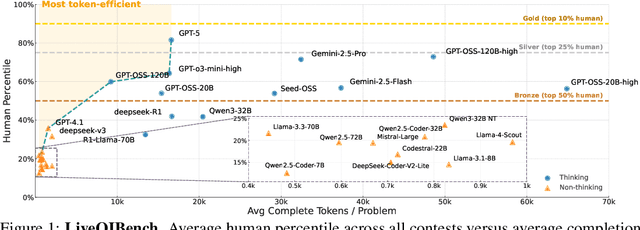
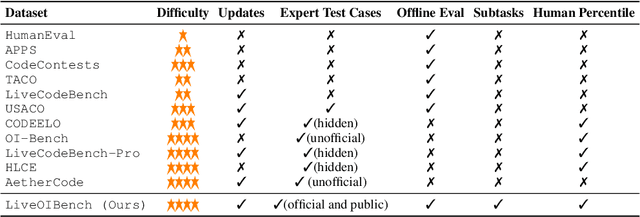
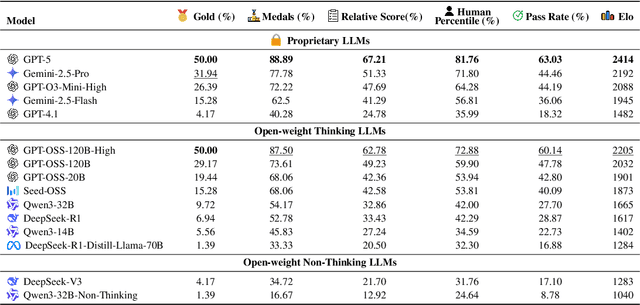
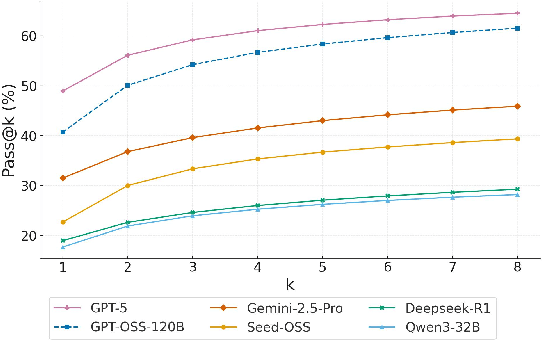
Competitive programming problems increasingly serve as valuable benchmarks to evaluate the coding capabilities of large language models (LLMs) due to their complexity and ease of verification. Yet, current coding benchmarks face limitations such as lack of exceptionally challenging problems, insufficient test case coverage, reliance on online platform APIs that limit accessibility. To address these issues, we introduce LiveOIBench, a comprehensive benchmark featuring 403 expert-curated Olympiad-level competitive programming problems, each with an average of 60 expert-designed test cases. The problems are sourced directly from 72 official Informatics Olympiads in different regions conducted between 2023 and 2025. LiveOIBench distinguishes itself through four key features: (1) meticulously curated high-quality tasks with detailed subtask rubrics and extensive private test cases; (2) direct integration of elite contestant performance data to enable informative comparison against top-performing humans; (3) planned continuous, contamination-free updates from newly released Olympiad problems; and (4) a self-contained evaluation system facilitating offline and easy-to-reproduce assessments. Benchmarking 32 popular general-purpose and reasoning LLMs, we find that GPT-5 achieves a notable 81.76th percentile, a strong result that nonetheless falls short of top human contestant performance, who usually place above 90th. In contrast, among open-weight reasoning models, GPT-OSS-120B achieves only a 60th percentile, underscoring significant capability disparities from frontier closed models. Detailed analyses indicate that robust reasoning models prioritize precise problem analysis over excessive exploration, suggesting future models should emphasize structured analysis and minimize unnecessary exploration. All data, code, and leaderboard results will be made publicly available on our website.