 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Source Information Learning Framework for Airbnb Price Prediction
Jan 01, 2023With the development of technology and sharing economy, Airbnb as a famous short-term rental platform, has become the first choice for many young people to select. The issue of Airbnb's pricing has always been a problem worth studying. While the previous studies achieve promising results, there are exists deficiencies to solve. Such as, (1) the feature attributes of rental are not rich enough; (2) the research on rental text information is not deep enough; (3) there are few studies on predicting the rental price combined with the point of interest(POI) around the house. To address the above challenges, we proposes a multi-source information embedding(MSIE) model to predict the rental price of Airbnb. Specifically, we first selects the statistical feature to embed the original rental data. Secondly, we generates the word feature vector and emotional score combination of three different text information to form the text feature embedding. Thirdly, we uses the points of interest(POI) around the rental house information generates a variety of spatial network graphs, and learns the embedding of the network to obtain the spatial feature embedding. Finally, this paper combines the three modules into multi source rental representations, and uses the constructed fully connected neural network to predict the price. The analysis of the experimental results shows the effectiveness of our proposed model.
Streaming Traffic Flow Prediction Based on Continuous Reinforcement Learning
Dec 24, 2022Traffic flow prediction is an important part of smart transportation. The goal is to predict future traffic conditions based on historical data recorded by sensors and the traffic network. As the city continues to build, parts of the transportation network will be added or modified. How to accurately predict expanding and evolving long-term streaming networks is of great significance. To this end, we propose a new simulation-based criterion that considers teaching autonomous agents to mimic sensor patterns, planning their next visit based on the sensor's profile (e.g., traffic, speed, occupancy). The data recorded by the sensor is most accurate when the agent can perfectly simulate the sensor's activity pattern. We propose to formulate the problem as a continuous reinforcement learning task, where the agent is the next flow value predictor, the action is the next time-series flow value in the sensor, and the environment state is a dynamically fused representation of the sensor and transportation network. Actions taken by the agent change the environment, which in turn forces the agent's mode to update, while the agent further explores changes in the dynamic traffic network, which helps the agent predict its next visit more accurately. Therefore, we develop a strategy in which sensors and traffic networks update each other and incorporate temporal context to quantify state representations evolving over time.
MAGVIT: Masked Generative Video Transformer
Dec 10, 2022



We introduce the MAsked Generative VIdeo Transformer, MAGVIT, to tackle various video synthesis tasks with a single model. We introduce a 3D tokenizer to quantize a video into spatial-temporal visual tokens and propose an embedding method for masked video token modeling to facilitate multi-task learning. We conduct extensive experiments to demonstrate the quality, efficiency, and flexibility of MAGVIT. Our experiments show that (i) MAGVIT performs favorably against state-of-the-art approaches and establishes the best-published FVD on three video generation benchmarks, including the challenging Kinetics-600. (ii) MAGVIT outperforms existing methods in inference time by two orders of magnitude against diffusion models and by 60x against autoregressive models. (iii) A single MAGVIT model supports ten diverse generation tasks and generalizes across videos from different visual domains. The source code and trained models will be released to the public at https://magvit.cs.cmu.edu.
Visual Prompt Tuning for Generative Transfer Learning
Oct 03, 2022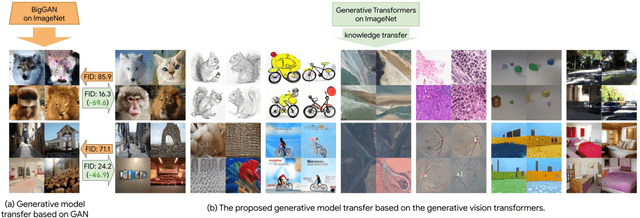
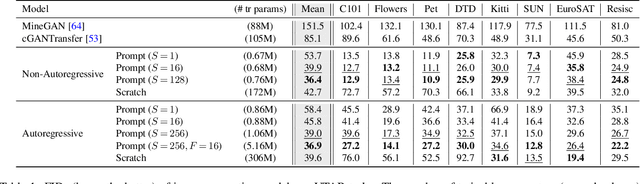
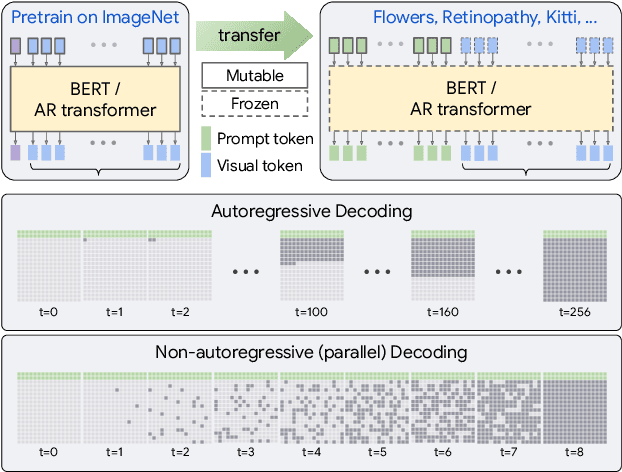
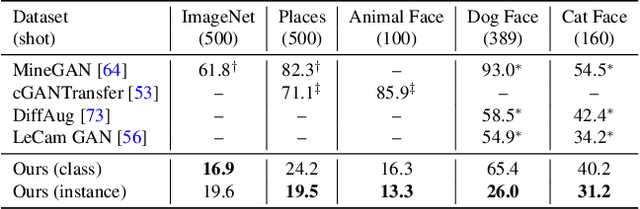
Transferring knowledge from an image synthesis model trained on a large dataset is a promising direction for learning generative image models from various domains efficiently. While previous works have studied GAN models, we present a recipe for learning vision transformers by generative knowledge transfer. We base our framework on state-of-the-art generative vision transformers that represent an image as a sequence of visual tokens to the autoregressive or non-autoregressive transformers. To adapt to a new domain, we employ prompt tuning, which prepends learnable tokens called prompt to the image token sequence, and introduce a new prompt design for our task. We study on a variety of visual domains, including visual task adaptation benchmark~\cite{zhai2019large}, with varying amount of training images, and show effectiveness of knowledge transfer and a significantly better image generation quality over existing works.
Improved Masked Image Generation with Token-Critic
Sep 09, 2022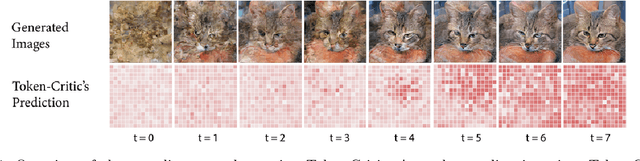
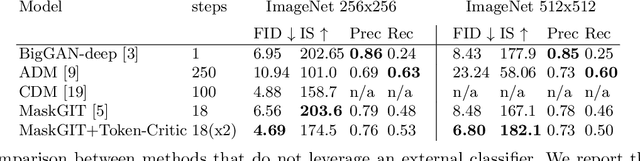
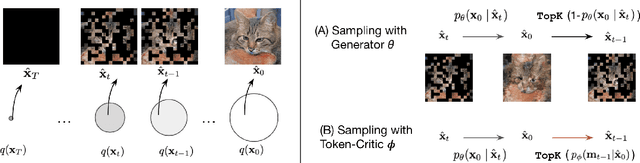
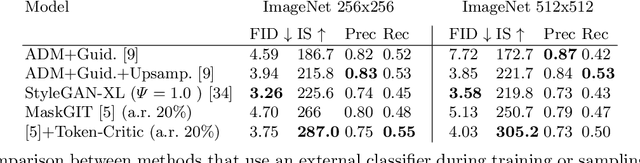
Non-autoregressive generative transformers recently demonstrated impressive image generation performance, and orders of magnitude faster sampling than their autoregressive counterparts. However, optimal parallel sampling from the true joint distribution of visual tokens remains an open challenge. In this paper we introduce Token-Critic, an auxiliary model to guide the sampling of a non-autoregressive generative transformer. Given a masked-and-reconstructed real image, the Token-Critic model is trained to distinguish which visual tokens belong to the original image and which were sampled by the generative transformer. During non-autoregressive iterative sampling, Token-Critic is used to select which tokens to accept and which to reject and resample. Coupled with Token-Critic, a state-of-the-art generative transformer significantly improves its performance, and outperforms recent diffusion models and GANs in terms of the trade-off between generated image quality and diversity, in the challenging class-conditional ImageNet generation.
MaskGIT: Masked Generative Image Transformer
Feb 08, 2022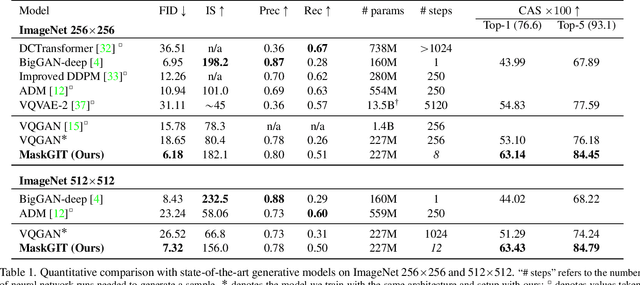

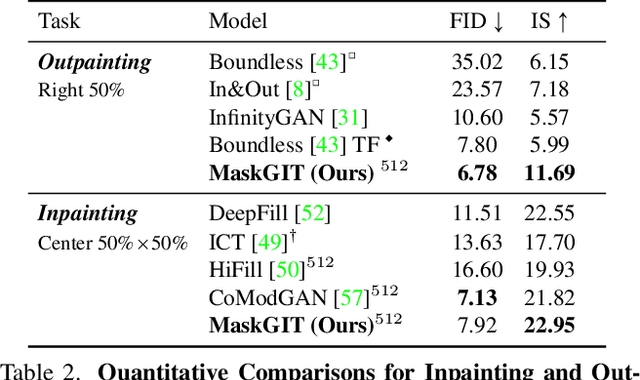
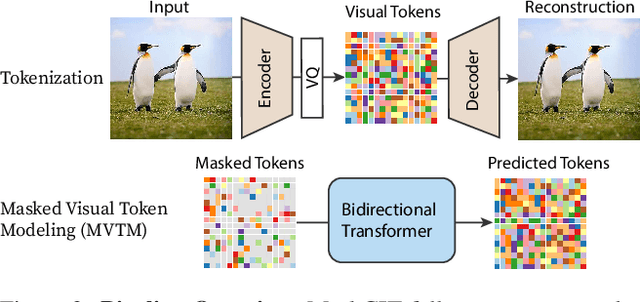
Generative transformers have experienced rapid popularity growth in the computer vision community in synthesizing high-fidelity and high-resolution images. The best generative transformer models so far, however, still treat an image naively as a sequence of tokens, and decode an image sequentially following the raster scan ordering (i.e. line-by-line). We find this strategy neither optimal nor efficient. This paper proposes a novel image synthesis paradigm using a bidirectional transformer decoder, which we term MaskGIT. During training, MaskGIT learns to predict randomly masked tokens by attending to tokens in all directions. At inference time, the model begins with generating all tokens of an image simultaneously, and then refines the image iteratively conditioned on the previous generation. Our experiments demonstrate that MaskGIT significantly outperforms the state-of-the-art transformer model on the ImageNet dataset, and accelerates autoregressive decoding by up to 64x. Besides, we illustrate that MaskGIT can be easily extended to various image editing tasks, such as inpainting, extrapolation, and image manipulation.
BLT: Bidirectional Layout Transformer for Controllable Layout Generation
Dec 09, 2021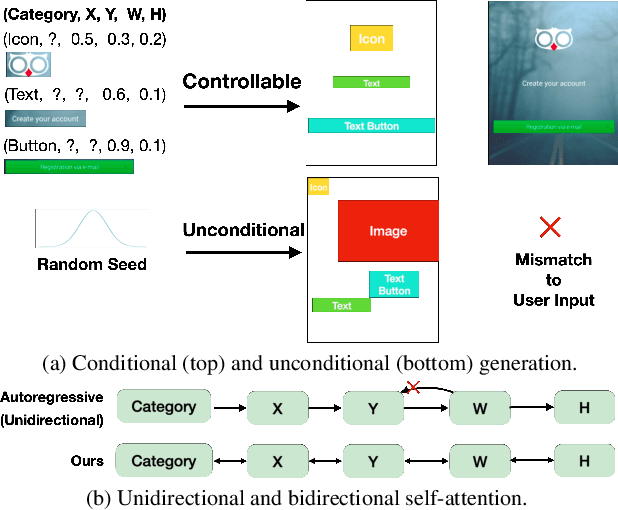
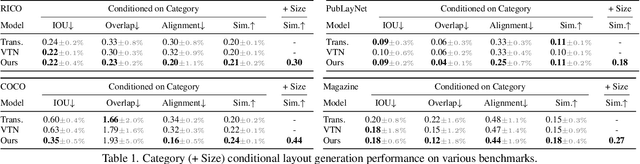
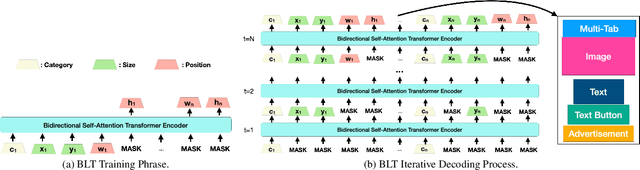
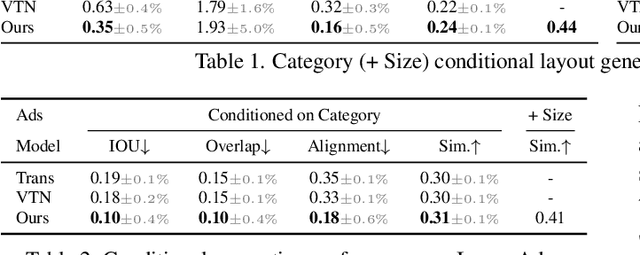
Creating visual layouts is an important step in graphic design. Automatic generation of such layouts is important as we seek scale-able and diverse visual designs. Prior works on automatic layout generation focus on unconditional generation, in which the models generate layouts while neglecting user needs for specific problems. To advance conditional layout generation, we introduce BLT, a bidirectional layout transformer. BLT differs from autoregressive decoding as it first generates a draft layout that satisfies the user inputs and then refines the layout iteratively. We verify the proposed model on multiple benchmarks with various fidelity metrics. Our results demonstrate two key advances to the state-of-the-art layout transformer models. First, our model empowers layout transformers to fulfill controllable layout generation. Second, our model slashes the linear inference time in autoregressive decoding into a constant complexity, thereby achieving 4x-10x speedups in generating a layout at inference time.
Pyramid Adversarial Training Improves ViT Performance
Nov 30, 2021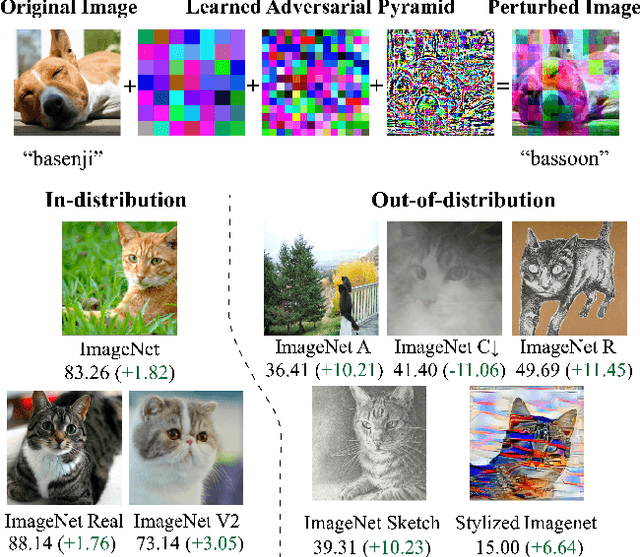
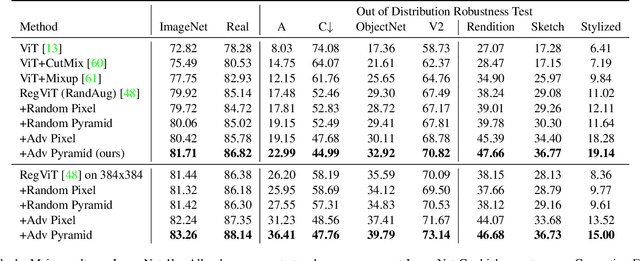

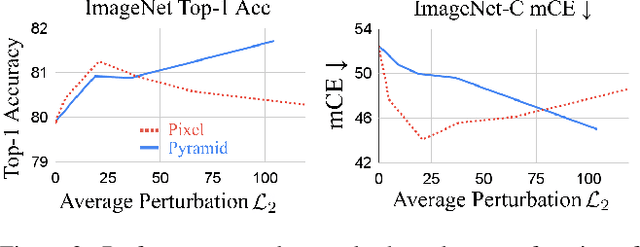
Aggressive data augmentation is a key component of the strong generalization capabilities of Vision Transformer (ViT). One such data augmentation technique is adversarial training; however, many prior works have shown that this often results in poor clean accuracy. In this work, we present Pyramid Adversarial Training, a simple and effective technique to improve ViT's overall performance. We pair it with a "matched" Dropout and stochastic depth regularization, which adopts the same Dropout and stochastic depth configuration for the clean and adversarial samples. Similar to the improvements on CNNs by AdvProp (not directly applicable to ViT), our Pyramid Adversarial Training breaks the trade-off between in-distribution accuracy and out-of-distribution robustness for ViT and related architectures. It leads to $1.82\%$ absolute improvement on ImageNet clean accuracy for the ViT-B model when trained only on ImageNet-1K data, while simultaneously boosting performance on $7$ ImageNet robustness metrics, by absolute numbers ranging from $1.76\%$ to $11.45\%$. We set a new state-of-the-art for ImageNet-C (41.4 mCE), ImageNet-R ($53.92\%$), and ImageNet-Sketch ($41.04\%$) without extra data, using only the ViT-B/16 backbone and our Pyramid Adversarial Training. Our code will be publicly available upon acceptance.
Discrete Representations Strengthen Vision Transformer Robustness
Nov 20, 2021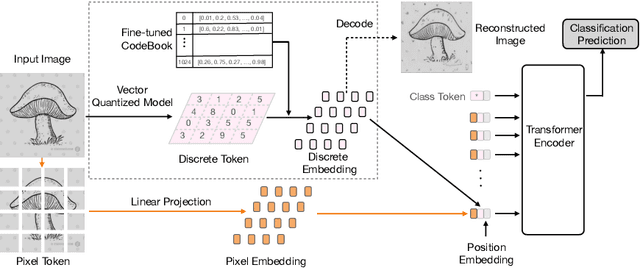
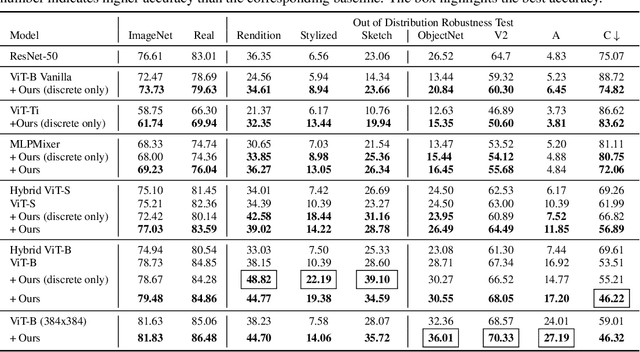


Vision Transformer (ViT) is emerging as the state-of-the-art architecture for image recognition. While recent studies suggest that ViTs are more robust than their convolutional counterparts, our experiments find that ViTs are overly reliant on local features (e.g., nuisances and texture) and fail to make adequate use of global context (e.g., shape and structure). As a result, ViTs fail to generalize to out-of-distribution, real-world data. To address this deficiency, we present a simple and effective architecture modification to ViT's input layer by adding discrete tokens produced by a vector-quantized encoder. Different from the standard continuous pixel tokens, discrete tokens are invariant under small perturbations and contain less information individually, which promote ViTs to learn global information that is invariant. Experimental results demonstrate that adding discrete representation on four architecture variants strengthens ViT robustness by up to 12% across seven ImageNet robustness benchmarks while maintaining the performance on ImageNet.
ViTGAN: Training GANs with Vision Transformers
Jul 09, 2021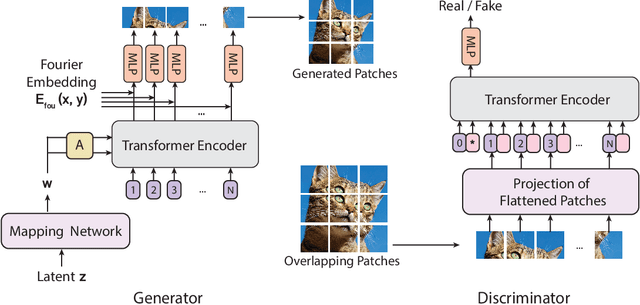
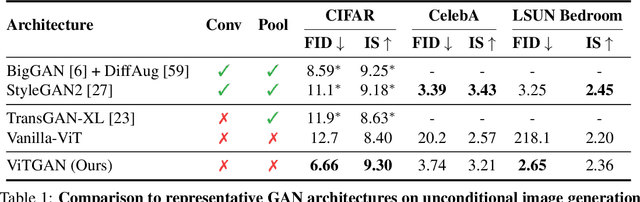
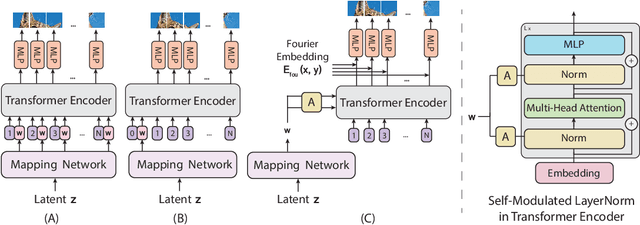

Recently, Vision Transformers (ViTs) have shown competitive performance on image recognition while requiring less vision-specific inductive biases. In this paper, we investigate if such observation can be extended to image generation. To this end, we integrate the ViT architecture into generative adversarial networks (GANs). We observe that existing regularization methods for GANs interact poorly with self-attention, causing serious instability during training. To resolve this issue, we introduce novel regularization techniques for training GANs with ViTs. Empirically, our approach, named ViTGAN, achieves comparable performance to state-of-the-art CNN-based StyleGAN2 on CIFAR-10, CelebA, and LSUN bedroom datasets.