 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Multimodal Transformers Robust to Missing Modality?
Apr 12, 2022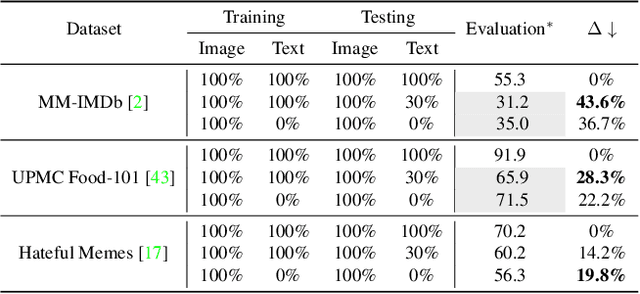

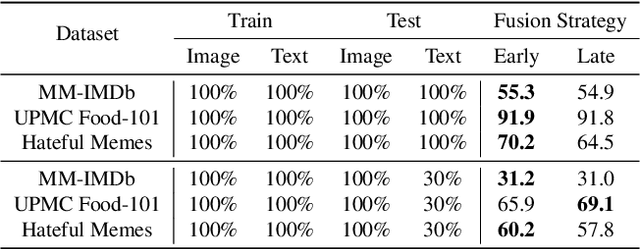
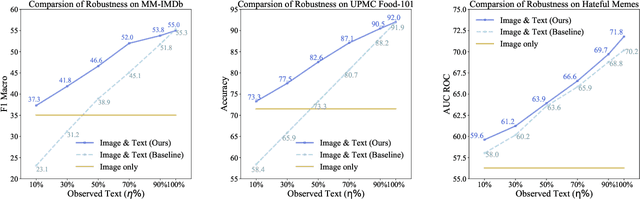
Multimodal data collected from the real world are often imperfect due to missing modalities. Therefore multimodal models that are robust against modal-incomplete data are highly preferred. Recently, Transformer models have shown great success in processing multimodal data. However, existing work has been limited to either architecture designs or pre-training strategies; whether Transformer models are naturally robust against missing-modal data has rarely been investigated. In this paper, we present the first-of-its-kind work to comprehensively investigate the behavior of Transformers in the presence of modal-incomplete data. Unsurprising, we find Transformer models are sensitive to missing modalities while different modal fusion strategies will significantly affect the robustness. What surprised us is that the optimal fusion strategy is dataset dependent even for the same Transformer model; there does not exist a universal strategy that works in general cases. Based on these findings, we propose a principle method to improve the robustness of Transformer models by automatically searching for an optimal fusion strategy regarding input data. Experimental validations on three benchmarks support the superior performance of the proposed method.
Global Matching with Overlapping Attention for Optical Flow Estimation
Mar 21, 2022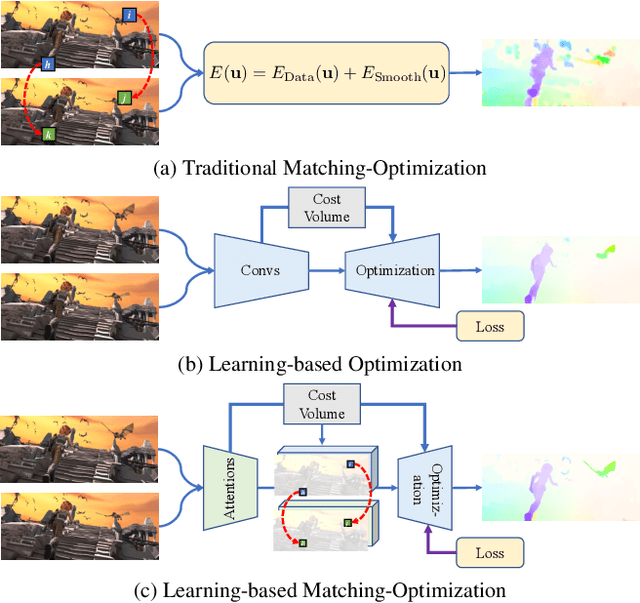
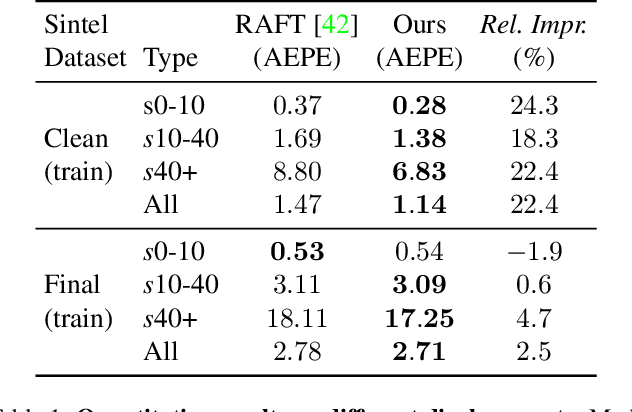
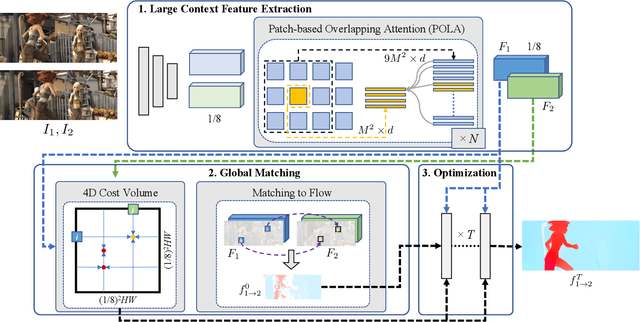
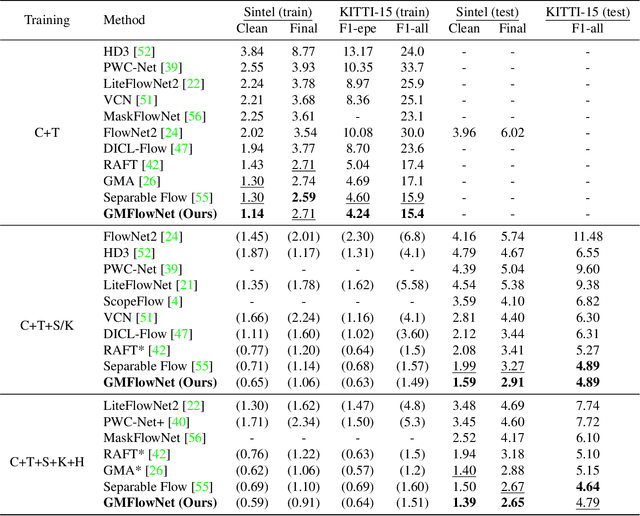
Optical flow estimation is a fundamental task in computer vision. Recent direct-regression methods using deep neural networks achieve remarkable performance improvement. However, they do not explicitly capture long-term motion correspondences and thus cannot handle large motions effectively. In this paper, inspired by the traditional matching-optimization methods where matching is introduced to handle large displacements before energy-based optimizations, we introduce a simple but effective global matching step before the direct regression and develop a learning-based matching-optimization framework, namely GMFlowNet. In GMFlowNet, global matching is efficiently calculated by applying argmax on 4D cost volumes. Additionally, to improve the matching quality, we propose patch-based overlapping attention to extract large context features. Extensive experiments demonstrate that GMFlowNet outperforms RAFT, the most popular optimization-only method, by a large margin and achieves state-of-the-art performance on standard benchmarks. Thanks to the matching and overlapping attention, GMFlowNet obtains major improvements on the predictions for textureless regions and large motions. Our code is made publicly available at https://github.com/xiaofeng94/GMFlowNet
Min-Max Latency Optimization Based on Sensed Position State Information in Internet of Vehicles
Mar 19, 2022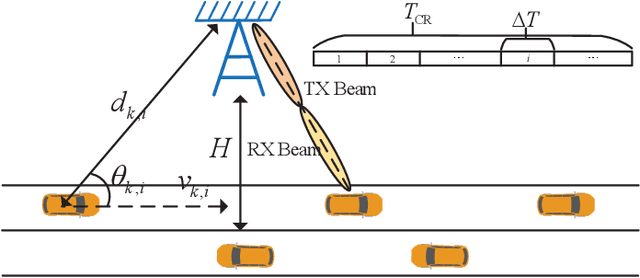
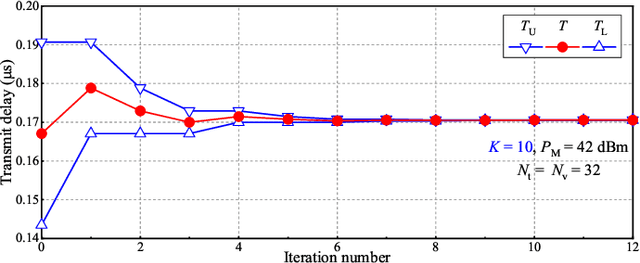
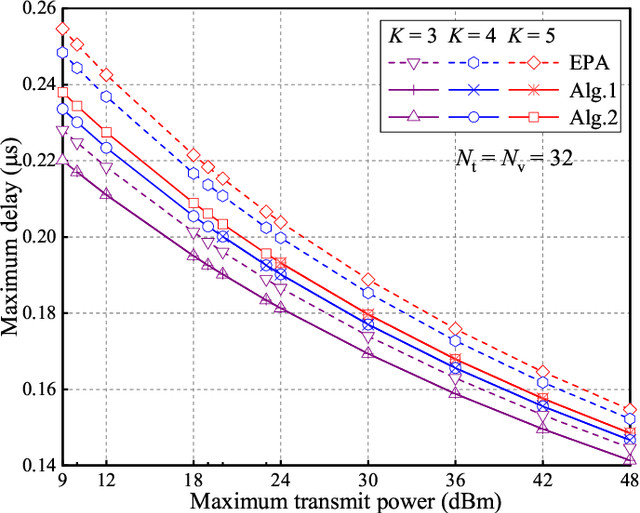
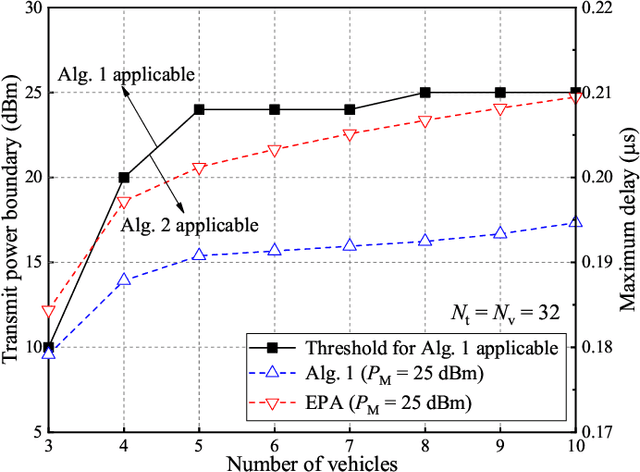
The dual-function radar communication (DFRC) is an essential technology in Internet of Vehicles (IoV). Consider that the road-side unit (RSU) employs the DFRC signals to sense the vehicles' position state information (PSI), and communicates with the vehicles based on PSI. The objective of this paper is to minimize the maximum communication delay among all vehicles by considering the estimation accuracy constraint of the vehicles' PSI and the transmit power constraint of RSU. By leveraging convex optimization theory, two iterative power allocation algorithms are proposed with different complexities and applicable scenarios. Simulation results indicate that the proposed power allocation algorithm converges and can significantly reduce the maximum transmit delay among vehicles compared with other schemes.
COMPOSER: Compositional Learning of Group Activity in Videos
Dec 11, 2021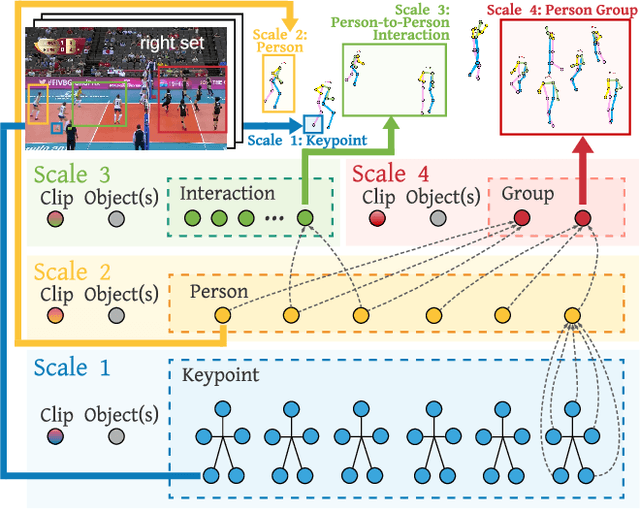

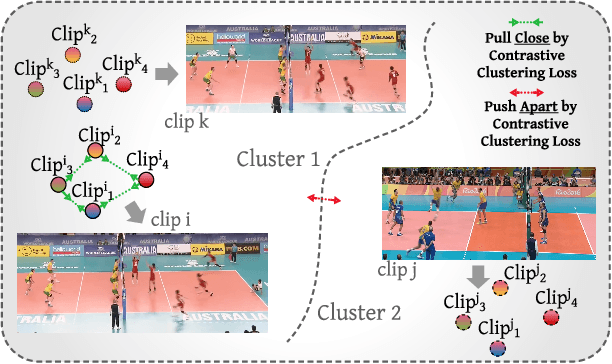
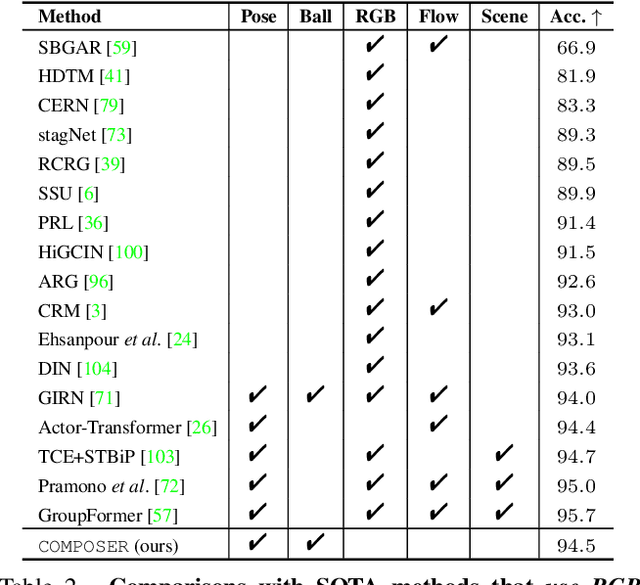
Group Activity Recognition (GAR) detects the activity performed by a group of actors in a short video clip. The task requires the compositional understanding of scene entities and relational reasoning between them. We approach GAR by modeling the video as a series of tokens that represent the multi-scale semantic concepts in the video. We propose COMPOSER, a Multiscale Transformer based architecture that performs attention-based reasoning over tokens at each scale and learns group activity compositionally. In addition, we only use the keypoint modality which reduces scene biases and improves the generalization ability of the model. We improve the multi-scale representations in COMPOSER by clustering the intermediate scale representations, while maintaining consistent cluster assignments between scales. Finally, we use techniques such as auxiliary prediction and novel data augmentations (e.g., Actor Dropout) to aid model training. We demonstrate the model's strength and interpretability on the challenging Volleyball dataset. COMPOSER achieves a new state-of-the-art 94.5% accuracy with the keypoint-only modality. COMPOSER outperforms the latest GAR methods that rely on RGB signals, and performs favorably compared against methods that exploit multiple modalities. Our code will be available.
Out-of-domain Generalization from a Single Source: A Uncertainty Quantification Approach
Aug 05, 2021
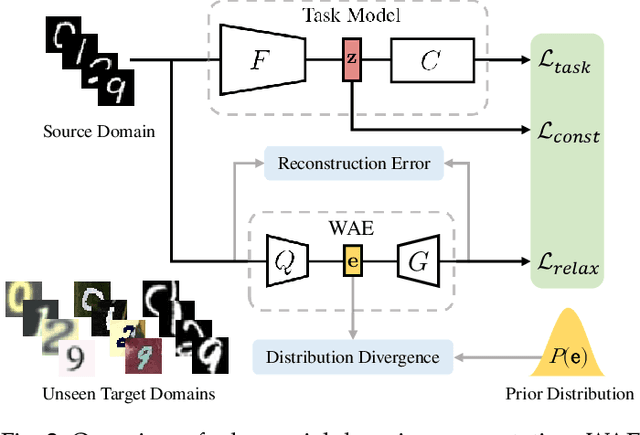
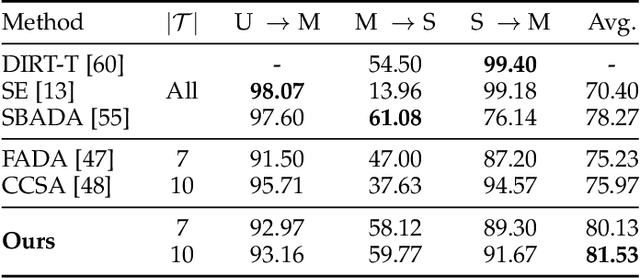
We study a worst-case scenario in generalization: Out-of-domain generalization from a single source. The goal is to learn a robust model from a single source and expect it to generalize over many unknown distributions. This challenging problem has been seldom investigated while existing solutions suffer from various limitations such as the ignorance of uncertainty assessment and label augmentation. In this paper, we propose uncertainty-guided domain generalization to tackle the aforementioned limitations. The key idea is to augment the source capacity in both feature and label spaces, while the augmentation is guided by uncertainty assessment. To the best of our knowledge, this is the first work to (1) quantify the generalization uncertainty from a single source and (2) leverage it to guide both feature and label augmentation for robust generalization. The model training and deployment are effectively organized in a Bayesian meta-learning framework. We conduct extensive comparisons and ablation study to validate our approach. The results prove our superior performance in a wide scope of tasks including image classification, semantic segmentation, text classification, and speech recognition.
Improved Transformer for High-Resolution GANs
Jun 14, 2021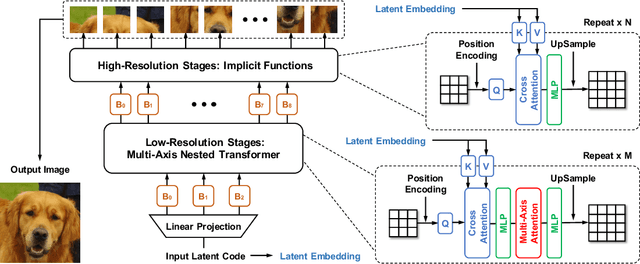
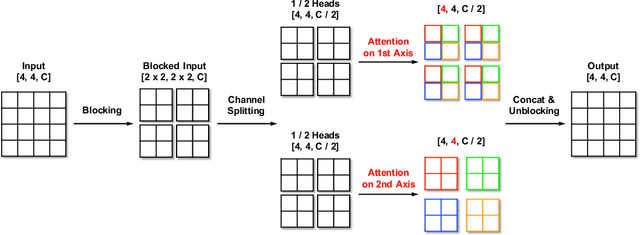
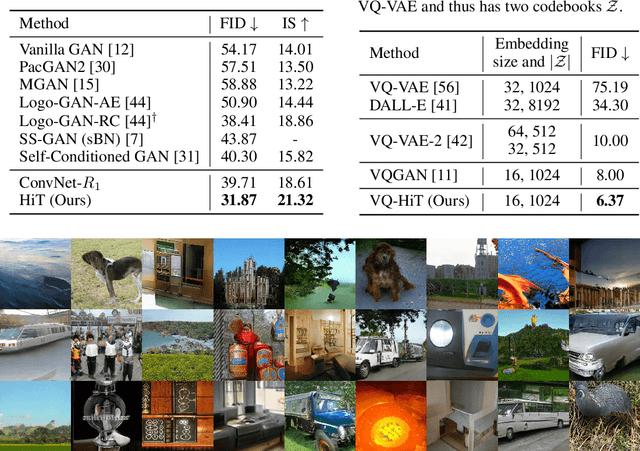

Attention-based models, exemplified by the Transformer, can effectively model long range dependency, but suffer from the quadratic complexity of self-attention operation, making them difficult to be adopted for high-resolution image generation based on Generative Adversarial Networks (GANs). In this paper, we introduce two key ingredients to Transformer to address this challenge. First, in low-resolution stages of the generative process, standard global self-attention is replaced with the proposed multi-axis blocked self-attention which allows efficient mixing of local and global attention. Second, in high-resolution stages, we drop self-attention while only keeping multi-layer perceptrons reminiscent of the implicit neural function. To further improve the performance, we introduce an additional self-modulation component based on cross-attention. The resulting model, denoted as HiT, has a linear computational complexity with respect to the image size and thus directly scales to synthesizing high definition images. We show in the experiments that the proposed HiT achieves state-of-the-art FID scores of 31.87 and 2.95 on unconditional ImageNet $128 \times 128$ and FFHQ $256 \times 256$, respectively, with a reasonable throughput. We believe the proposed HiT is an important milestone for generators in GANs which are completely free of convolutions.
Aggregating Nested Transformers
May 26, 2021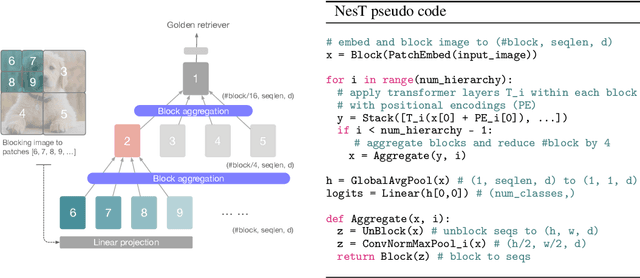
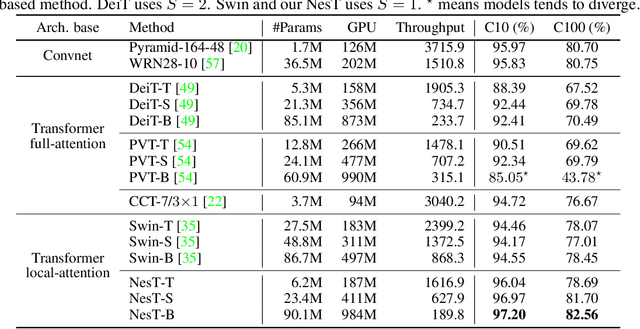
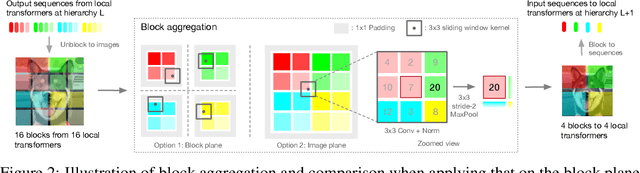
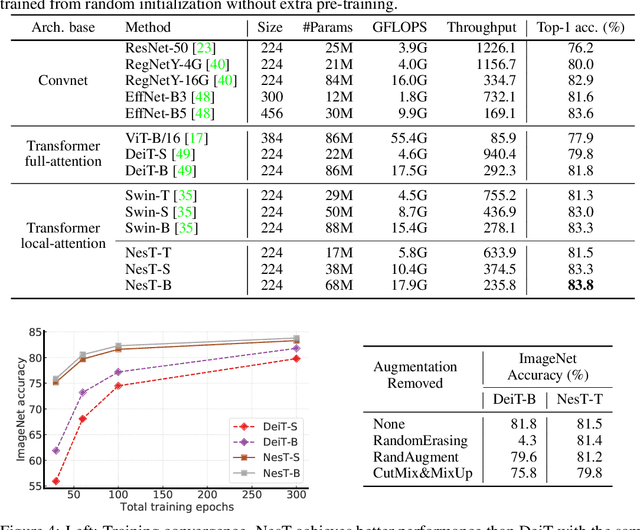
Although hierarchical structures are popular in recent vision transformers, they require sophisticated designs and massive datasets to work well. In this work, we explore the idea of nesting basic local transformers on non-overlapping image blocks and aggregating them in a hierarchical manner. We find that the block aggregation function plays a critical role in enabling cross-block non-local information communication. This observation leads us to design a simplified architecture with minor code changes upon the original vision transformer and obtains improved performance compared to existing methods. Our empirical results show that the proposed method NesT converges faster and requires much less training data to achieve good generalization. For example, a NesT with 68M parameters trained on ImageNet for 100/300 epochs achieves $82.3\%/83.8\%$ accuracy evaluated on $224\times 224$ image size, outperforming previous methods with up to $57\%$ parameter reduction. Training a NesT with 6M parameters from scratch on CIFAR10 achieves $96\%$ accuracy using a single GPU, setting a new state of the art for vision transformers. Beyond image classification, we extend the key idea to image generation and show NesT leads to a strong decoder that is 8$\times$ faster than previous transformer based generators. Furthermore, we also propose a novel method for visually interpreting the learned model.
More Than Just Attention: Learning Cross-Modal Attentions with Contrastive Constraints
May 20, 2021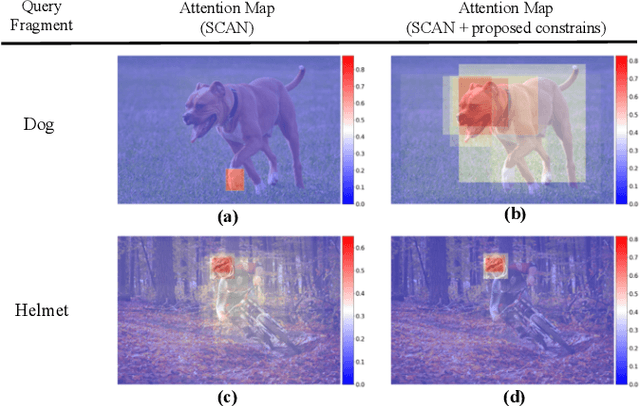
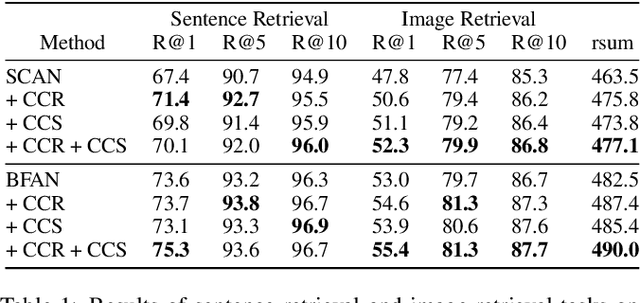
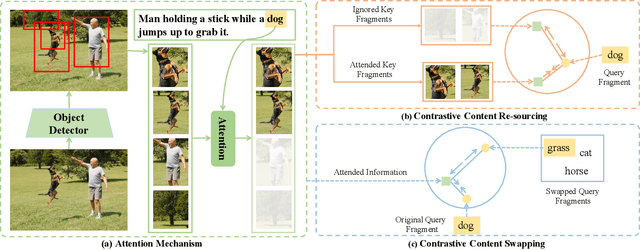
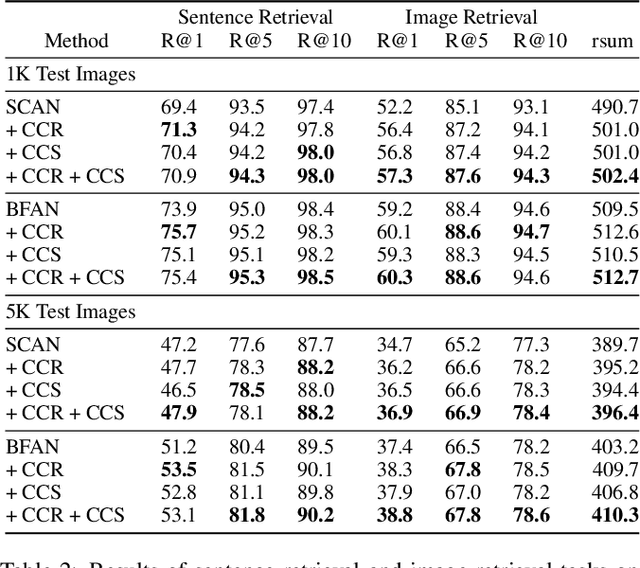
Attention mechanisms have been widely applied to cross-modal tasks such as image captioning and information retrieval, and have achieved remarkable improvements due to its capability to learn fine-grained relevance across different modalities. However, existing attention models could be sub-optimal and lack preciseness because there is no direct supervision involved during training. In this work, we propose Contrastive Content Re-sourcing (CCR) and Contrastive Content Swapping (CCS) constraints to address such limitation. These constraints supervise the training of attention models in a contrastive learning manner without requiring explicit attention annotations. Additionally, we introduce three metrics, namely Attention Precision, Recall and F1-Score, to quantitatively evaluate the attention quality. We evaluate the proposed constraints with cross-modal retrieval (image-text matching) task. The experiments on both Flickr30k and MS-COCO datasets demonstrate that integrating these attention constraints into two state-of-the-art attention-based models improves the model performance in terms of both retrieval accuracy and attention metrics.
SMIL: Multimodal Learning with Severely Missing Modality
Mar 09, 2021
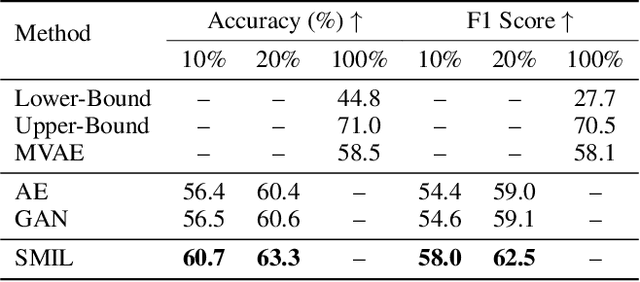
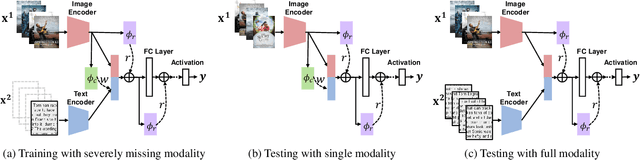
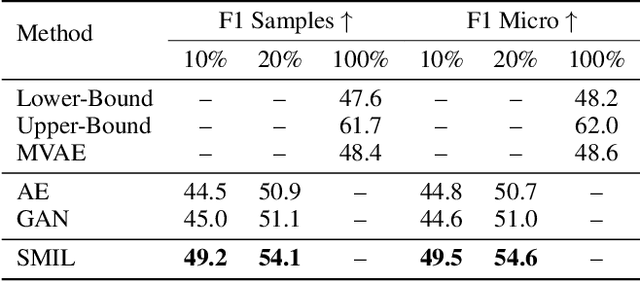
A common assumption in multimodal learning is the completeness of training data, i.e., full modalities are available in all training examples. Although there exists research endeavor in developing novel methods to tackle the incompleteness of testing data, e.g., modalities are partially missing in testing examples, few of them can handle incomplete training modalities. The problem becomes even more challenging if considering the case of severely missing, e.g., 90% training examples may have incomplete modalities. For the first time in the literature, this paper formally studies multimodal learning with missing modality in terms of flexibility (missing modalities in training, testing, or both) and efficiency (most training data have incomplete modality). Technically, we propose a new method named SMIL that leverages Bayesian meta-learning in uniformly achieving both objectives. To validate our idea, we conduct a series of experiments on three popular benchmarks: MM-IMDb, CMU-MOSI, and avMNIST. The results prove the state-of-the-art performance of SMIL over existing methods and generative baselines including autoencoders and generative adversarial networks. Our code is available at https://github.com/mengmenm/SMIL.
Box Re-Ranking: Unsupervised False Positive Suppression for Domain Adaptive Pedestrian Detection
Feb 01, 2021
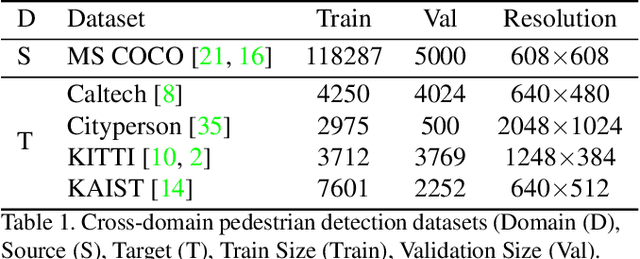
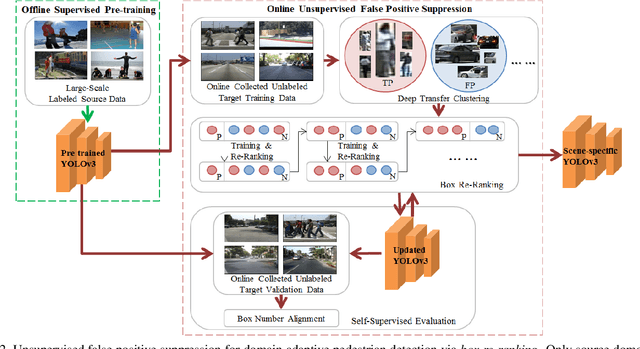
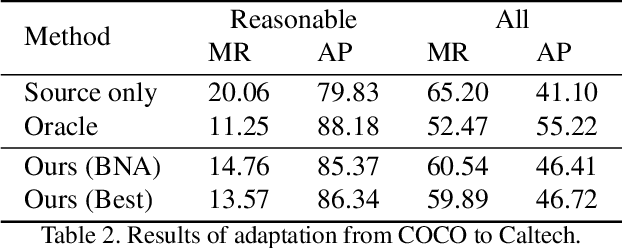
False positive is one of the most serious problems brought by agnostic domain shift in domain adaptive pedestrian detection. However, it is impossible to label each box in countless target domains. Therefore, it yields our attention to suppress false positive in each target domain in an unsupervised way. In this paper, we model an object detection task into a ranking task among positive and negative boxes innovatively, and thus transform a false positive suppression problem into a box re-ranking problem elegantly, which makes it feasible to solve without manual annotation. An attached problem during box re-ranking appears that no labeled validation data is available for cherrypicking. Considering we aim to keep the detection of true positive unchanged, we propose box number alignment, a self-supervised evaluation metric, to prevent the optimized model from capacity degeneration. Extensive experiments conducted on cross-domain pedestrian detection datasets have demonstrated the effectiveness of our proposed framework. Furthermore, the extension to two general unsupervised domain adaptive object detection benchmarks also supports our superiority to other state-of-the-arts.