 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Tags Matter for Zero-Shot Neural Machine Translation
Jun 15, 2021
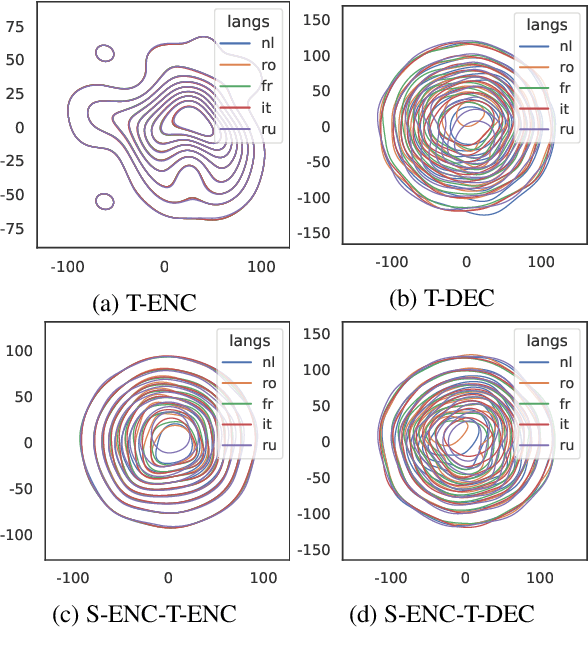
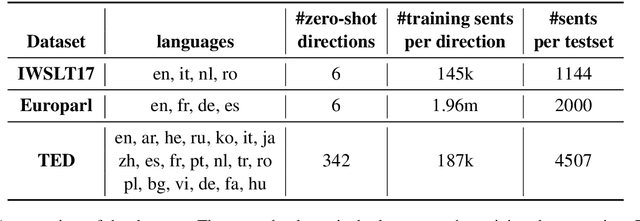
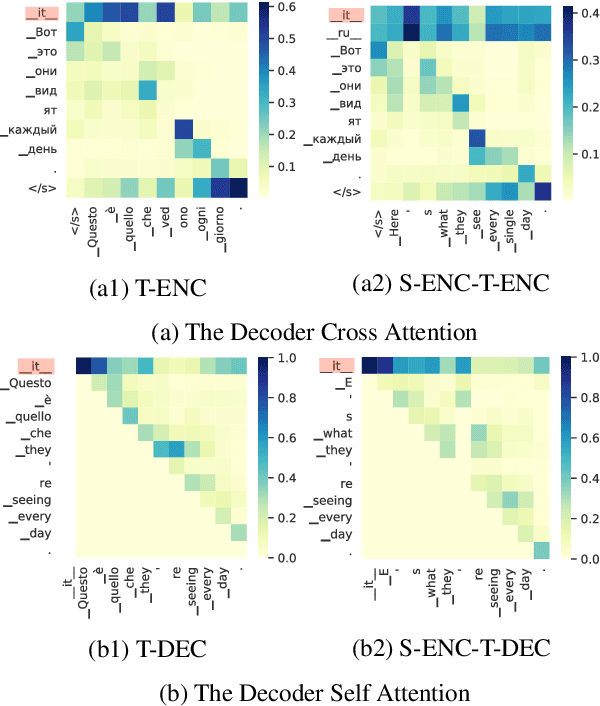
Multilingual Neural Machine Translation (MNMT) has aroused widespread interest due to its efficiency. An exciting advantage of MNMT models is that they could also translate between unsupervised (zero-shot) language directions. Language tag (LT) strategies are often adopted to indicate the translation directions in MNMT. In this paper, we demonstrate that the LTs are not only indicators for translation directions but also crucial to zero-shot translation qualities. Unfortunately, previous work tends to ignore the importance of LT strategies. We demonstrate that a proper LT strategy could enhance the consistency of semantic representations and alleviate the off-target issue in zero-shot directions. Experimental results show that by ignoring the source language tag (SLT) and adding the target language tag (TLT) to the encoder, the zero-shot translations could achieve a +8 BLEU score difference over other LT strategies in IWSLT17, Europarl, TED talks translation tasks.
MST: Masked Self-Supervised Transformer for Visual Representation
Jun 10, 2021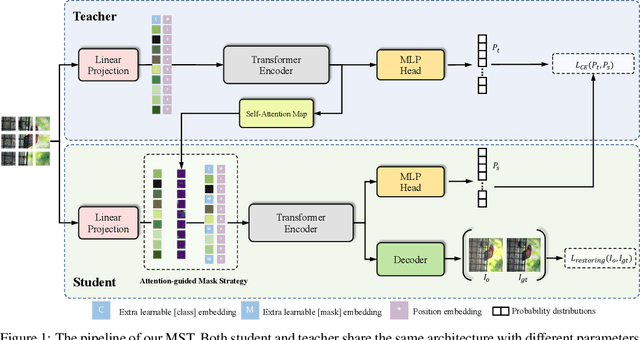
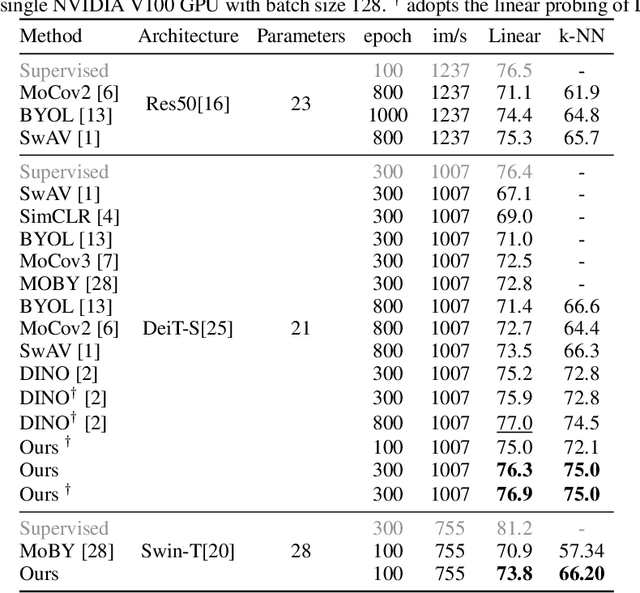

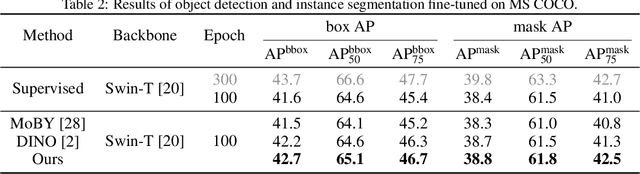
Transformer has been widely used for self-supervised pre-training in Natural Language Processing (NLP) and achieved great success. However, it has not been fully explored in visual self-supervised learning. Meanwhile, previous methods only consider the high-level feature and learning representation from a global perspective, which may fail to transfer to the downstream dense prediction tasks focusing on local features. In this paper, we present a novel Masked Self-supervised Transformer approach named MST, which can explicitly capture the local context of an image while preserving the global semantic information. Specifically, inspired by the Masked Language Modeling (MLM) in NLP, we propose a masked token strategy based on the multi-head self-attention map, which dynamically masks some tokens of local patches without damaging the crucial structure for self-supervised learning. More importantly, the masked tokens together with the remaining tokens are further recovered by a global image decoder, which preserves the spatial information of the image and is more friendly to the downstream dense prediction tasks. The experiments on multiple datasets demonstrate the effectiveness and generality of the proposed method. For instance, MST achieves Top-1 accuracy of 76.9% with DeiT-S only using 300-epoch pre-training by linear evaluation, which outperforms supervised methods with the same epoch by 0.4% and its comparable variant DINO by 1.0\%. For dense prediction tasks, MST also achieves 42.7% mAP on MS COCO object detection and 74.04% mIoU on Cityscapes segmentation only with 100-epoch pre-training.
Contrastive Learning for Many-to-many Multilingual Neural Machine Translation
Jun 09, 2021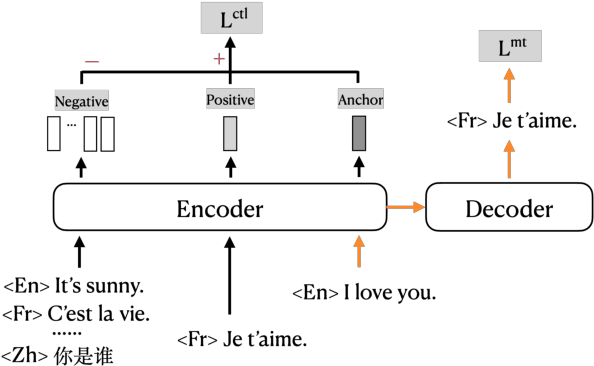
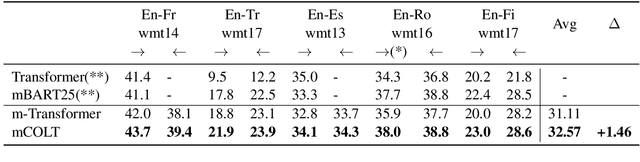

Existing multilingual machine translation approaches mainly focus on English-centric directions, while the non-English directions still lag behind. In this work, we aim to build a many-to-many translation system with an emphasis on the quality of non-English language directions. Our intuition is based on the hypothesis that a universal cross-language representation leads to better multilingual translation performance. To this end, we propose mRASP2, a training method to obtain a single unified multilingual translation model. mRASP2 is empowered by two techniques: a) a contrastive learning scheme to close the gap among representations of different languages, and b) data augmentation on both multiple parallel and monolingual data to further align token representations. For English-centric directions, mRASP2 outperforms existing best unified model and achieves competitive or even better performance than the pre-trained and fine-tuned model mBART on tens of WMT's translation directions. For non-English directions, mRASP2 achieves an improvement of average 10+ BLEU compared with the multilingual Transformer baseline. Code, data and trained models are available at https://github.com/PANXiao1994/mRASP2.
Learning Language Specific Sub-network for Multilingual Machine Translation
May 19, 2021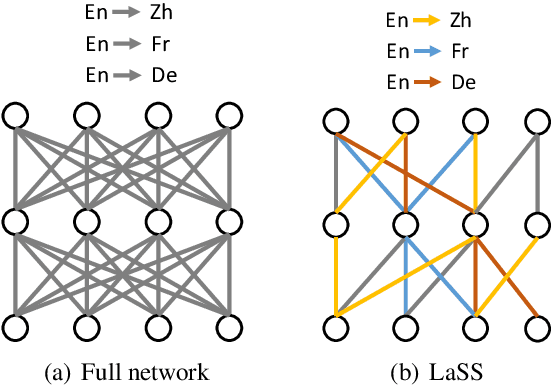
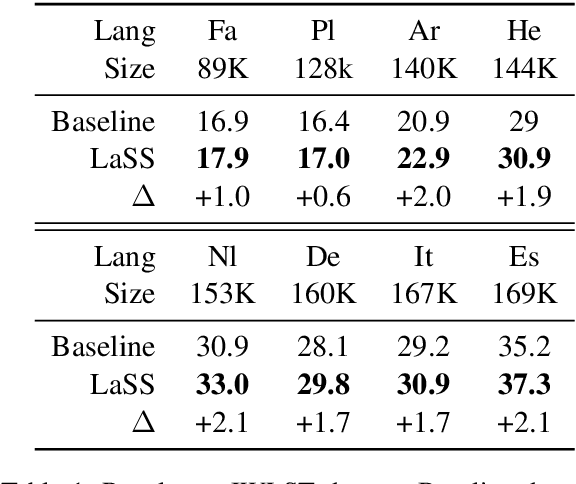
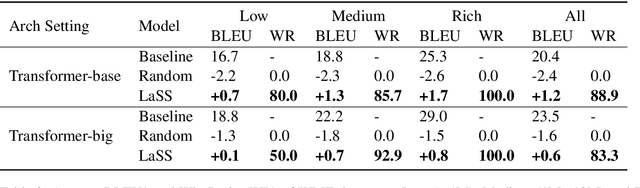
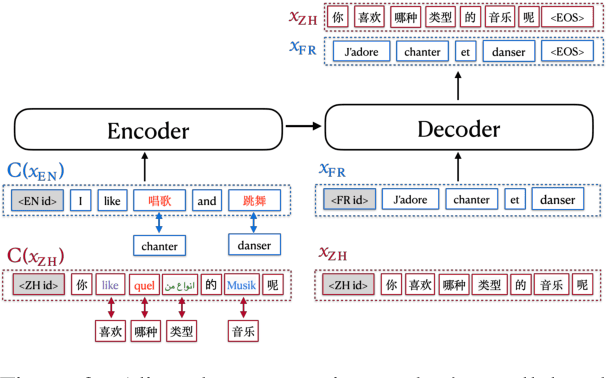
Multilingual neural machine translation aims at learning a single translation model for multiple languages. These jointly trained models often suffer from performance degradation on rich-resource language pairs. We attribute this degeneration to parameter interference. In this paper, we propose LaSS to jointly train a single unified multilingual MT model. LaSS learns Language Specific Sub-network (LaSS) for each language pair to counter parameter interference. Comprehensive experiments on IWSLT and WMT datasets with various Transformer architectures show that LaSS obtains gains on 36 language pairs by up to 1.2 BLEU. Besides, LaSS shows its strong generalization performance at easy extension to new language pairs and zero-shot translation.LaSS boosts zero-shot translation with an average of 8.3 BLEU on 30 language pairs. Codes and trained models are available at https://github.com/NLP-Playground/LaSS.
The Volctrans Machine Translation System for WMT20
Oct 28, 2020
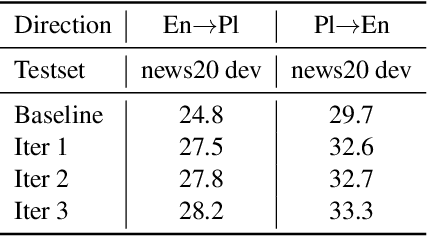
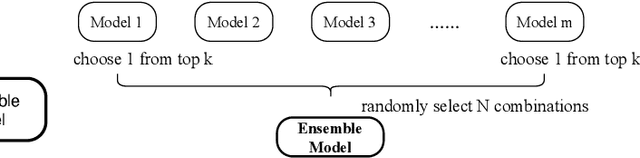
This paper describes our VolcTrans system on WMT20 shared news translation task. We participated in 8 translation directions. Our basic systems are based on Transformer, with several variants (wider or deeper Transformers, dynamic convolutions). The final system includes text pre-process, data selection, synthetic data generation, advanced model ensemble, and multilingual pre-training.
Multimodal Categorization of Crisis Events in Social Media
Apr 10, 2020
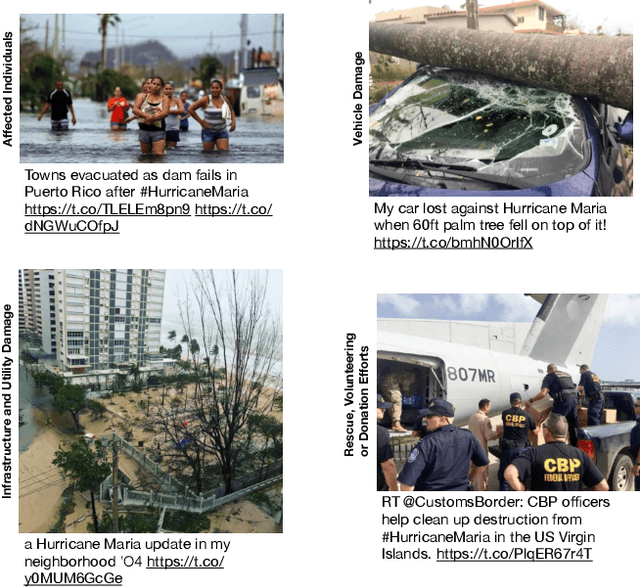
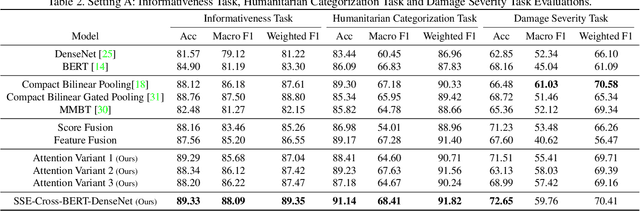
Recent developments in image classification and natural language processing, coupled with the rapid growth in social media usage, have enabled fundamental advances in detecting breaking events around the world in real-time. Emergency response is one such area that stands to gain from these advances. By processing billions of texts and images a minute, events can be automatically detected to enable emergency response workers to better assess rapidly evolving situations and deploy resources accordingly. To date, most event detection techniques in this area have focused on image-only or text-only approaches, limiting detection performance and impacting the quality of information delivered to crisis response teams. In this paper, we present a new multimodal fusion method that leverages both images and texts as input. In particular, we introduce a cross-attention module that can filter uninformative and misleading components from weak modalities on a sample by sample basis. In addition, we employ a multimodal graph-based approach to stochastically transition between embeddings of different multimodal pairs during training to better regularize the learning process as well as dealing with limited training data by constructing new matched pairs from different samples. We show that our method outperforms the unimodal approaches and strong multimodal baselines by a large margin on three crisis-related tasks.
* Conference on Computer Vision and Pattern Recognition (CVPR 2020)
Advances in Collaborative Filtering and Ranking
Feb 27, 2020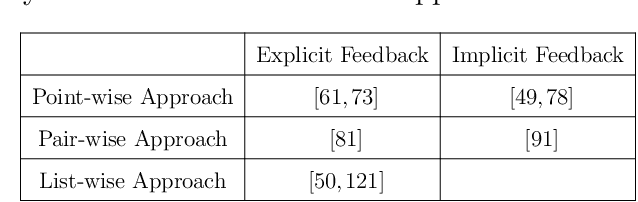
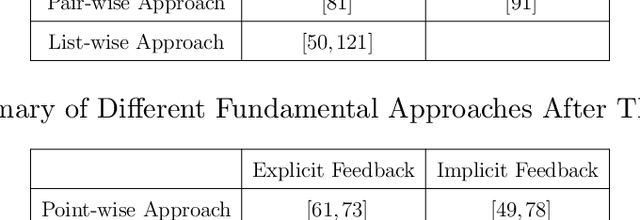
In this dissertation, we cover some recent advances in collaborative filtering and ranking. In chapter 1, we give a brief introduction of the history and the current landscape of collaborative filtering and ranking; chapter 2 we first talk about pointwise collaborative filtering problem with graph information, and how our proposed new method can encode very deep graph information which helps four existing graph collaborative filtering algorithms; chapter 3 is on the pairwise approach for collaborative ranking and how we speed up the algorithm to near-linear time complexity; chapter 4 is on the new listwise approach for collaborative ranking and how the listwise approach is a better choice of loss for both explicit and implicit feedback over pointwise and pairwise loss; chapter 5 is about the new regularization technique Stochastic Shared Embeddings (SSE) we proposed for embedding layers and how it is both theoretically sound and empirically effectively for 6 different tasks across recommendation and natural language processing; chapter 6 is how we introduce personalization for the state-of-the-art sequential recommendation model with the help of SSE, which plays an important role in preventing our personalized model from overfitting to the training data; chapter 7, we summarize what we have achieved so far and predict what the future directions can be; chapter 8 is the appendix to all the chapters.
Temporal Collaborative Ranking Via Personalized Transformer
Aug 15, 2019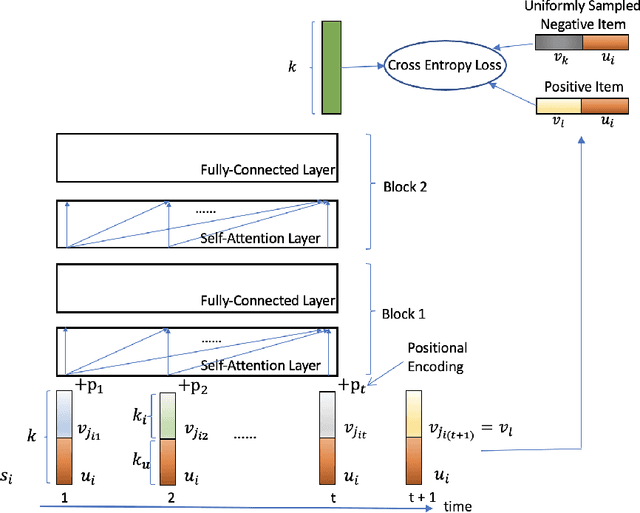
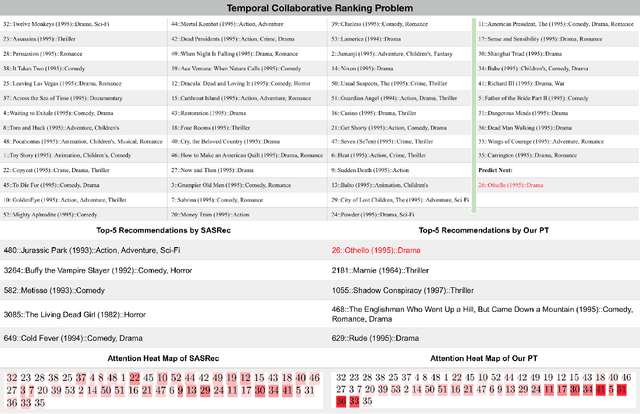

The collaborative ranking problem has been an important open research question as most recommendation problems can be naturally formulated as ranking problems. While much of collaborative ranking methodology assumes static ranking data, the importance of temporal information to improving ranking performance is increasingly apparent. Recent advances in deep learning, especially the discovery of various attention mechanisms and newer architectures in addition to widely used RNN and CNN in natural language processing, have allowed us to make better use of the temporal ordering of items that each user has engaged with. In particular, the SASRec model, inspired by the popular Transformer model in natural languages processing, has achieved state-of-art results in the temporal collaborative ranking problem and enjoyed more than 10x speed-up when compared to earlier CNN/RNN-based methods. However, SASRec is inherently an un-personalized model and does not include personalized user embeddings. To overcome this limitation, we propose a Personalized Transformer (SSE-PT) model, outperforming SASRec by almost 5% in terms of NDCG@10 on 5 real-world datasets. Furthermore, after examining some random users' engagement history and corresponding attention heat maps used during the inference stage, we find our model is not only more interpretable but also able to focus on recent engagement patterns for each user. Moreover, our SSE-PT model with a slight modification, which we call SSE-PT++, can handle extremely long sequences and outperform SASRec in ranking results with comparable training speed, striking a balance between performance and speed requirements. Code and data are open sourced at https://github.com/wuliwei9278/SSE-PT.
Graph DNA: Deep Neighborhood Aware Graph Encoding for Collaborative Filtering
May 29, 2019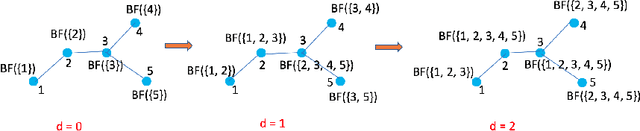
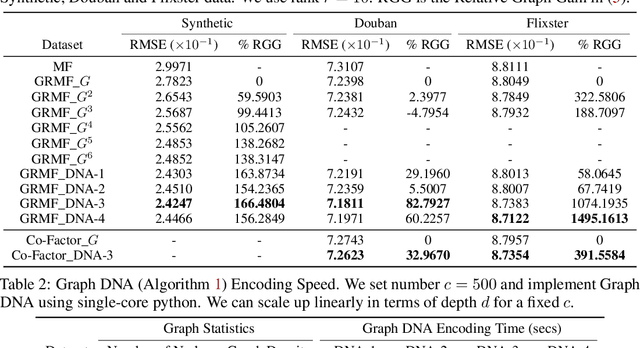
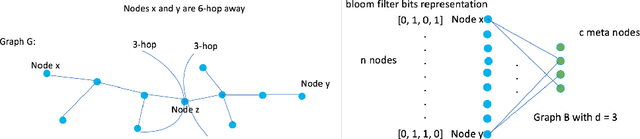

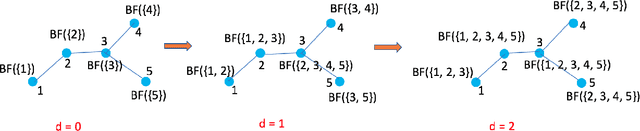
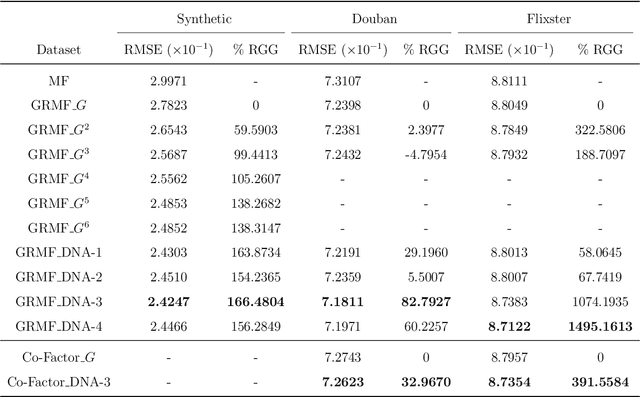
In this paper, we consider recommender systems with side information in the form of graphs. Existing collaborative filtering algorithms mainly utilize only immediate neighborhood information and have a hard time taking advantage of deeper neighborhoods beyond 1-2 hops. The main caveat of exploiting deeper graph information is the rapidly growing time and space complexity when incorporating information from these neighborhoods. In this paper, we propose using Graph DNA, a novel Deep Neighborhood Aware graph encoding algorithm, for exploiting deeper neighborhood information. DNA encoding computes approximate deep neighborhood information in linear time using Bloom filters, a space-efficient probabilistic data structure and results in a per-node encoding that is logarithmic in the number of nodes in the graph. It can be used in conjunction with both feature-based and graph-regularization-based collaborative filtering algorithms. Graph DNA has the advantages of being memory and time efficient and providing additional regularization when compared to directly using higher order graph information. We conduct experiments on real-world datasets, showing graph DNA can be easily used with 4 popular collaborative filtering algorithms and consistently leads to a performance boost with little computational and memory overhead.
Stochastic Shared Embeddings: Data-driven Regularization of Embedding Layers
May 25, 2019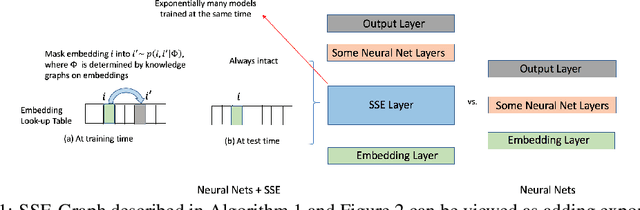

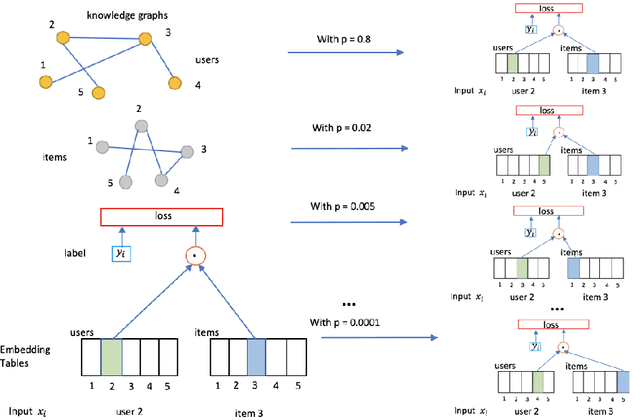
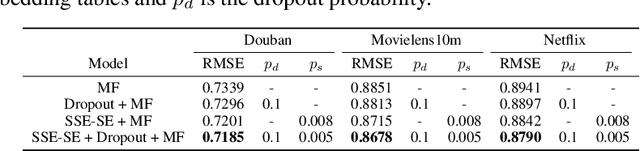
In deep neural nets, lower level embedding layers account for a large portion of the total number of parameters. Tikhonov regularization, graph-based regularization, and hard parameter sharing are approaches that introduce explicit biases into training in a hope to reduce statistical complexity. Alternatively, we propose stochastically shared embeddings (SSE), a data-driven approach to regularizing embedding layers, which stochastically transitions between embeddings during stochastic gradient descent (SGD). Because SSE integrates seamlessly with existing SGD algorithms, it can be used with only minor modifications when training large scale neural networks. We develop two versions of SSE: SSE-Graph using knowledge graphs of embeddings; SSE-SE using no prior information. We provide theoretical guarantees for our method and show its empirical effectiveness on 6 distinct tasks, from simple neural networks with one hidden layer in recommender systems, to the transformer and BERT in natural languages. We find that when used along with widely-used regularization methods such as weight decay and dropout, our proposed SSE can further reduce overfitting, which often leads to more favorable generalization results.