 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Epidemiological Modeling by Black-box Knowledge Distillation: An Accurate Deep Learning Model for COVID-19
Jan 20, 2021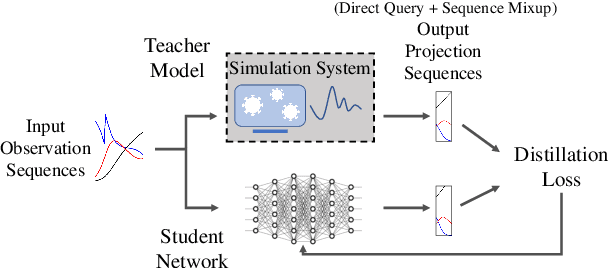
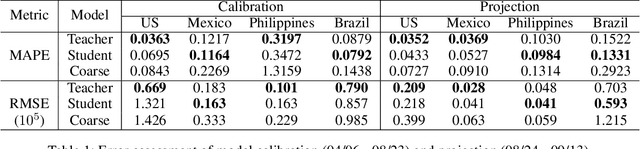
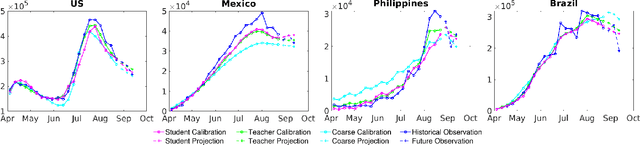

An accurate and efficient forecasting system is imperative to the prevention of emerging infectious diseases such as COVID-19 in public health. This system requires accurate transient modeling, lower computation cost, and fewer observation data. To tackle these three challenges, we propose a novel deep learning approach using black-box knowledge distillation for both accurate and efficient transmission dynamics prediction in a practical manner. First, we leverage mixture models to develop an accurate, comprehensive, yet impractical simulation system. Next, we use simulated observation sequences to query the simulation system to retrieve simulated projection sequences as knowledge. Then, with the obtained query data, sequence mixup is proposed to improve query efficiency, increase knowledge diversity, and boost distillation model accuracy. Finally, we train a student deep neural network with the retrieved and mixed observation-projection sequences for practical use. The case study on COVID-19 justifies that our approach accurately projects infections with much lower computation cost when observation data are limited.
Ranking Neural Checkpoints
Nov 23, 2020
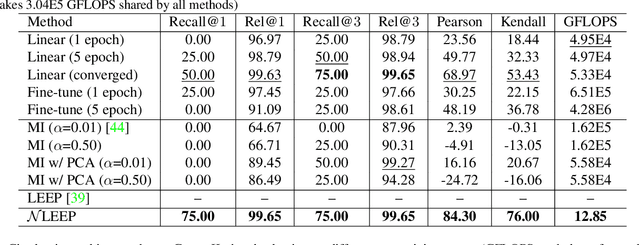
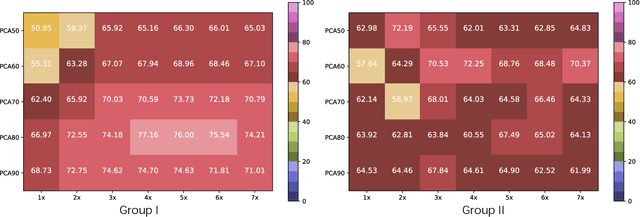
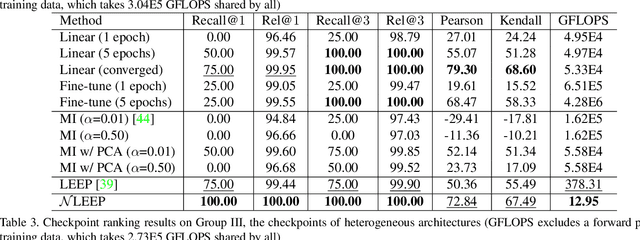
This paper is concerned with ranking many pre-trained deep neural networks (DNNs), called checkpoints, for the transfer learning to a downstream task. Thanks to the broad use of DNNs, we may easily collect hundreds of checkpoints from various sources. Which of them transfers the best to our downstream task of interest? Striving to answer this question thoroughly, we establish a neural checkpoint ranking benchmark (NeuCRaB) and study some intuitive ranking measures. These measures are generic, applying to the checkpoints of different output types without knowing how the checkpoints are pre-trained on which dataset. They also incur low computation cost, making them practically meaningful. Our results suggest that the linear separability of the features extracted by the checkpoints is a strong indicator of transferability. We also arrive at a new ranking measure, NLEEP, which gives rise to the best performance in the experiments.
Cross-Domain Learning for Classifying Propaganda in Online Contents
Nov 22, 2020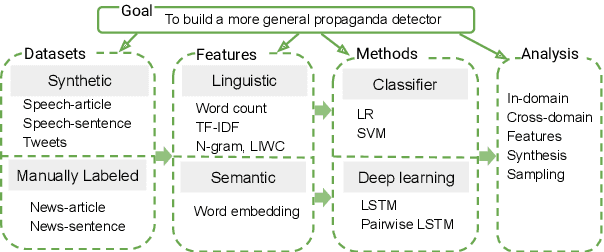
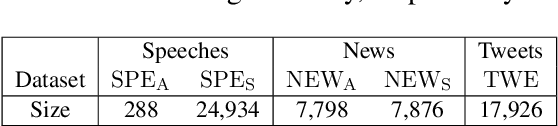
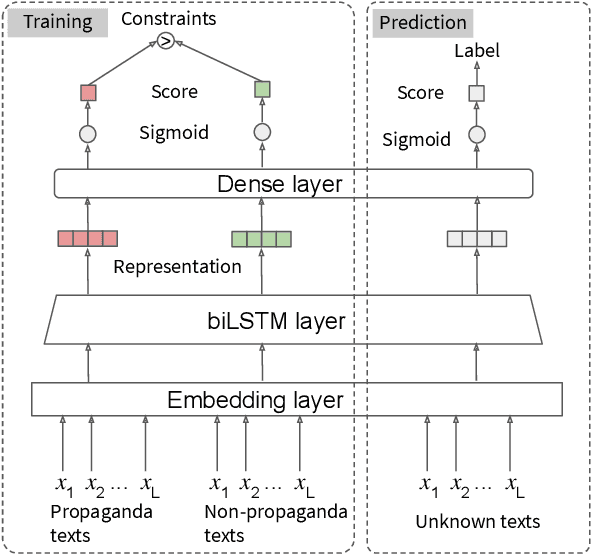

As news and social media exhibit an increasing amount of manipulative polarized content, detecting such propaganda has received attention as a new task for content analysis. Prior work has focused on supervised learning with training data from the same domain. However, as propaganda can be subtle and keeps evolving, manual identification and proper labeling are very demanding. As a consequence, training data is a major bottleneck. In this paper, we tackle this bottleneck and present an approach to leverage cross-domain learning, based on labeled documents and sentences from news and tweets, as well as political speeches with a clear difference in their degrees of being propagandistic. We devise informative features and build various classifiers for propaganda labeling, using cross-domain learning. Our experiments demonstrate the usefulness of this approach, and identify difficulties and limitations in various configurations of sources and targets for the transfer step. We further analyze the influence of various features, and characterize salient indicators of propaganda.
Improving Object Detection with Selective Self-supervised Self-training
Jul 24, 2020
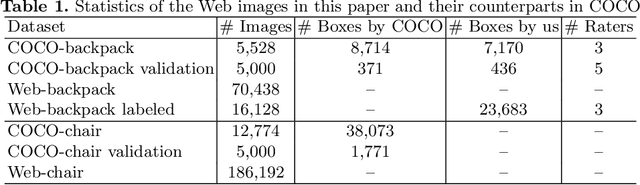

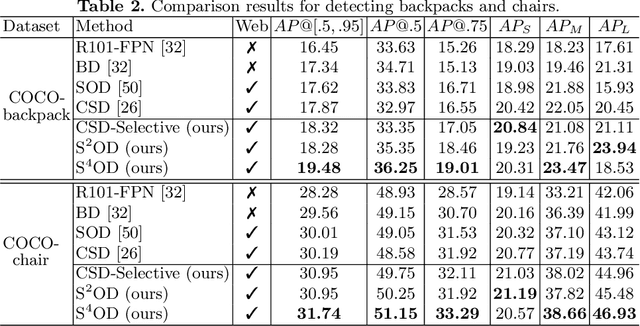
We study how to leverage Web images to augment human-curated object detection datasets. Our approach is two-pronged. On the one hand, we retrieve Web images by image-to-image search, which incurs less domain shift from the curated data than other search methods. The Web images are diverse, supplying a wide variety of object poses, appearances, their interactions with the context, etc. On the other hand, we propose a novel learning method motivated by two parallel lines of work that explore unlabeled data for image classification: self-training and self-supervised learning. They fail to improve object detectors in their vanilla forms due to the domain gap between the Web images and curated datasets. To tackle this challenge, we propose a selective net to rectify the supervision signals in Web images. It not only identifies positive bounding boxes but also creates a safe zone for mining hard negative boxes. We report state-of-the-art results on detecting backpacks and chairs from everyday scenes, along with other challenging object classes.
Trace-Norm Adversarial Examples
Jul 02, 2020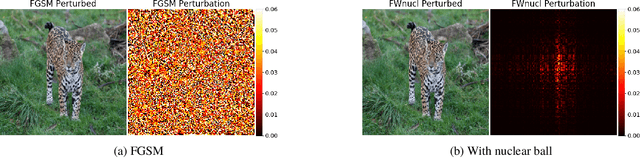
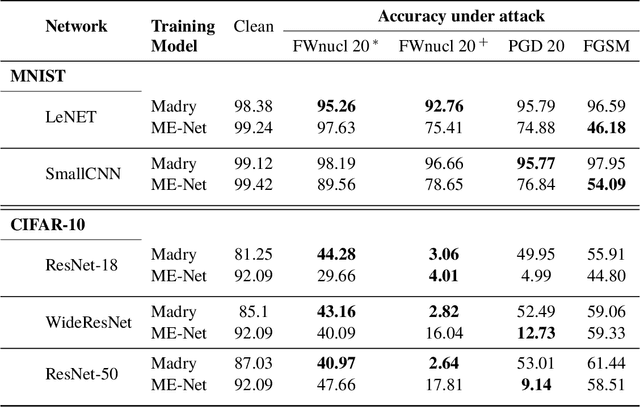

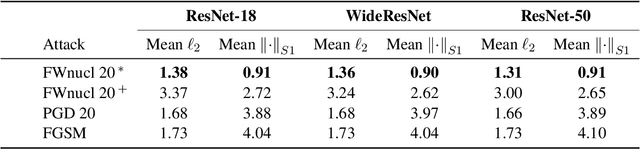
White box adversarial perturbations are sought via iterative optimization algorithms most often minimizing an adversarial loss on a $l_p$ neighborhood of the original image, the so-called distortion set. Constraining the adversarial search with different norms results in disparately structured adversarial examples. Here we explore several distortion sets with structure-enhancing algorithms. These new structures for adversarial examples, yet pervasive in optimization, are for instance a challenge for adversarial theoretical certification which again provides only $l_p$ certificates. Because adversarial robustness is still an empirical field, defense mechanisms should also reasonably be evaluated against differently structured attacks. Besides, these structured adversarial perturbations may allow for larger distortions size than their $l_p$ counter-part while remaining imperceptible or perceptible as natural slight distortions of the image. Finally, they allow some control on the generation of the adversarial perturbation, like (localized) bluriness.
Neural Networks Are More Productive Teachers Than Human Raters: Active Mixup for Data-Efficient Knowledge Distillation from a Blackbox Model
Mar 31, 2020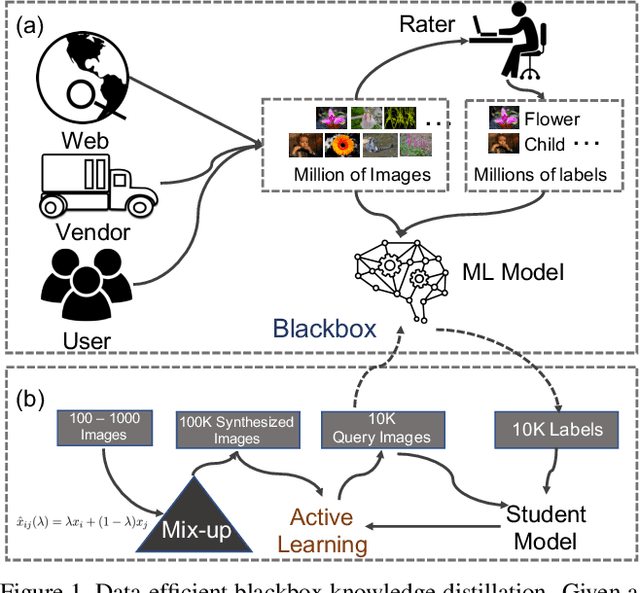



We study how to train a student deep neural network for visual recognition by distilling knowledge from a blackbox teacher model in a data-efficient manner. Progress on this problem can significantly reduce the dependence on large-scale datasets for learning high-performing visual recognition models. There are two major challenges. One is that the number of queries into the teacher model should be minimized to save computational and/or financial costs. The other is that the number of images used for the knowledge distillation should be small; otherwise, it violates our expectation of reducing the dependence on large-scale datasets. To tackle these challenges, we propose an approach that blends mixup and active learning. The former effectively augments the few unlabeled images by a big pool of synthetic images sampled from the convex hull of the original images, and the latter actively chooses from the pool hard examples for the student neural network and query their labels from the teacher model. We validate our approach with extensive experiments.
BachGAN: High-Resolution Image Synthesis from Salient Object Layout
Mar 27, 2020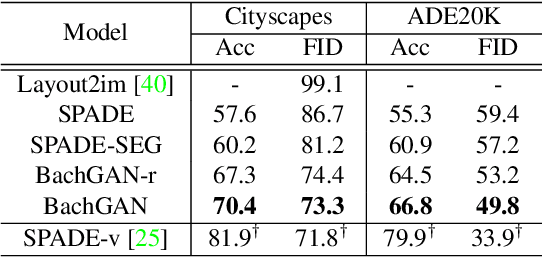
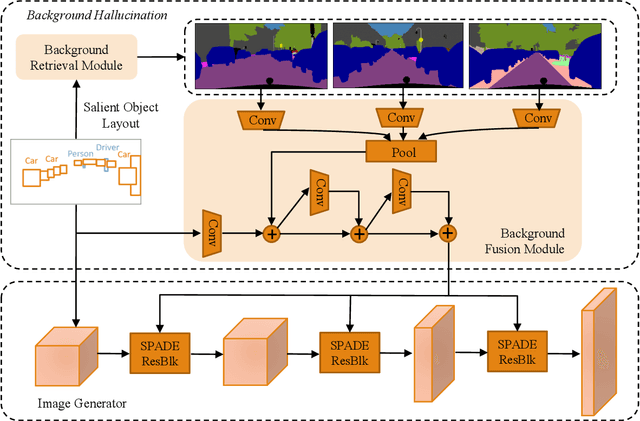


We propose a new task towards more practical application for image generation - high-quality image synthesis from salient object layout. This new setting allows users to provide the layout of salient objects only (i.e., foreground bounding boxes and categories), and lets the model complete the drawing with an invented background and a matching foreground. Two main challenges spring from this new task: (i) how to generate fine-grained details and realistic textures without segmentation map input; and (ii) how to create a background and weave it seamlessly into standalone objects. To tackle this, we propose Background Hallucination Generative Adversarial Network (BachGAN), which first selects a set of segmentation maps from a large candidate pool via a background retrieval module, then encodes these candidate layouts via a background fusion module to hallucinate a suitable background for the given objects. By generating the hallucinated background representation dynamically, our model can synthesize high-resolution images with both photo-realistic foreground and integral background. Experiments on Cityscapes and ADE20K datasets demonstrate the advantage of BachGAN over existing methods, measured on both visual fidelity of generated images and visual alignment between output images and input layouts.
Rethinking Class-Balanced Methods for Long-Tailed Visual Recognition from a Domain Adaptation Perspective
Mar 24, 2020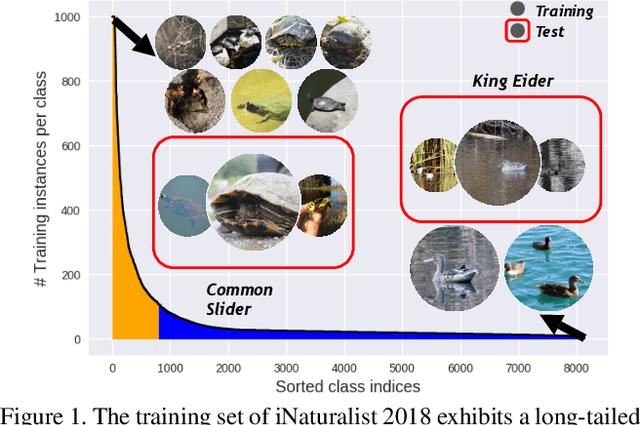


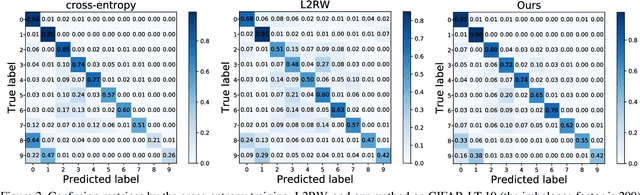
Object frequency in the real world often follows a power law, leading to a mismatch between datasets with long-tailed class distributions seen by a machine learning model and our expectation of the model to perform well on all classes. We analyze this mismatch from a domain adaptation point of view. First of all, we connect existing class-balanced methods for long-tailed classification to target shift, a well-studied scenario in domain adaptation. The connection reveals that these methods implicitly assume that the training data and test data share the same class-conditioned distribution, which does not hold in general and especially for the tail classes. While a head class could contain abundant and diverse training examples that well represent the expected data at inference time, the tail classes are often short of representative training data. To this end, we propose to augment the classic class-balanced learning by explicitly estimating the differences between the class-conditioned distributions with a meta-learning approach. We validate our approach with six benchmark datasets and three loss functions.
Self-supervised learning for audio-visual speaker diarization
Feb 13, 2020



Speaker diarization, which is to find the speech segments of specific speakers, has been widely used in human-centered applications such as video conferences or human-computer interaction systems. In this paper, we propose a self-supervised audio-video synchronization learning method to address the problem of speaker diarization without massive labeling effort. We improve the previous approaches by introducing two new loss functions: the dynamic triplet loss and the multinomial loss. We test them on a real-world human-computer interaction system and the results show our best model yields a remarkable gain of +8%F1-scoresas well as diarization error rate reduction. Finally, we introduce a new large scale audio-video corpus designed to fill the vacancy of audio-video datasets in Chinese.
AdaFilter: Adaptive Filter Fine-tuning for Deep Transfer Learning
Dec 09, 2019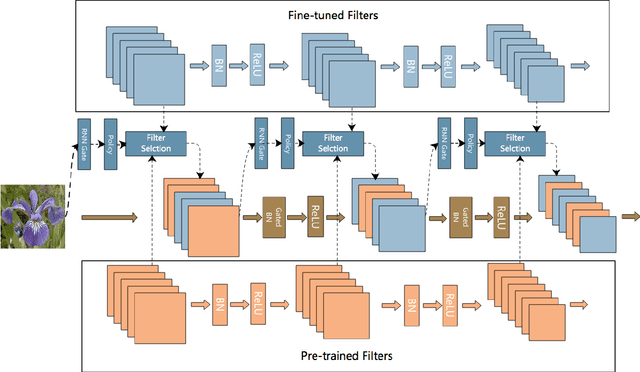
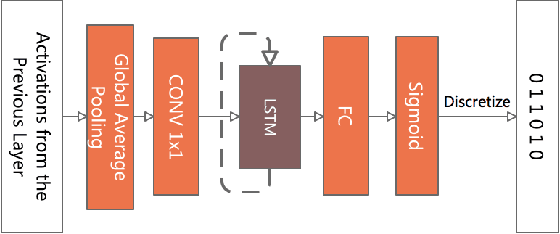

There is an increasing number of pre-trained deep neural network models. However, it is still unclear how to effectively use these models for a new task. Transfer learning, which aims to transfer knowledge from source tasks to a target task, is an effective solution to this problem. Fine-tuning is a popular transfer learning technique for deep neural networks where a few rounds of training are applied to the parameters of a pre-trained model to adapt them to a new task. Despite its popularity, in this paper, we show that fine-tuning suffers from several drawbacks. We propose an adaptive fine-tuning approach, called AdaFilter, which selects only a part of the convolutional filters in the pre-trained model to optimize on a per-example basis. We use a recurrent gated network to selectively fine-tune convolutional filters based on the activations of the previous layer. We experiment with 7 public image classification datasets and the results show that AdaFilter can reduce the average classification error of the standard fine-tuning by 2.54%.