 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Role of Depth in Surgical Vision Foundation Models: An Empirical Study of RGB-D Pre-training
Jan 26, 2026Vision foundation models (VFMs) have emerged as powerful tools for surgical scene understanding. However, current approaches predominantly rely on unimodal RGB pre-training, overlooking the complex 3D geometry inherent to surgical environments. Although several architectures support multimodal or geometry-aware inputs in general computer vision, the benefits of incorporating depth information in surgical settings remain underexplored. We conduct a large-scale empirical study comparing eight ViT-based VFMs that differ in pre-training domain, learning objective, and input modality (RGB vs. RGB-D). For pre-training, we use a curated dataset of 1.4 million robotic surgical images paired with depth maps generated from an off-the-shelf network. We evaluate these models under both frozen-backbone and end-to-end fine-tuning protocols across eight surgical datasets spanning object detection, segmentation, depth estimation, and pose estimation. Our experiments yield several consistent findings. Models incorporating explicit geometric tokenization, such as MultiMAE, substantially outperform unimodal baselines across all tasks. Notably, geometric-aware pre-training enables remarkable data efficiency: models fine-tuned on just 25% of labeled data consistently surpass RGB-only models trained on the full dataset. Importantly, these gains require no architectural or runtime changes at inference; depth is used only during pre-training, making adoption straightforward. These findings suggest that multimodal pre-training offers a viable path towards building more capable surgical vision systems.
Multi-view Video-Pose Pretraining for Operating Room Surgical Activity Recognition
Feb 19, 2025



Understanding the workflow of surgical procedures in complex operating rooms requires a deep understanding of the interactions between clinicians and their environment. Surgical activity recognition (SAR) is a key computer vision task that detects activities or phases from multi-view camera recordings. Existing SAR models often fail to account for fine-grained clinician movements and multi-view knowledge, or they require calibrated multi-view camera setups and advanced point-cloud processing to obtain better results. In this work, we propose a novel calibration-free multi-view multi-modal pretraining framework called Multiview Pretraining for Video-Pose Surgical Activity Recognition PreViPS, which aligns 2D pose and vision embeddings across camera views. Our model follows CLIP-style dual-encoder architecture: one encoder processes visual features, while the other encodes human pose embeddings. To handle the continuous 2D human pose coordinates, we introduce a tokenized discrete representation to convert the continuous 2D pose coordinates into discrete pose embeddings, thereby enabling efficient integration within the dual-encoder framework. To bridge the gap between these two modalities, we propose several pretraining objectives using cross- and in-modality geometric constraints within the embedding space and incorporating masked pose token prediction strategy to enhance representation learning. Extensive experiments and ablation studies demonstrate improvements over the strong baselines, while data-efficiency experiments on two distinct operating room datasets further highlight the effectiveness of our approach. We highlight the benefits of our approach for surgical activity recognition in both multi-view and single-view settings, showcasing its practical applicability in complex surgical environments. Code will be made available at: https://github.com/CAMMA-public/PreViPS.
VidLPRO: A $\underline{Vid}$eo-$\underline{L}$anguage $\underline{P}$re-training Framework for $\underline{Ro}$botic and Laparoscopic Surgery
Sep 07, 2024We introduce VidLPRO, a novel video-language (VL) pre-training framework designed specifically for robotic and laparoscopic surgery. While existing surgical VL models primarily rely on contrastive learning, we propose a more comprehensive approach to capture the intricate temporal dynamics and align video with language. VidLPRO integrates video-text contrastive learning, video-text matching, and masked language modeling objectives to learn rich VL representations. To support this framework, we present GenSurg+, a carefully curated dataset derived from GenSurgery, comprising 17k surgical video clips paired with captions generated by GPT-4 using transcripts extracted by the Whisper model. This dataset addresses the need for large-scale, high-quality VL data in the surgical domain. Extensive experiments on benchmark datasets, including Cholec80 and AutoLaparo, demonstrate the efficacy of our approach. VidLPRO achieves state-of-the-art performance in zero-shot surgical phase recognition, significantly outperforming existing surgical VL models such as SurgVLP and HecVL. Our model demonstrates improvements of up to 21.5\% in accuracy and 15.7% in F1 score, setting a new benchmark in the field. Notably, VidLPRO exhibits robust performance even with single-frame inference, while effectively scaling with increased temporal context. Ablation studies reveal the impact of frame sampling strategies on model performance and computational efficiency. These results underscore VidLPRO's potential as a foundation model for surgical video understanding.
Curriculum learning based pre-training using Multi-Modal Contrastive Masked Autoencoders
Aug 05, 2024In this paper, we propose a new pre-training method for image understanding tasks under Curriculum Learning (CL) paradigm which leverages RGB-D. The method utilizes Multi-Modal Contrastive Masked Autoencoder and Denoising techniques. Recent approaches either use masked autoencoding (e.g., MultiMAE) or contrastive learning(e.g., Pri3D, or combine them in a single contrastive masked autoencoder architecture such as CMAE and CAV-MAE. However, none of the single contrastive masked autoencoder is applicable to RGB-D datasets. To improve the performance and efficacy of such methods, we propose a new pre-training strategy based on CL. Specifically, in the first stage, we pre-train the model using contrastive learning to learn cross-modal representations. In the second stage, we initialize the modality-specific encoders using the weights from the first stage and then pre-train the model using masked autoencoding and denoising/noise prediction used in diffusion models. Masked autoencoding focuses on reconstructing the missing patches in the input modality using local spatial correlations, while denoising learns high frequency components of the input data. Our approach is scalable, robust and suitable for pre-training with limited RGB-D datasets. Extensive experiments on multiple datasets such as ScanNet, NYUv2 and SUN RGB-D show the efficacy and superior performance of our approach. Specifically, we show an improvement of +1.0% mIoU against Mask3D on ScanNet semantic segmentation. We further demonstrate the effectiveness of our approach in low-data regime by evaluating it for semantic segmentation task against the state-of-the-art methods.
Rethinking RGB-D Fusion for Semantic Segmentation in Surgical Datasets
Jul 29, 2024



Surgical scene understanding is a key technical component for enabling intelligent and context aware systems that can transform various aspects of surgical interventions. In this work, we focus on the semantic segmentation task, propose a simple yet effective multi-modal (RGB and depth) training framework called SurgDepth, and show state-of-the-art (SOTA) results on all publicly available datasets applicable for this task. Unlike previous approaches, which either fine-tune SOTA segmentation models trained on natural images, or encode RGB or RGB-D information using RGB only pre-trained backbones, SurgDepth, which is built on top of Vision Transformers (ViTs), is designed to encode both RGB and depth information through a simple fusion mechanism. We conduct extensive experiments on benchmark datasets including EndoVis2022, AutoLapro, LapI2I and EndoVis2017 to verify the efficacy of SurgDepth. Specifically, SurgDepth achieves a new SOTA IoU of 0.86 on EndoVis 2022 SAR-RARP50 challenge and outperforms the current best method by at least 4%, using a shallow and compute efficient decoder consisting of ConvNeXt blocks.
ST(OR)2: Spatio-Temporal Object Level Reasoning for Activity Recognition in the Operating Room
Dec 19, 2023



Surgical robotics holds much promise for improving patient safety and clinician experience in the Operating Room (OR). However, it also comes with new challenges, requiring strong team coordination and effective OR management. Automatic detection of surgical activities is a key requirement for developing AI-based intelligent tools to tackle these challenges. The current state-of-the-art surgical activity recognition methods however operate on image-based representations and depend on large-scale labeled datasets whose collection is time-consuming and resource-expensive. This work proposes a new sample-efficient and object-based approach for surgical activity recognition in the OR. Our method focuses on the geometric arrangements between clinicians and surgical devices, thus utilizing the significant object interaction dynamics in the OR. We conduct experiments in a low-data regime study for long video activity recognition. We also benchmark our method againstother object-centric approaches on clip-level action classification and show superior performance.
M$^{3}$3D: Learning 3D priors using Multi-Modal Masked Autoencoders for 2D image and video understanding
Sep 26, 2023



We present a new pre-training strategy called M$^{3}$3D ($\underline{M}$ulti-$\underline{M}$odal $\underline{M}$asked $\underline{3D}$) built based on Multi-modal masked autoencoders that can leverage 3D priors and learned cross-modal representations in RGB-D data. We integrate two major self-supervised learning frameworks; Masked Image Modeling (MIM) and contrastive learning; aiming to effectively embed masked 3D priors and modality complementary features to enhance the correspondence between modalities. In contrast to recent approaches which are either focusing on specific downstream tasks or require multi-view correspondence, we show that our pre-training strategy is ubiquitous, enabling improved representation learning that can transfer into improved performance on various downstream tasks such as video action recognition, video action detection, 2D semantic segmentation and depth estimation. Experiments show that M$^{3}$3D outperforms the existing state-of-the-art approaches on ScanNet, NYUv2, UCF-101 and OR-AR, particularly with an improvement of +1.3\% mIoU against Mask3D on ScanNet semantic segmentation. We further evaluate our method on low-data regime and demonstrate its superior data efficiency compared to current state-of-the-art approaches.
SurgMAE: Masked Autoencoders for Long Surgical Video Analysis
May 19, 2023



There has been a growing interest in using deep learning models for processing long surgical videos, in order to automatically detect clinical/operational activities and extract metrics that can enable workflow efficiency tools and applications. However, training such models require vast amounts of labeled data which is costly and not scalable. Recently, self-supervised learning has been explored in computer vision community to reduce the burden of the annotation cost. Masked autoencoders (MAE) got the attention in self-supervised paradigm for Vision Transformers (ViTs) by predicting the randomly masked regions given the visible patches of an image or a video clip, and have shown superior performance on benchmark datasets. However, the application of MAE in surgical data remains unexplored. In this paper, we first investigate whether MAE can learn transferrable representations in surgical video domain. We propose SurgMAE, which is a novel architecture with a masking strategy based on sampling high spatio-temporal tokens for MAE. We provide an empirical study of SurgMAE on two large scale long surgical video datasets, and find that our method outperforms several baselines in low data regime. We conduct extensive ablation studies to show the efficacy of our approach and also demonstrate it's superior performance on UCF-101 to prove it's generalizability in non-surgical datasets as well.
Multi-Modal Unsupervised Pre-Training for Surgical Operating Room Workflow Analysis
Jul 16, 2022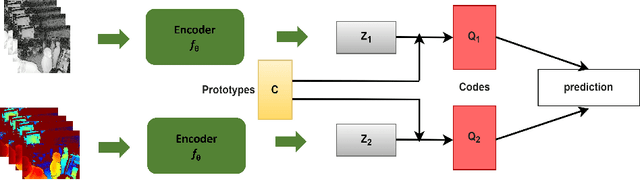
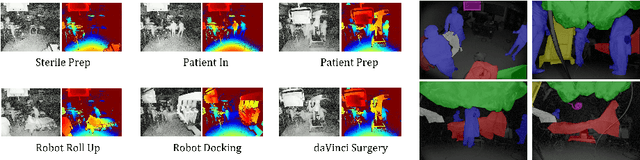

Data-driven approaches to assist operating room (OR) workflow analysis depend on large curated datasets that are time consuming and expensive to collect. On the other hand, we see a recent paradigm shift from supervised learning to self-supervised and/or unsupervised learning approaches that can learn representations from unlabeled datasets. In this paper, we leverage the unlabeled data captured in robotic surgery ORs and propose a novel way to fuse the multi-modal data for a single video frame or image. Instead of producing different augmentations (or 'views') of the same image or video frame which is a common practice in self-supervised learning, we treat the multi-modal data as different views to train the model in an unsupervised manner via clustering. We compared our method with other state of the art methods and results show the superior performance of our approach on surgical video activity recognition and semantic segmentation.
Rethinking Class-Balanced Methods for Long-Tailed Visual Recognition from a Domain Adaptation Perspective
Mar 24, 2020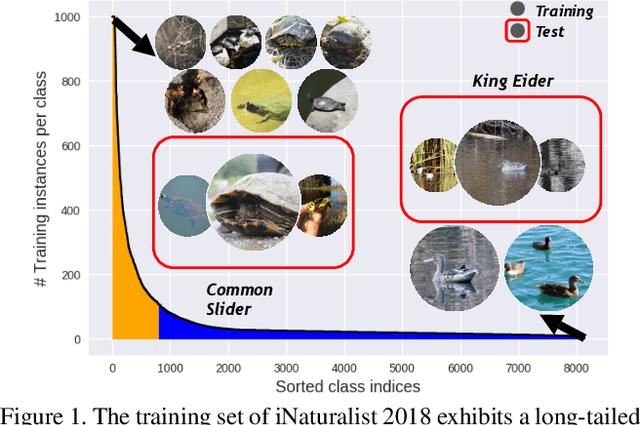


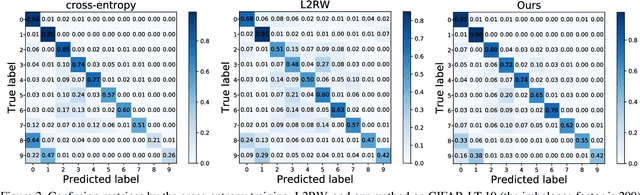
Object frequency in the real world often follows a power law, leading to a mismatch between datasets with long-tailed class distributions seen by a machine learning model and our expectation of the model to perform well on all classes. We analyze this mismatch from a domain adaptation point of view. First of all, we connect existing class-balanced methods for long-tailed classification to target shift, a well-studied scenario in domain adaptation. The connection reveals that these methods implicitly assume that the training data and test data share the same class-conditioned distribution, which does not hold in general and especially for the tail classes. While a head class could contain abundant and diverse training examples that well represent the expected data at inference time, the tail classes are often short of representative training data. To this end, we propose to augment the classic class-balanced learning by explicitly estimating the differences between the class-conditioned distributions with a meta-learning approach. We validate our approach with six benchmark datasets and three loss functions.