 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneous Semantic Transfer for Multi-label Recognition with Partial Labels
May 23, 2022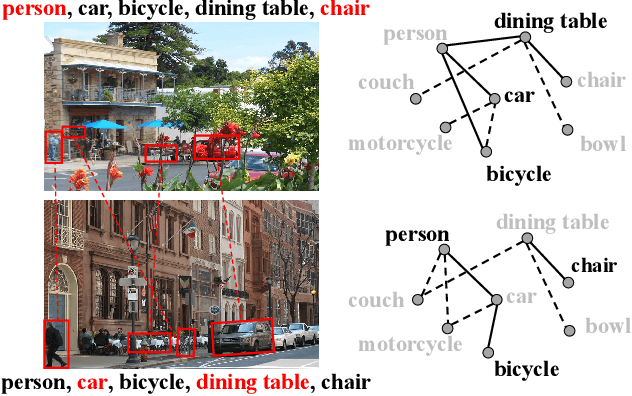
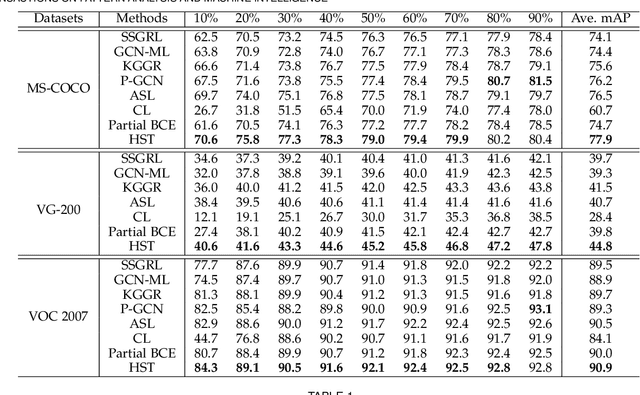

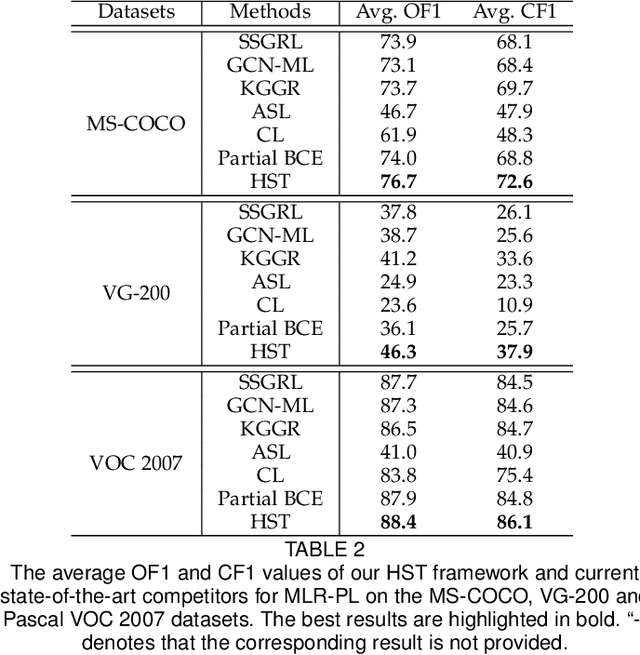
Multi-label image recognition with partial labels (MLR-PL), in which some labels are known while others are unknown for each image, may greatly reduce the cost of annotation and thus facilitate large-scale MLR. We find that strong semantic correlations exist within each image and across different images, and these correlations can help transfer the knowledge possessed by the known labels to retrieve the unknown labels and thus improve the performance of the MLR-PL task (see Figure 1). In this work, we propose a novel heterogeneous semantic transfer (HST) framework that consists of two complementary transfer modules that explore both within-image and cross-image semantic correlations to transfer the knowledge possessed by known labels to generate pseudo labels for the unknown labels. Specifically, an intra-image semantic transfer (IST) module learns an image-specific label co-occurrence matrix for each image and maps the known labels to complement the unknown labels based on these matrices. Additionally, a cross-image transfer (CST) module learns category-specific feature-prototype similarities and then helps complement the unknown labels that have high degrees of similarity with the corresponding prototypes. Finally, both the known and generated pseudo labels are used to train MLR models. Extensive experiments conducted on the Microsoft COCO, Visual Genome, and Pascal VOC 2007 datasets show that the proposed HST framework achieves superior performance to that of current state-of-the-art algorithms. Specifically, it obtains mean average precision (mAP) improvements of 1.4%, 3.3%, and 0.4% on the three datasets over the results of the best-performing previously developed algorithm.
TCGL: Temporal Contrastive Graph for Self-supervised Video Representation Learning
Jan 05, 2022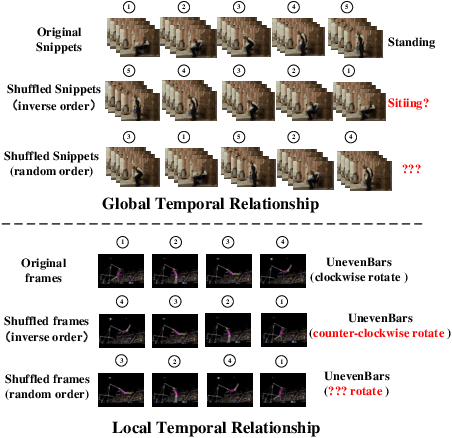
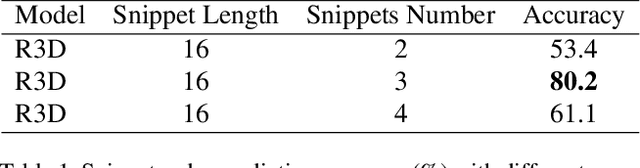
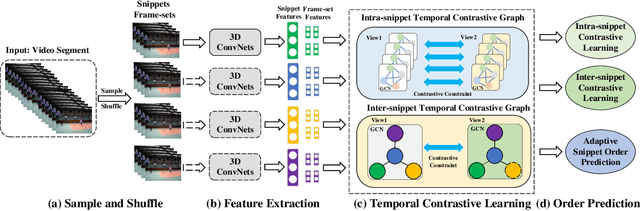

Video self-supervised learning is a challenging task, which requires significant expressive power from the model to leverage rich spatial-temporal knowledge and generate effective supervisory signals from large amounts of unlabeled videos. However, existing methods fail to increase the temporal diversity of unlabeled videos and ignore elaborately modeling multi-scale temporal dependencies in an explicit way. To overcome these limitations, we take advantage of the multi-scale temporal dependencies within videos and proposes a novel video self-supervised learning framework named Temporal Contrastive Graph Learning (TCGL), which jointly models the inter-snippet and intra-snippet temporal dependencies for temporal representation learning with a hybrid graph contrastive learning strategy. Specifically, a Spatial-Temporal Knowledge Discovering (STKD) module is first introduced to extract motion-enhanced spatial-temporal representations from videos based on the frequency domain analysis of discrete cosine transform. To explicitly model multi-scale temporal dependencies of unlabeled videos, our TCGL integrates the prior knowledge about the frame and snippet orders into graph structures, i.e., the intra-/inter- snippet Temporal Contrastive Graphs (TCG). Then, specific contrastive learning modules are designed to maximize the agreement between nodes in different graph views. To generate supervisory signals for unlabeled videos, we introduce an Adaptive Snippet Order Prediction (ASOP) module which leverages the relational knowledge among video snippets to learn the global context representation and recalibrate the channel-wise features adaptively. Experimental results demonstrate the superiority of our TCGL over the state-of-the-art methods on large-scale action recognition and video retrieval benchmarks.The code is publicly available at https://github.com/YangLiu9208/TCGL.
Unconstrained Face Sketch Synthesis via Perception-Adaptive Network and A New Benchmark
Dec 02, 2021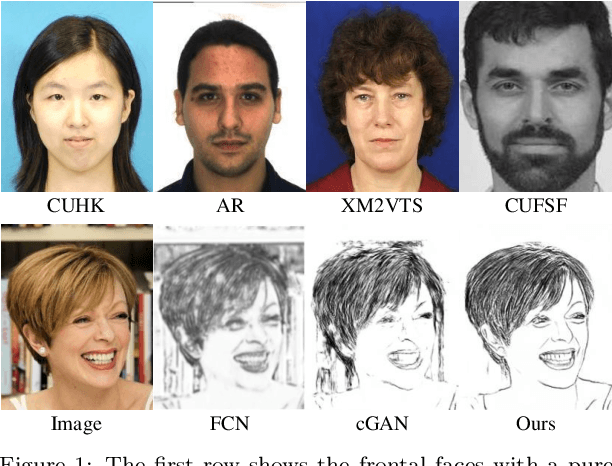
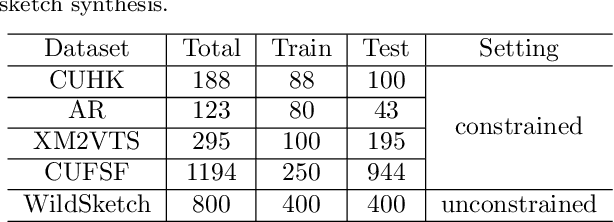

Face sketch generation has attracted much attention in the field of visual computing. However, existing methods either are limited to constrained conditions or heavily rely on various preprocessing steps to deal with in-the-wild cases. In this paper, we argue that accurately perceiving facial region and facial components is crucial for unconstrained sketch synthesis. To this end, we propose a novel Perception-Adaptive Network (PANet), which can generate high-quality face sketches under unconstrained conditions in an end-to-end scheme. Specifically, our PANet is composed of i) a Fully Convolutional Encoder for hierarchical feature extraction, ii) a Face-Adaptive Perceiving Decoder for extracting potential facial region and handling face variations, and iii) a Component-Adaptive Perceiving Module for facial component aware feature representation learning. To facilitate further researches of unconstrained face sketch synthesis, we introduce a new benchmark termed WildSketch, which contains 800 pairs of face photo-sketch with large variations in pose, expression, ethnic origin, background, and illumination. Extensive experiments demonstrate that the proposed method is capable of achieving state-of-the-art performance under both constrained and unconstrained conditions. Our source codes and the WildSketch benchmark are resealed on the project page http://lingboliu.com/unconstrained_face_sketch.html.
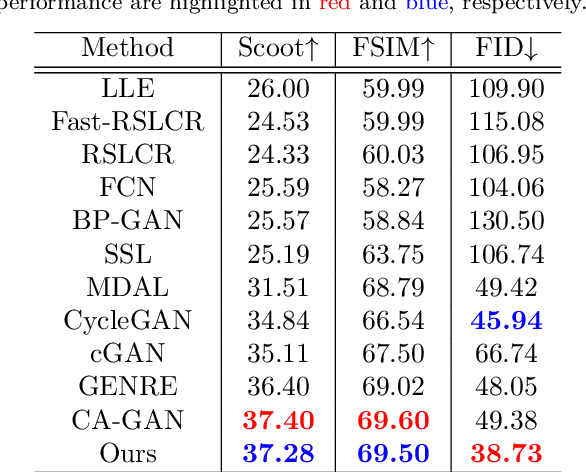
Aerial Images Meet Crowdsourced Trajectories: A New Approach to Robust Road Extraction
Nov 30, 2021
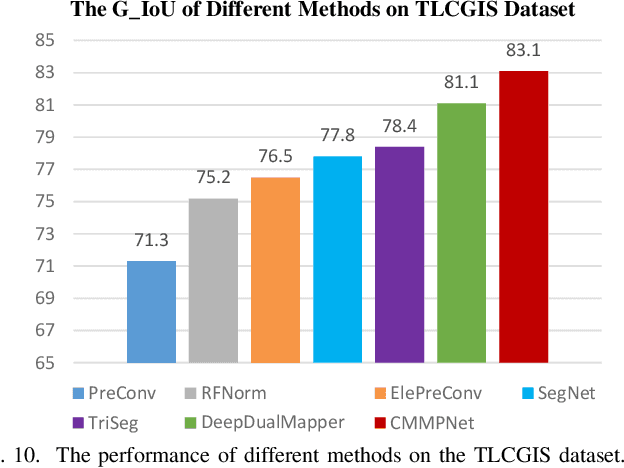
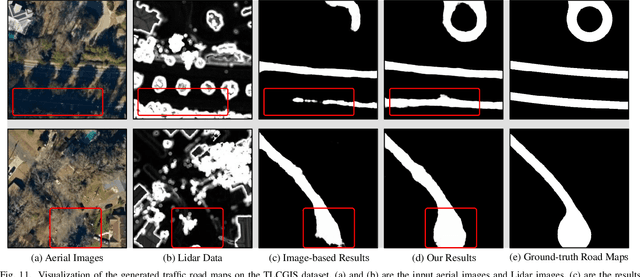
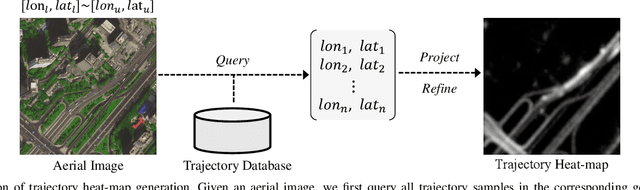
Land remote sensing analysis is a crucial research in earth science. In this work, we focus on a challenging task of land analysis, i.e., automatic extraction of traffic roads from remote sensing data, which has widespread applications in urban development and expansion estimation. Nevertheless, conventional methods either only utilized the limited information of aerial images, or simply fused multimodal information (e.g., vehicle trajectories), thus cannot well recognize unconstrained roads. To facilitate this problem, we introduce a novel neural network framework termed Cross-Modal Message Propagation Network (CMMPNet), which fully benefits the complementary different modal data (i.e., aerial images and crowdsourced trajectories). Specifically, CMMPNet is composed of two deep Auto-Encoders for modality-specific representation learning and a tailor-designed Dual Enhancement Module for cross-modal representation refinement. In particular, the complementary information of each modality is comprehensively extracted and dynamically propagated to enhance the representation of another modality. Extensive experiments on three real-world benchmarks demonstrate the effectiveness of our CMMPNet for robust road extraction benefiting from blending different modal data, either using image and trajectory data or image and Lidar data. From the experimental results, we observe that the proposed approach outperforms current state-of-the-art methods by large margins.
Road Network Guided Fine-Grained Urban Traffic Flow Inference
Sep 29, 2021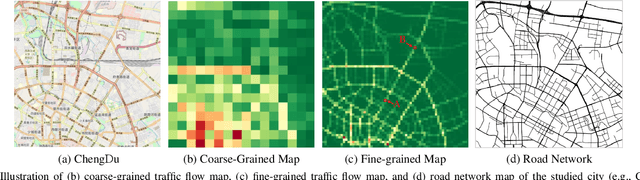
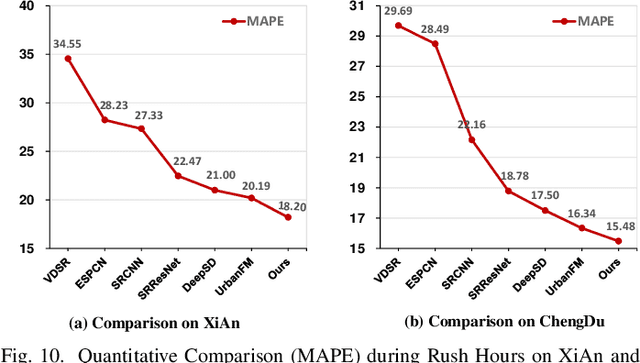
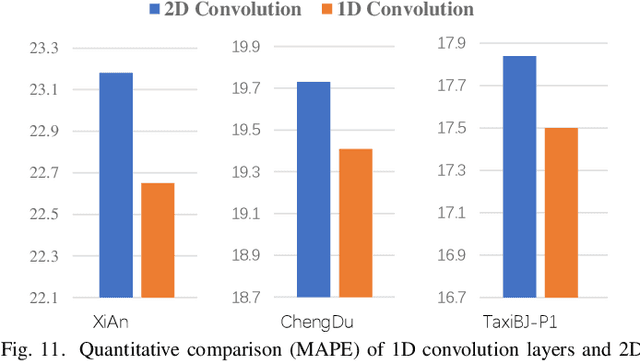
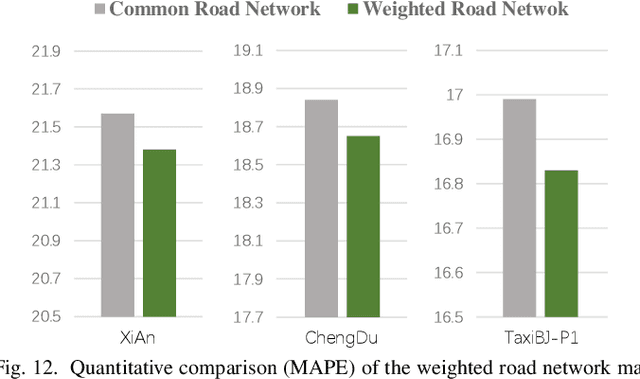
Accurate inference of fine-grained traffic flow from coarse-grained one is an emerging yet crucial problem, which can help greatly reduce the number of traffic monitoring sensors for cost savings. In this work, we notice that traffic flow has a high correlation with road network, which was either completely ignored or simply treated as an external factor in previous works. To facilitate this problem, we propose a novel Road-Aware Traffic Flow Magnifier (RATFM) that explicitly exploits the prior knowledge of road networks to fully learn the road-aware spatial distribution of fine-grained traffic flow. Specifically, a multi-directional 1D convolutional layer is first introduced to extract the semantic feature of the road network. Subsequently, we incorporate the road network feature and coarse-grained flow feature to regularize the short-range spatial distribution modeling of road-relative traffic flow. Furthermore, we take the road network feature as a query to capture the long-range spatial distribution of traffic flow with a transformer architecture. Benefiting from the road-aware inference mechanism, our method can generate high-quality fine-grained traffic flow maps. Extensive experiments on three real-world datasets show that the proposed RATFM outperforms state-of-the-art models under various scenarios.
GroupFormer: Group Activity Recognition with Clustered Spatial-Temporal Transformer
Aug 28, 2021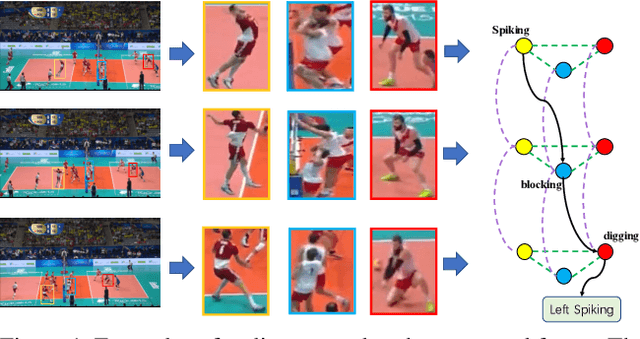
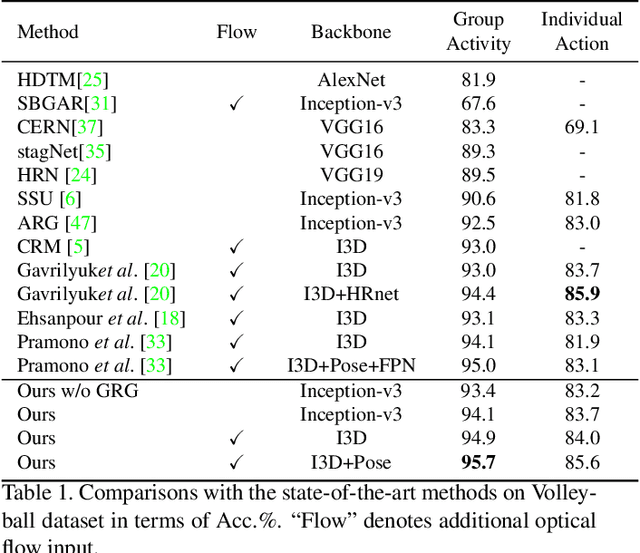
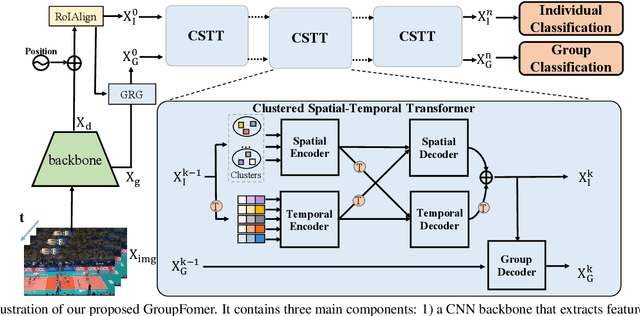
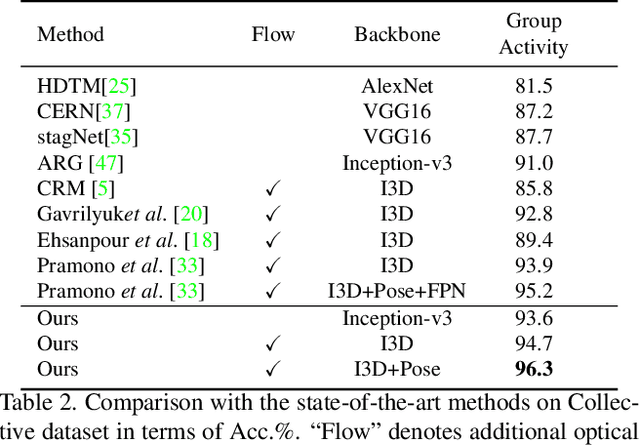
Group activity recognition is a crucial yet challenging problem, whose core lies in fully exploring spatial-temporal interactions among individuals and generating reasonable group representations. However, previous methods either model spatial and temporal information separately, or directly aggregate individual features to form group features. To address these issues, we propose a novel group activity recognition network termed GroupFormer. It captures spatial-temporal contextual information jointly to augment the individual and group representations effectively with a clustered spatial-temporal transformer. Specifically, our GroupFormer has three appealing advantages: (1) A tailor-modified Transformer, Clustered Spatial-Temporal Transformer, is proposed to enhance the individual representation and group representation. (2) It models the spatial and temporal dependencies integrally and utilizes decoders to build the bridge between the spatial and temporal information. (3) A clustered attention mechanism is utilized to dynamically divide individuals into multiple clusters for better learning activity-aware semantic representations. Moreover, experimental results show that the proposed framework outperforms state-of-the-art methods on the Volleyball dataset and Collective Activity dataset. Code is available at https://github.com/xueyee/GroupFormer.
Online Metro Origin-Destination Prediction via Heterogeneous Information Aggregation
Aug 02, 2021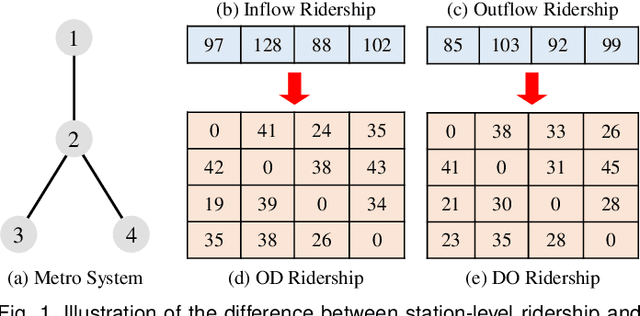
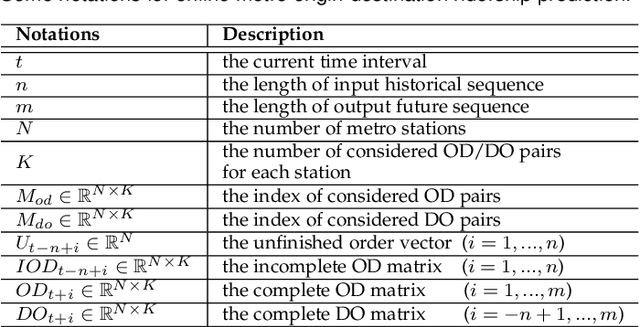
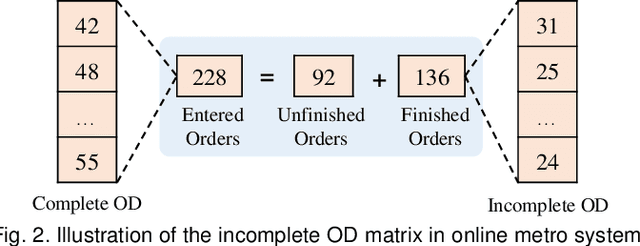
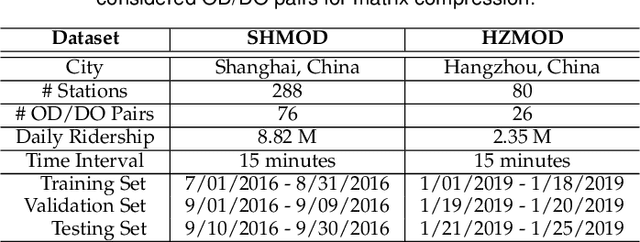
Metro origin-destination prediction is a crucial yet challenging time-series analysis task in intelligent transportation systems, which aims to accurately forecast two specific types of cross-station ridership, i.e., Origin-Destination (OD) one and Destination-Origin (DO) one. However, complete OD matrices of previous time intervals can not be obtained immediately in online metro systems, and conventional methods only used limited information to forecast the future OD and DO ridership separately. In this work, we proposed a novel neural network module termed Heterogeneous Information Aggregation Machine (HIAM), which fully exploits heterogeneous information of historical data (e.g., incomplete OD matrices, unfinished order vectors, and DO matrices) to jointly learn the evolutionary patterns of OD and DO ridership. Specifically, an OD modeling branch estimates the potential destinations of unfinished orders explicitly to complement the information of incomplete OD matrices, while a DO modeling branch takes DO matrices as input to capture the spatial-temporal distribution of DO ridership. Moreover, a Dual Information Transformer is introduced to propagate the mutual information among OD features and DO features for modeling the OD-DO causality and correlation. Based on the proposed HIAM, we develop a unified Seq2Seq network to forecast the future OD and DO ridership simultaneously. Extensive experiments conducted on two large-scale benchmarks demonstrate the effectiveness of our method for online metro origin-destination prediction.
Video Crowd Localization with Multi-focus Gaussian Neighbor Attention and a Large-Scale Benchmark
Jul 20, 2021
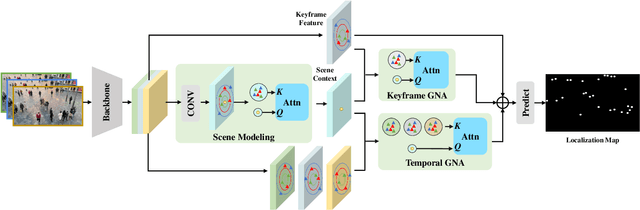

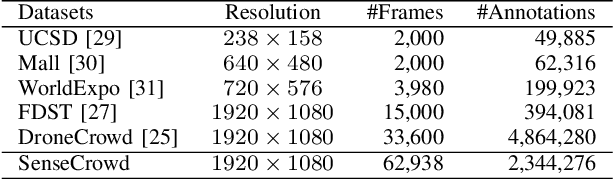
Video crowd localization is a crucial yet challenging task, which aims to estimate exact locations of human heads in the given crowded videos. To model spatial-temporal dependencies of human mobility, we propose a multi-focus Gaussian neighbor attention (GNA), which can effectively exploit long-range correspondences while maintaining the spatial topological structure of the input videos. In particular, our GNA can also capture the scale variation of human heads well using the equipped multi-focus mechanism. Based on the multi-focus GNA, we develop a unified neural network called GNANet to accurately locate head centers in video clips by fully aggregating spatial-temporal information via a scene modeling module and a context cross-attention module. Moreover, to facilitate future researches in this field, we introduce a large-scale crowded video benchmark named SenseCrowd, which consists of 60K+ frames captured in various surveillance scenarios and 2M+ head annotations. Finally, we conduct extensive experiments on three datasets including our SenseCrowd, and the experiment results show that the proposed method is capable to achieve state-of-the-art performance for both video crowd localization and counting. The code and the dataset will be released.
GeoQA: A Geometric Question Answering Benchmark Towards Multimodal Numerical Reasoning
Jun 08, 2021
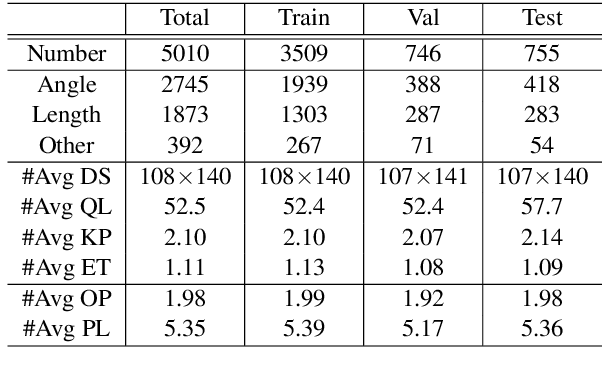

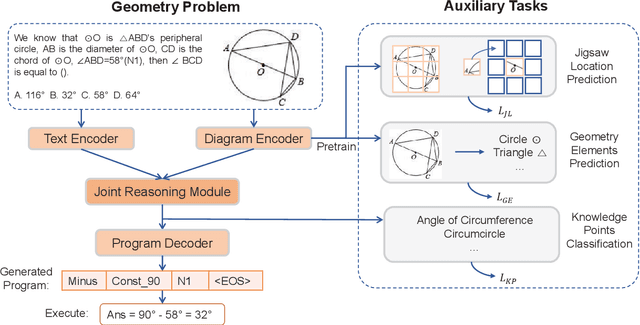
Automatic math problem solving has recently attracted increasing attention as a long-standing AI benchmark. In this paper, we focus on solving geometric problems, which requires a comprehensive understanding of textual descriptions, visual diagrams, and theorem knowledge. However, the existing methods were highly dependent on handcraft rules and were merely evaluated on small-scale datasets. Therefore, we propose a Geometric Question Answering dataset GeoQA, containing 5,010 geometric problems with corresponding annotated programs, which illustrate the solving process of the given problems. Compared with another publicly available dataset GeoS, GeoQA is 25 times larger, in which the program annotations can provide a practical testbed for future research on explicit and explainable numerical reasoning. Moreover, we introduce a Neural Geometric Solver (NGS) to address geometric problems by comprehensively parsing multimodal information and generating interpretable programs. We further add multiple self-supervised auxiliary tasks on NGS to enhance cross-modal semantic representation. Extensive experiments on GeoQA validate the effectiveness of our proposed NGS and auxiliary tasks. However, the results are still significantly lower than human performance, which leaves large room for future research. Our benchmark and code are released at https://github.com/chen-judge/GeoQA .
Cross-Modal Collaborative Representation Learning and a Large-Scale RGBT Benchmark for Crowd Counting
Dec 08, 2020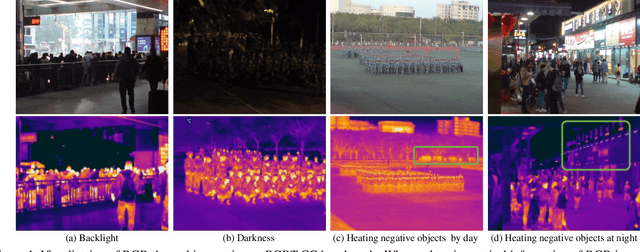
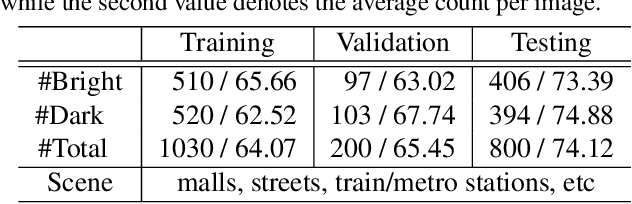
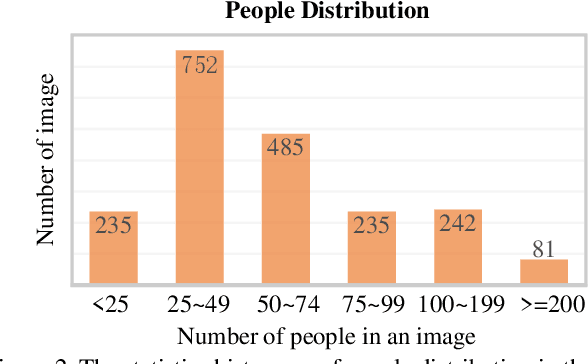
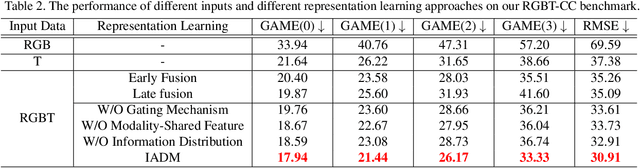
Crowd counting is a fundamental yet challenging problem, which desires rich information to generate pixel-wise crowd density maps. However, most previous methods only utilized the limited information of RGB images and may fail to discover the potential pedestrians in unconstrained environments. In this work, we find that incorporating optical and thermal information can greatly help to recognize pedestrians. To promote future researches in this field, we introduce a large-scale RGBT Crowd Counting (RGBT-CC) benchmark, which contains 2,030 pairs of RGB-thermal images with 138,389 annotated people. Furthermore, to facilitate the multimodal crowd counting, we propose a cross-modal collaborative representation learning framework, which consists of multiple modality-specific branches, a modality-shared branch, and an Information Aggregation-Distribution Module (IADM) to fully capture the complementary information of different modalities. Specifically, our IADM incorporates two collaborative information transfer components to dynamically enhance the modality-shared and modality-specific representations with a dual information propagation mechanism. Extensive experiments conducted on the RGBT-CC benchmark demonstrate the effectiveness of our framework for RGBT crowd counting. Moreover, the proposed approach is universal for multimodal crowd counting and is also capable to achieve superior performance on the ShanghaiTechRGBD dataset.