 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResNet-LDDMM: Advancing the LDDMM Framework Using Deep Residual Networks
Feb 16, 2021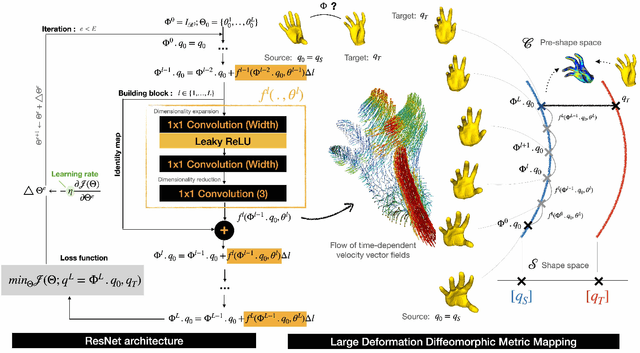

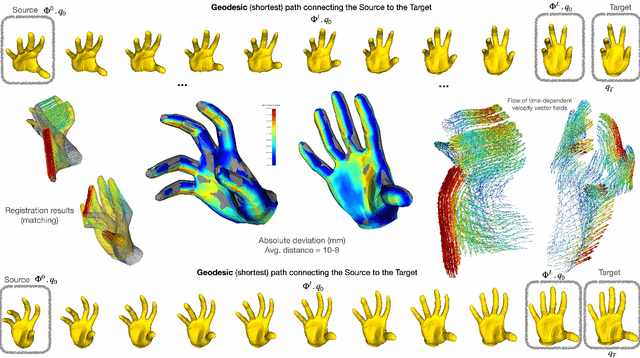
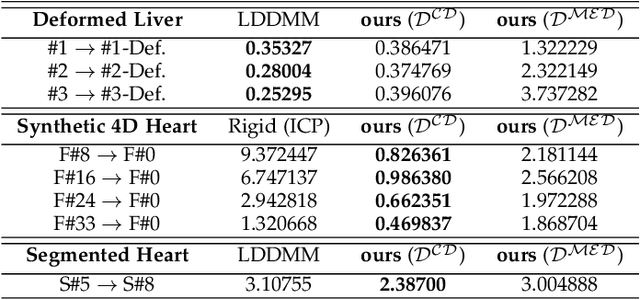
In deformable registration, the geometric framework - large deformation diffeomorphic metric mapping or LDDMM, in short - has inspired numerous techniques for comparing, deforming, averaging and analyzing shapes or images. Grounded in flows, which are akin to the equations of motion used in fluid dynamics, LDDMM algorithms solve the flow equation in the space of plausible deformations, i.e. diffeomorphisms. In this work, we make use of deep residual neural networks to solve the non-stationary ODE (flow equation) based on a Euler's discretization scheme. The central idea is to represent time-dependent velocity fields as fully connected ReLU neural networks (building blocks) and derive optimal weights by minimizing a regularized loss function. Computing minimizing paths between deformations, thus between shapes, turns to find optimal network parameters by back-propagating over the intermediate building blocks. Geometrically, at each time step, ResNet-LDDMM searches for an optimal partition of the space into multiple polytopes, and then computes optimal velocity vectors as affine transformations on each of these polytopes. As a result, different parts of the shape, even if they are close (such as two fingers of a hand), can be made to belong to different polytopes, and therefore be moved in different directions without costing too much energy. Importantly, we show how diffeomorphic transformations, or more precisely bilipshitz transformations, are predicted by our algorithm. We illustrate these ideas on diverse registration problems of 3D shapes under complex topology-preserving transformations. We thus provide essential foundations for more advanced shape variability analysis under a novel joint geometric-neural networks Riemannian-like framework, i.e. ResNet-LDDMM.
Multi-Stage Progressive Image Restoration
Feb 04, 2021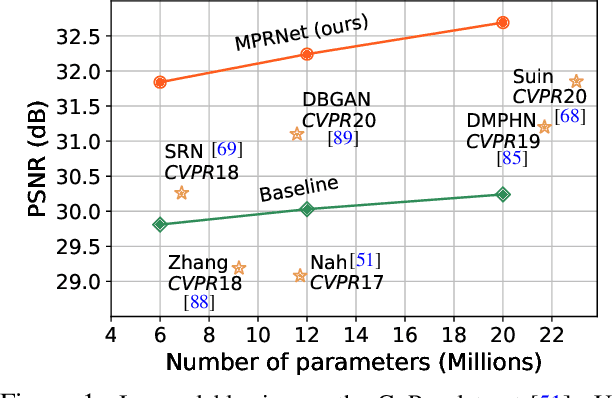

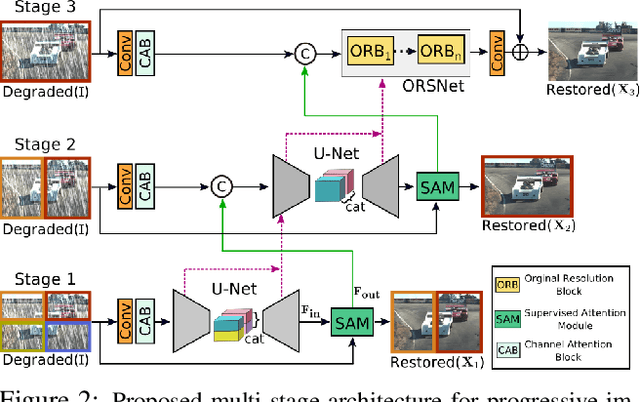
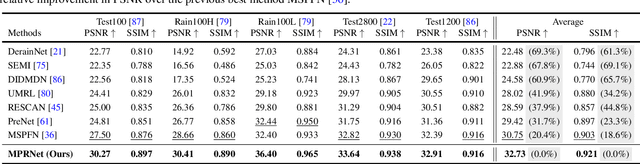
Image restoration tasks demand a complex balance between spatial details and high-level contextualized information while recovering images. In this paper, we propose a novel synergistic design that can optimally balance these competing goals. Our main proposal is a multi-stage architecture, that progressively learns restoration functions for the degraded inputs, thereby breaking down the overall recovery process into more manageable steps. Specifically, our model first learns the contextualized features using encoder-decoder architectures and later combines them with a high-resolution branch that retains local information. At each stage, we introduce a novel per-pixel adaptive design that leverages in-situ supervised attention to reweight the local features. A key ingredient in such a multi-stage architecture is the information exchange between different stages. To this end, we propose a two-faceted approach where the information is not only exchanged sequentially from early to late stages, but lateral connections between feature processing blocks also exist to avoid any loss of information. The resulting tightly interlinked multi-stage architecture, named as MPRNet, delivers strong performance gains on ten datasets across a range of tasks including image deraining, deblurring, and denoising. For example, on the Rain100L, GoPro and DND datasets, we obtain PSNR gains of 4 dB, 0.81 dB and 0.21 dB, respectively, compared to the state-of-the-art. The source code and pre-trained models are available at https://github.com/swz30/MPRNet.
Generative Multi-Label Zero-Shot Learning
Jan 28, 2021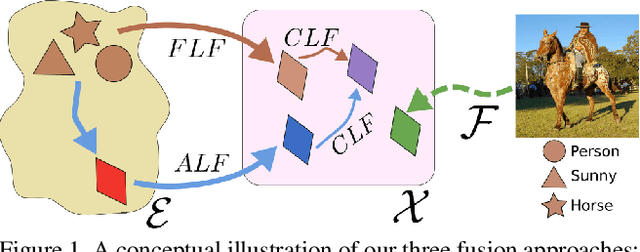
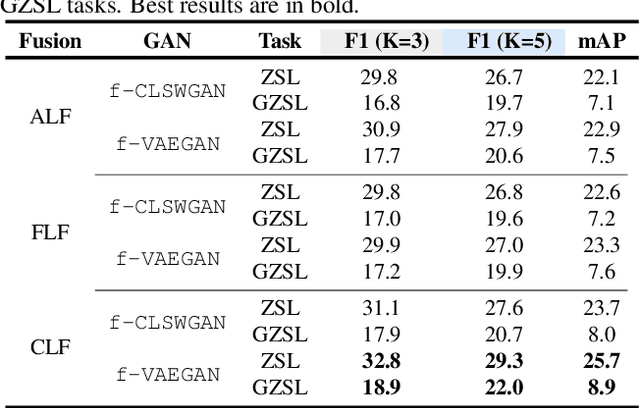
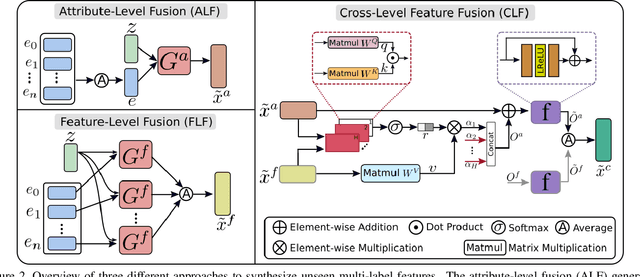
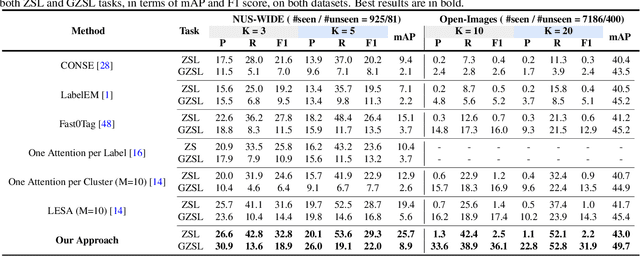
Multi-label zero-shot learning strives to classify images into multiple unseen categories for which no data is available during training. The test samples can additionally contain seen categories in the generalized variant. Existing approaches rely on learning either shared or label-specific attention from the seen classes. Nevertheless, computing reliable attention maps for unseen classes during inference in a multi-label setting is still a challenge. In contrast, state-of-the-art single-label generative adversarial network (GAN) based approaches learn to directly synthesize the class-specific visual features from the corresponding class attribute embeddings. However, synthesizing multi-label features from GANs is still unexplored in the context of zero-shot setting. In this work, we introduce different fusion approaches at the attribute-level, feature-level and cross-level (across attribute and feature-levels) for synthesizing multi-label features from their corresponding multi-label class embedding. To the best of our knowledge, our work is the first to tackle the problem of multi-label feature synthesis in the (generalized) zero-shot setting. Comprehensive experiments are performed on three zero-shot image classification benchmarks: NUS-WIDE, Open Images and MS COCO. Our cross-level fusion-based generative approach outperforms the state-of-the-art on all three datasets. Furthermore, we show the generalization capabilities of our fusion approach in the zero-shot detection task on MS COCO, achieving favorable performance against existing methods. The source code is available at https://github.com/akshitac8/Generative_MLZSL.
Boundary-Aware Segmentation Network for Mobile and Web Applications
Jan 12, 2021
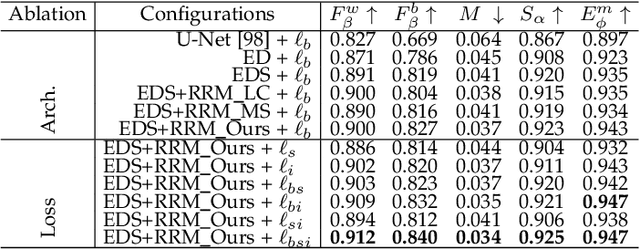
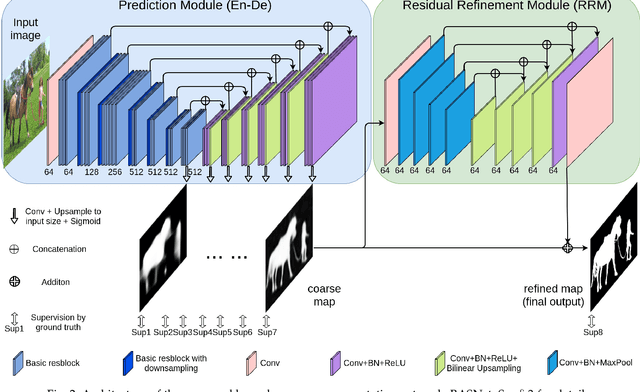
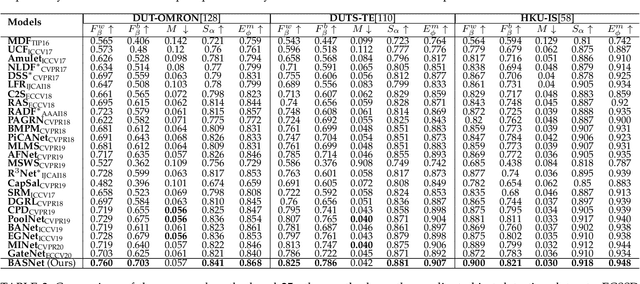
Although deep models have greatly improved the accuracy and robustness of image segmentation, obtaining segmentation results with highly accurate boundaries and fine structures is still a challenging problem. In this paper, we propose a simple yet powerful Boundary-Aware Segmentation Network (BASNet), which comprises a predict-refine architecture and a hybrid loss, for highly accurate image segmentation. The predict-refine architecture consists of a densely supervised encoder-decoder network and a residual refinement module, which are respectively used to predict and refine a segmentation probability map. The hybrid loss is a combination of the binary cross entropy, structural similarity and intersection-over-union losses, which guide the network to learn three-level (ie, pixel-, patch- and map- level) hierarchy representations. We evaluate our BASNet on two reverse tasks including salient object segmentation, camouflaged object segmentation, showing that it achieves very competitive performance with sharp segmentation boundaries. Importantly, BASNet runs at over 70 fps on a single GPU which benefits many potential real applications. Based on BASNet, we further developed two (close to) commercial applications: AR COPY & PASTE, in which BASNet is integrated with augmented reality for "COPYING" and "PASTING" real-world objects, and OBJECT CUT, which is a web-based tool for automatic object background removal. Both applications have already drawn huge amount of attention and have important real-world impacts. The code and two applications will be publicly available at: https://github.com/NathanUA/BASNet.
Low Light Image Enhancement via Global and Local Context Modeling
Jan 04, 2021
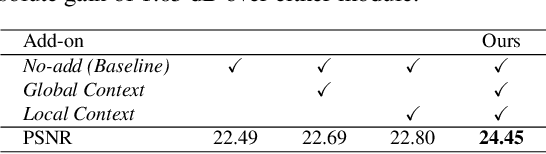
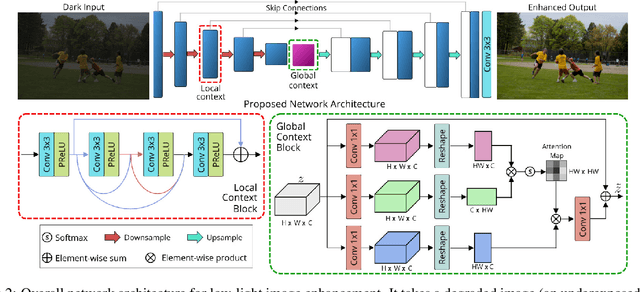

Images captured under low-light conditions manifest poor visibility, lack contrast and color vividness. Compared to conventional approaches, deep convolutional neural networks (CNNs) perform well in enhancing images. However, being solely reliant on confined fixed primitives to model dependencies, existing data-driven deep models do not exploit the contexts at various spatial scales to address low-light image enhancement. These contexts can be crucial towards inferring several image enhancement tasks, e.g., local and global contrast, brightness and color corrections; which requires cues from both local and global spatial extent. To this end, we introduce a context-aware deep network for low-light image enhancement. First, it features a global context module that models spatial correlations to find complementary cues over full spatial domain. Second, it introduces a dense residual block that captures local context with a relatively large receptive field. We evaluate the proposed approach using three challenging datasets: MIT-Adobe FiveK, LoL, and SID. On all these datasets, our method performs favorably against the state-of-the-arts in terms of standard image fidelity metrics. In particular, compared to the best performing method on the MIT-Adobe FiveK dataset, our algorithm improves PSNR from 23.04 dB to 24.45 dB.
D2-Net: Weakly-Supervised Action Localization via Discriminative Embeddings and Denoised Activations
Dec 11, 2020
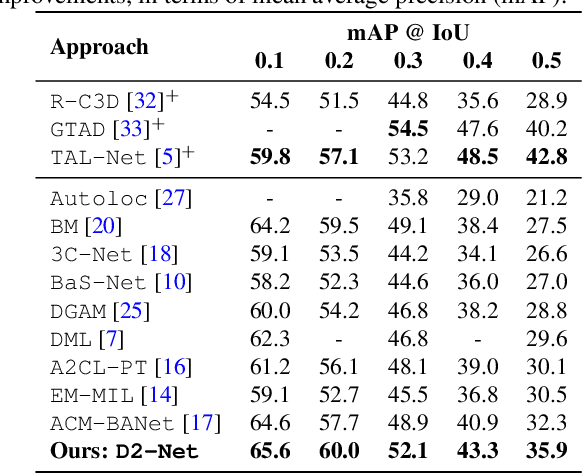
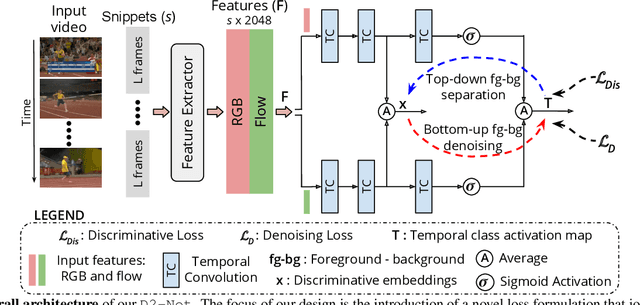
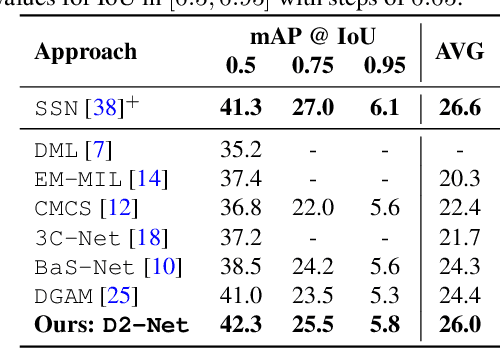
This work proposes a weakly-supervised temporal action localization framework, called D2-Net, which strives to temporally localize actions using video-level supervision. Our main contribution is the introduction of a novel loss formulation, which jointly enhances the discriminability of latent embeddings and robustness of the output temporal class activations with respect to foreground-background noise caused by weak supervision. The proposed formulation comprises a discriminative and a denoising loss term for enhancing temporal action localization. The discriminative term incorporates a classification loss and utilizes a top-down attention mechanism to enhance the separability of latent foreground-background embeddings. The denoising loss term explicitly addresses the foreground-background noise in class activations by simultaneously maximizing intra-video and inter-video mutual information using a bottom-up attention mechanism. As a result, activations in the foreground regions are emphasized whereas those in the background regions are suppressed, thereby leading to more robust predictions. Comprehensive experiments are performed on two benchmarks: THUMOS14 and ActivityNet1.2. Our D2-Net performs favorably in comparison to the existing methods on both datasets, achieving gains as high as 3.6% in terms of mean average precision on THUMOS14.
Learning to Fuse Asymmetric Feature Maps in Siamese Trackers
Dec 04, 2020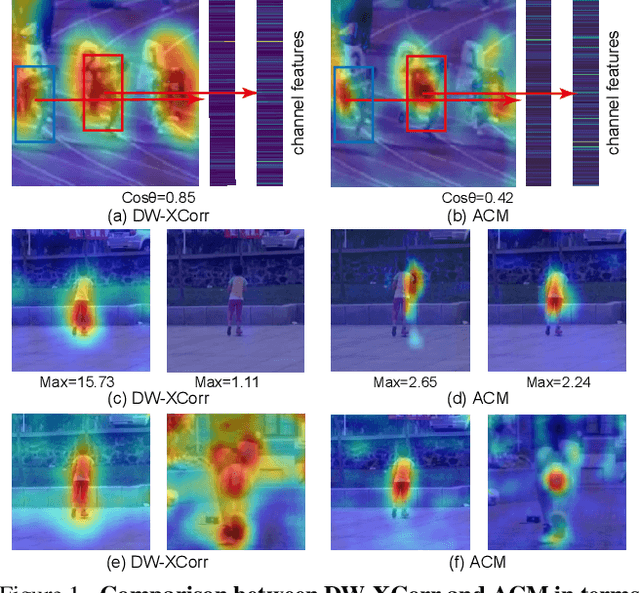
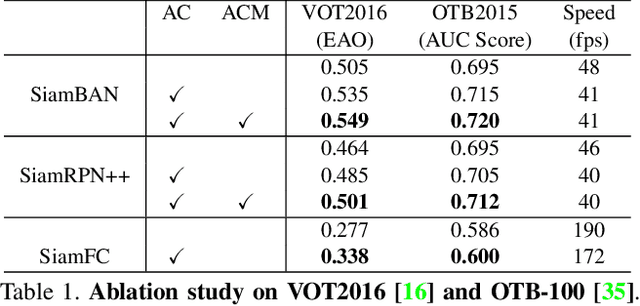
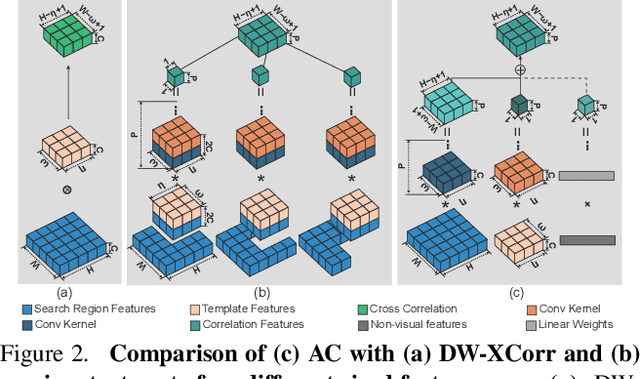
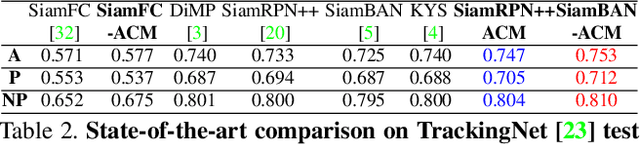
In recent years, Siamese-based trackers have achieved promising performance in visual tracking. Most recent Siamese-based trackers typically employ a depth-wise cross-correlation (DW-XCorr) to obtain multi-channel correlation information from the two feature maps (target and search region). However, DW-XCorr has several limitations within Siamese-based tracking: it can easily be fooled by distractors, has fewer activated channels, and provides weak discrimination of object boundaries. Further, DW-XCorr is a handcrafted parameter-free module and cannot fully benefit from offline learning on large-scale data. We propose a learnable module, called the asymmetric convolution (ACM), which learns to better capture the semantic correlation information in offline training on large-scale data. Different from DW-XCorr and its predecessor (XCorr), which regard a single feature map as the convolution kernel, our ACM decomposes the convolution operation on a concatenated feature map into two mathematically equivalent operations, thereby avoiding the need for the feature maps to be of the same size (width and height) during concatenation. Our ACM can incorporate useful prior information, such as bounding-box size, with standard visual features. Furthermore, ACM can easily be integrated into existing Siamese trackers based on DW-XCorr or XCorr. To demonstrate its generalization ability, we integrate ACM into three representative trackers: SiamFC, SiamRPN++, and SiamBAN. Our experiments reveal the benefits of the proposed ACM, which outperforms existing methods on six tracking benchmarks. On the LaSOT test set, our ACM-based tracker obtains a significant improvement of 5.8% in terms of success (AUC), over the baseline.
DomainMix: Learning Generalizable Person Re-Identification Without Human Annotations
Nov 24, 2020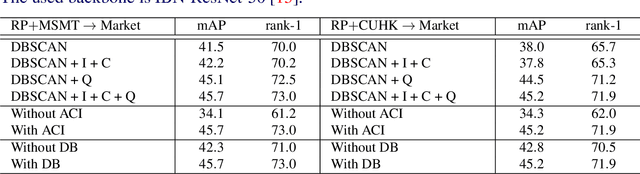
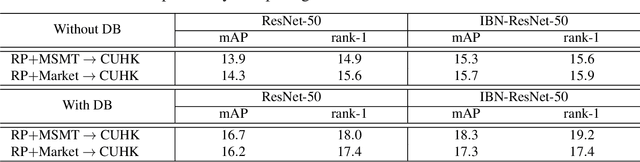

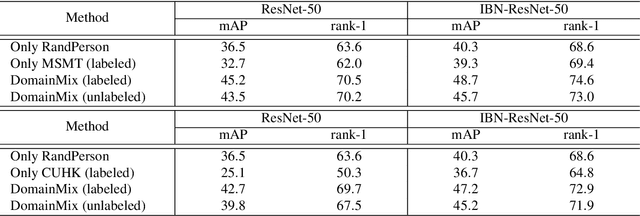
Existing person re-identification methods often have low generalization capability, which is mostly due to the limited availability of large-scale labeled training data. However, labeling large-scale training data is very expensive and time-consuming. To address this, this paper presents a solution, called DomainMix, which can learn a person re-identification model from both synthetic and real-world data, for the first time, completely without human annotations. This way, the proposed method enjoys the cheap availability of large-scale training data, and benefiting from its scalability and diversity, the learned model is able to generalize well on unseen domains. Specifically, inspired from a recent work generating large-scale synthetic data for effective person re-identification training, the proposed method firstly applies unsupervised domain adaptation from labeled synthetic data to unlabeled real-world data to generate pseudo labels. Then, the two sources of data are directly mixed together for supervised training. However, a large domain gap still exists between them. To address this, a domain-invariant feature learning method is proposed, which designs an adversarial learning between domain-invariant feature learning and domain discrimination, and meanwhile learns a discriminant feature for person re-identification. This way, the domain gap between synthetic and real-world data is much reduced, and the learned feature is generalizable thanks to the large-scale and diverse training data. Experimental results show that the proposed annotation-free method is more or less comparable to the counterpart trained with full human annotations, which is quite promising. In addition, it achieves the current state of the art on several popular person re-identification datasets under direct cross-dataset evaluation.
Learning Efficient GANs using Differentiable Masks and co-Attention Distillation
Nov 21, 2020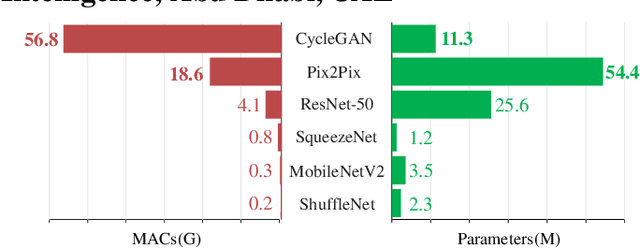
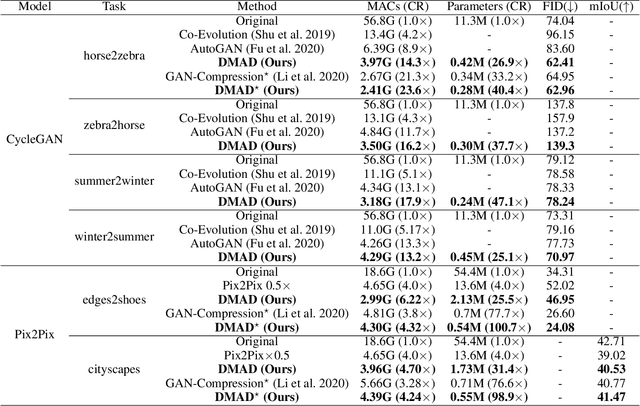
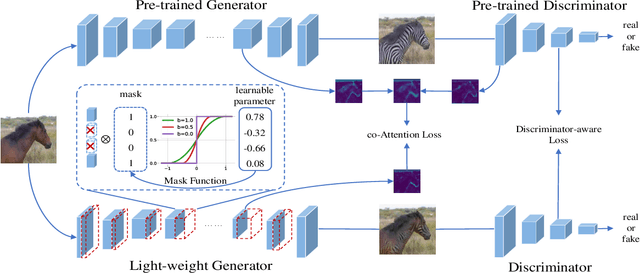
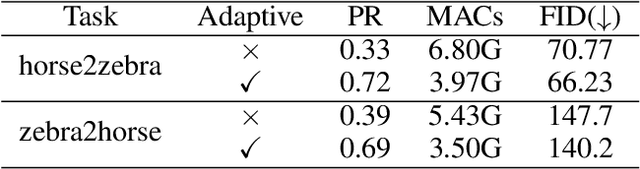
Generative Adversarial Networks (GANs) have been widely-used in image translation, but their high computational and storage costs impede the deployment on mobile devices. Prevalent methods for CNN compression cannot be directly applied to GANs due to the complicated generator architecture and the unstable adversarial training. To solve these, in this paper, we introduce a novel GAN compression method, termed DMAD, by proposing a Differentiable Mask and a co-Attention Distillation. The former searches for a light-weight generator architecture in a training-adaptive manner. To overcome channel inconsistency when pruning the residual connections, an adaptive cross-block group sparsity is further incorporated. The latter simultaneously distills informative attention maps from both the generator and discriminator of a pre-trained model to the searched generator, effectively stabilizing the adversarial training of our light-weight model. Experiments show that DMAD can reduce the Multiply Accumulate Operations (MACs) of CycleGAN by 13x and that of Pix2Pix by 4x while retaining a comparable performance against the full model. Code is available at https://github.com/SJLeo/DMAD.
Invariant Deep Compressible Covariance Pooling for Aerial Scene Categorization
Nov 11, 2020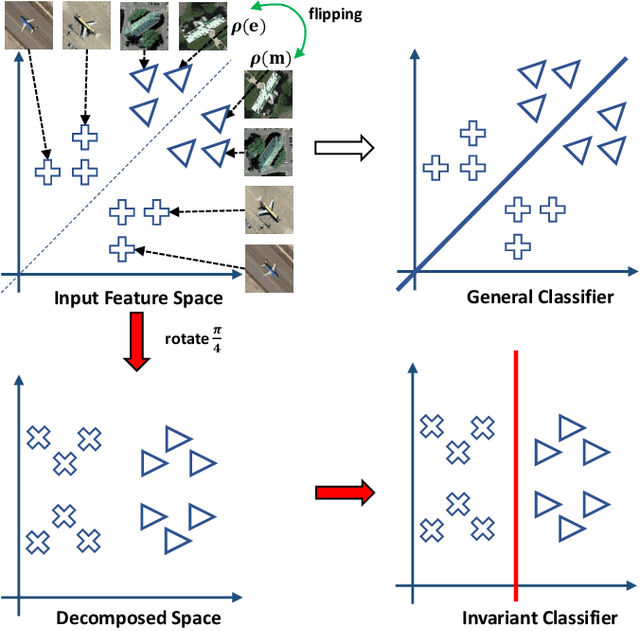
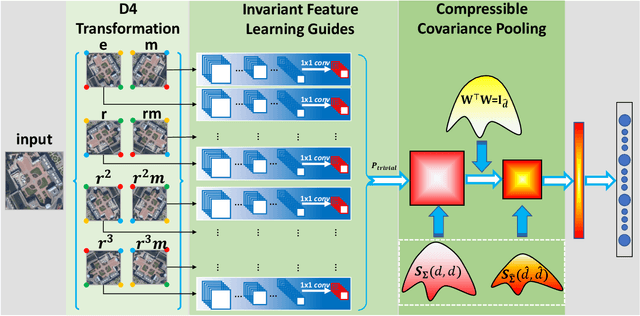
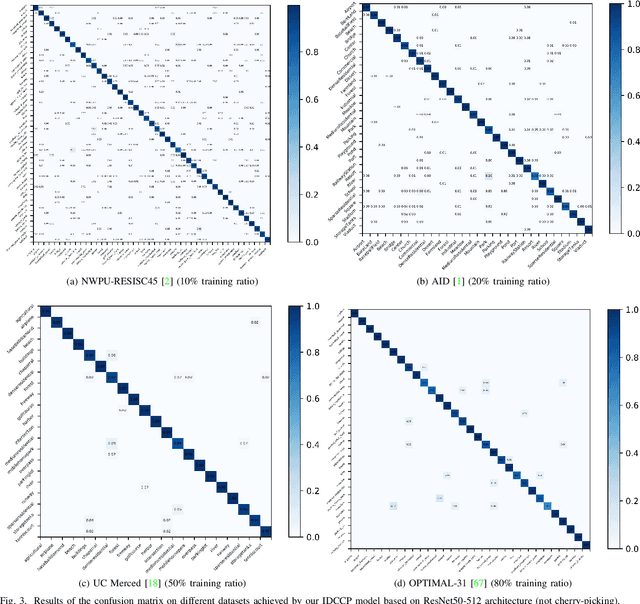
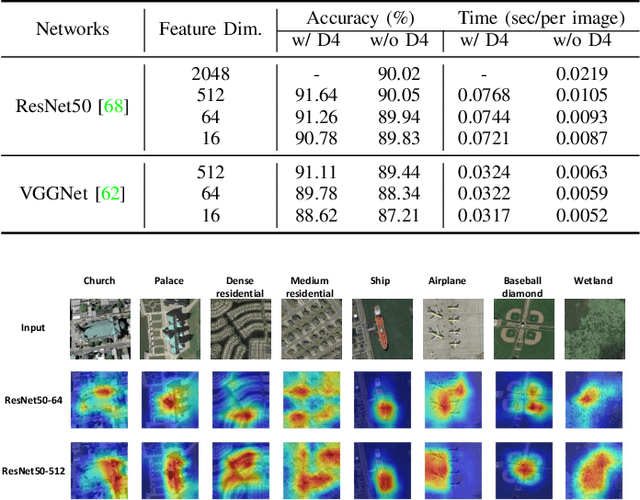
Learning discriminative and invariant feature representation is the key to visual image categorization. In this article, we propose a novel invariant deep compressible covariance pooling (IDCCP) to solve nuisance variations in aerial scene categorization. We consider transforming the input image according to a finite transformation group that consists of multiple confounding orthogonal matrices, such as the D4 group. Then, we adopt a Siamese-style network to transfer the group structure to the representation space, where we can derive a trivial representation that is invariant under the group action. The linear classifier trained with trivial representation will also be possessed with invariance. To further improve the discriminative power of representation, we extend the representation to the tensor space while imposing orthogonal constraints on the transformation matrix to effectively reduce feature dimensions. We conduct extensive experiments on the publicly released aerial scene image data sets and demonstrate the superiority of this method compared with state-of-the-art methods. In particular, with using ResNet architecture, our IDCCP model can reduce the dimension of the tensor representation by about 98% without sacrificing accuracy (i.e., <0.5%).