 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGloss-Free End-to-End Sign Language Translation
May 22, 2023



In this paper, we tackle the problem of sign language translation (SLT) without gloss annotations. Although intermediate representation like gloss has been proven effective, gloss annotations are hard to acquire, especially in large quantities. This limits the domain coverage of translation datasets, thus handicapping real-world applications. To mitigate this problem, we design the Gloss-Free End-to-end sign language translation framework (GloFE). Our method improves the performance of SLT in the gloss-free setting by exploiting the shared underlying semantics of signs and the corresponding spoken translation. Common concepts are extracted from the text and used as a weak form of intermediate representation. The global embedding of these concepts is used as a query for cross-attention to find the corresponding information within the learned visual features. In a contrastive manner, we encourage the similarity of query results between samples containing such concepts and decrease those that do not. We obtained state-of-the-art results on large-scale datasets, including OpenASL and How2Sign. The code and model will be available at https://github.com/HenryLittle/GloFE.
Efficient Multimodal Fusion via Interactive Prompting
Apr 13, 2023Large-scale pre-training has brought unimodal fields such as computer vision and natural language processing to a new era. Following this trend, the size of multi-modal learning models constantly increases, leading to an urgent need to reduce the massive computational cost of finetuning these models for downstream tasks. In this paper, we propose an efficient and flexible multimodal fusion method, namely PMF, tailored for fusing unimodally pre-trained transformers. Specifically, we first present a modular multimodal fusion framework that exhibits high flexibility and facilitates mutual interactions among different modalities. In addition, we disentangle vanilla prompts into three types in order to learn different optimizing objectives for multimodal learning. It is also worth noting that we propose to add prompt vectors only on the deep layers of the unimodal transformers, thus significantly reducing the training memory usage. Experiment results show that our proposed method achieves comparable performance to several other multimodal finetuning methods with less than 3% trainable parameters and up to 66% saving of training memory usage.
DeCap: Decoding CLIP Latents for Zero-Shot Captioning via Text-Only Training
Mar 06, 2023



Large-scale pre-trained multi-modal models (e.g., CLIP) demonstrate strong zero-shot transfer capability in many discriminative tasks. Their adaptation to zero-shot image-conditioned text generation tasks has drawn increasing interest. Prior arts approach to zero-shot captioning by either utilizing the existing large language models (e.g., GPT-2) or pre-training the encoder-decoder network in an end-to-end manner. In this work, we propose a simple framework, named DeCap, for zero-shot captioning. We introduce a lightweight visual-aware language decoder. This decoder is both data-efficient and computation-efficient: 1) it only requires the text data for training, easing the burden on the collection of paired data. 2) it does not require end-to-end training. When trained with text-only data, the decoder takes the text embedding extracted from the off-the-shelf CLIP encoder as a prefix embedding. The challenge is that the decoder is trained on the text corpus but at the inference stage, it needs to generate captions based on visual inputs. The modality gap issue is widely observed in multi-modal contrastive models that prevents us from directly taking the visual embedding as the prefix embedding. We propose a training-free mechanism to reduce the modality gap. We project the visual embedding into the CLIP text embedding space, while the projected embedding retains the information of the visual input. Taking the projected embedding as the prefix embedding, the decoder generates high-quality descriptions that match the visual input. The experiments show that DeCap outperforms other zero-shot captioning methods and unpaired captioning methods on the typical image captioning benchmarks, i.e., MSCOCO and NoCaps.
Variational Cross-Graph Reasoning and Adaptive Structured Semantics Learning for Compositional Temporal Grounding
Jan 22, 2023Temporal grounding is the task of locating a specific segment from an untrimmed video according to a query sentence. This task has achieved significant momentum in the computer vision community as it enables activity grounding beyond pre-defined activity classes by utilizing the semantic diversity of natural language descriptions. The semantic diversity is rooted in the principle of compositionality in linguistics, where novel semantics can be systematically described by combining known words in novel ways (compositional generalization). However, existing temporal grounding datasets are not carefully designed to evaluate the compositional generalizability. To systematically benchmark the compositional generalizability of temporal grounding models, we introduce a new Compositional Temporal Grounding task and construct two new dataset splits, i.e., Charades-CG and ActivityNet-CG. When evaluating the state-of-the-art methods on our new dataset splits, we empirically find that they fail to generalize to queries with novel combinations of seen words. We argue that the inherent structured semantics inside the videos and language is the crucial factor to achieve compositional generalization. Based on this insight, we propose a variational cross-graph reasoning framework that explicitly decomposes video and language into hierarchical semantic graphs, respectively, and learns fine-grained semantic correspondence between the two graphs. Furthermore, we introduce a novel adaptive structured semantics learning approach to derive the structure-informed and domain-generalizable graph representations, which facilitate the fine-grained semantic correspondence reasoning between the two graphs. Extensive experiments validate the superior compositional generalizability of our approach.
Temporal Perceiving Video-Language Pre-training
Jan 18, 2023Video-Language Pre-training models have recently significantly improved various multi-modal downstream tasks. Previous dominant works mainly adopt contrastive learning to achieve global feature alignment across modalities. However, the local associations between videos and texts are not modeled, restricting the pre-training models' generality, especially for tasks requiring the temporal video boundary for certain query texts. This work introduces a novel text-video localization pre-text task to enable fine-grained temporal and semantic alignment such that the trained model can accurately perceive temporal boundaries in videos given the text description. Specifically, text-video localization consists of moment retrieval, which predicts start and end boundaries in videos given the text description, and text localization which matches the subset of texts with the video features. To produce temporal boundaries, frame features in several videos are manually merged into a long video sequence that interacts with a text sequence. With the localization task, our method connects the fine-grained frame representations with the word representations and implicitly distinguishes representations of different instances in the single modality. Notably, comprehensive experimental results show that our method significantly improves the state-of-the-art performance on various benchmarks, covering text-to-video retrieval, video question answering, video captioning, temporal action localization and temporal moment retrieval. The code will be released soon.
Discriminative Radial Domain Adaptation
Jan 01, 2023



Domain adaptation methods reduce domain shift typically by learning domain-invariant features. Most existing methods are built on distribution matching, e.g., adversarial domain adaptation, which tends to corrupt feature discriminability. In this paper, we propose Discriminative Radial Domain Adaptation (DRDR) which bridges source and target domains via a shared radial structure. It's motivated by the observation that as the model is trained to be progressively discriminative, features of different categories expand outwards in different directions, forming a radial structure. We show that transferring such an inherently discriminative structure would enable to enhance feature transferability and discriminability simultaneously. Specifically, we represent each domain with a global anchor and each category a local anchor to form a radial structure and reduce domain shift via structure matching. It consists of two parts, namely isometric transformation to align the structure globally and local refinement to match each category. To enhance the discriminability of the structure, we further encourage samples to cluster close to the corresponding local anchors based on optimal-transport assignment. Extensively experimenting on multiple benchmarks, our method is shown to consistently outperforms state-of-the-art approaches on varied tasks, including the typical unsupervised domain adaptation, multi-source domain adaptation, domain-agnostic learning, and domain generalization.
MIST: Multi-modal Iterative Spatial-Temporal Transformer for Long-form Video Question Answering
Dec 19, 2022To build Video Question Answering (VideoQA) systems capable of assisting humans in daily activities, seeking answers from long-form videos with diverse and complex events is a must. Existing multi-modal VQA models achieve promising performance on images or short video clips, especially with the recent success of large-scale multi-modal pre-training. However, when extending these methods to long-form videos, new challenges arise. On the one hand, using a dense video sampling strategy is computationally prohibitive. On the other hand, methods relying on sparse sampling struggle in scenarios where multi-event and multi-granularity visual reasoning are required. In this work, we introduce a new model named Multi-modal Iterative Spatial-temporal Transformer (MIST) to better adapt pre-trained models for long-form VideoQA. Specifically, MIST decomposes traditional dense spatial-temporal self-attention into cascaded segment and region selection modules that adaptively select frames and image regions that are closely relevant to the question itself. Visual concepts at different granularities are then processed efficiently through an attention module. In addition, MIST iteratively conducts selection and attention over multiple layers to support reasoning over multiple events. The experimental results on four VideoQA datasets, including AGQA, NExT-QA, STAR, and Env-QA, show that MIST achieves state-of-the-art performance and is superior at computation efficiency and interpretability.
Slimmable Networks for Contrastive Self-supervised Learning
Sep 30, 2022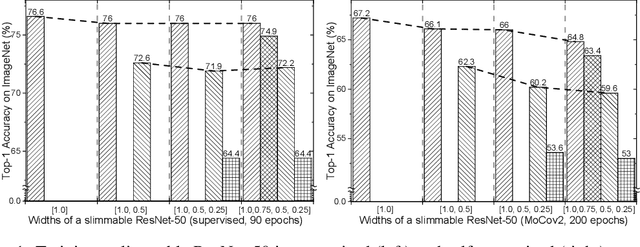
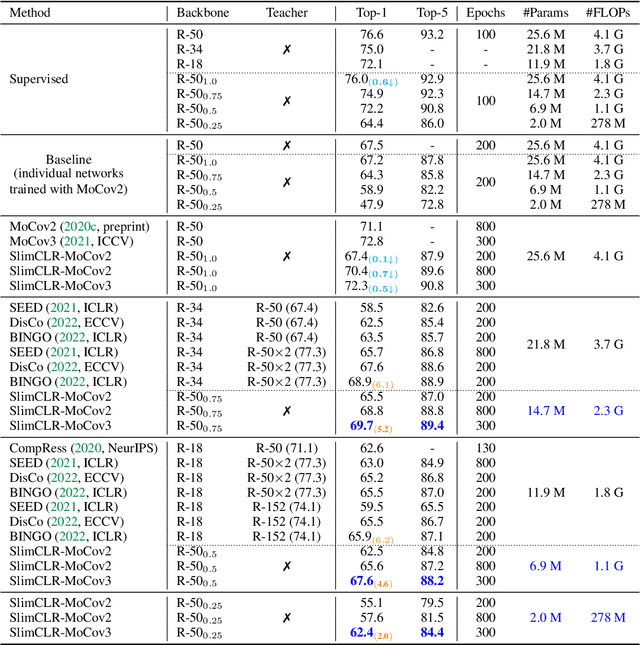
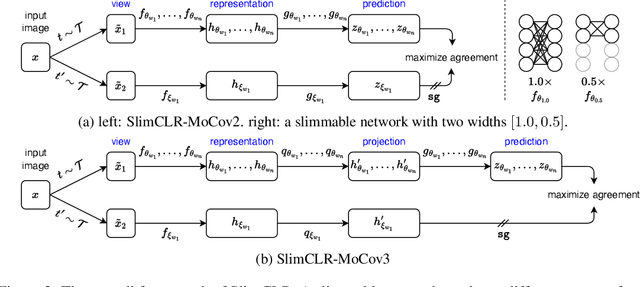
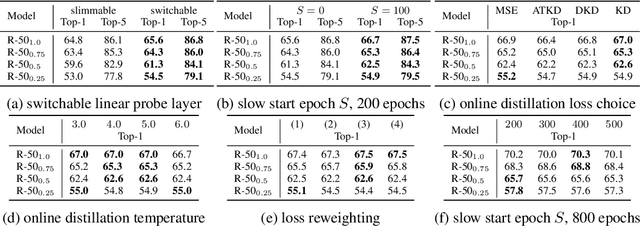
Self-supervised learning makes great progress in large model pre-training but suffers in training small models. Previous solutions to this problem mainly rely on knowledge distillation and indeed have a two-stage learning procedure: first train a large teacher model, then distill it to improve the generalization ability of small ones. In this work, we present a new one-stage solution to obtain pre-trained small models without extra teachers: slimmable networks for contrastive self-supervised learning (\emph{SlimCLR}). A slimmable network contains a full network and several weight-sharing sub-networks. We can pre-train for only one time and obtain various networks including small ones with low computation costs. However, in self-supervised cases, the interference between weight-sharing networks leads to severe performance degradation. One evidence of the interference is \emph{gradient imbalance}: a small proportion of parameters produces dominant gradients during backpropagation, and the main parameters may not be fully optimized. The divergence in gradient directions of various networks may also cause interference between networks. To overcome these problems, we make the main parameters produce dominant gradients and provide consistent guidance for sub-networks via three techniques: slow start training of sub-networks, online distillation, and loss re-weighting according to model sizes. Besides, a switchable linear probe layer is applied during linear evaluation to avoid the interference of weight-sharing linear layers. We instantiate SlimCLR with typical contrastive learning frameworks and achieve better performance than previous arts with fewer parameters and FLOPs.
AFE-CNN: 3D Skeleton-based Action Recognition with Action Feature Enhancement
Aug 06, 2022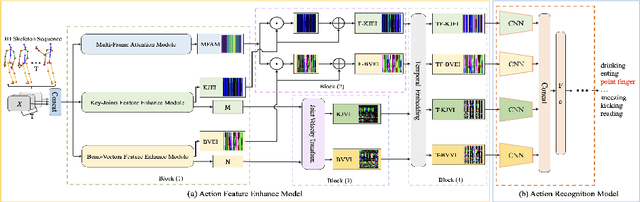
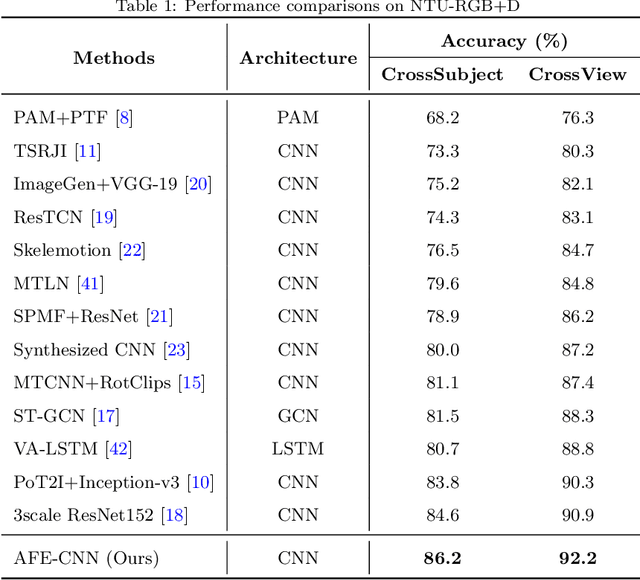
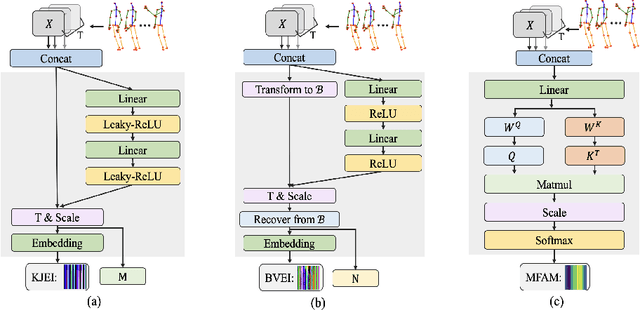
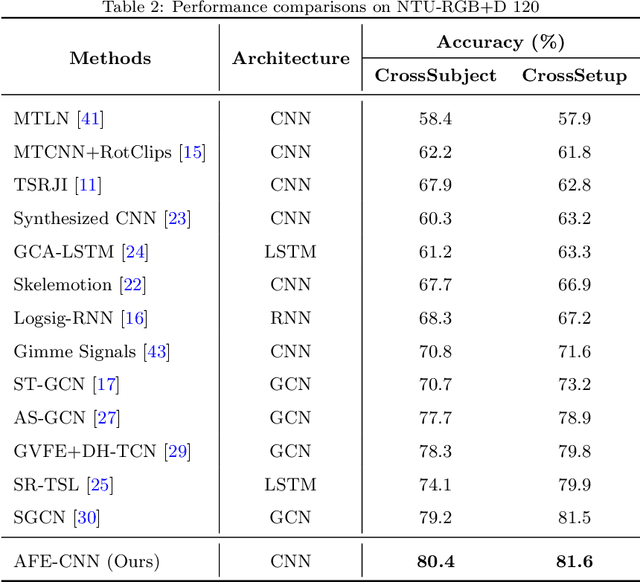
Existing 3D skeleton-based action recognition approaches reach impressive performance by encoding handcrafted action features to image format and decoding by CNNs. However, such methods are limited in two ways: a) the handcrafted action features are difficult to handle challenging actions, and b) they generally require complex CNN models to improve action recognition accuracy, which usually occur heavy computational burden. To overcome these limitations, we introduce a novel AFE-CNN, which devotes to enhance the features of 3D skeleton-based actions to adapt to challenging actions. We propose feature enhance modules from key joint, bone vector, key frame and temporal perspectives, thus the AFE-CNN is more robust to camera views and body sizes variation, and significantly improve the recognition accuracy on challenging actions. Moreover, our AFE-CNN adopts a light-weight CNN model to decode images with action feature enhanced, which ensures a much lower computational burden than the state-of-the-art methods. We evaluate the AFE-CNN on three benchmark skeleton-based action datasets: NTU RGB+D, NTU RGB+D 120, and UTKinect-Action3D, with extensive experimental results demonstrate our outstanding performance of AFE-CNN.
Fine-Grained Semantically Aligned Vision-Language Pre-Training
Aug 04, 2022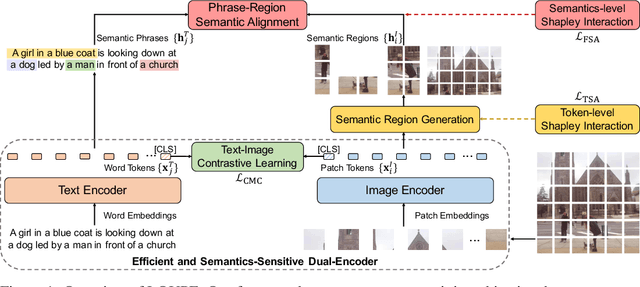
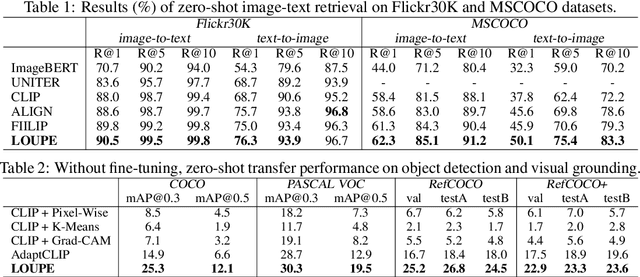
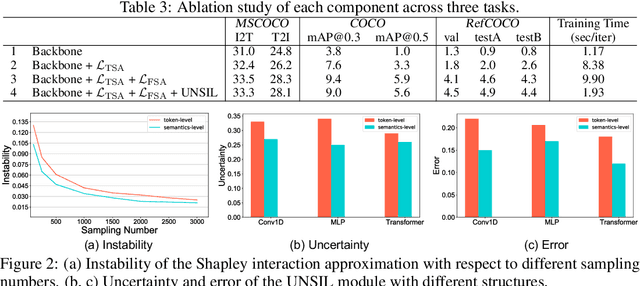

Large-scale vision-language pre-training has shown impressive advances in a wide range of downstream tasks. Existing methods mainly model the cross-modal alignment by the similarity of the global representations of images and texts, or advanced cross-modal attention upon image and text features. However, they fail to explicitly learn the fine-grained semantic alignment between visual regions and textual phrases, as only global image-text alignment information is available. In this paper, we introduce LOUPE, a fine-grained semantically aLigned visiOn-langUage PrE-training framework, which learns fine-grained semantic alignment from the novel perspective of game-theoretic interactions. To efficiently compute the game-theoretic interactions, we further propose an uncertainty-aware neural Shapley interaction learning module. Experiments show that LOUPE achieves state-of-the-art on image-text retrieval benchmarks. Without any object-level human annotations and fine-tuning, LOUPE achieves competitive performance on object detection and visual grounding. More importantly, LOUPE opens a new promising direction of learning fine-grained semantics from large-scale raw image-text pairs.