 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneHGN: Hierarchical Graph Networks for 3D Indoor Scene Generation with Fine-Grained Geometry
Feb 16, 2023



3D indoor scenes are widely used in computer graphics, with applications ranging from interior design to gaming to virtual and augmented reality. They also contain rich information, including room layout, as well as furniture type, geometry, and placement. High-quality 3D indoor scenes are highly demanded while it requires expertise and is time-consuming to design high-quality 3D indoor scenes manually. Existing research only addresses partial problems: some works learn to generate room layout, and other works focus on generating detailed structure and geometry of individual furniture objects. However, these partial steps are related and should be addressed together for optimal synthesis. We propose SCENEHGN, a hierarchical graph network for 3D indoor scenes that takes into account the full hierarchy from the room level to the object level, then finally to the object part level. Therefore for the first time, our method is able to directly generate plausible 3D room content, including furniture objects with fine-grained geometry, and their layout. To address the challenge, we introduce functional regions as intermediate proxies between the room and object levels to make learning more manageable. To ensure plausibility, our graph-based representation incorporates both vertical edges connecting child nodes with parent nodes from different levels, and horizontal edges encoding relationships between nodes at the same level. Extensive experiments demonstrate that our method produces superior generation results, even when comparing results of partial steps with alternative methods that can only achieve these. We also demonstrate that our method is effective for various applications such as part-level room editing, room interpolation, and room generation by arbitrary room boundaries.
NeRFFaceEditing: Disentangled Face Editing in Neural Radiance Fields
Nov 15, 2022



Recent methods for synthesizing 3D-aware face images have achieved rapid development thanks to neural radiance fields, allowing for high quality and fast inference speed. However, existing solutions for editing facial geometry and appearance independently usually require retraining and are not optimized for the recent work of generation, thus tending to lag behind the generation process. To address these issues, we introduce NeRFFaceEditing, which enables editing and decoupling geometry and appearance in the pretrained tri-plane-based neural radiance field while retaining its high quality and fast inference speed. Our key idea for disentanglement is to use the statistics of the tri-plane to represent the high-level appearance of its corresponding facial volume. Moreover, we leverage a generated 3D-continuous semantic mask as an intermediary for geometry editing. We devise a geometry decoder (whose output is unchanged when the appearance changes) and an appearance decoder. The geometry decoder aligns the original facial volume with the semantic mask volume. We also enhance the disentanglement by explicitly regularizing rendered images with the same appearance but different geometry to be similar in terms of color distribution for each facial component separately. Our method allows users to edit via semantic masks with decoupled control of geometry and appearance. Both qualitative and quantitative evaluations show the superior geometry and appearance control abilities of our method compared to existing and alternative solutions.
StylizedNeRF: Consistent 3D Scene Stylization as Stylized NeRF via 2D-3D Mutual Learning
May 25, 2022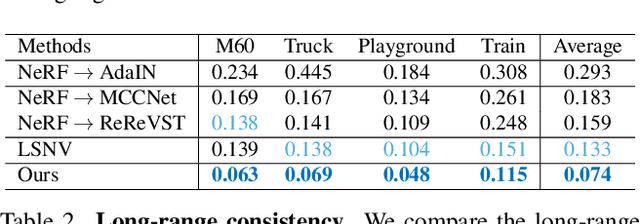

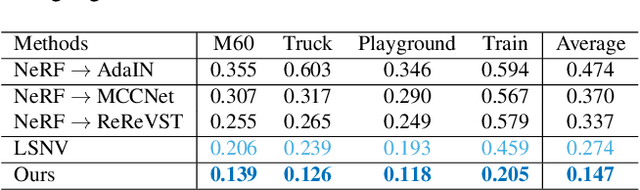
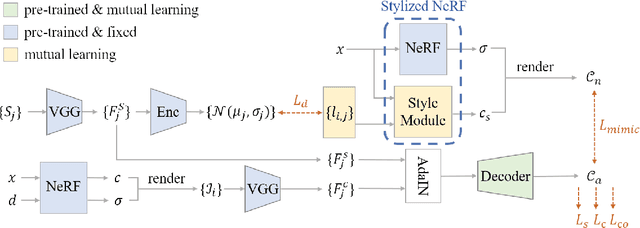
3D scene stylization aims at generating stylized images of the scene from arbitrary novel views following a given set of style examples, while ensuring consistency when rendered from different views. Directly applying methods for image or video stylization to 3D scenes cannot achieve such consistency. Thanks to recently proposed neural radiance fields (NeRF), we are able to represent a 3D scene in a consistent way. Consistent 3D scene stylization can be effectively achieved by stylizing the corresponding NeRF. However, there is a significant domain gap between style examples which are 2D images and NeRF which is an implicit volumetric representation. To address this problem, we propose a novel mutual learning framework for 3D scene stylization that combines a 2D image stylization network and NeRF to fuse the stylization ability of 2D stylization network with the 3D consistency of NeRF. We first pre-train a standard NeRF of the 3D scene to be stylized and replace its color prediction module with a style network to obtain a stylized NeRF. It is followed by distilling the prior knowledge of spatial consistency from NeRF to the 2D stylization network through an introduced consistency loss. We also introduce a mimic loss to supervise the mutual learning of the NeRF style module and fine-tune the 2D stylization decoder. In order to further make our model handle ambiguities of 2D stylization results, we introduce learnable latent codes that obey the probability distributions conditioned on the style. They are attached to training samples as conditional inputs to better learn the style module in our novel stylized NeRF. Experimental results demonstrate that our method is superior to existing approaches in both visual quality and long-range consistency.
NeRF-Editing: Geometry Editing of Neural Radiance Fields
May 10, 2022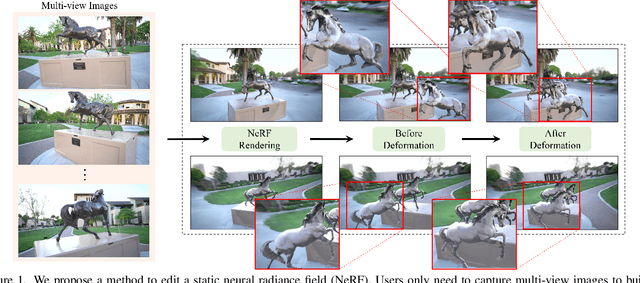

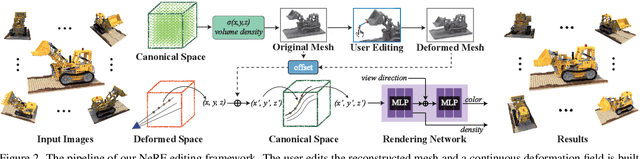

Implicit neural rendering, especially Neural Radiance Field (NeRF), has shown great potential in novel view synthesis of a scene. However, current NeRF-based methods cannot enable users to perform user-controlled shape deformation in the scene. While existing works have proposed some approaches to modify the radiance field according to the user's constraints, the modification is limited to color editing or object translation and rotation. In this paper, we propose a method that allows users to perform controllable shape deformation on the implicit representation of the scene, and synthesizes the novel view images of the edited scene without re-training the network. Specifically, we establish a correspondence between the extracted explicit mesh representation and the implicit neural representation of the target scene. Users can first utilize well-developed mesh-based deformation methods to deform the mesh representation of the scene. Our method then utilizes user edits from the mesh representation to bend the camera rays by introducing a tetrahedra mesh as a proxy, obtaining the rendering results of the edited scene. Extensive experiments demonstrate that our framework can achieve ideal editing results not only on synthetic data, but also on real scenes captured by users.
DrawingInStyles: Portrait Image Generation and Editing with Spatially Conditioned StyleGAN
Mar 05, 2022

The research topic of sketch-to-portrait generation has witnessed a boost of progress with deep learning techniques. The recently proposed StyleGAN architectures achieve state-of-the-art generation ability but the original StyleGAN is not friendly for sketch-based creation due to its unconditional generation nature. To address this issue, we propose a direct conditioning strategy to better preserve the spatial information under the StyleGAN framework. Specifically, we introduce Spatially Conditioned StyleGAN (SC-StyleGAN for short), which explicitly injects spatial constraints to the original StyleGAN generation process. We explore two input modalities, sketches and semantic maps, which together allow users to express desired generation results more precisely and easily. Based on SC-StyleGAN, we present DrawingInStyles, a novel drawing interface for non-professional users to easily produce high-quality, photo-realistic face images with precise control, either from scratch or editing existing ones. Qualitative and quantitative evaluations show the superior generation ability of our method to existing and alternative solutions. The usability and expressiveness of our system are confirmed by a user study.
Socially-Optimal Mechanism Design for Incentivized Online Learning
Dec 29, 2021
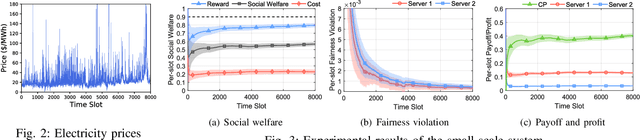
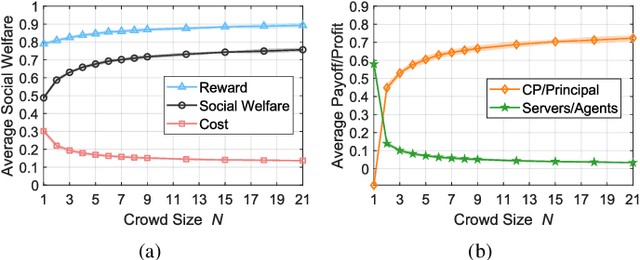

Multi-arm bandit (MAB) is a classic online learning framework that studies the sequential decision-making in an uncertain environment. The MAB framework, however, overlooks the scenario where the decision-maker cannot take actions (e.g., pulling arms) directly. It is a practically important scenario in many applications such as spectrum sharing, crowdsensing, and edge computing. In these applications, the decision-maker would incentivize other selfish agents to carry out desired actions (i.e., pulling arms on the decision-maker's behalf). This paper establishes the incentivized online learning (IOL) framework for this scenario. The key challenge to design the IOL framework lies in the tight coupling of the unknown environment learning and asymmetric information revelation. To address this, we construct a special Lagrangian function based on which we propose a socially-optimal mechanism for the IOL framework. Our mechanism satisfies various desirable properties such as agent fairness, incentive compatibility, and voluntary participation. It achieves the same asymptotic performance as the state-of-art benchmark that requires extra information. Our analysis also unveils the power of crowd in the IOL framework: a larger agent crowd enables our mechanism to approach more closely the theoretical upper bound of social performance. Numerical results demonstrate the advantages of our mechanism in large-scale edge computing.
High-Fidelity Point Cloud Completion with Low-Resolution Recovery and Noise-Aware Upsampling
Dec 22, 2021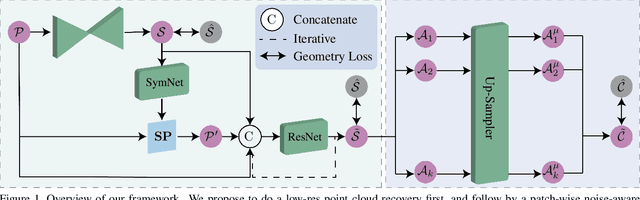
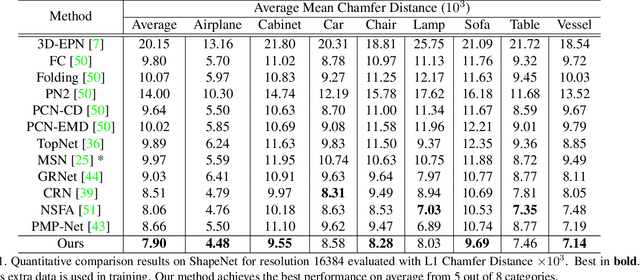
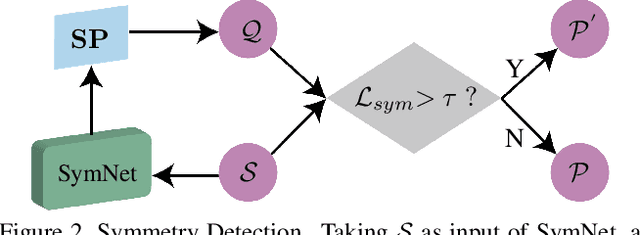
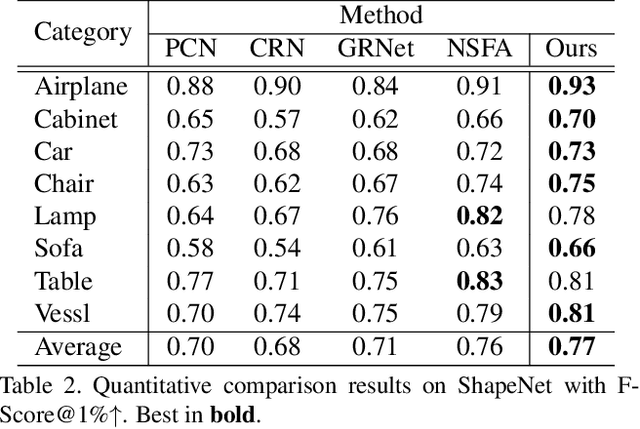
Completing an unordered partial point cloud is a challenging task. Existing approaches that rely on decoding a latent feature to recover the complete shape, often lead to the completed point cloud being over-smoothing, losing details, and noisy. Instead of decoding a whole shape, we propose to decode and refine a low-resolution (low-res) point cloud first, and then performs a patch-wise noise-aware upsampling rather than interpolating the whole sparse point cloud at once, which tends to lose details. Regarding the possibility of lacking details of the initially decoded low-res point cloud, we propose an iterative refinement to recover the geometric details and a symmetrization process to preserve the trustworthy information from the input partial point cloud. After obtaining a sparse and complete point cloud, we propose a patch-wise upsampling strategy. Patch-based upsampling allows to better recover fine details unlike decoding a whole shape, however, the existing upsampling methods are not applicable to completion task due to the data discrepancy (i.e., input sparse data here is not from ground-truth). Therefore, we propose a patch extraction approach to generate training patch pairs between the sparse and ground-truth point clouds, and an outlier removal step to suppress the noisy points from the sparse point cloud. Together with the low-res recovery, our whole method is able to achieve high-fidelity point cloud completion. Comprehensive evaluations are provided to demonstrate the effectiveness of the proposed method and its individual components.
OctField: Hierarchical Implicit Functions for 3D Modeling
Nov 01, 2021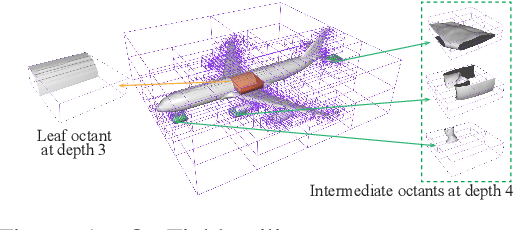
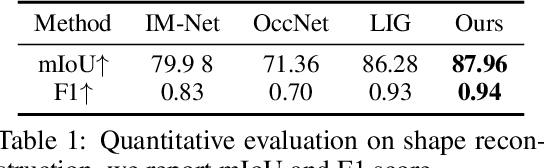
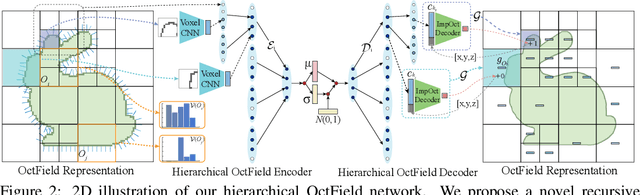
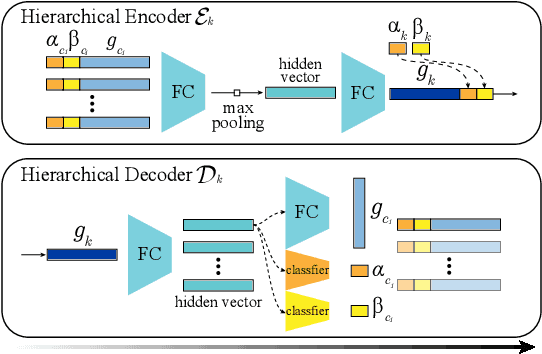
Recent advances in localized implicit functions have enabled neural implicit representation to be scalable to large scenes. However, the regular subdivision of 3D space employed by these approaches fails to take into account the sparsity of the surface occupancy and the varying granularities of geometric details. As a result, its memory footprint grows cubically with the input volume, leading to a prohibitive computational cost even at a moderately dense decomposition. In this work, we present a learnable hierarchical implicit representation for 3D surfaces, coded OctField, that allows high-precision encoding of intricate surfaces with low memory and computational budget. The key to our approach is an adaptive decomposition of 3D scenes that only distributes local implicit functions around the surface of interest. We achieve this goal by introducing a hierarchical octree structure to adaptively subdivide the 3D space according to the surface occupancy and the richness of part geometry. As octree is discrete and non-differentiable, we further propose a novel hierarchical network that models the subdivision of octree cells as a probabilistic process and recursively encodes and decodes both octree structure and surface geometry in a differentiable manner. We demonstrate the value of OctField for a range of shape modeling and reconstruction tasks, showing superiority over alternative approaches.
Multi-sensor joint target detection, tracking and classification via Bernoulli filter
Sep 23, 2021
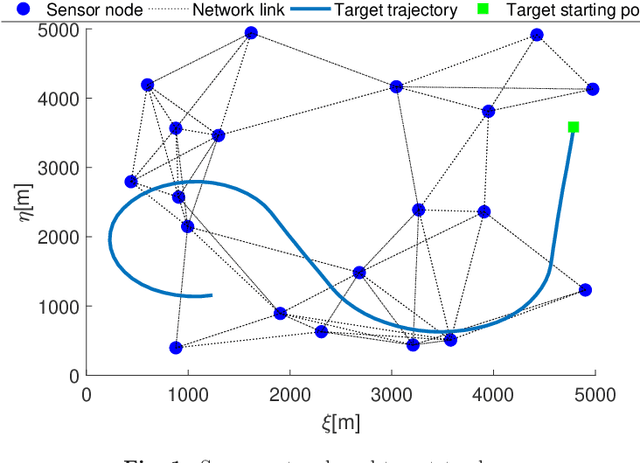

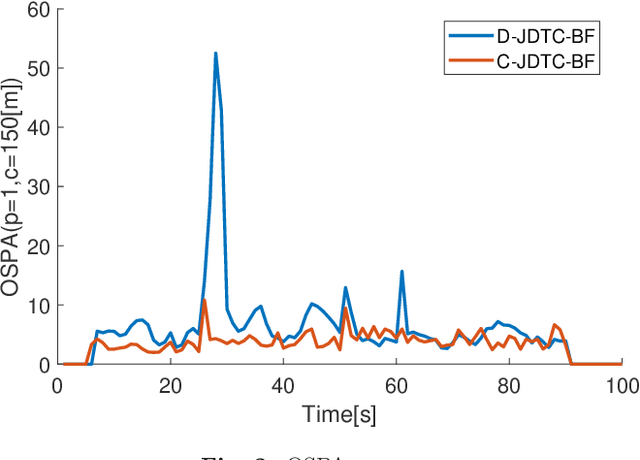
This paper focuses on \textit{joint detection, tracking and classification} (JDTC) of a target via multi-sensor fusion. The target can be present or not, can belong to different classes, and depending on its class can behave according to different kinematic modes. Accordingly, it is modeled as a suitably extended Bernoulli \textit{random finite set} (RFS) uniquely characterized by existence, classification, class-conditioned mode and class\&mode-conditioned state probability distributions. By designing suitable centralized and distributed rules for fusing information on target existence, class, mode and state from different sensor nodes, novel \textit{centralized} and \textit{distributed} JDTC \textit{Bernoulli filters} (C-JDTC-BF and D-JDTC-BF), are proposed. The performance of the proposed JDTC-BF approach is evaluated by means of simulation experiments.
Robust Pose Transfer with Dynamic Details using Neural Video Rendering
Jul 14, 2021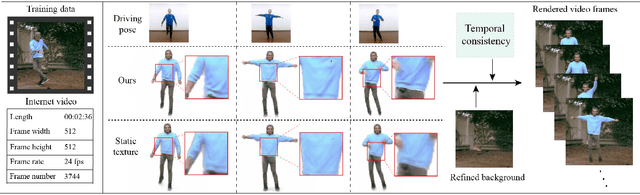
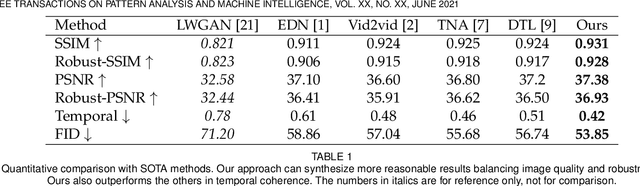
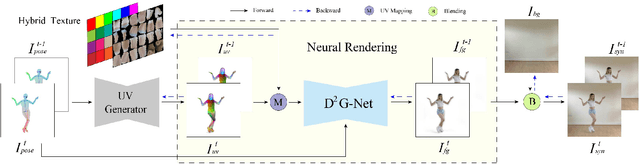
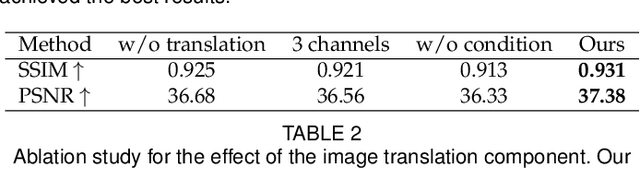
Pose transfer of human videos aims to generate a high fidelity video of a target person imitating actions of a source person. A few studies have made great progress either through image translation with deep latent features or neural rendering with explicit 3D features. However, both of them rely on large amounts of training data to generate realistic results, and the performance degrades on more accessible internet videos due to insufficient training frames. In this paper, we demonstrate that the dynamic details can be preserved even trained from short monocular videos. Overall, we propose a neural video rendering framework coupled with an image-translation-based dynamic details generation network (D2G-Net), which fully utilizes both the stability of explicit 3D features and the capacity of learning components. To be specific, a novel texture representation is presented to encode both the static and pose-varying appearance characteristics, which is then mapped to the image space and rendered as a detail-rich frame in the neural rendering stage. Moreover, we introduce a concise temporal loss in the training stage to suppress the detail flickering that is made more visible due to high-quality dynamic details generated by our method. Through extensive comparisons, we demonstrate that our neural human video renderer is capable of achieving both clearer dynamic details and more robust performance even on accessible short videos with only 2k - 4k frames.