 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint-Voxel Adaptive Feature Abstraction for Robust Point Cloud Classification
Oct 30, 2022



Great progress has been made in point cloud classification with learning-based methods. However, complex scene and sensor inaccuracy in real-world application make point cloud data suffer from corruptions, such as occlusion, noise and outliers. In this work, we propose Point-Voxel based Adaptive (PV-Ada) feature abstraction for robust point cloud classification under various corruptions. Specifically, the proposed framework iteratively voxelize the point cloud and extract point-voxel feature with shared local encoding and Transformer. Then, adaptive max-pooling is proposed to robustly aggregate the point cloud feature for classification. Experiments on ModelNet-C dataset demonstrate that PV-Ada outperforms the state-of-the-art methods. In particular, we rank the $2^{nd}$ place in ModelNet-C classification track of PointCloud-C Challenge 2022, with Overall Accuracy (OA) being 0.865. Code will be available at https://github.com/zhulf0804/PV-Ada.
Neighborhood-aware Geometric Encoding Network for Point Cloud Registration
Jan 28, 2022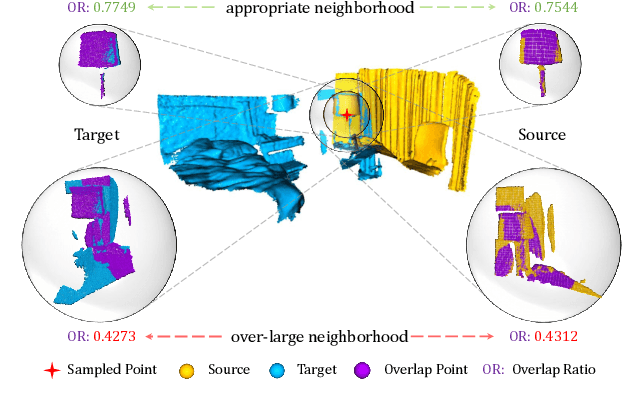
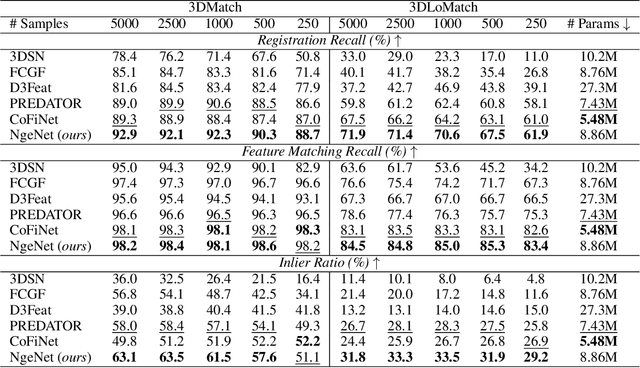
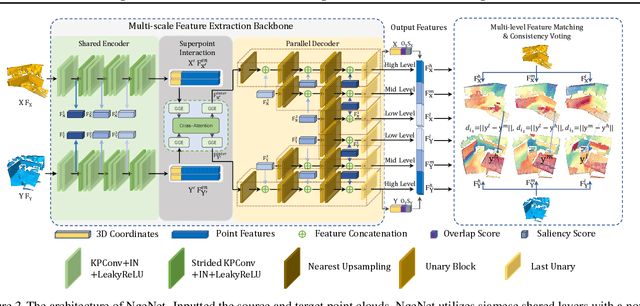
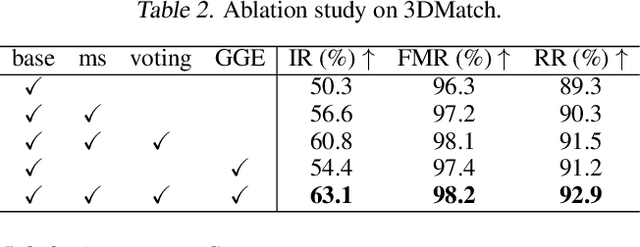
The distinguishing geometric features determine the success of point cloud registration. However, most point clouds are partially overlapping, corrupted by noise, and comprised of indistinguishable surfaces, which makes it a challenge to extract discriminative features. Here, we propose the Neighborhood-aware Geometric Encoding Network (NgeNet) for accurate point cloud registration. NgeNet utilizes a geometric guided encoding module to take geometric characteristics into consideration, a multi-scale architecture to focus on the semantically rich regions in different scales, and a consistent voting strategy to select features with proper neighborhood size and reject the specious features. The awareness of adaptive neighborhood points is obtained through the multi-scale architecture accompanied by voting. Specifically, the proposed techniques in NgeNet are model-agnostic, which could be easily migrated to other networks. Comprehensive experiments on indoor, outdoor and object-centric synthetic datasets demonstrate that NgeNet surpasses all of the published state-of-the-art methods. The code will be available at https://github.com/zhulf0804/NgeNet.
Multi-View Partial Point Cloud Challenge 2021 on Completion and Registration: Methods and Results
Dec 22, 2021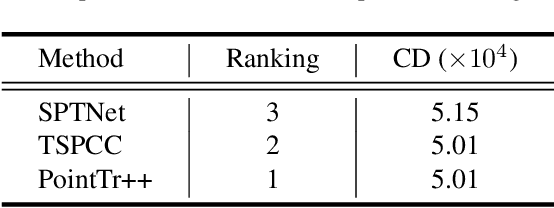
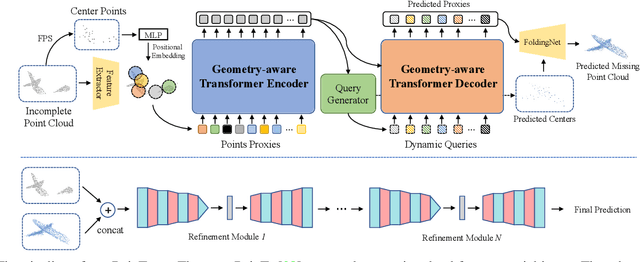
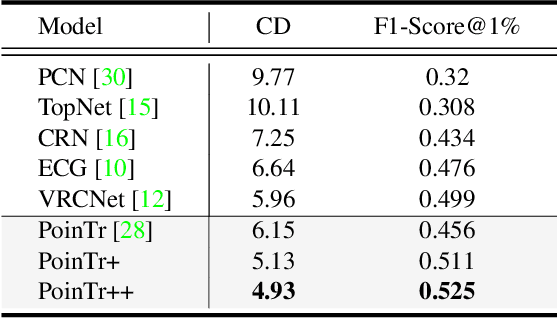
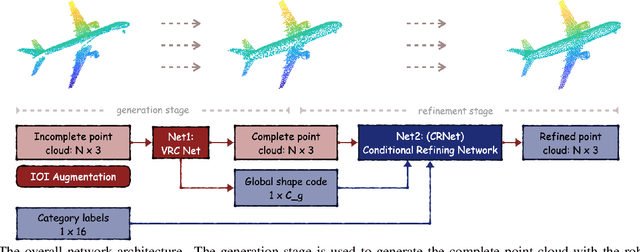
As real-scanned point clouds are mostly partial due to occlusions and viewpoints, reconstructing complete 3D shapes based on incomplete observations becomes a fundamental problem for computer vision. With a single incomplete point cloud, it becomes the partial point cloud completion problem. Given multiple different observations, 3D reconstruction can be addressed by performing partial-to-partial point cloud registration. Recently, a large-scale Multi-View Partial (MVP) point cloud dataset has been released, which consists of over 100,000 high-quality virtual-scanned partial point clouds. Based on the MVP dataset, this paper reports methods and results in the Multi-View Partial Point Cloud Challenge 2021 on Completion and Registration. In total, 128 participants registered for the competition, and 31 teams made valid submissions. The top-ranked solutions will be analyzed, and then we will discuss future research directions.
Deep Models with Fusion Strategies for MVP Point Cloud Registration
Oct 18, 2021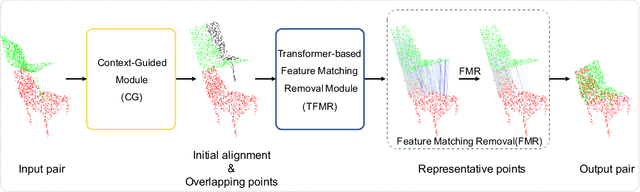
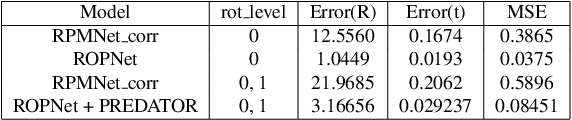
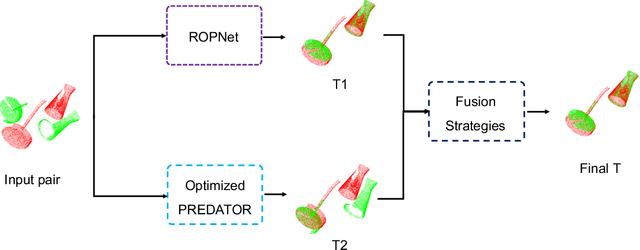
The main goal of point cloud registration in Multi-View Partial (MVP) Challenge 2021 is to estimate a rigid transformation to align a point cloud pair. The pairs in this competition have the characteristics of low overlap, non-uniform density, unrestricted rotations and ambiguity, which pose a huge challenge to the registration task. In this report, we introduce our solution to the registration task, which fuses two deep learning models: ROPNet and PREDATOR, with customized ensemble strategies. Finally, we achieved the second place in the registration track with 2.96546, 0.02632 and 0.07808 under the the metrics of Rot\_Error, Trans\_Error and MSE, respectively.
Point Cloud Registration using Representative Overlapping Points
Jul 06, 2021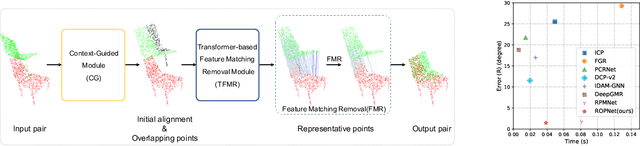
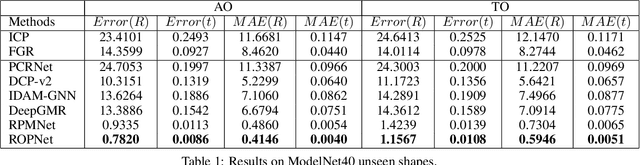
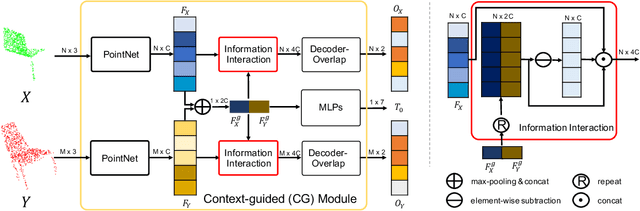
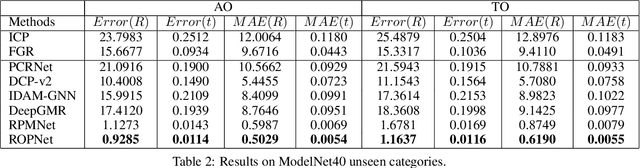
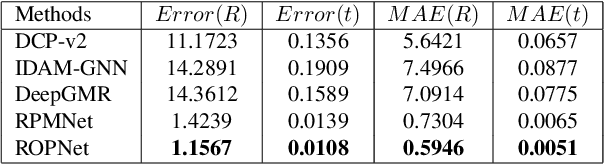
3D point cloud registration is a fundamental task in robotics and computer vision. Recently, many learning-based point cloud registration methods based on correspondences have emerged. However, these methods heavily rely on such correspondences and meet great challenges with partial overlap. In this paper, we propose ROPNet, a new deep learning model using Representative Overlapping Points with discriminative features for registration that transforms partial-to-partial registration into partial-to-complete registration. Specifically, we propose a context-guided module which uses an encoder to extract global features for predicting point overlap score. To better find representative overlapping points, we use the extracted global features for coarse alignment. Then, we introduce a Transformer to enrich point features and remove non-representative points based on point overlap score and feature matching. A similarity matrix is built in a partial-to-complete mode, and finally, weighted SVD is adopted to estimate a transformation matrix. Extensive experiments over ModelNet40 using noisy and partially overlapping point clouds show that the proposed method outperforms traditional and learning-based methods, achieving state-of-the-art performance. The code is available at https://github.com/zhulf0804/ROPNet.
SegET: Deep Neural Network with Rich Contextual Features for Cellular Structures Segmentation in Electron Tomography Image
Nov 28, 2018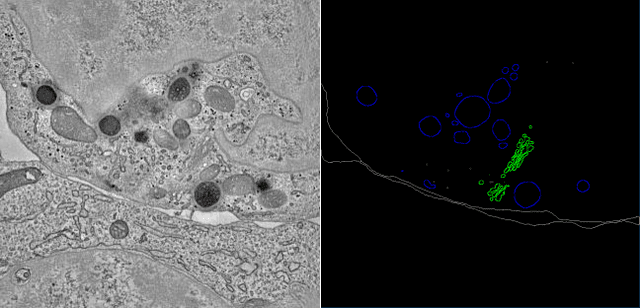
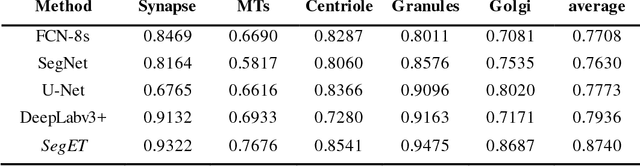
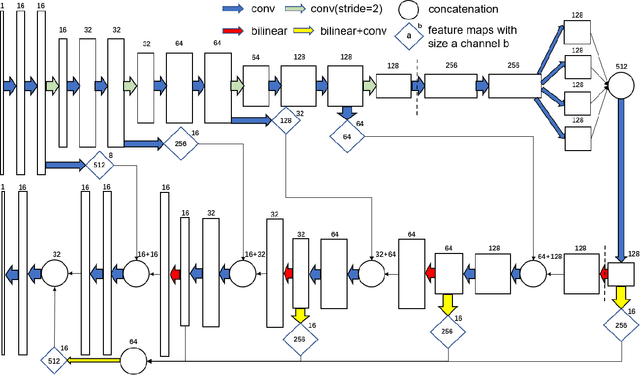
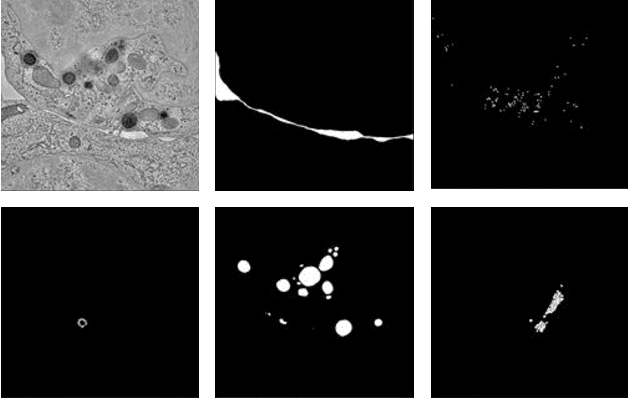
Electron tomography (ET) allows high-resolution reconstructions of macromolecular complexes at nearnative state. Cellular structures segmentation in the reconstruction data from electron tomographic images is often required for analyzing and visualizing biological structures, making it a powerful tool for quantitative descriptions of whole cell structures and understanding biological functions. However, these cellular structures are rather difficult to automatically separate or quantify from view owing to complex molecular environment and the limitations of reconstruction data of ET. In this paper, we propose a single end-to-end deep fully-convolutional semantic segmentation network dubbed SegET with rich contextual features which fully exploitsthe multi-scale and multi-level contextual information and reduces the loss of details of cellular structures in ET images. We trained and evaluated our network on the electron tomogram of the CTL Immunological Synapse from Cell Image library. Our results demonstrate that SegET can automatically segment accurately and outperform all other baseline methods on each individual structure in our ET dataset.