 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Safety Fails Before the Answer: Benchmarking Harmful Behavior Detection in Reasoning Chains
Apr 21, 2026Large reasoning models (LRMs) produce complex, multi-step reasoning traces, yet safety evaluation remains focused on final outputs, overlooking how harm emerges during reasoning. When jailbroken, harm does not appear instantaneously but unfolds through distinct behavioral steps such as suppressing refusal, rationalizing compliance, decomposing harmful tasks, and concealing risk. However, no existing benchmark captures this process at sentence-level granularity within reasoning traces -- a key step toward reliable safety monitoring, interventions, and systematic failure diagnosis. To address this gap, we introduce HarmThoughts, a benchmark for step-wise safety evaluation of reasoning traces. \ourdataset is built on our proposed harm taxonomy of 16 harmful reasoning behaviors across four functional groups that characterize how harm propagates rather than what harm is produced. The dataset consists of 56,931 sentences from 1,018 reasoning traces generated by four model families, each annotated with fine-grained sentence-level behavioral labels. Using HarmThoughts, we analyze harm propagation patterns across reasoning traces, identifying common behavioral trajectories and drift points where reasoning transitions from safe to unsafe. Finally, we systematically compare white-box and black-box detectors on the task of identifying harmful reasoning behaviours on HarmThoughts. Our results show that existing detectors struggle with fine-grained behavior detection in reasoning traces, particularly for nuanced categories within harm emergence and execution, highlighting a critical gap in process-level safety monitoring. HarmThoughts is available publicly at: https://huggingface.co/datasets/ishitakakkar-10/HarmThoughts
Appear2Meaning: A Cross-Cultural Benchmark for Structured Cultural Metadata Inference from Images
Apr 08, 2026Recent advances in vision-language models (VLMs) have improved image captioning for cultural heritage. However, inferring structured cultural metadata (e.g., creator, origin, period) from visual input remains underexplored. We introduce a multi-category, cross-cultural benchmark for this task and evaluate VLMs using an LLM-as-Judge framework that measures semantic alignment with reference annotations. To assess cultural reasoning, we report exact-match, partial-match, and attribute-level accuracy across cultural regions. Results show that models capture fragmented signals and exhibit substantial performance variation across cultures and metadata types, leading to inconsistent and weakly grounded predictions. These findings highlight the limitations of current VLMs in structured cultural metadata inference beyond visual perception.
State-Action Inpainting Diffuser for Continuous Control with Delay
Mar 02, 2026Signal delay poses a fundamental challenge in continuous control and reinforcement learning (RL) by introducing a temporal gap between interaction and perception. Current solutions have largely evolved along two distinct paradigms: model-free approaches which utilize state augmentation to preserve Markovian properties, and model-based methods which focus on inferring latent beliefs via dynamics modeling. In this paper, we bridge these perspectives by introducing State-Action Inpainting Diffuser (SAID), a framework that integrates the inductive bias of dynamics learning with the direct decision-making capability of policy optimization. By formulating the problem as a joint sequence inpainting task, SAID implicitly captures environmental dynamics while directly generating consistent plans, effectively operating at the intersection of model-based and model-free paradigms. Crucially, this generative formulation allows SAID to be seamlessly applied to both online and offline RL. Extensive experiments on delayed continuous control benchmarks demonstrate that SAID achieves state-of-the-art and robust performance. Our study suggests a new methodology to advance the field of RL with delay.
MentraSuite: Post-Training Large Language Models for Mental Health Reasoning and Assessment
Dec 16, 2025Mental health disorders affect hundreds of millions globally, and the Web now serves as a primary medium for accessing support, information, and assessment. Large language models (LLMs) offer scalable and accessible assistance, yet their deployment in mental-health settings remains risky when their reasoning is incomplete, inconsistent, or ungrounded. Existing psychological LLMs emphasize emotional understanding or knowledge recall but overlook the step-wise, clinically aligned reasoning required for appraisal, diagnosis, intervention planning, abstraction, and verification. To address these issues, we introduce MentraSuite, a unified framework for advancing reliable mental-health reasoning. We propose MentraBench, a comprehensive benchmark spanning five core reasoning aspects, six tasks, and 13 datasets, evaluating both task performance and reasoning quality across five dimensions: conciseness, coherence, hallucination avoidance, task understanding, and internal consistency. We further present Mindora, a post-trained model optimized through a hybrid SFT-RL framework with an inconsistency-detection reward to enforce faithful and coherent reasoning. To support training, we construct high-quality trajectories using a novel reasoning trajectory generation strategy, that strategically filters difficult samples and applies a structured, consistency-oriented rewriting process to produce concise, readable, and well-balanced trajectories. Across 20 evaluated LLMs, Mindora achieves the highest average performance on MentraBench and shows remarkable performances in reasoning reliability, demonstrating its effectiveness for complex mental-health scenarios.
SegET: Deep Neural Network with Rich Contextual Features for Cellular Structures Segmentation in Electron Tomography Image
Nov 28, 2018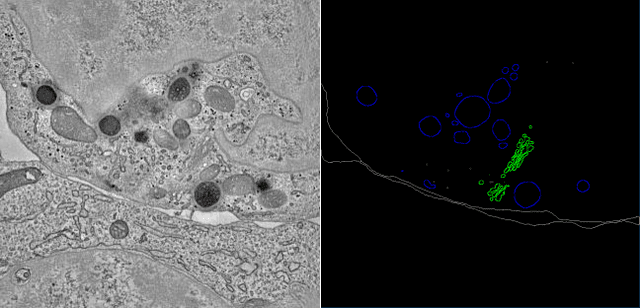
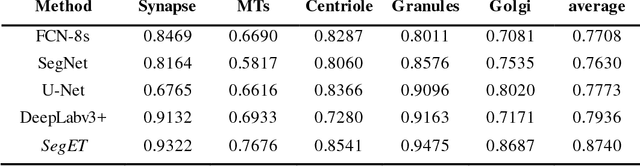
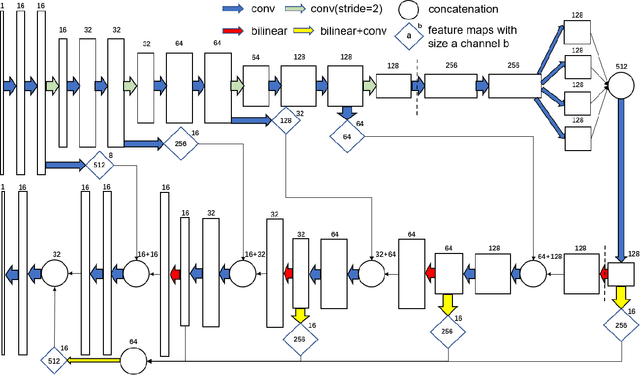
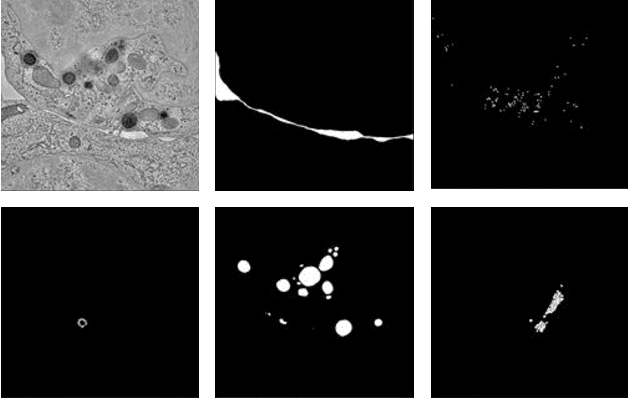
Electron tomography (ET) allows high-resolution reconstructions of macromolecular complexes at nearnative state. Cellular structures segmentation in the reconstruction data from electron tomographic images is often required for analyzing and visualizing biological structures, making it a powerful tool for quantitative descriptions of whole cell structures and understanding biological functions. However, these cellular structures are rather difficult to automatically separate or quantify from view owing to complex molecular environment and the limitations of reconstruction data of ET. In this paper, we propose a single end-to-end deep fully-convolutional semantic segmentation network dubbed SegET with rich contextual features which fully exploitsthe multi-scale and multi-level contextual information and reduces the loss of details of cellular structures in ET images. We trained and evaluated our network on the electron tomogram of the CTL Immunological Synapse from Cell Image library. Our results demonstrate that SegET can automatically segment accurately and outperform all other baseline methods on each individual structure in our ET dataset.