 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChange is Everywhere: Single-Temporal Supervised Object Change Detection in Remote Sensing Imagery
Aug 16, 2021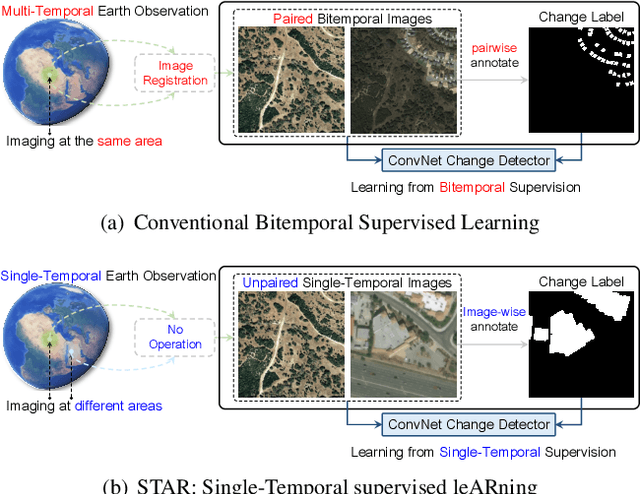
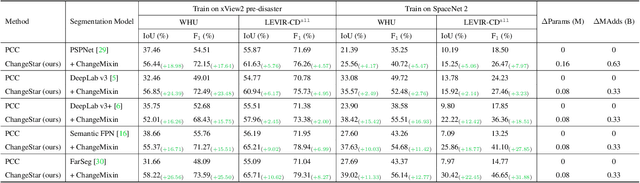

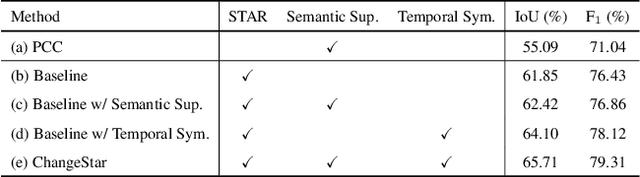
For high spatial resolution (HSR) remote sensing images, bitemporal supervised learning always dominates change detection using many pairwise labeled bitemporal images. However, it is very expensive and time-consuming to pairwise label large-scale bitemporal HSR remote sensing images. In this paper, we propose single-temporal supervised learning (STAR) for change detection from a new perspective of exploiting object changes in unpaired images as supervisory signals. STAR enables us to train a high-accuracy change detector only using \textbf{unpaired} labeled images and generalize to real-world bitemporal images. To evaluate the effectiveness of STAR, we design a simple yet effective change detector called ChangeStar, which can reuse any deep semantic segmentation architecture by the ChangeMixin module. The comprehensive experimental results show that ChangeStar outperforms the baseline with a large margin under single-temporal supervision and achieves superior performance under bitemporal supervision. Code is available at https://github.com/Z-Zheng/ChangeStar
Coupling Model-Driven and Data-Driven Methods for Remote Sensing Image Restoration and Fusion
Aug 13, 2021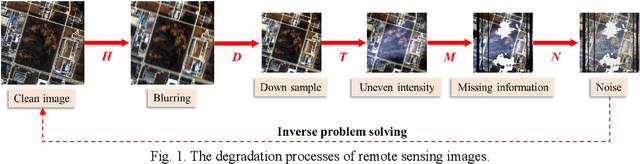
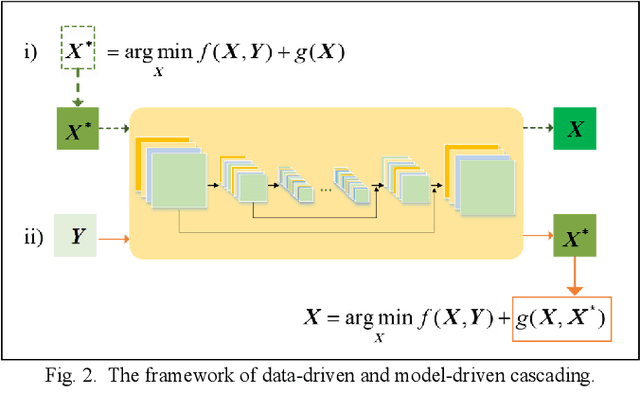
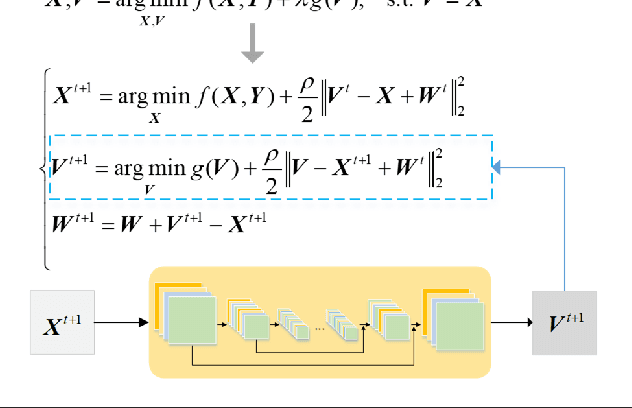
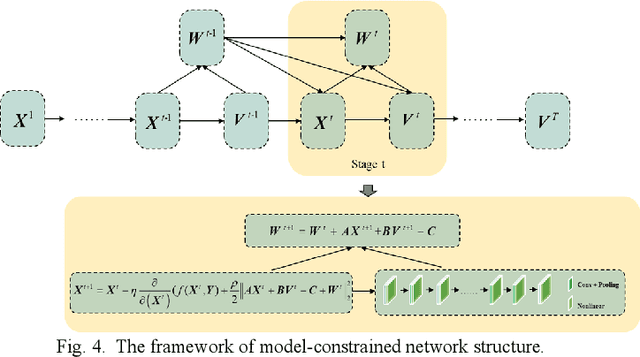
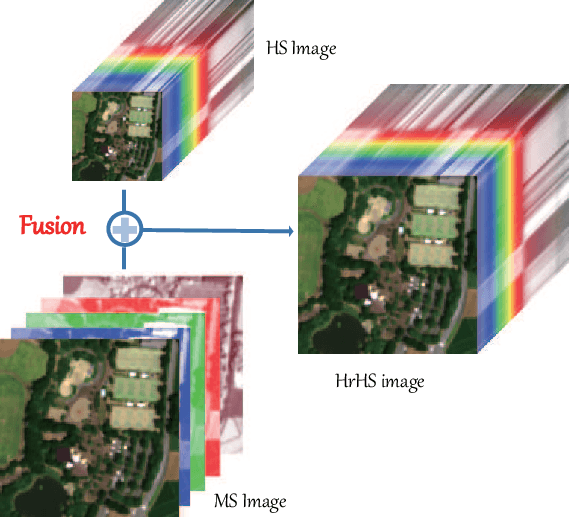
In the fields of image restoration and image fusion, model-driven methods and data-driven methods are the two representative frameworks. However, both approaches have their respective advantages and disadvantages. The model-driven methods consider the imaging mechanism, which is deterministic and theoretically reasonable; however, they cannot easily model complicated nonlinear problems. The data-driven methods have a stronger prior knowledge learning capability for huge data, especially for nonlinear statistical features; however, the interpretability of the networks is poor, and they are over-dependent on training data. In this paper, we systematically investigate the coupling of model-driven and data-driven methods, which has rarely been considered in the remote sensing image restoration and fusion communities. We are the first to summarize the coupling approaches into the following three categories: 1) data-driven and model-driven cascading methods; 2) variational models with embedded learning; and 3) model-constrained network learning methods. The typical existing and potential coupling methods for remote sensing image restoration and fusion are introduced with application examples. This paper also gives some new insights into the potential future directions, in terms of both methods and applications.
Spectral-Spatial Graph Reasoning Network for Hyperspectral Image Classification
Jun 26, 2021


In this paper, we propose a spectral-spatial graph reasoning network (SSGRN) for hyperspectral image (HSI) classification. Concretely, this network contains two parts that separately named spatial graph reasoning subnetwork (SAGRN) and spectral graph reasoning subnetwork (SEGRN) to capture the spatial and spectral graph contexts, respectively. Different from the previous approaches implementing superpixel segmentation on the original image or attempting to obtain the category features under the guide of label image, we perform the superpixel segmentation on intermediate features of the network to adaptively produce the homogeneous regions to get the effective descriptors. Then, we adopt a similar idea in spectral part that reasonably aggregating the channels to generate spectral descriptors for spectral graph contexts capturing. All graph reasoning procedures in SAGRN and SEGRN are achieved through graph convolution. To guarantee the global perception ability of the proposed methods, all adjacent matrices in graph reasoning are obtained with the help of non-local self-attention mechanism. At last, by combining the extracted spatial and spectral graph contexts, we obtain the SSGRN to achieve a high accuracy classification. Extensive quantitative and qualitative experiments on three public HSI benchmarks demonstrate the competitiveness of the proposed methods compared with other state-of-the-art approaches.
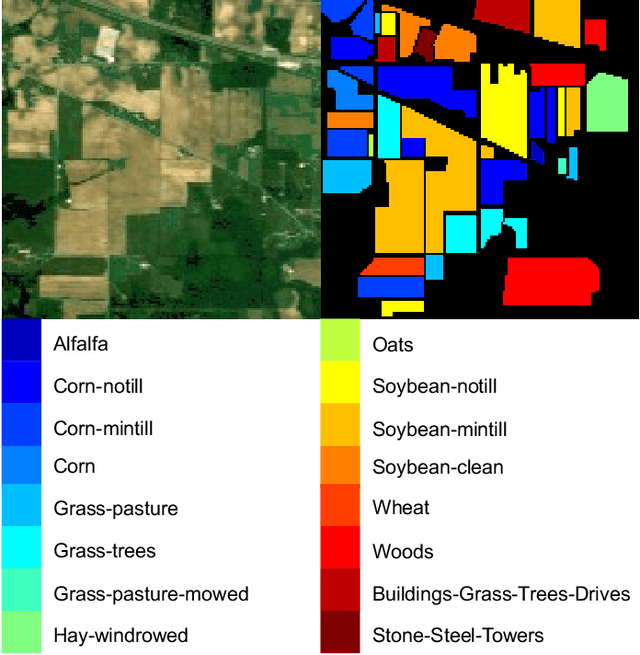
A Spectral-Spatial-Dependent Global Learning Framework for Insufficient and Imbalanced Hyperspectral Image Classification
May 29, 2021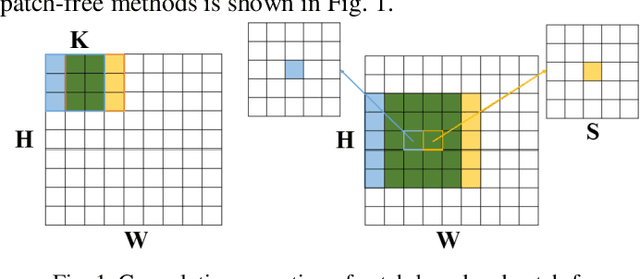
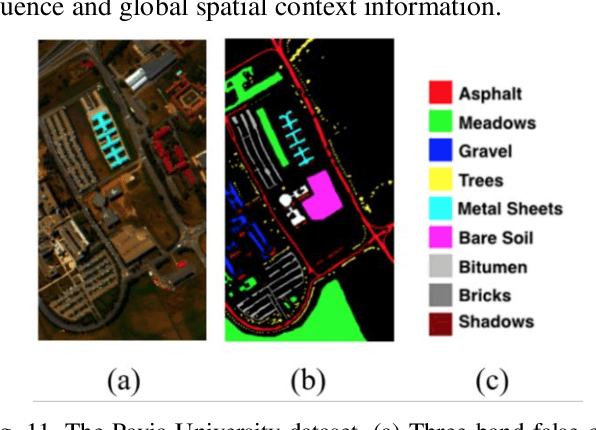

Deep learning techniques have been widely applied to hyperspectral image (HSI) classification and have achieved great success. However, the deep neural network model has a large parameter space and requires a large number of labeled data. Deep learning methods for HSI classification usually follow a patchwise learning framework. Recently, a fast patch-free global learning (FPGA) architecture was proposed for HSI classification according to global spatial context information. However, FPGA has difficulty extracting the most discriminative features when the sample data is imbalanced. In this paper, a spectral-spatial dependent global learning (SSDGL) framework based on global convolutional long short-term memory (GCL) and global joint attention mechanism (GJAM) is proposed for insufficient and imbalanced HSI classification. In SSDGL, the hierarchically balanced (H-B) sampling strategy and the weighted softmax loss are proposed to address the imbalanced sample problem. To effectively distinguish similar spectral characteristics of land cover types, the GCL module is introduced to extract the long short-term dependency of spectral features. To learn the most discriminative feature representations, the GJAM module is proposed to extract attention areas. The experimental results obtained with three public HSI datasets show that the SSDGL has powerful performance in insufficient and imbalanced sample problems and is superior to other state-of-the-art methods. Code can be obtained at: https://github.com/dengweihuan/SSDGL.
Robust Self-Ensembling Network for Hyperspectral Image Classification
Apr 08, 2021
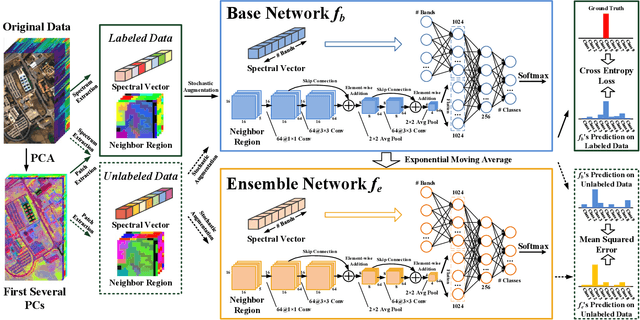
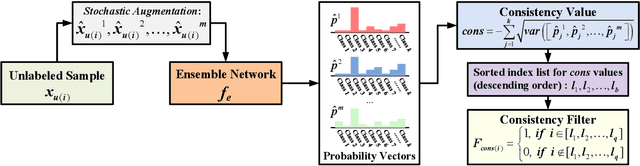
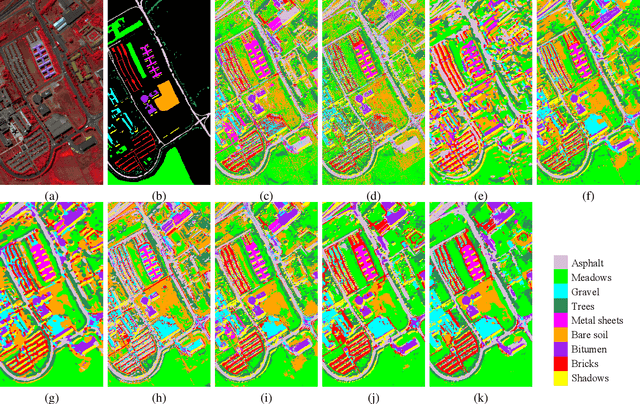
Recent research has shown the great potential of deep learning algorithms in the hyperspectral image (HSI) classification task. Nevertheless, training these models usually requires a large amount of labeled data. Since the collection of pixel-level annotations for HSI is laborious and time-consuming, developing algorithms that can yield good performance in the small sample size situation is of great significance. In this study, we propose a robust self-ensembling network (RSEN) to address this problem. The proposed RSEN consists of two subnetworks including a base network and an ensemble network. With the constraint of both the supervised loss from the labeled data and the unsupervised loss from the unlabeled data, the base network and the ensemble network can learn from each other, achieving the self-ensembling mechanism. To the best of our knowledge, the proposed method is the first attempt to introduce the self-ensembling technique into the HSI classification task, which provides a different view on how to utilize the unlabeled data in HSI to assist the network training. We further propose a novel consistency filter to increase the robustness of self-ensembling learning. Extensive experiments on three benchmark HSI datasets demonstrate that the proposed algorithm can yield competitive performance compared with the state-of-the-art methods.
Transportation Density Reduction Caused by City Lockdowns Across the World during the COVID-19 Epidemic: From the View of High-resolution Remote Sensing Imagery
Mar 02, 2021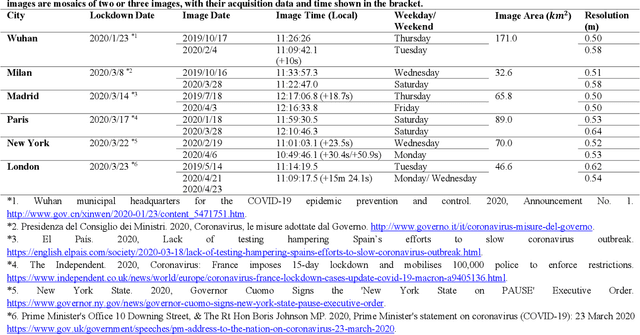
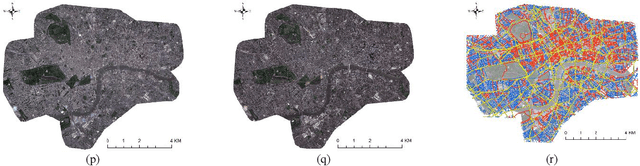
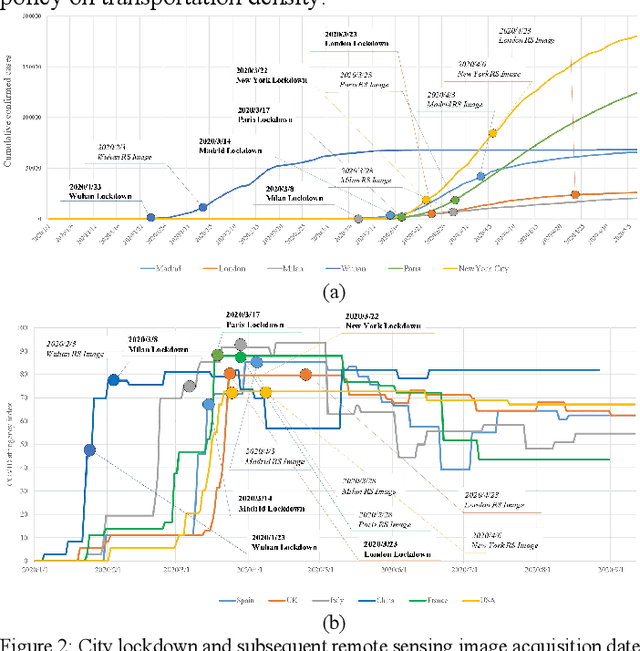
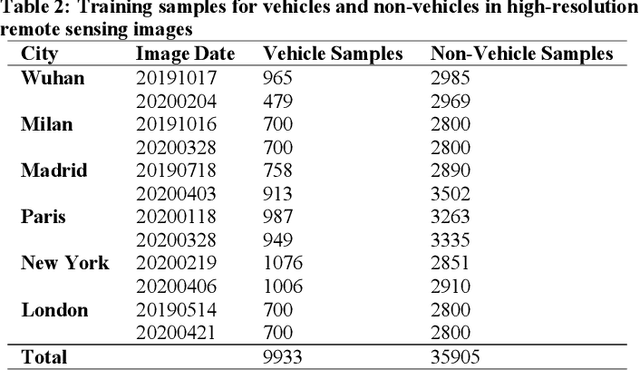
As the COVID-19 epidemic began to worsen in the first months of 2020, stringent lockdown policies were implemented in numerous cities throughout the world to control human transmission and mitigate its spread. Although transportation density reduction inside the city was felt subjectively, there has thus far been no objective and quantitative study of its variation to reflect the intracity population flows and their corresponding relationship with lockdown policy stringency from the view of remote sensing images with the high resolution under 1m. Accordingly, we here provide a quantitative investigation of the transportation density reduction before and after lockdown was implemented in six epicenter cities (Wuhan, Milan, Madrid, Paris, New York, and London) around the world during the COVID-19 epidemic, which is accomplished by extracting vehicles from the multi-temporal high-resolution remote sensing images. A novel vehicle detection model combining unsupervised vehicle candidate extraction and deep learning identification was specifically proposed for the images with the resolution of 0.5m. Our results indicate that transportation densities were reduced by an average of approximately 50% (and as much as 75.96%) in these six cities following lockdown. The influences on transportation density reduction rates are also highly correlated with policy stringency, with an R^2 value exceeding 0.83. Even within a specific city, the transportation density changes differed and tended to be distributed in accordance with the city's land-use patterns. Considering that public transportation was mostly reduced or even forbidden, our results indicate that city lockdown policies are effective at limiting human transmission within cities.
Interpretable Hyperspectral AI: When Non-Convex Modeling meets Hyperspectral Remote Sensing
Mar 02, 2021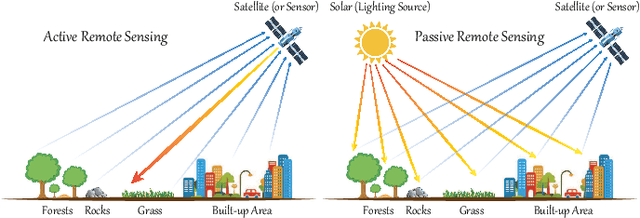


Hyperspectral imaging, also known as image spectrometry, is a landmark technique in geoscience and remote sensing (RS). In the past decade, enormous efforts have been made to process and analyze these hyperspectral (HS) products mainly by means of seasoned experts. However, with the ever-growing volume of data, the bulk of costs in manpower and material resources poses new challenges on reducing the burden of manual labor and improving efficiency. For this reason, it is, therefore, urgent to develop more intelligent and automatic approaches for various HS RS applications. Machine learning (ML) tools with convex optimization have successfully undertaken the tasks of numerous artificial intelligence (AI)-related applications. However, their ability in handling complex practical problems remains limited, particularly for HS data, due to the effects of various spectral variabilities in the process of HS imaging and the complexity and redundancy of higher dimensional HS signals. Compared to the convex models, non-convex modeling, which is capable of characterizing more complex real scenes and providing the model interpretability technically and theoretically, has been proven to be a feasible solution to reduce the gap between challenging HS vision tasks and currently advanced intelligent data processing models.
Super-resolution-based Change Detection Network with Stacked Attention Module for Images with Different Resolutions
Feb 27, 2021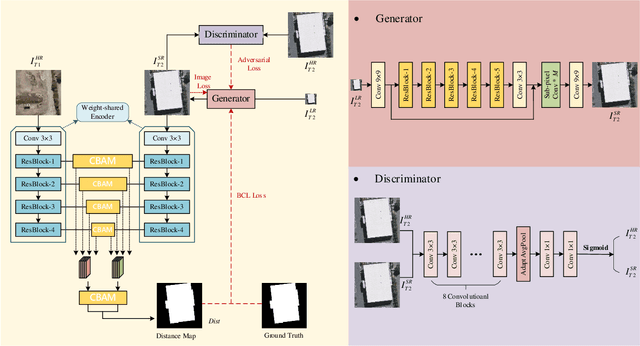

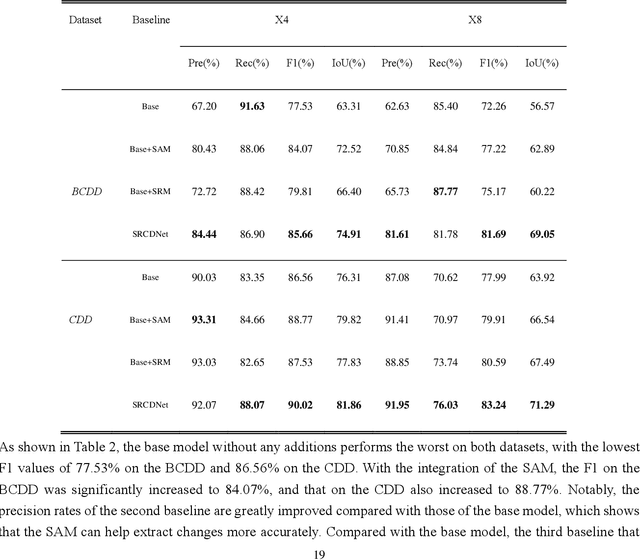

Change detection, which aims to distinguish surface changes based on bi-temporal images, plays a vital role in ecological protection and urban planning. Since high resolution (HR) images cannot be typically acquired continuously over time, bi-temporal images with different resolutions are often adopted for change detection in practical applications. Traditional subpixel-based methods for change detection using images with different resolutions may lead to substantial error accumulation when HR images are employed; this is because of intraclass heterogeneity and interclass similarity. Therefore, it is necessary to develop a novel method for change detection using images with different resolutions, that is more suitable for HR images. To this end, we propose a super-resolution-based change detection network (SRCDNet) with a stacked attention module. The SRCDNet employs a super resolution (SR) module containing a generator and a discriminator to directly learn SR images through adversarial learning and overcome the resolution difference between bi-temporal images. To enhance the useful information in multi-scale features, a stacked attention module consisting of five convolutional block attention modules (CBAMs) is integrated to the feature extractor. The final change map is obtained through a metric learning-based change decision module, wherein a distance map between bi-temporal features is calculated. The experimental results demonstrate the superiority of the proposed method, which not only outperforms all baselines -with the highest F1 scores of 87.40% on the building change detection dataset and 92.94% on the change detection dataset -but also obtains the best accuracies on experiments performed with images having a 4x and 8x resolution difference. The source code of SRCDNet will be available at https://github.com/liumency/SRCDNet.
Object Detection in Aerial Images: A Large-Scale Benchmark and Challenges
Feb 24, 2021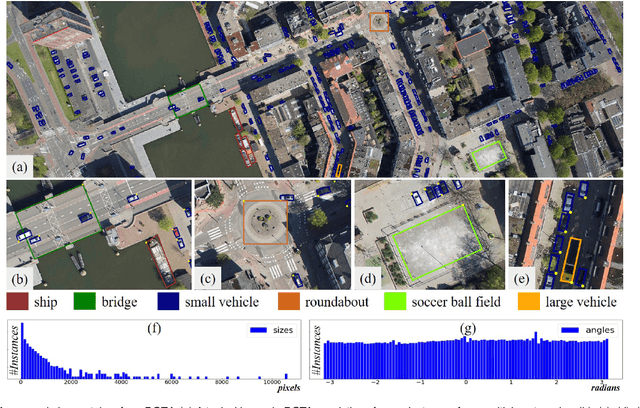
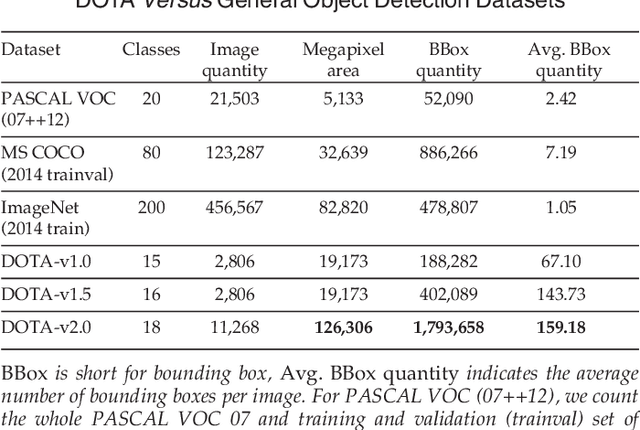
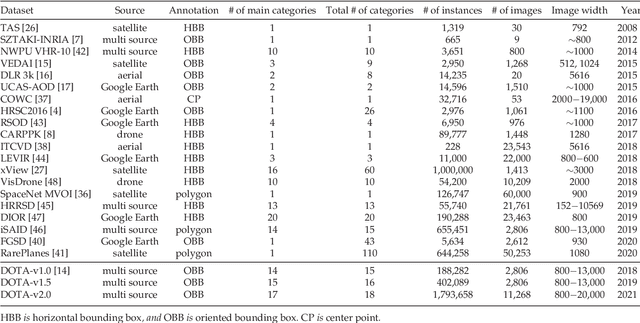
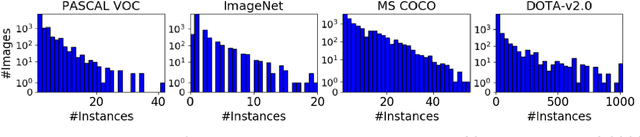
In the past decade, object detection has achieved significant progress in natural images but not in aerial images, due to the massive variations in the scale and orientation of objects caused by the bird's-eye view of aerial images. More importantly, the lack of large-scale benchmarks becomes a major obstacle to the development of object detection in aerial images (ODAI). In this paper, we present a large-scale Dataset of Object deTection in Aerial images (DOTA) and comprehensive baselines for ODAI. The proposed DOTA dataset contains 1,793,658 object instances of 18 categories of oriented-bounding-box annotations collected from 11,268 aerial images. Based on this large-scale and well-annotated dataset, we build baselines covering 10 state-of-the-art algorithms with over 70 configurations, where the speed and accuracy performances of each model have been evaluated. Furthermore, we provide a uniform code library for ODAI and build a website for testing and evaluating different algorithms. Previous challenges run on DOTA have attracted more than 1300 teams worldwide. We believe that the expanded large-scale DOTA dataset, the extensive baselines, the code library and the challenges can facilitate the designs of robust algorithms and reproducible research on the problem of object detection in aerial images.
Long time-series NDVI reconstruction in cloud-prone regions via spatio-temporal tensor completion
Feb 04, 2021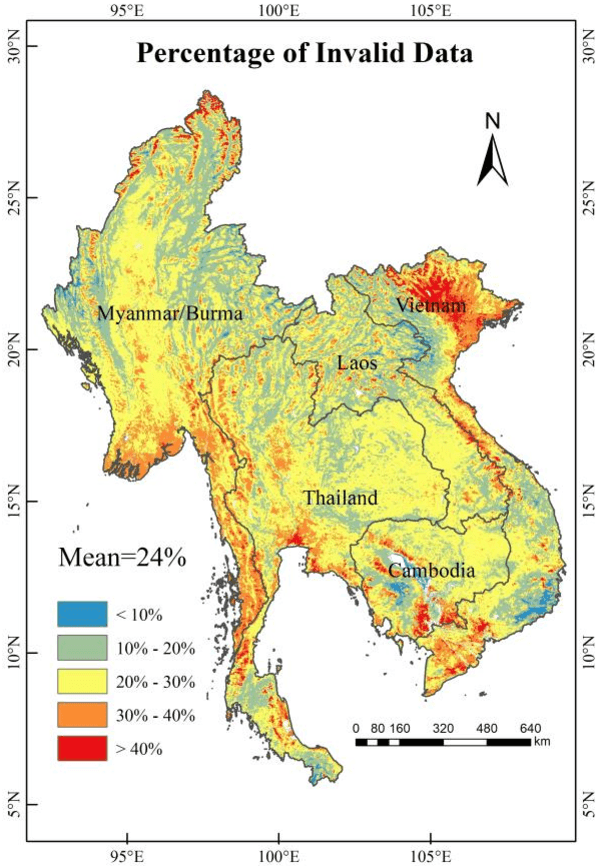

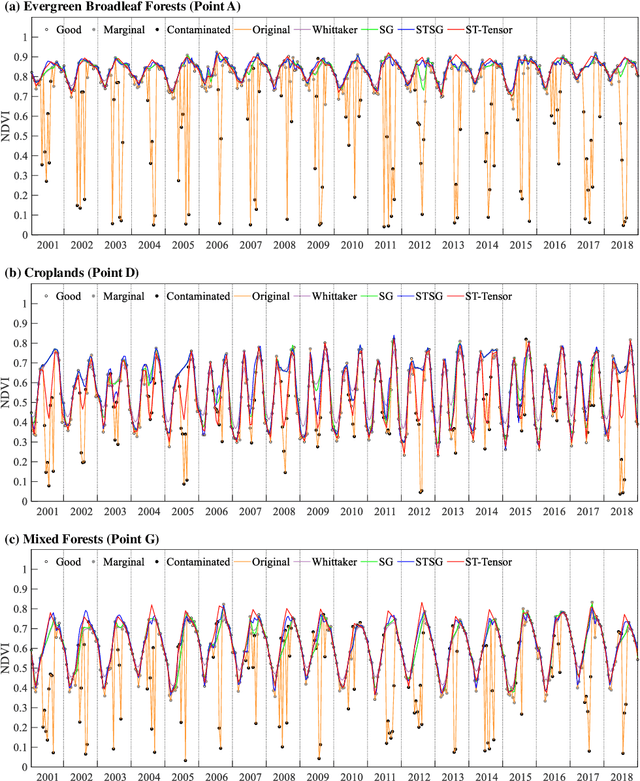
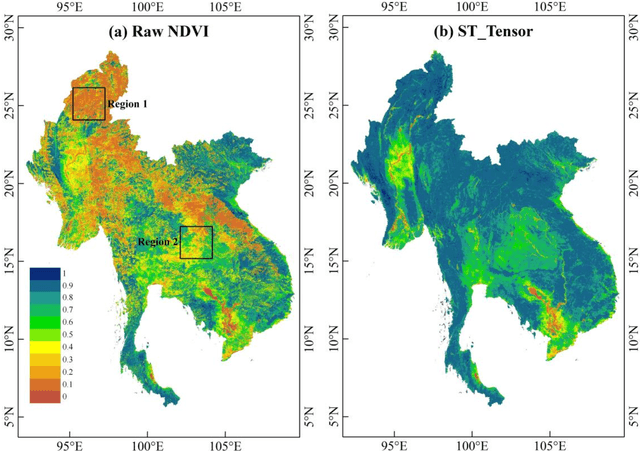
The applications of Normalized Difference Vegetation Index (NDVI) time-series data are inevitably hampered by cloud-induced gaps and noise. Although numerous reconstruction methods have been developed, they have not effectively addressed the issues associated with large gaps in the time series over cloudy and rainy regions, due to the insufficient utilization of the spatial and temporal correlations. In this paper, an adaptive Spatio-Temporal Tensor Completion method (termed ST-Tensor) method is proposed to reconstruct long-term NDVI time series in cloud-prone regions, by making full use of the multi-dimensional spatio-temporal information simultaneously. For this purpose, a highly-correlated tensor is built by considering the correlations among the spatial neighbors, inter-annual variations, and periodic characteristics, in order to reconstruct the missing information via an adaptive-weighted low-rank tensor completion model. An iterative l1 trend filtering method is then implemented to eliminate the residual temporal noise. This new method was tested using MODIS 16-day composite NDVI products from 2001 to 2018 obtained in the region of Mainland Southeast Asia, where the rainy climate commonly induces large gaps and noise in the data. The qualitative and quantitative results indicate that the ST-Tensor method is more effective than the five previous methods in addressing the different missing data problems, especially the temporally continuous gaps and spatio-temporally continuous gaps. It is also shown that the ST-Tensor method performs better than the other methods in tracking NDVI seasonal trajectories, and is therefore a superior option for generating high-quality long-term NDVI time series for cloud-prone regions.