 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeView-Invariant, Occlusion-Robust Probabilistic Embedding for Human Pose
Oct 23, 2020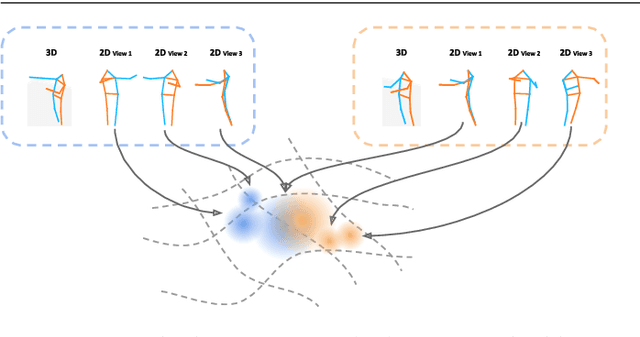
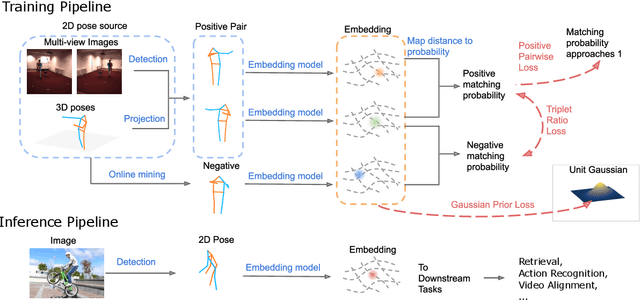

Recognition of human poses and activities is crucial for autonomous systems to interact smoothly with people. However, cameras generally capture human poses in 2D as images and videos, which can have significant appearance variations across viewpoints. To address this, we explore recognizing similarity in 3D human body poses from 2D information, which has not been well-studied in existing works. Here, we propose an approach to learning a compact view-invariant embedding space from 2D body joint keypoints, without explicitly predicting 3D poses. Input ambiguities of 2D poses from projection and occlusion are difficult to represent through a deterministic mapping, and therefore we use probabilistic embeddings. In order to enable our embeddings to work with partially visible input keypoints, we further investigate different keypoint occlusion augmentation strategies during training. Experimental results show that our embedding model achieves higher accuracy when retrieving similar poses across different camera views, in comparison with 3D pose estimation models. We further show that keypoint occlusion augmentation during training significantly improves retrieval performance on partial 2D input poses. Results on action recognition and video alignment demonstrate that our embeddings, without any additional training, achieves competitive performance relative to other models specifically trained for each task.
DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution
Jun 03, 2020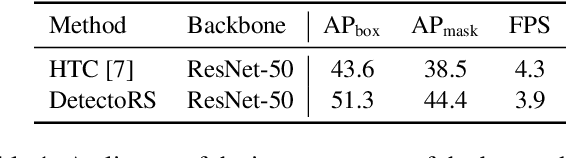
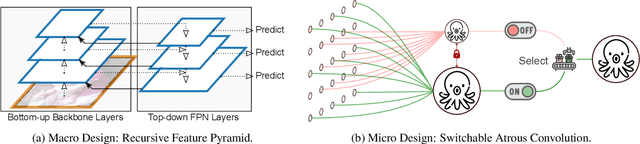
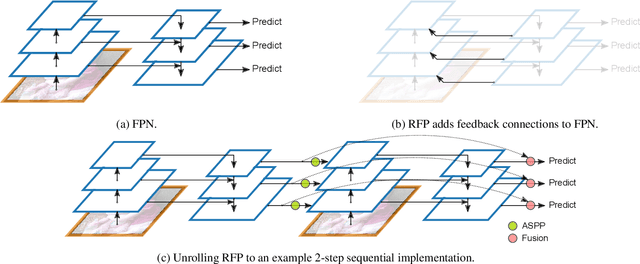

Many modern object detectors demonstrate outstanding performances by using the mechanism of looking and thinking twice. In this paper, we explore this mechanism in the backbone design for object detection. At the macro level, we propose Recursive Feature Pyramid, which incorporates extra feedback connections from Feature Pyramid Networks into the bottom-up backbone layers. At the micro level, we propose Switchable Atrous Convolution, which convolves the features with different atrous rates and gathers the results using switch functions. Combining them results in DetectoRS, which significantly improves the performances of object detection. On COCO test-dev, DetectoRS achieves state-of-the-art 54.7% box AP for object detection, 47.1% mask AP for instance segmentation, and 49.6% PQ for panoptic segmentation. The code is made publicly available.
Leveraging Semi-Supervised Learning in Video Sequences for Urban Scene Segmentation
May 22, 2020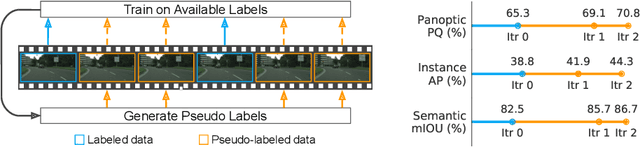

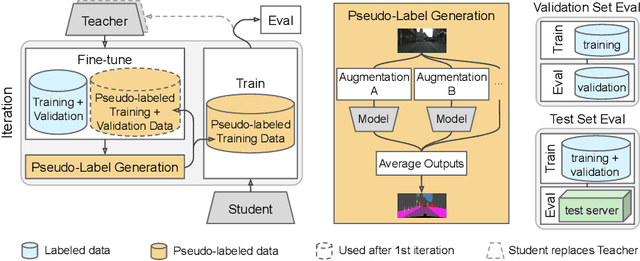
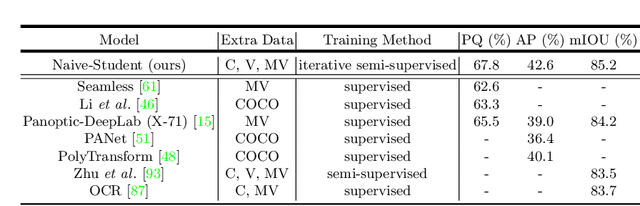
Supervised learning in large discriminative models is a mainstay for modern computer vision. Such an approach necessitates investing in large-scale human-annotated datasets for achieving state-of-the-art results. In turn, the efficacy of supervised learning may be limited by the size of the human annotated dataset. This limitation is particularly notable for image segmentation tasks, where the expense of human annotation is especially large, yet large amounts of unlabeled data may exist. In this work, we ask if we may leverage semi-supervised learning in unlabeled video sequences to improve the performance on urban scene segmentation, simultaneously tackling semantic, instance, and panoptic segmentation. The goal of this work is to avoid the construction of sophisticated, learned architectures specific to label propagation (e.g., patch matching and optical flow). Instead, we simply predict pseudo-labels for the unlabeled data and train subsequent models with both human-annotated and pseudo-labeled data. The procedure is iterated for several times. As a result, our Naive-Student model, trained with such simple yet effective iterative semi-supervised learning, attains state-of-the-art results at all three Cityscapes benchmarks, reaching the performance of 67.8% PQ, 42.6% AP, and 85.2% mIOU on the test set. We view this work as a notable step towards building a simple procedure to harness unlabeled video sequences to surpass state-of-the-art performance on core computer vision tasks.
Axial-DeepLab: Stand-Alone Axial-Attention for Panoptic Segmentation
Mar 17, 2020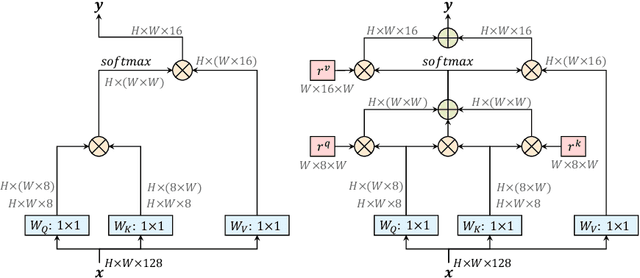
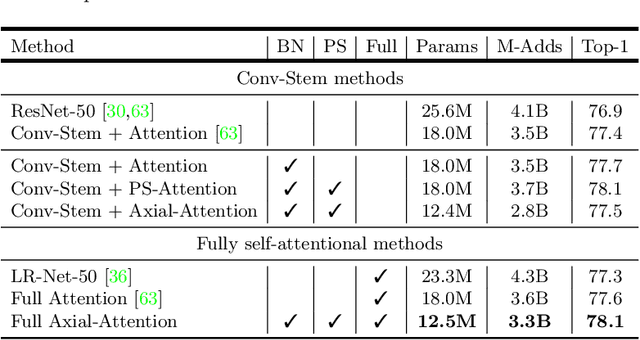
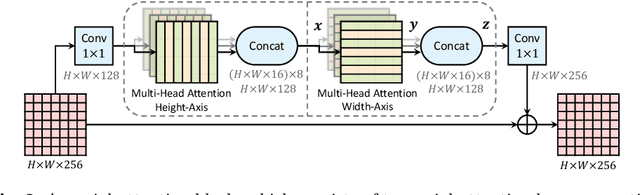
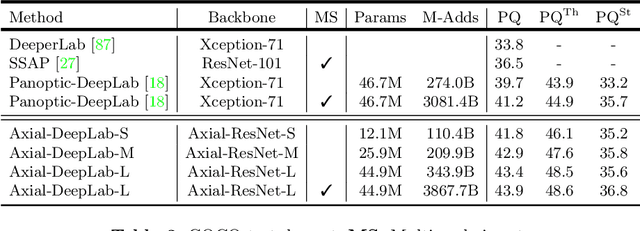
Convolution exploits locality for efficiency at a cost of missing long range context. Self-attention has been adopted to augment CNNs with non-local interactions. Recent works prove it possible to stack self-attention layers to obtain a fully attentional network by restricting the attention to a local region. In this paper, we attempt to remove this constraint by factorizing 2D self-attention into two 1D self-attentions. This reduces computation complexity and allows performing attention within a larger or even global region. In companion, we also propose a position-sensitive self-attention design. Combining both yields our position-sensitive axial-attention layer, a novel building block that one could stack to form axial-attention models for image classification and dense prediction. We demonstrate the effectiveness of our model on four large-scale datasets. In particular, our model outperforms all existing stand-alone self-attention models on ImageNet. Our Axial-DeepLab improves 2.8% PQ over bottom-up state-of-the-art on COCO test-dev. This previous state-of-the-art is attained by our small variant that is 3.8x parameter-efficient and 27x computation-efficient. Axial-DeepLab also achieves state-of-the-art results on Mapillary Vistas and Cityscapes.
Panoptic-DeepLab: A Simple, Strong, and Fast Baseline for Bottom-Up Panoptic Segmentation
Dec 06, 2019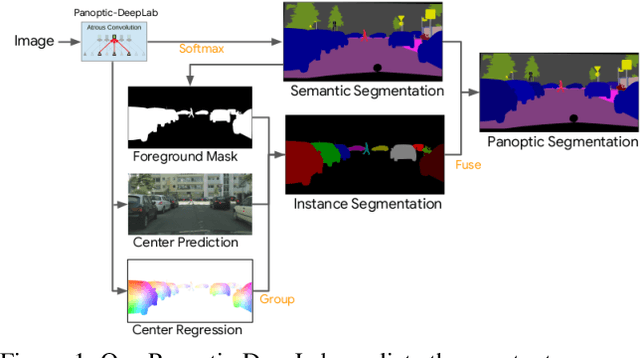

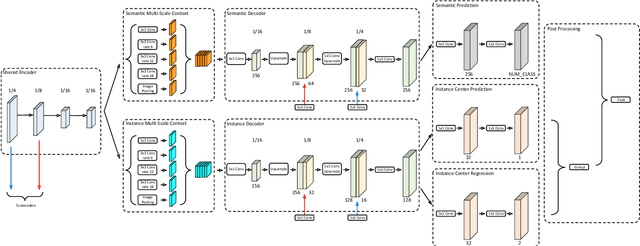
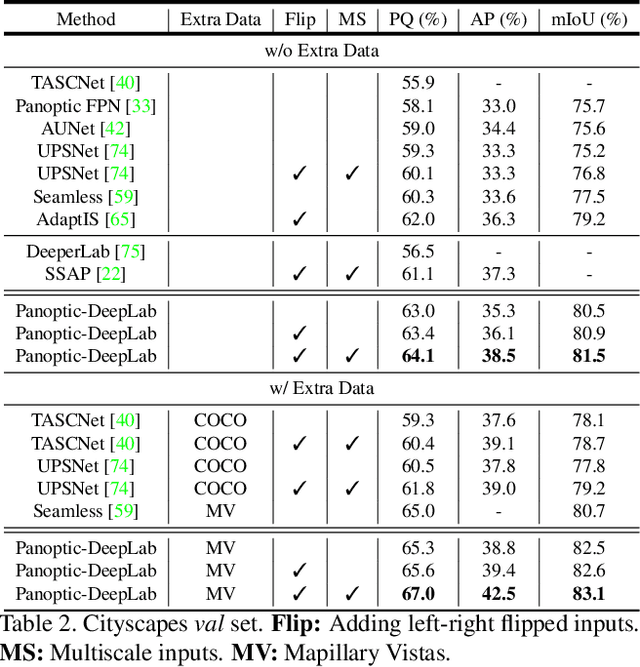
In this work, we introduce Panoptic-DeepLab, a simple, strong, and fast system for panoptic segmentation, aiming to establish a solid baseline for bottom-up methods that can achieve comparable performance of two-stage methods while yielding fast inference speed. In particular, PanopticDeepLab adopts the dual-ASPP and dual-decoder structures specific to semantic, and instance segmentation, respectively. The semantic segmentation branch is the same as the typical design of any semantic segmentation model (e.g., DeepLab), while the instance segmentation branch is class-agnostic, involving a simple instance center regression. As a result, our single Panoptic-DeepLab simultaneously ranks first at all three Cityscapes benchmarks, setting the new state-of-art of 84.2% mIoU, 39.0% AP, and 65.5% PQ on test set. Additionally, equipped with MobileNetV3, Panoptic-DeepLab runs nearly in real-time with a single 1025 x 2049 image (15.8 frames per second), while achieving a competitive performance on Cityscapes (54.1 PQ% on test set). On Mapillary Vistas test set, our ensemble of six models attains 42.7% PQ, outperforming the challenge winner in 2018 by a healthy margin of 1.5%. Finally, our Panoptic-DeepLab also performs on par with several topdown approaches on the challenging COCO dataset. For the first time, we demonstrate a bottom-up approach could deliver state-of-the-art results on panoptic segmentation.
View-Invariant Probabilistic Embedding for Human Pose
Dec 02, 2019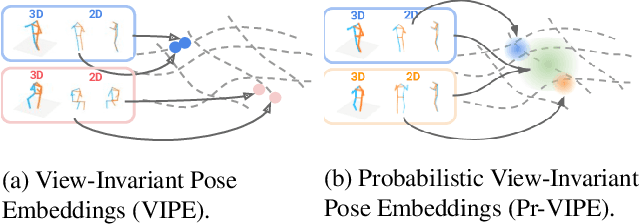
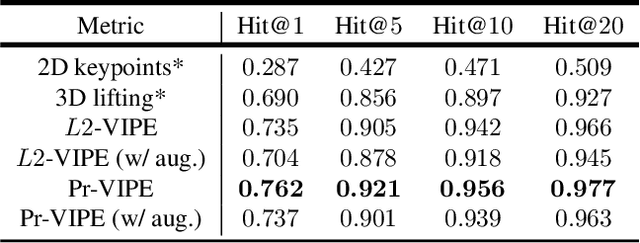
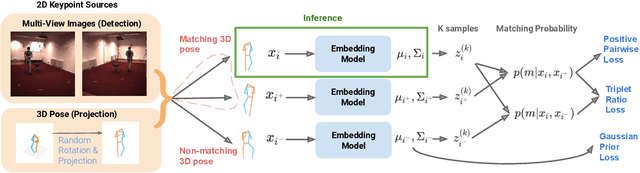
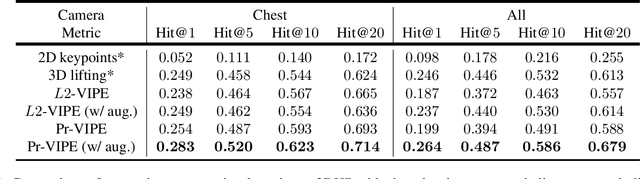
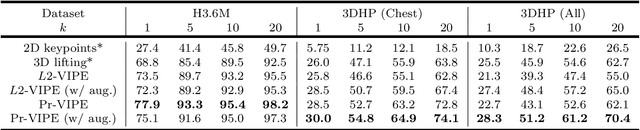
Depictions of similar human body configurations can vary with changing viewpoints. Using only 2D information, we would like to enable vision algorithms to recognize similarity in human body poses across multiple views. This ability is useful for analyzing body movements and human behaviors in images and videos. In this paper, we propose an approach for learning a compact view-invariant embedding space from 2D joint keypoints alone, without explicitly predicting 3D poses. Since 2D poses are projected from 3D space, they have an inherent ambiguity, which is difficult to represent through a deterministic mapping. Hence, we use probabilistic embeddings to model this input uncertainty. Experimental results show that our embedding model achieves higher accuracy when retrieving similar poses across different camera views, in comparison with 2D-to-3D pose lifting models. The results also suggest that our model is able to generalize across datasets, and our embedding variance correlates with input pose ambiguity.
SegSort: Segmentation by Discriminative Sorting of Segments
Oct 30, 2019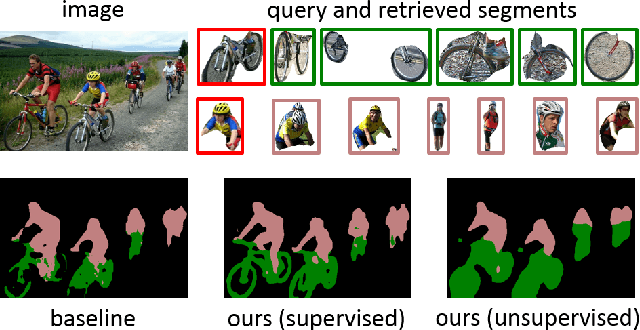
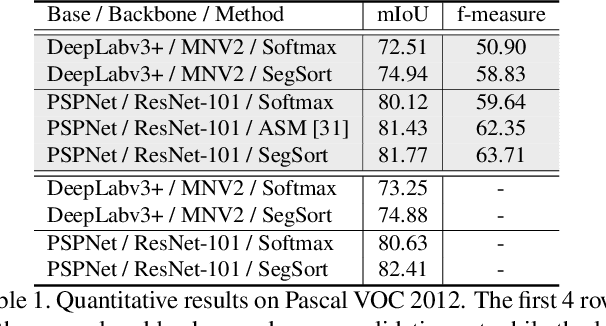
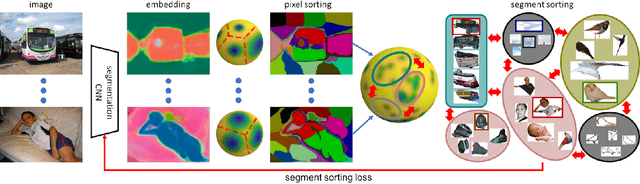
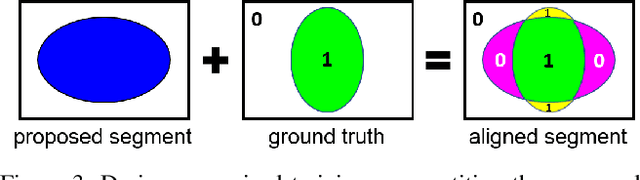
Almost all existing deep learning approaches for semantic segmentation tackle this task as a pixel-wise classification problem. Yet humans understand a scene not in terms of pixels, but by decomposing it into perceptual groups and structures that are the basic building blocks of recognition. This motivates us to propose an end-to-end pixel-wise metric learning approach that mimics this process. In our approach, the optimal visual representation determines the right segmentation within individual images and associates segments with the same semantic classes across images. The core visual learning problem is therefore to maximize the similarity within segments and minimize the similarity between segments. Given a model trained this way, inference is performed consistently by extracting pixel-wise embeddings and clustering, with the semantic label determined by the majority vote of its nearest neighbors from an annotated set. As a result, we present the SegSort, as a first attempt using deep learning for unsupervised semantic segmentation, achieving $76\%$ performance of its supervised counterpart. When supervision is available, SegSort shows consistent improvements over conventional approaches based on pixel-wise softmax training. Additionally, our approach produces more precise boundaries and consistent region predictions. The proposed SegSort further produces an interpretable result, as each choice of label can be easily understood from the retrieved nearest segments.
Panoptic-DeepLab
Oct 24, 2019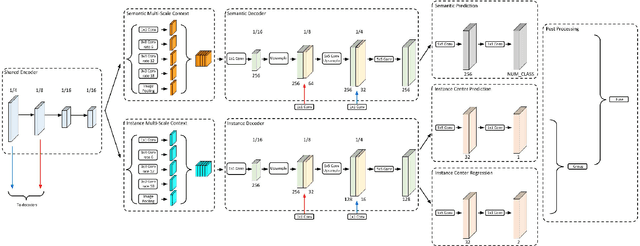
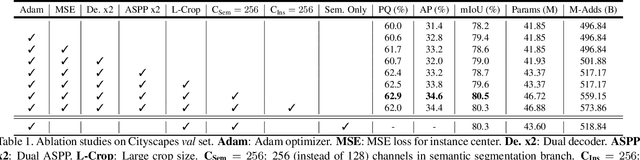
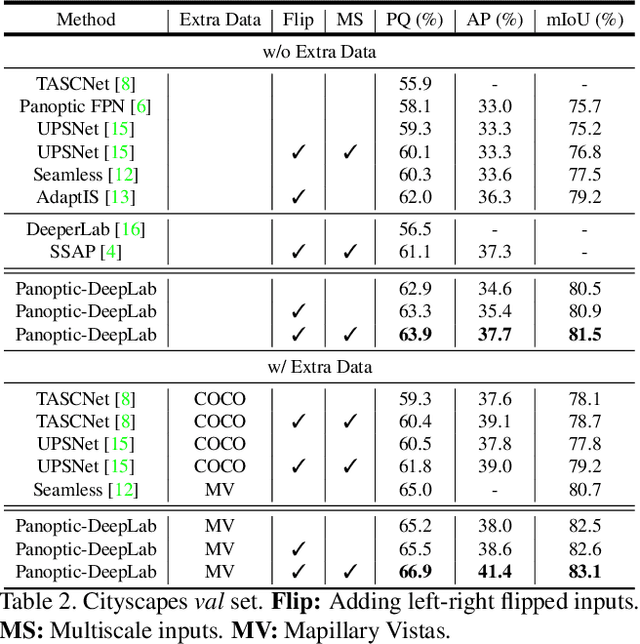
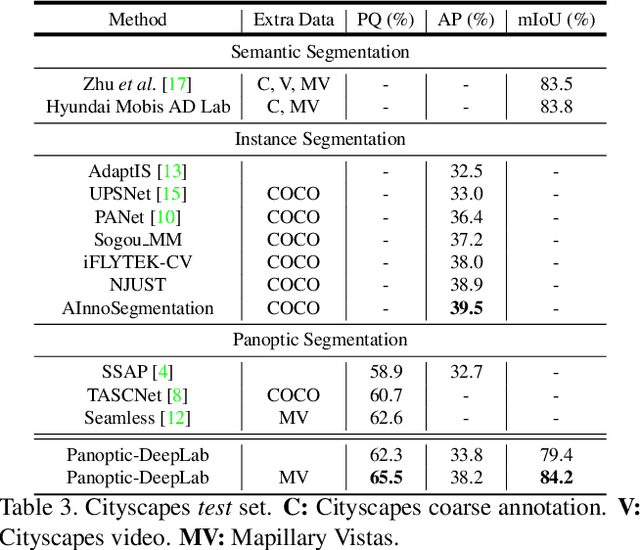
We present Panoptic-DeepLab, a bottom-up and single-shot approach for panoptic segmentation. Our Panoptic-DeepLab is conceptually simple and delivers state-of-the-art results. In particular, we adopt the dual-ASPP and dual-decoder structures specific to semantic, and instance segmentation, respectively. The semantic segmentation branch is the same as the typical design of any semantic segmentation model (e.g., DeepLab), while the instance segmentation branch is class-agnostic, involving a simple instance center regression. Our single Panoptic-DeepLab sets the new state-of-art at all three Cityscapes benchmarks, reaching 84.2% mIoU, 39.0% AP, and 65.5% PQ on test set, and advances results on the other challenging Mapillary Vistas.
SPGNet: Semantic Prediction Guidance for Scene Parsing
Aug 26, 2019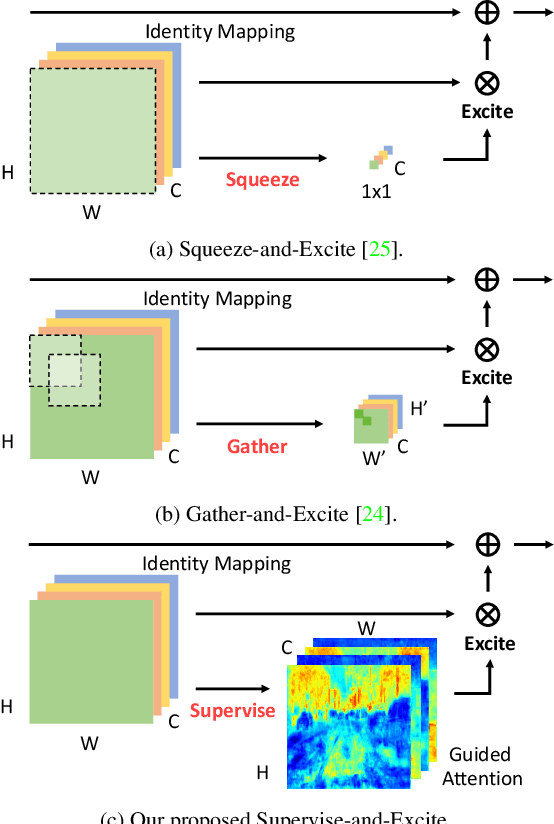
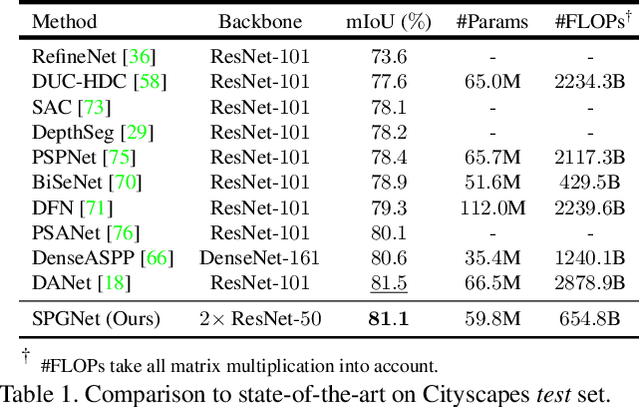
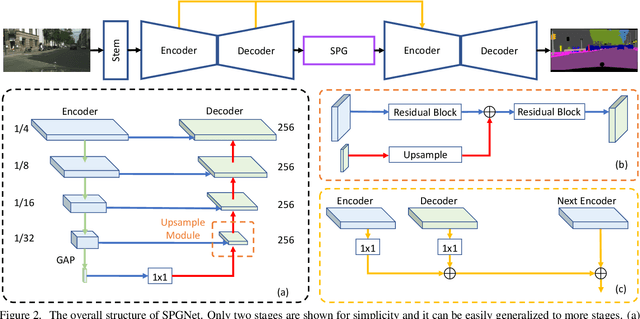

Multi-scale context module and single-stage encoder-decoder structure are commonly employed for semantic segmentation. The multi-scale context module refers to the operations to aggregate feature responses from a large spatial extent, while the single-stage encoder-decoder structure encodes the high-level semantic information in the encoder path and recovers the boundary information in the decoder path. In contrast, multi-stage encoder-decoder networks have been widely used in human pose estimation and show superior performance than their single-stage counterpart. However, few efforts have been attempted to bring this effective design to semantic segmentation. In this work, we propose a Semantic Prediction Guidance (SPG) module which learns to re-weight the local features through the guidance from pixel-wise semantic prediction. We find that by carefully re-weighting features across stages, a two-stage encoder-decoder network coupled with our proposed SPG module can significantly outperform its one-stage counterpart with similar parameters and computations. Finally, we report experimental results on the semantic segmentation benchmark Cityscapes, in which our SPGNet attains 81.1% on the test set using only 'fine' annotations.
Searching for MobileNetV3
May 14, 2019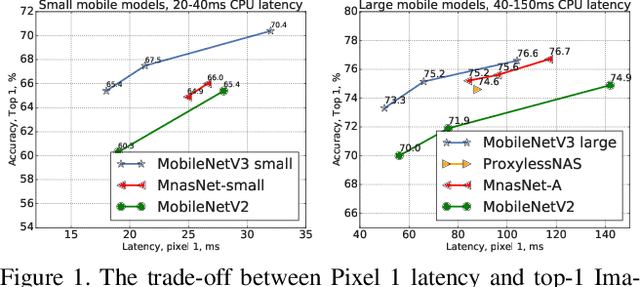
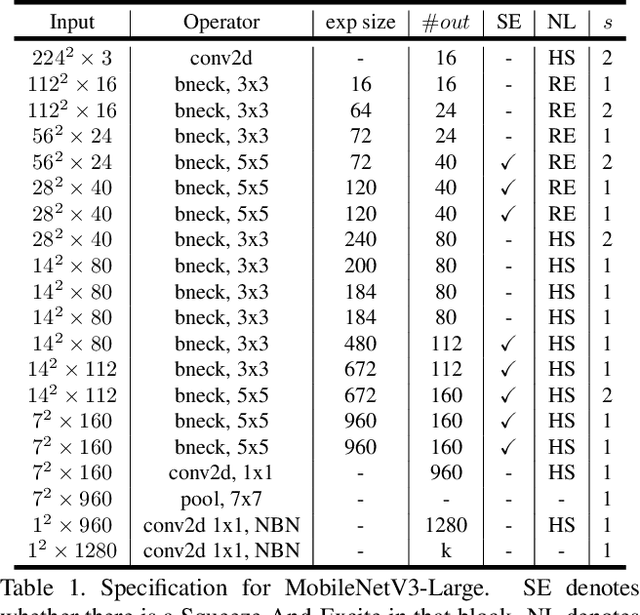
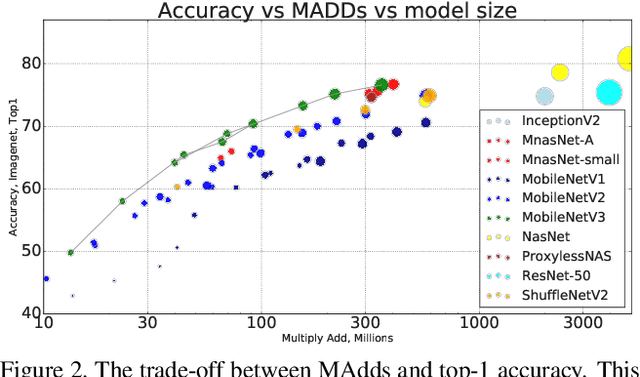
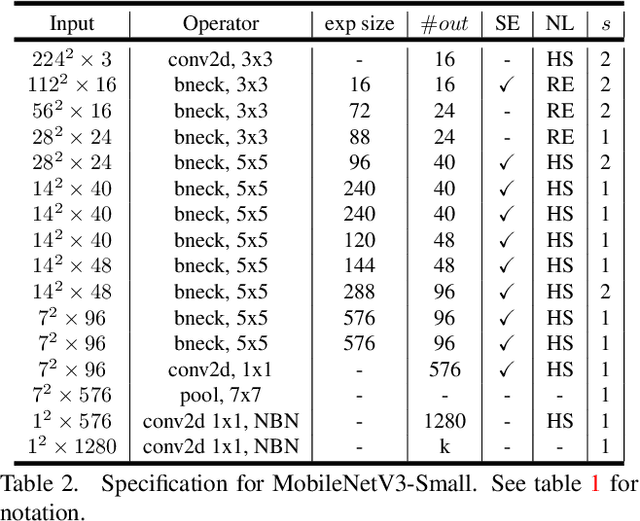
We present the next generation of MobileNets based on a combination of complementary search techniques as well as a novel architecture design. MobileNetV3 is tuned to mobile phone CPUs through a combination of hardware aware network architecture search (NAS) complemented by the NetAdapt algorithm and then subsequently improved through novel architecture advances. This paper starts the exploration of how automated search algorithms and network design can work together to harness complementary approaches improving the overall state of the art. Through this process we create two new MobileNet models for release: MobileNetV3-Large and MobileNetV3-Small which are targeted for high and low resource use cases. These models are then adapted and applied to the tasks of object detection and semantic segmentation. For the task of semantic segmentation (or any dense pixel prediction), we propose a new efficient segmentation decoder Lite Reduced Atrous Spatial Pyramid Pooling (LR-ASPP). We achieve new state of the art results for mobile classification, detection and segmentation. MobileNetV3-Large is 3.2% more accurate on ImageNet classification while reducing latency by 15% compared to MobileNetV2. MobileNetV2-Small is 4.6% more accurate while reducing latency by 5% compared to MobileNetV2. MobileNetV3-Large detection is 25% faster at roughly the same accuracy as MobileNetV2 on COCO detection. MobileNetV3-Large LR-ASPP is 30% faster than MobileNetV2 R-ASPP at similar accuracy for Cityscapes segmentation.