 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerception in Reflection
Apr 09, 2025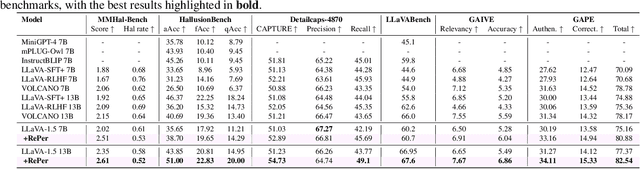


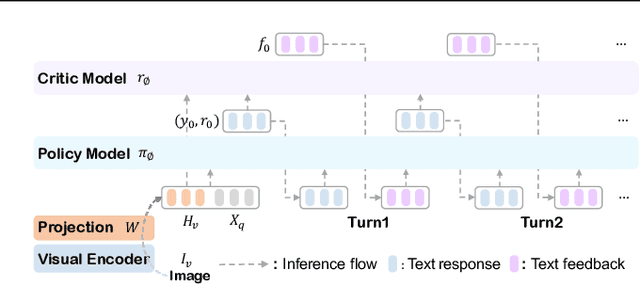
We present a perception in reflection paradigm designed to transcend the limitations of current large vision-language models (LVLMs), which are expected yet often fail to achieve perfect perception initially. Specifically, we propose Reflective Perception (RePer), a dual-model reflection mechanism that systematically alternates between policy and critic models, enables iterative refinement of visual perception. This framework is powered by Reflective Perceptual Learning (RPL), which reinforces intrinsic reflective capabilities through a methodically constructed visual reflection dataset and reflective unlikelihood training. Comprehensive experimental evaluation demonstrates RePer's quantifiable improvements in image understanding, captioning precision, and hallucination reduction. Notably, RePer achieves strong alignment between model attention patterns and human visual focus, while RPL optimizes fine-grained and free-form preference alignment. These advancements establish perception in reflection as a robust paradigm for future multimodal agents, particularly in tasks requiring complex reasoning and multi-step manipulation.
CLICv2: Image Complexity Representation via Content Invariance Contrastive Learning
Mar 09, 2025



Unsupervised image complexity representation often suffers from bias in positive sample selection and sensitivity to image content. We propose CLICv2, a contrastive learning framework that enforces content invariance for complexity representation. Unlike CLIC, which generates positive samples via cropping-introducing positive pairs bias-our shifted patchify method applies randomized directional shifts to image patches before contrastive learning. Patches at corresponding positions serve as positive pairs, ensuring content-invariant learning. Additionally, we propose patch-wise contrastive loss, which enhances local complexity representation while mitigating content interference. In order to further suppress the interference of image content, we introduce Masked Image Modeling as an auxiliary task, but we set its modeling objective as the entropy of masked patches, which recovers the entropy of the overall image by using the information of the unmasked patches, and then obtains the global complexity perception ability. Extensive experiments on IC9600 demonstrate that CLICv2 significantly outperforms existing unsupervised methods in PCC and SRCC, achieving content-invariant complexity representation without introducing positive pairs bias.
AutoTestForge: A Multidimensional Automated Testing Framework for Natural Language Processing Models
Mar 07, 2025



In recent years, the application of behavioral testing in Natural Language Processing (NLP) model evaluation has experienced a remarkable and substantial growth. However, the existing methods continue to be restricted by the requirements for manual labor and the limited scope of capability assessment. To address these limitations, we introduce AutoTestForge, an automated and multidimensional testing framework for NLP models in this paper. Within AutoTestForge, through the utilization of Large Language Models (LLMs) to automatically generate test templates and instantiate them, manual involvement is significantly reduced. Additionally, a mechanism for the validation of test case labels based on differential testing is implemented which makes use of a multi-model voting system to guarantee the quality of test cases. The framework also extends the test suite across three dimensions, taxonomy, fairness, and robustness, offering a comprehensive evaluation of the capabilities of NLP models. This expansion enables a more in-depth and thorough assessment of the models, providing valuable insights into their strengths and weaknesses. A comprehensive evaluation across sentiment analysis (SA) and semantic textual similarity (STS) tasks demonstrates that AutoTestForge consistently outperforms existing datasets and testing tools, achieving higher error detection rates (an average of $30.89\%$ for SA and $34.58\%$ for STS). Moreover, different generation strategies exhibit stable effectiveness, with error detection rates ranging from $29.03\% - 36.82\%$.
From Hypothesis to Publication: A Comprehensive Survey of AI-Driven Research Support Systems
Mar 03, 2025



Research is a fundamental process driving the advancement of human civilization, yet it demands substantial time and effort from researchers. In recent years, the rapid development of artificial intelligence (AI) technologies has inspired researchers to explore how AI can accelerate and enhance research. To monitor relevant advancements, this paper presents a systematic review of the progress in this domain. Specifically, we organize the relevant studies into three main categories: hypothesis formulation, hypothesis validation, and manuscript publication. Hypothesis formulation involves knowledge synthesis and hypothesis generation. Hypothesis validation includes the verification of scientific claims, theorem proving, and experiment validation. Manuscript publication encompasses manuscript writing and the peer review process. Furthermore, we identify and discuss the current challenges faced in these areas, as well as potential future directions for research. Finally, we also offer a comprehensive overview of existing benchmarks and tools across various domains that support the integration of AI into the research process. We hope this paper serves as an introduction for beginners and fosters future research. Resources have been made publicly available at https://github.com/zkzhou126/AI-for-Research.
Network Tomography with Path-Centric Graph Neural Network
Feb 23, 2025



Network tomography is a crucial problem in network monitoring, where the observable path performance metric values are used to infer the unobserved ones, making it essential for tasks such as route selection, fault diagnosis, and traffic control. However, most existing methods either assume complete knowledge of network topology and metric formulas-an unrealistic expectation in many real-world scenarios with limited observability-or rely entirely on black-box end-to-end models. To tackle this, in this paper, we argue that a good network tomography requires synergizing the knowledge from both data and appropriate inductive bias from (partial) prior knowledge. To see this, we propose Deep Network Tomography (DeepNT), a novel framework that leverages a path-centric graph neural network to predict path performance metrics without relying on predefined hand-crafted metrics, assumptions, or the real network topology. The path-centric graph neural network learns the path embedding by inferring and aggregating the embeddings of the sequence of nodes that compose this path. Training path-centric graph neural networks requires learning the neural netowrk parameters and network topology under discrete constraints induced by the observed path performance metrics, which motivates us to design a learning objective that imposes connectivity and sparsity constraints on topology and path performance triangle inequality on path performance. Extensive experiments on real-world and synthetic datasets demonstrate the superiority of DeepNT in predicting performance metrics and inferring graph topology compared to state-of-the-art methods.
Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction
Feb 18, 2025Real-time speech interaction, serving as a fundamental interface for human-machine collaboration, holds immense potential. However, current open-source models face limitations such as high costs in voice data collection, weakness in dynamic control, and limited intelligence. To address these challenges, this paper introduces Step-Audio, the first production-ready open-source solution. Key contributions include: 1) a 130B-parameter unified speech-text multi-modal model that achieves unified understanding and generation, with the Step-Audio-Chat version open-sourced; 2) a generative speech data engine that establishes an affordable voice cloning framework and produces the open-sourced lightweight Step-Audio-TTS-3B model through distillation; 3) an instruction-driven fine control system enabling dynamic adjustments across dialects, emotions, singing, and RAP; 4) an enhanced cognitive architecture augmented with tool calling and role-playing abilities to manage complex tasks effectively. Based on our new StepEval-Audio-360 evaluation benchmark, Step-Audio achieves state-of-the-art performance in human evaluations, especially in terms of instruction following. On open-source benchmarks like LLaMA Question, shows 9.3% average performance improvement, demonstrating our commitment to advancing the development of open-source multi-modal language technologies. Our code and models are available at https://github.com/stepfun-ai/Step-Audio.
Unhackable Temporal Rewarding for Scalable Video MLLMs
Feb 17, 2025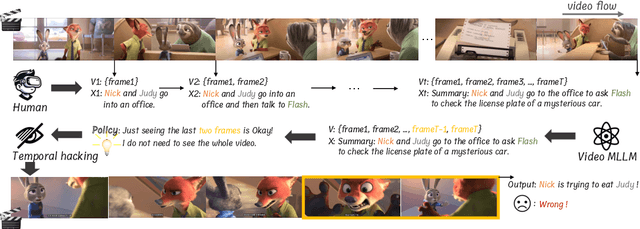
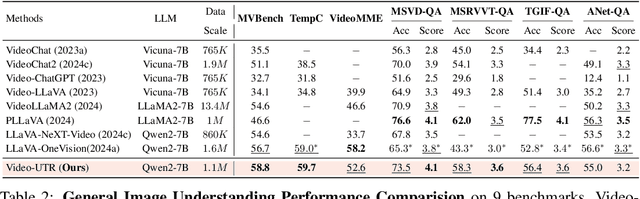
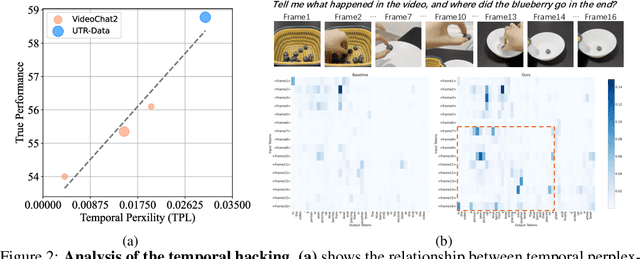

In the pursuit of superior video-processing MLLMs, we have encountered a perplexing paradox: the "anti-scaling law", where more data and larger models lead to worse performance. This study unmasks the culprit: "temporal hacking", a phenomenon where models shortcut by fixating on select frames, missing the full video narrative. In this work, we systematically establish a comprehensive theory of temporal hacking, defining it from a reinforcement learning perspective, introducing the Temporal Perplexity (TPL) score to assess this misalignment, and proposing the Unhackable Temporal Rewarding (UTR) framework to mitigate the temporal hacking. Both theoretically and empirically, TPL proves to be a reliable indicator of temporal modeling quality, correlating strongly with frame activation patterns. Extensive experiments reveal that UTR not only counters temporal hacking but significantly elevates video comprehension capabilities. This work not only advances video-AI systems but also illuminates the critical importance of aligning proxy rewards with true objectives in MLLM development.
Occupancy-SLAM: An Efficient and Robust Algorithm for Simultaneously Optimizing Robot Poses and Occupancy Map
Feb 10, 2025Joint optimization of poses and features has been extensively studied and demonstrated to yield more accurate results in feature-based SLAM problems. However, research on jointly optimizing poses and non-feature-based maps remains limited. Occupancy maps are widely used non-feature-based environment representations because they effectively classify spaces into obstacles, free areas, and unknown regions, providing robots with spatial information for various tasks. In this paper, we propose Occupancy-SLAM, a novel optimization-based SLAM method that enables the joint optimization of robot trajectory and the occupancy map through a parameterized map representation. The key novelty lies in optimizing both robot poses and occupancy values at different cell vertices simultaneously, a significant departure from existing methods where the robot poses need to be optimized first before the map can be estimated. Evaluations using simulations and practical 2D laser datasets demonstrate that the proposed approach can robustly obtain more accurate robot trajectories and occupancy maps than state-of-the-art techniques with comparable computational time. Preliminary results in the 3D case further confirm the potential of the proposed method in practical 3D applications, achieving more accurate results than existing methods.
PerPO: Perceptual Preference Optimization via Discriminative Rewarding
Feb 05, 2025



This paper presents Perceptual Preference Optimization (PerPO), a perception alignment method aimed at addressing the visual discrimination challenges in generative pre-trained multimodal large language models (MLLMs). To align MLLMs with human visual perception process, PerPO employs discriminative rewarding to gather diverse negative samples, followed by listwise preference optimization to rank them.By utilizing the reward as a quantitative margin for ranking, our method effectively bridges generative preference optimization and discriminative empirical risk minimization. PerPO significantly enhances MLLMs' visual discrimination capabilities while maintaining their generative strengths, mitigates image-unconditional reward hacking, and ensures consistent performance across visual tasks. This work marks a crucial step towards more perceptually aligned and versatile MLLMs. We also hope that PerPO will encourage the community to rethink MLLM alignment strategies.
Machine Learning-Driven Student Performance Prediction for Enhancing Tiered Instruction
Feb 05, 2025



Student performance prediction is one of the most important subjects in educational data mining. As a modern technology, machine learning offers powerful capabilities in feature extraction and data modeling, providing essential support for diverse application scenarios, as evidenced by recent studies confirming its effectiveness in educational data mining. However, despite extensive prediction experiments, machine learning methods have not been effectively integrated into practical teaching strategies, hindering their application in modern education. In addition, massive features as input variables for machine learning algorithms often leads to information redundancy, which can negatively impact prediction accuracy. Therefore, how to effectively use machine learning methods to predict student performance and integrate the prediction results with actual teaching scenarios is a worthy research subject. To this end, this study integrates the results of machine learning-based student performance prediction with tiered instruction, aiming to enhance student outcomes in target course, which is significant for the application of educational data mining in contemporary teaching scenarios. Specifically, we collect original educational data and perform feature selection to reduce information redundancy. Then, the performance of five representative machine learning methods is analyzed and discussed with Random Forest showing the best performance. Furthermore, based on the results of the classification of students, tiered instruction is applied accordingly, and different teaching objectives and contents are set for all levels of students. The comparison of teaching outcomes between the control and experimental classes, along with the analysis of questionnaire results, demonstrates the effectiveness of the proposed framework.