 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery Answering via Decentralized Search
Dec 26, 2020

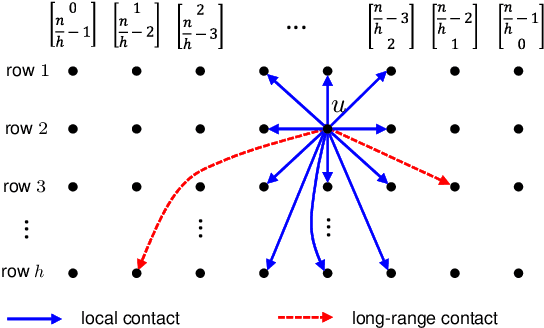
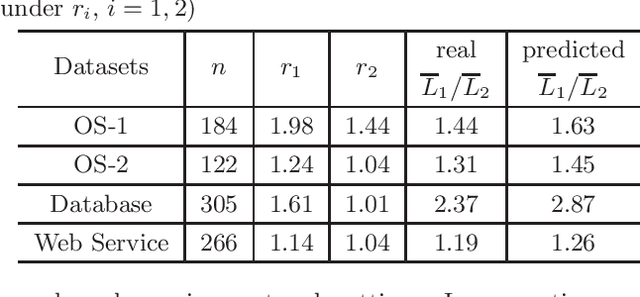
Expert networks are formed by a group of expert-professionals with different specialties to collaboratively resolve specific queries posted to the network. In such networks, when a query reaches an expert who does not have sufficient expertise, this query needs to be routed to other experts for further processing until it is completely solved; therefore, query answering efficiency is sensitive to the underlying query routing mechanism being used. Among all possible query routing mechanisms, decentralized search, operating purely on each expert's local information without any knowledge of network global structure, represents the most basic and scalable routing mechanism, which is applicable to any network scenarios even in dynamic networks. However, there is still a lack of fundamental understanding of the efficiency of decentralized search in expert networks. In this regard, we investigate decentralized search by quantifying its performance under a variety of network settings. Our key findings reveal the existence of network conditions, under which decentralized search can achieve significantly short query routing paths (i.e., between $O(\log n)$ and $O(\log^2 n)$ hops, $n$: total number of experts in the network). Based on such theoretical foundation, we further study how the unique properties of decentralized search in expert networks is related to the anecdotal small-world phenomenon. In addition, we demonstrate that decentralized search is robust against estimation errors introduced by misinterpreting the required expertise levels. To the best of our knowledge, this is the first work studying fundamental behaviors of decentralized search in expert networks. The developed performance bounds, confirmed by real datasets, are able to assist in predicting network performance and designing complex expert networks.
Influence Maximization Under Generic Threshold-based Non-submodular Model
Dec 18, 2020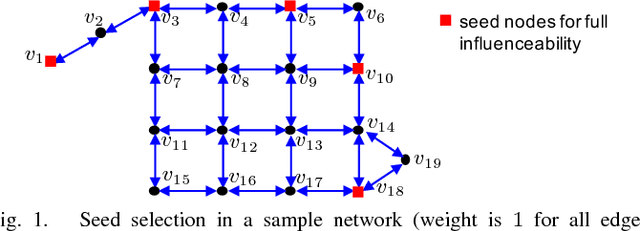
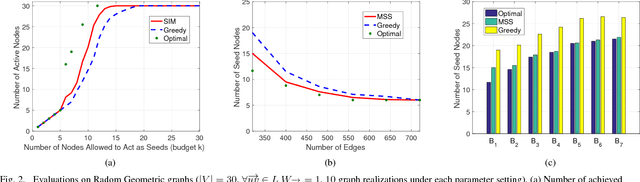
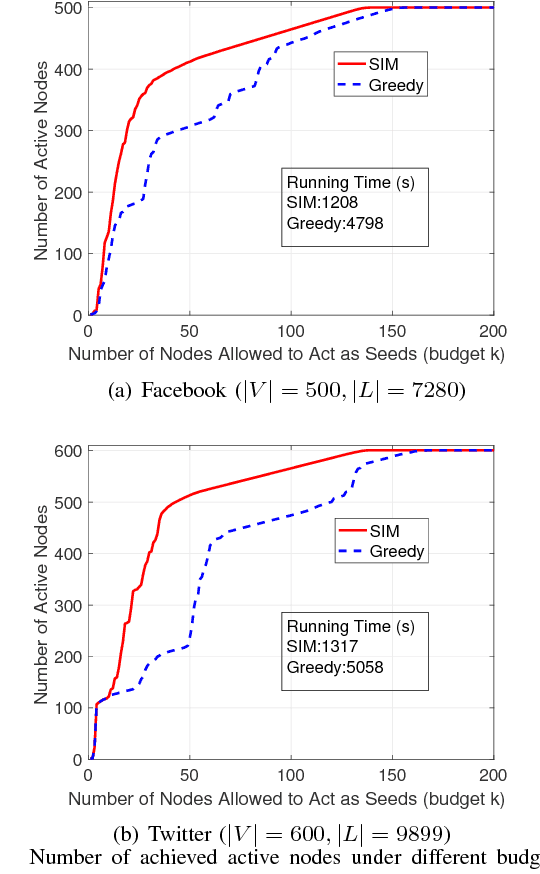
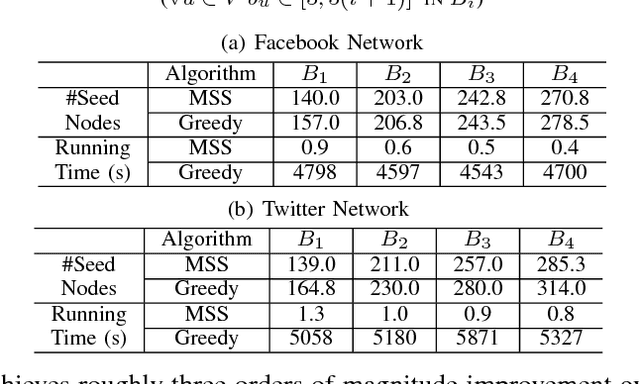
As a widely observable social effect, influence diffusion refers to a process where innovations, trends, awareness, etc. spread across the network via the social impact among individuals. Motivated by such social effect, the concept of influence maximization is coined, where the goal is to select a bounded number of the most influential nodes (seed nodes) from a social network so that they can jointly trigger the maximal influence diffusion. A rich body of research in this area is performed under statistical diffusion models with provable submodularity, which essentially simplifies the problem as the optimal result can be approximated by the simple greedy search. When the diffusion models are non-submodular, however, the research community mostly focuses on how to bound/approximate them by tractable submodular functions so as to estimate the optimal result. In other words, there is still a lack of efficient methods that can directly resolve non-submodular influence maximization problems. In this regard, we fill the gap by proposing seed selection strategies using network graphical properties in a generalized threshold-based model, called influence barricade model, which is non-submodular. Specifically, under this model, we first establish theories to reveal graphical conditions that ensure the network generated by node removals has the same optimal seed set as that in the original network. We then exploit these theoretical conditions to develop efficient algorithms by strategically removing less-important nodes and selecting seeds only in the remaining network. To the best of our knowledge, this is the first graph-based approach that directly tackles non-submodular influence maximization.
Joint State-Action Embedding for Efficient Reinforcement Learning
Oct 12, 2020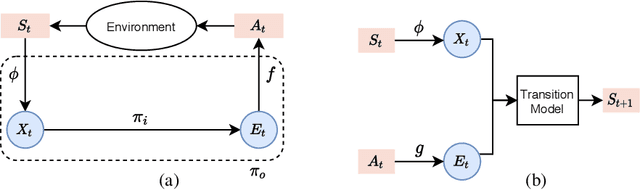
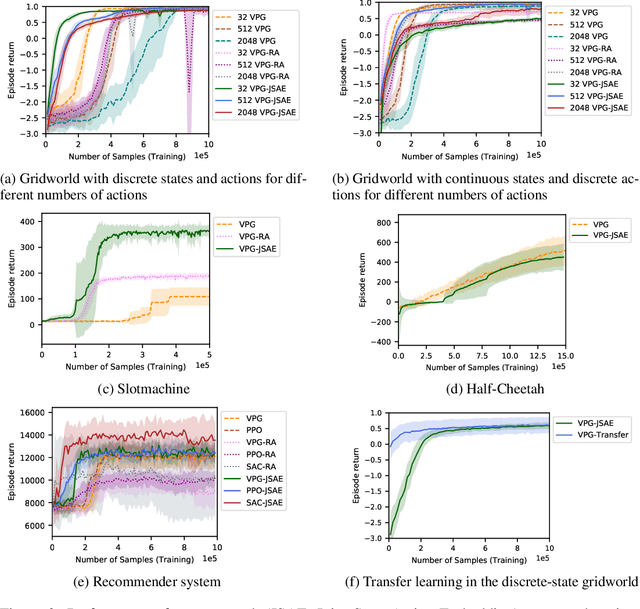
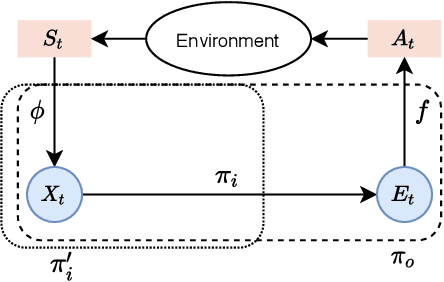
While reinforcement learning has achieved considerable successes in recent years, state-of-the-art models are often still limited by the size of state and action spaces. Model-free reinforcement learning approaches use some form of state representations and the latest work has explored embedding techniques for actions, both with the aim of achieving better generalization and applicability. However, these approaches consider only states or actions, ignoring the interaction between them when generating embedded representations. In this work, we propose a new approach for jointly embedding states and actions that combines aspects of model-free and model-based reinforcement learning, which can be applied in both discrete and continuous domains. Specifically, we use a model of the environment to obtain embeddings for states and actions and present a generic architecture that uses these to learn a policy. In this way, the embedded representations obtained via our approach enable better generalization over both states and actions by capturing similarities in the embedding spaces. Evaluations of our approach on several gaming and recommender system environments show it significantly outperforms state-of-the-art models in discrete domains with large state/action space, thus confirming the efficacy of joint embedding and its overall superior performance.
State Action Separable Reinforcement Learning
Jun 05, 2020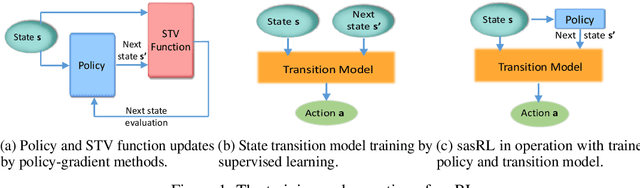
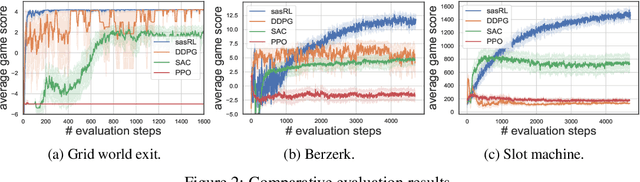
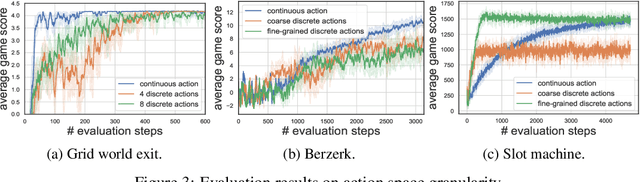
Reinforcement Learning (RL) based methods have seen their paramount successes in solving serial decision-making and control problems in recent years. For conventional RL formulations, Markov Decision Process (MDP) and state-action-value function are the basis for the problem modeling and policy evaluation. However, several challenging issues still remain. Among most cited issues, the enormity of state/action space is an important factor that causes inefficiency in accurately approximating the state-action-value function. We observe that although actions directly define the agents' behaviors, for many problems the next state after a state transition matters more than the action taken, in determining the return of such a state transition. In this regard, we propose a new learning paradigm, State Action Separable Reinforcement Learning (sasRL), wherein the action space is decoupled from the value function learning process for higher efficiency. Then, a light-weight transition model is learned to assist the agent to determine the action that triggers the associated state transition. In addition, our convergence analysis reveals that under certain conditions, the convergence time of sasRL is $O(T^{1/k})$, where $T$ is the convergence time for updating the value function in the MDP-based formulation and $k$ is a weighting factor. Experiments on several gaming scenarios show that sasRL outperforms state-of-the-art MDP-based RL algorithms by up to $75\%$.
IROS 2019 Lifelong Robotic Vision Challenge -- Lifelong Object Recognition Report
Apr 26, 2020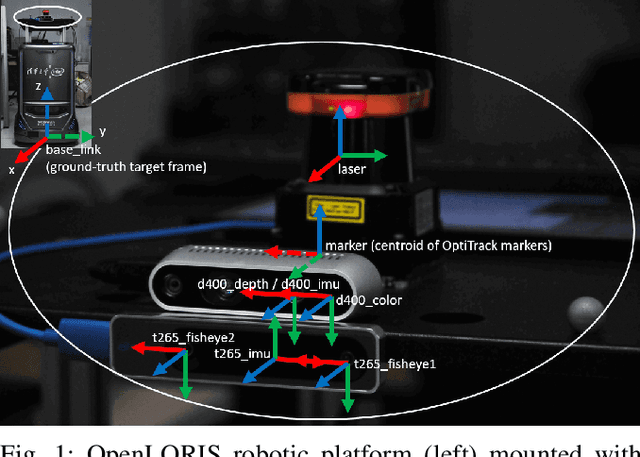
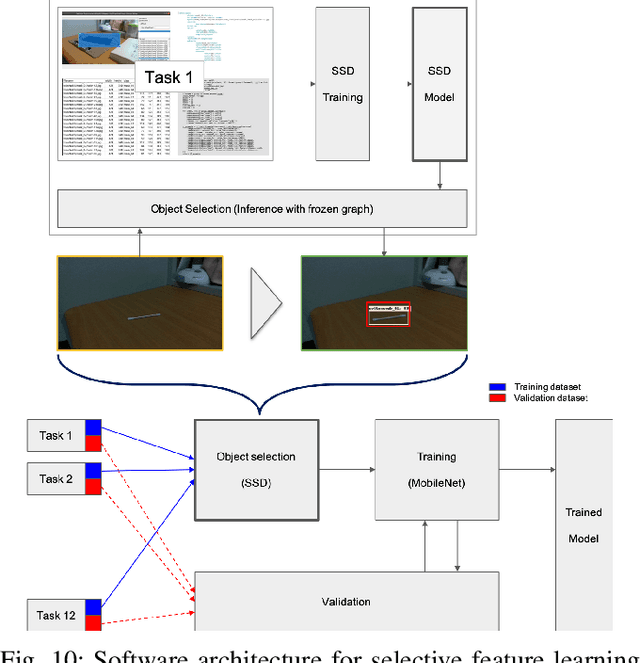


This report summarizes IROS 2019-Lifelong Robotic Vision Competition (Lifelong Object Recognition Challenge) with methods and results from the top $8$ finalists (out of over~$150$ teams). The competition dataset (L)ifel(O)ng (R)obotic V(IS)ion (OpenLORIS) - Object Recognition (OpenLORIS-object) is designed for driving lifelong/continual learning research and application in robotic vision domain, with everyday objects in home, office, campus, and mall scenarios. The dataset explicitly quantifies the variants of illumination, object occlusion, object size, camera-object distance/angles, and clutter information. Rules are designed to quantify the learning capability of the robotic vision system when faced with the objects appearing in the dynamic environments in the contest. Individual reports, dataset information, rules, and released source code can be found at the project homepage: "https://lifelong-robotic-vision.github.io/competition/".
Neural Network Tomography
Jan 09, 2020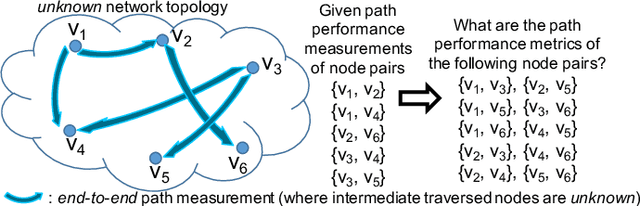
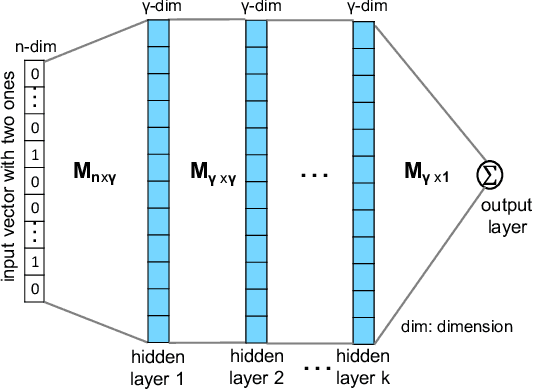
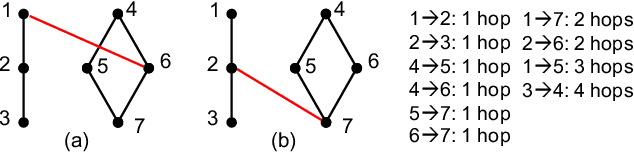
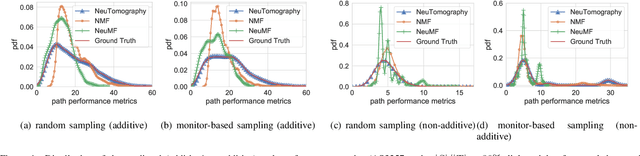
Network tomography, a classic research problem in the realm of network monitoring, refers to the methodology of inferring unmeasured network attributes using selected end-to-end path measurements. In the research community, network tomography is generally investigated under the assumptions of known network topology, correlated path measurements, bounded number of faulty nodes/links, or even special network protocol support. The applicability of network tomography is considerably constrained by these strong assumptions, which therefore frequently position it in the theoretical world. In this regard, we revisit network tomography from the practical perspective by establishing a generic framework that does not rely on any of these assumptions or the types of performance metrics. Given only the end-to-end path performance metrics of sampled node pairs, the proposed framework, NeuTomography, utilizes deep neural network and data augmentation to predict the unmeasured performance metrics via learning non-linear relationships between node pairs and underlying unknown topological/routing properties. In addition, NeuTomography can be employed to reconstruct the original network topology, which is critical to most network planning tasks. Extensive experiments using real network data show that comparing to baseline solutions, NeuTomography can predict network characteristics and reconstruct network topologies with significantly higher accuracy and robustness using only limited measurement data.
Efficient Global String Kernel with Random Features: Beyond Counting Substructures
Nov 25, 2019
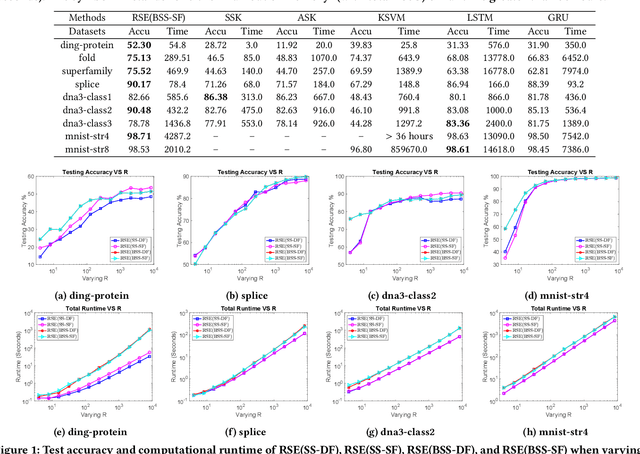
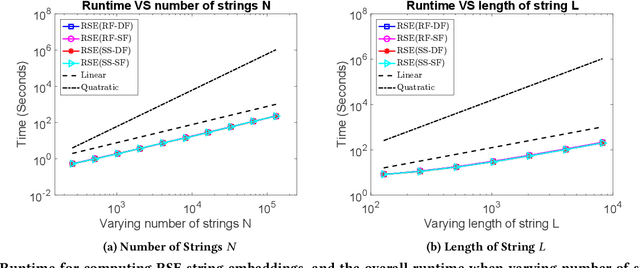
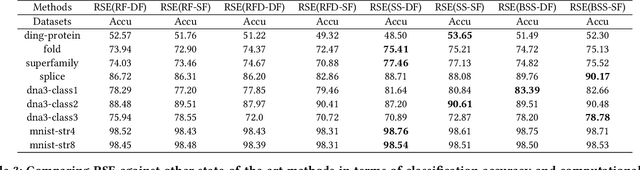
Analysis of large-scale sequential data has been one of the most crucial tasks in areas such as bioinformatics, text, and audio mining. Existing string kernels, however, either (i) rely on local features of short substructures in the string, which hardly capture long discriminative patterns, (ii) sum over too many substructures, such as all possible subsequences, which leads to diagonal dominance of the kernel matrix, or (iii) rely on non-positive-definite similarity measures derived from the edit distance. Furthermore, while there have been works addressing the computational challenge with respect to the length of string, most of them still experience quadratic complexity in terms of the number of training samples when used in a kernel-based classifier. In this paper, we present a new class of global string kernels that aims to (i) discover global properties hidden in the strings through global alignments, (ii) maintain positive-definiteness of the kernel, without introducing a diagonal dominant kernel matrix, and (iii) have a training cost linear with respect to not only the length of the string but also the number of training string samples. To this end, the proposed kernels are explicitly defined through a series of different random feature maps, each corresponding to a distribution of random strings. We show that kernels defined this way are always positive-definite, and exhibit computational benefits as they always produce \emph{Random String Embeddings (RSE)} that can be directly used in any linear classification models. Our extensive experiments on nine benchmark datasets corroborate that RSE achieves better or comparable accuracy in comparison to state-of-the-art baselines, especially with the strings of longer lengths. In addition, we empirically show that RSE scales linearly with the increase of the number and the length of string.
SENSE: Semantically Enhanced Node Sequence Embedding
Nov 07, 2019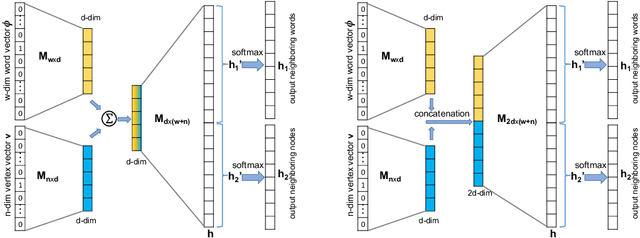
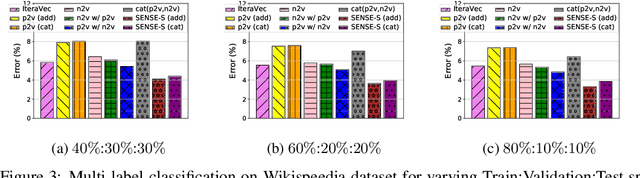
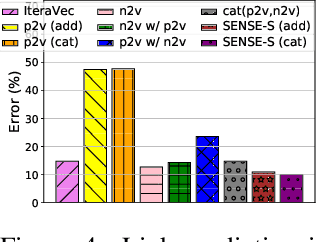
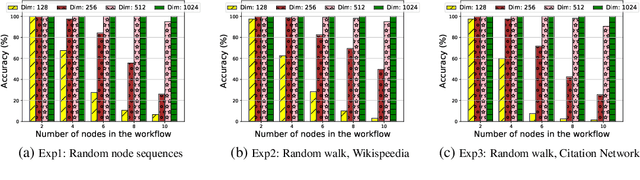
Effectively capturing graph node sequences in the form of vector embeddings is critical to many applications. We achieve this by (i) first learning vector embeddings of single graph nodes and (ii) then composing them to compactly represent node sequences. Specifically, we propose SENSE-S (Semantically Enhanced Node Sequence Embedding - for Single nodes), a skip-gram based novel embedding mechanism, for single graph nodes that co-learns graph structure as well as their textual descriptions. We demonstrate that SENSE-S vectors increase the accuracy of multi-label classification tasks by up to 50% and link-prediction tasks by up to 78% under a variety of scenarios using real datasets. Based on SENSE-S, we next propose generic SENSE to compute composite vectors that represent a sequence of nodes, where preserving the node order is important. We prove that this approach is efficient in embedding node sequences, and our experiments on real data confirm its high accuracy in node order decoding.
MACS: Deep Reinforcement Learning based SDN Controller Synchronization Policy Design
Sep 19, 2019
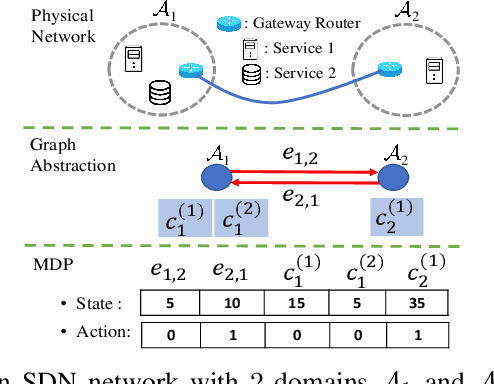
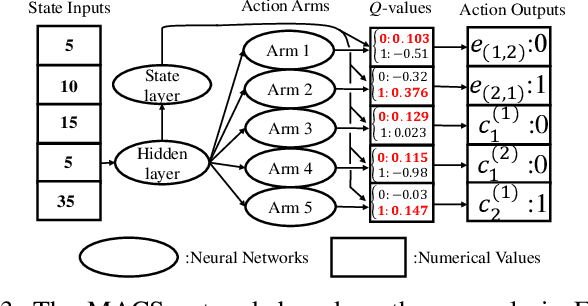
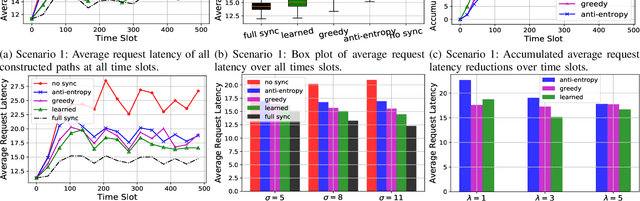
In distributed software-defined networks (SDN), multiple physical SDN controllers, each managing a network domain, are implemented to balance centralised control, scalability, and reliability requirements. In such networking paradigms, controllers synchronize with each other, in attempts to maintain a logically centralised network view. Despite the presence of various design proposals for distributed SDN controller architectures, most existing works only aim at eliminating anomalies arising from the inconsistencies in different controllers' network views. However, the performance aspect of controller synchronization designs with respect to given SDN applications are generally missing. To fill this gap, we formulate the controller synchronization problem as a Markov decision process (MDP) and apply reinforcement learning techniques combined with deep neural networks (DNNs) to train a smart, scalable, and fine-grained controller synchronization policy, called the Multi-Armed Cooperative Synchronization (MACS), whose goal is to maximise the performance enhancements brought by controller synchronizations. Evaluation results confirm the DNN's exceptional ability in abstracting latent patterns in the distributed SDN environment, rendering significant superiority to MACS-based synchronization policy, which are 56% and 30% performance improvements over ONOS and greedy SDN controller synchronization heuristics.
Learning Incremental Triplet Margin for Person Re-identification
Dec 17, 2018

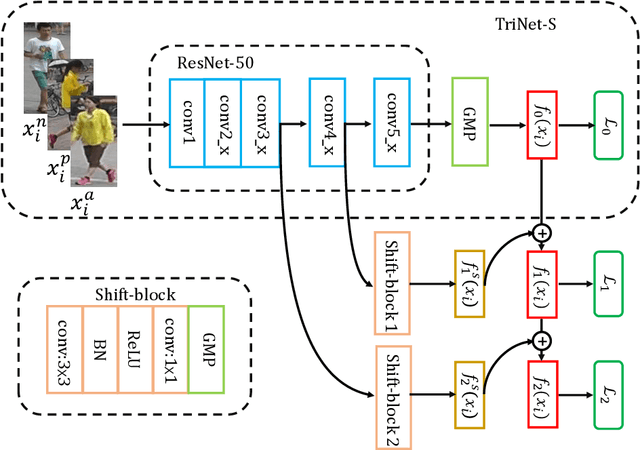

Person re-identification (ReID) aims to match people across multiple non-overlapping video cameras deployed at different locations. To address this challenging problem, many metric learning approaches have been proposed, among which triplet loss is one of the state-of-the-arts. In this work, we explore the margin between positive and negative pairs of triplets and prove that large margin is beneficial. In particular, we propose a novel multi-stage training strategy which learns incremental triplet margin and improves triplet loss effectively. Multiple levels of feature maps are exploited to make the learned features more discriminative. Besides, we introduce global hard identity searching method to sample hard identities when generating a training batch. Extensive experiments on Market-1501, CUHK03, and DukeMTMCreID show that our approach yields a performance boost and outperforms most existing state-of-the-art methods.