 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to See and Act: Task-Aware View Planning for Robotic Manipulation
Aug 07, 2025Recent vision-language-action (VLA) models for multi-task robotic manipulation commonly rely on static viewpoints and shared visual encoders, which limit 3D perception and cause task interference, hindering robustness and generalization. In this work, we propose Task-Aware View Planning (TAVP), a framework designed to overcome these challenges by integrating active view planning with task-specific representation learning. TAVP employs an efficient exploration policy, accelerated by a novel pseudo-environment, to actively acquire informative views. Furthermore, we introduce a Mixture-of-Experts (MoE) visual encoder to disentangle features across different tasks, boosting both representation fidelity and task generalization. By learning to see the world in a task-aware way, TAVP generates more complete and discriminative visual representations, demonstrating significantly enhanced action prediction across a wide array of manipulation challenges. Extensive experiments on RLBench tasks show that our proposed TAVP model achieves superior performance over state-of-the-art fixed-view approaches. Visual results and code are provided at: https://hcplab-sysu.github.io/TAVP.
One Model For All: Partial Diffusion for Unified Try-On and Try-Off in Any Pose
Aug 06, 2025Recent diffusion-based approaches have made significant advances in image-based virtual try-on, enabling more realistic and end-to-end garment synthesis. However, most existing methods remain constrained by their reliance on exhibition garments and segmentation masks, as well as their limited ability to handle flexible pose variations. These limitations reduce their practicality in real-world scenarios-for instance, users cannot easily transfer garments worn by one person onto another, and the generated try-on results are typically restricted to the same pose as the reference image. In this paper, we introduce \textbf{OMFA} (\emph{One Model For All}), a unified diffusion framework for both virtual try-on and try-off that operates without the need for exhibition garments and supports arbitrary poses. For example, OMFA enables removing garments from a source person (try-off) and transferring them onto a target person (try-on), while also allowing the generated target to appear in novel poses-even without access to multi-pose images of that person. OMFA is built upon a novel \emph{partial diffusion} strategy that selectively applies noise and denoising to individual components of the joint input-such as the garment, the person image, or the face-enabling dynamic subtask control and efficient bidirectional garment-person transformation. The framework is entirely mask-free and requires only a single portrait and a target pose as input, making it well-suited for real-world applications. Additionally, by leveraging SMPL-X-based pose conditioning, OMFA supports multi-view and arbitrary-pose try-on from just one image. Extensive experiments demonstrate that OMFA achieves state-of-the-art results on both try-on and try-off tasks, providing a practical and generalizable solution for virtual garment synthesis. The project page is here: https://onemodelforall.github.io/.
Paper Summary Attack: Jailbreaking LLMs through LLM Safety Papers
Jul 17, 2025



The safety of large language models (LLMs) has garnered significant research attention. In this paper, we argue that previous empirical studies demonstrate LLMs exhibit a propensity to trust information from authoritative sources, such as academic papers, implying new possible vulnerabilities. To verify this possibility, a preliminary analysis is designed to illustrate our two findings. Based on this insight, a novel jailbreaking method, Paper Summary Attack (\llmname{PSA}), is proposed. It systematically synthesizes content from either attack-focused or defense-focused LLM safety paper to construct an adversarial prompt template, while strategically infilling harmful query as adversarial payloads within predefined subsections. Extensive experiments show significant vulnerabilities not only in base LLMs, but also in state-of-the-art reasoning model like Deepseek-R1. PSA achieves a 97\% attack success rate (ASR) on well-aligned models like Claude3.5-Sonnet and an even higher 98\% ASR on Deepseek-R1. More intriguingly, our work has further revealed diametrically opposed vulnerability bias across different base models, and even between different versions of the same model, when exposed to either attack-focused or defense-focused papers. This phenomenon potentially indicates future research clues for both adversarial methodologies and safety alignment.Code is available at https://github.com/233liang/Paper-Summary-Attack
One-shot Face Sketch Synthesis in the Wild via Generative Diffusion Prior and Instruction Tuning
Jun 18, 2025



Face sketch synthesis is a technique aimed at converting face photos into sketches. Existing face sketch synthesis research mainly relies on training with numerous photo-sketch sample pairs from existing datasets. However, these large-scale discriminative learning methods will have to face problems such as data scarcity and high human labor costs. Once the training data becomes scarce, their generative performance significantly degrades. In this paper, we propose a one-shot face sketch synthesis method based on diffusion models. We optimize text instructions on a diffusion model using face photo-sketch image pairs. Then, the instructions derived through gradient-based optimization are used for inference. To simulate real-world scenarios more accurately and evaluate method effectiveness more comprehensively, we introduce a new benchmark named One-shot Face Sketch Dataset (OS-Sketch). The benchmark consists of 400 pairs of face photo-sketch images, including sketches with different styles and photos with different backgrounds, ages, sexes, expressions, illumination, etc. For a solid out-of-distribution evaluation, we select only one pair of images for training at each time, with the rest used for inference. Extensive experiments demonstrate that the proposed method can convert various photos into realistic and highly consistent sketches in a one-shot context. Compared to other methods, our approach offers greater convenience and broader applicability. The dataset will be available at: https://github.com/HanWu3125/OS-Sketch
SIRI-Bench: Challenging VLMs' Spatial Intelligence through Complex Reasoning Tasks
Jun 17, 2025
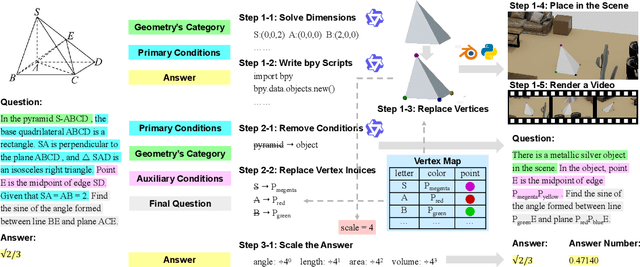


Large Language Models (LLMs) are experiencing rapid advancements in complex reasoning, exhibiting remarkable generalization in mathematics and programming. In contrast, while spatial intelligence is fundamental for Vision-Language Models (VLMs) in real-world interaction, the systematic evaluation of their complex reasoning ability within spatial contexts remains underexplored. To bridge this gap, we introduce SIRI-Bench, a benchmark designed to evaluate VLMs' spatial intelligence through video-based reasoning tasks. SIRI-Bench comprises nearly 1K video-question-answer triplets, where each problem is embedded in a realistic 3D scene and captured by video. By carefully designing questions and corresponding 3D scenes, our benchmark ensures that solving the questions requires both spatial comprehension for extracting information and high-level reasoning for deriving solutions, making it a challenging benchmark for evaluating VLMs. To facilitate large-scale data synthesis, we develop an Automatic Scene Creation Engine. This engine, leveraging multiple specialized LLM agents, can generate realistic 3D scenes from abstract math problems, ensuring faithfulness to the original descriptions. Experimental results reveal that state-of-the-art VLMs struggle significantly on SIRI-Bench, underscoring the challenge of spatial reasoning. We hope that our study will bring researchers' attention to spatially grounded reasoning and advance VLMs in visual problem-solving.
DART: Differentiable Dynamic Adaptive Region Tokenizer for Vision Transformer and Mamba
Jun 12, 2025Recently, non-convolutional models such as the Vision Transformer (ViT) and Vision Mamba (Vim) have achieved remarkable performance in computer vision tasks. However, their reliance on fixed-size patches often results in excessive encoding of background regions and omission of critical local details, especially when informative objects are sparsely distributed. To address this, we introduce a fully differentiable Dynamic Adaptive Region Tokenizer (DART), which adaptively partitions images into content-dependent patches of varying sizes. DART combines learnable region scores with piecewise differentiable quantile operations to allocate denser tokens to information-rich areas. Despite introducing only approximately 1 million (1M) additional parameters, DART improves accuracy by 2.1% on DeiT (ImageNet-1K). Unlike methods that uniformly increase token density to capture fine-grained details, DART offers a more efficient alternative, achieving 45% FLOPs reduction with superior performance. Extensive experiments on DeiT, Vim, and VideoMamba confirm that DART consistently enhances accuracy while incurring minimal or even reduced computational overhead. Code is available at https://github.com/HCPLab-SYSU/DART.
Chain of Methodologies: Scaling Test Time Computation without Training
Jun 08, 2025Large Language Models (LLMs) often struggle with complex reasoning tasks due to insufficient in-depth insights in their training data, which are typically absent in publicly available documents. This paper introduces the Chain of Methodologies (CoM), an innovative and intuitive prompting framework that enhances structured thinking by integrating human methodological insights, enabling LLMs to tackle complex tasks with extended reasoning. CoM leverages the metacognitive abilities of advanced LLMs, activating systematic reasoning throught user-defined methodologies without explicit fine-tuning. Experiments show that CoM surpasses competitive baselines, demonstrating the potential of training-free prompting methods as robust solutions for complex reasoning tasks and bridging the gap toward human-level reasoning through human-like methodological insights.
Geometry-Editable and Appearance-Preserving Object Compositon
May 27, 2025General object composition (GOC) aims to seamlessly integrate a target object into a background scene with desired geometric properties, while simultaneously preserving its fine-grained appearance details. Recent approaches derive semantic embeddings and integrate them into advanced diffusion models to enable geometry-editable generation. However, these highly compact embeddings encode only high-level semantic cues and inevitably discard fine-grained appearance details. We introduce a Disentangled Geometry-editable and Appearance-preserving Diffusion (DGAD) model that first leverages semantic embeddings to implicitly capture the desired geometric transformations and then employs a cross-attention retrieval mechanism to align fine-grained appearance features with the geometry-edited representation, facilitating both precise geometry editing and faithful appearance preservation in object composition. Specifically, DGAD builds on CLIP/DINO-derived and reference networks to extract semantic embeddings and appearance-preserving representations, which are then seamlessly integrated into the encoding and decoding pipelines in a disentangled manner. We first integrate the semantic embeddings into pre-trained diffusion models that exhibit strong spatial reasoning capabilities to implicitly capture object geometry, thereby facilitating flexible object manipulation and ensuring effective editability. Then, we design a dense cross-attention mechanism that leverages the implicitly learned object geometry to retrieve and spatially align appearance features with their corresponding regions, ensuring faithful appearance consistency. Extensive experiments on public benchmarks demonstrate the effectiveness of the proposed DGAD framework.
MiniLongBench: The Low-cost Long Context Understanding Benchmark for Large Language Models
May 26, 2025



Long Context Understanding (LCU) is a critical area for exploration in current large language models (LLMs). However, due to the inherently lengthy nature of long-text data, existing LCU benchmarks for LLMs often result in prohibitively high evaluation costs, like testing time and inference expenses. Through extensive experimentation, we discover that existing LCU benchmarks exhibit significant redundancy, which means the inefficiency in evaluation. In this paper, we propose a concise data compression method tailored for long-text data with sparse information characteristics. By pruning the well-known LCU benchmark LongBench, we create MiniLongBench. This benchmark includes only 237 test samples across six major task categories and 21 distinct tasks. Through empirical analysis of over 60 LLMs, MiniLongBench achieves an average evaluation cost reduced to only 4.5% of the original while maintaining an average rank correlation coefficient of 0.97 with LongBench results. Therefore, our MiniLongBench, as a low-cost benchmark, holds great potential to substantially drive future research into the LCU capabilities of LLMs. See https://github.com/MilkThink-Lab/MiniLongBench for our code, data and tutorial.
UniErase: Unlearning Token as a Universal Erasure Primitive for Language Models
May 21, 2025Large language models require iterative updates to address challenges such as knowledge conflicts and outdated information (e.g., incorrect, private, or illegal contents). Machine unlearning provides a systematic methodology for targeted knowledge removal from trained models, enabling elimination of sensitive information influences. However, mainstream fine-tuning-based unlearning methods often fail to balance unlearning efficacy and model ability, frequently resulting in catastrophic model collapse under extensive knowledge removal. Meanwhile, in-context unlearning, which relies solely on contextual prompting without modifying the model's intrinsic mechanisms, suffers from limited generalizability and struggles to achieve true unlearning. In this work, we introduce UniErase, a novel unlearning paradigm that employs learnable parametric suffix (unlearning token) to steer language models toward targeted forgetting behaviors. UniErase operates through two key phases: (I) an optimization stage that binds desired unlearning outputs to the model's autoregressive probability distribution via token optimization, followed by (II) a lightweight model editing phase that activates the learned token to probabilistically induce specified forgetting objective. Serving as a new research direction for token learning to induce unlearning target, UniErase achieves state-of-the-art (SOTA) performance across batch, sequential, and precise unlearning under fictitious and real-world knowledge settings. Remarkably, in terms of TOFU benchmark, UniErase, modifying only around 3.66% of the LLM parameters, outperforms previous forgetting SOTA baseline by around 4.01 times for model ability with even better unlearning efficacy. Similarly, UniErase, maintaining more ability, also surpasses previous retaining SOTA by 35.96% for unlearning efficacy, showing dual top-tier performances in current unlearing domain.