 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Representation and Dependency Learning for Multi-Label Image Recognition
Apr 08, 2022
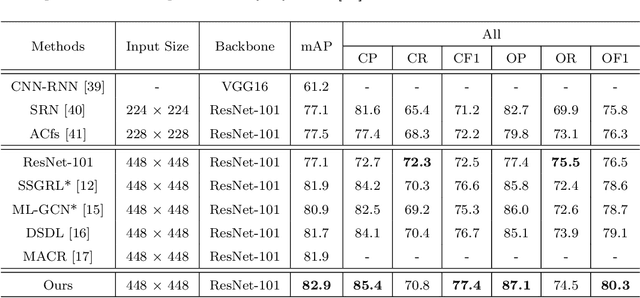
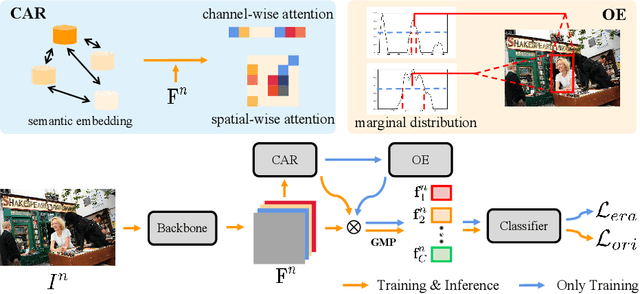
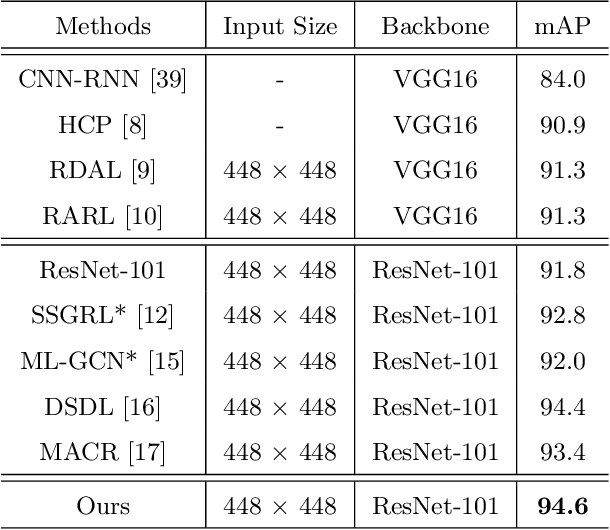
Recently many multi-label image recognition (MLR) works have made significant progress by introducing pre-trained object detection models to generate lots of proposals or utilizing statistical label co-occurrence enhance the correlation among different categories. However, these works have some limitations: (1) the effectiveness of the network significantly depends on pre-trained object detection models that bring expensive and unaffordable computation; (2) the network performance degrades when there exist occasional co-occurrence objects in images, especially for the rare categories. To address these problems, we propose a novel and effective semantic representation and dependency learning (SRDL) framework to learn category-specific semantic representation for each category and capture semantic dependency among all categories. Specifically, we design a category-specific attentional regions (CAR) module to generate channel/spatial-wise attention matrices to guide model to focus on semantic-aware regions. We also design an object erasing (OE) module to implicitly learn semantic dependency among categories by erasing semantic-aware regions to regularize the network training. Extensive experiments and comparisons on two popular MLR benchmark datasets (i.e., MS-COCO and Pascal VOC 2007) demonstrate the effectiveness of the proposed framework over current state-of-the-art algorithms.
Open Set Domain Adaptation By Novel Class Discovery
Mar 07, 2022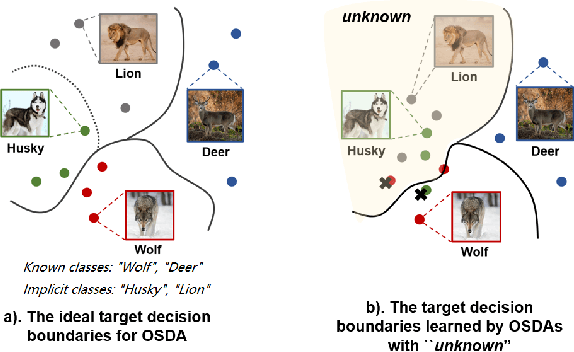
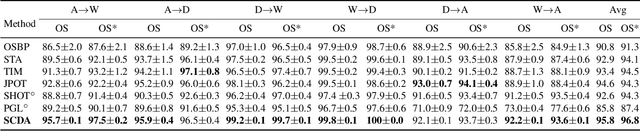
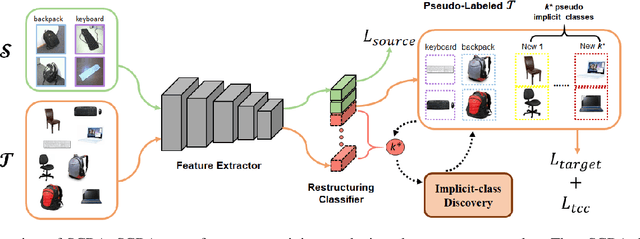

In Open Set Domain Adaptation (OSDA), large amounts of target samples are drawn from the implicit categories that never appear in the source domain. Due to the lack of their specific belonging, existing methods indiscriminately regard them as a single class unknown. We challenge this broadly-adopted practice that may arouse unexpected detrimental effects because the decision boundaries between the implicit categories have been fully ignored. Instead, we propose Self-supervised Class-Discovering Adapter (SCDA) that attempts to achieve OSDA by gradually discovering those implicit classes, then incorporating them to restructure the classifier and update the domain-adaptive features iteratively. SCDA performs two alternate steps to achieve implicit class discovery and self-supervised OSDA, respectively. By jointly optimizing for two tasks, SCDA achieves the state-of-the-art in OSDA and shows a competitive performance to unearth the implicit target classes.
Semantic-Aware Representation Blending for Multi-Label Image Recognition with Partial Labels
Mar 04, 2022
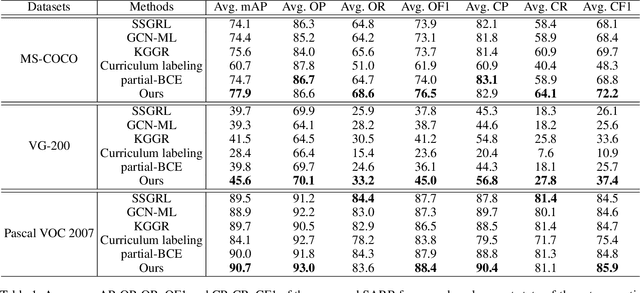
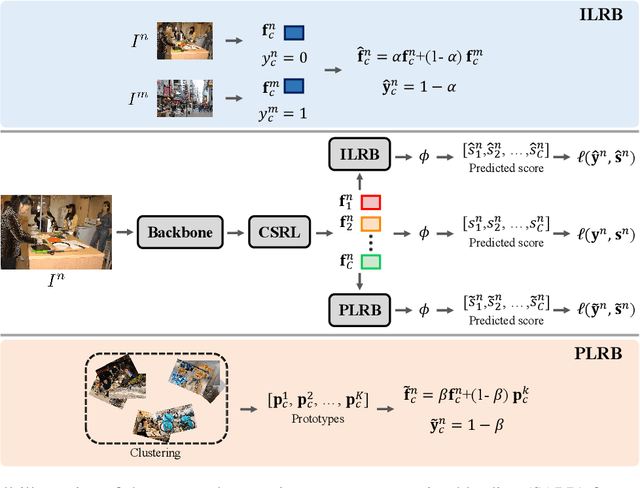
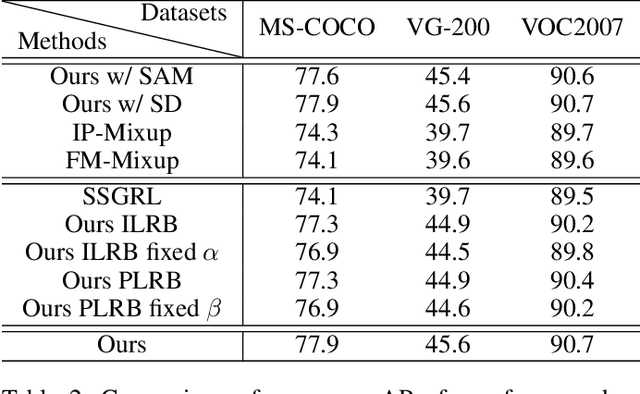
Training the multi-label image recognition models with partial labels, in which merely some labels are known while others are unknown for each image, is a considerably challenging and practical task. To address this task, current algorithms mainly depend on pre-training classification or similarity models to generate pseudo labels for the unknown labels. However, these algorithms depend on sufficient multi-label annotations to train the models, leading to poor performance especially with low known label proportion. In this work, we propose to blend category-specific representation across different images to transfer information of known labels to complement unknown labels, which can get rid of pre-training models and thus does not depend on sufficient annotations. To this end, we design a unified semantic-aware representation blending (SARB) framework that exploits instance-level and prototype-level semantic representation to complement unknown labels by two complementary modules: 1) an instance-level representation blending (ILRB) module blends the representations of the known labels in an image to the representations of the unknown labels in another image to complement these unknown labels. 2) a prototype-level representation blending (PLRB) module learns more stable representation prototypes for each category and blends the representation of unknown labels with the prototypes of corresponding labels to complement these labels. Extensive experiments on the MS-COCO, Visual Genome, Pascal VOC 2007 datasets show that the proposed SARB framework obtains superior performance over current leading competitors on all known label proportion settings, i.e., with the mAP improvement of 4.6%, 4.%, 2.2% on these three datasets when the known label proportion is 10%. Codes are available at https://github.com/HCPLab-SYSU/HCP-MLR-PL.
Unsupervised Domain Adaptive Salient Object Detection Through Uncertainty-Aware Pseudo-Label Learning
Feb 26, 2022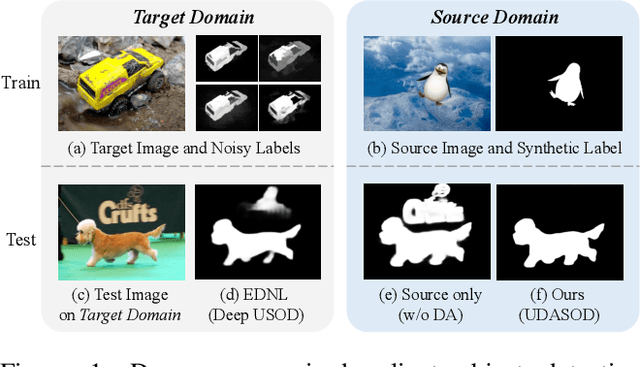
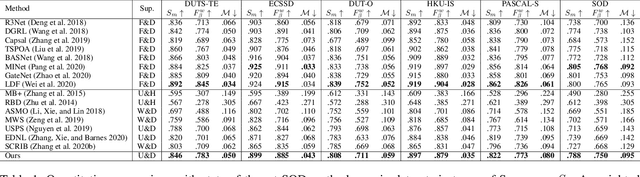


Recent advances in deep learning significantly boost the performance of salient object detection (SOD) at the expense of labeling larger-scale per-pixel annotations. To relieve the burden of labor-intensive labeling, deep unsupervised SOD methods have been proposed to exploit noisy labels generated by handcrafted saliency methods. However, it is still difficult to learn accurate saliency details from rough noisy labels. In this paper, we propose to learn saliency from synthetic but clean labels, which naturally has higher pixel-labeling quality without the effort of manual annotations. Specifically, we first construct a novel synthetic SOD dataset by a simple copy-paste strategy. Considering the large appearance differences between the synthetic and real-world scenarios, directly training with synthetic data will lead to performance degradation on real-world scenarios. To mitigate this problem, we propose a novel unsupervised domain adaptive SOD method to adapt between these two domains by uncertainty-aware self-training. Experimental results show that our proposed method outperforms the existing state-of-the-art deep unsupervised SOD methods on several benchmark datasets, and is even comparable to fully-supervised ones.
TCGL: Temporal Contrastive Graph for Self-supervised Video Representation Learning
Jan 05, 2022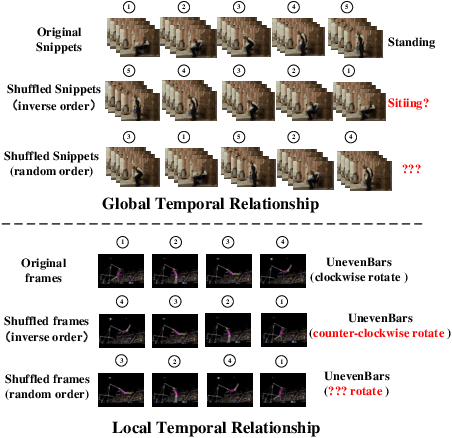
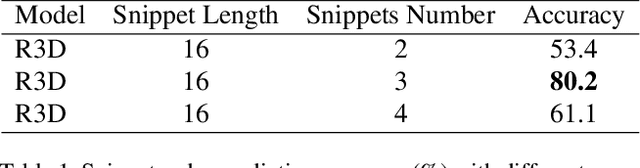
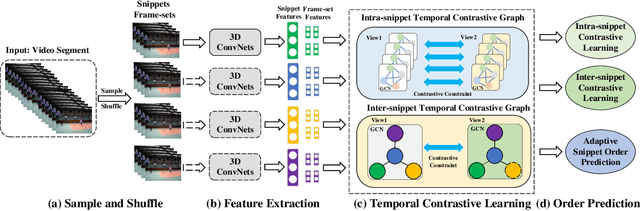

Video self-supervised learning is a challenging task, which requires significant expressive power from the model to leverage rich spatial-temporal knowledge and generate effective supervisory signals from large amounts of unlabeled videos. However, existing methods fail to increase the temporal diversity of unlabeled videos and ignore elaborately modeling multi-scale temporal dependencies in an explicit way. To overcome these limitations, we take advantage of the multi-scale temporal dependencies within videos and proposes a novel video self-supervised learning framework named Temporal Contrastive Graph Learning (TCGL), which jointly models the inter-snippet and intra-snippet temporal dependencies for temporal representation learning with a hybrid graph contrastive learning strategy. Specifically, a Spatial-Temporal Knowledge Discovering (STKD) module is first introduced to extract motion-enhanced spatial-temporal representations from videos based on the frequency domain analysis of discrete cosine transform. To explicitly model multi-scale temporal dependencies of unlabeled videos, our TCGL integrates the prior knowledge about the frame and snippet orders into graph structures, i.e., the intra-/inter- snippet Temporal Contrastive Graphs (TCG). Then, specific contrastive learning modules are designed to maximize the agreement between nodes in different graph views. To generate supervisory signals for unlabeled videos, we introduce an Adaptive Snippet Order Prediction (ASOP) module which leverages the relational knowledge among video snippets to learn the global context representation and recalibrate the channel-wise features adaptively. Experimental results demonstrate the superiority of our TCGL over the state-of-the-art methods on large-scale action recognition and video retrieval benchmarks.The code is publicly available at https://github.com/YangLiu9208/TCGL.
Structured Semantic Transfer for Multi-Label Recognition with Partial Labels
Dec 22, 2021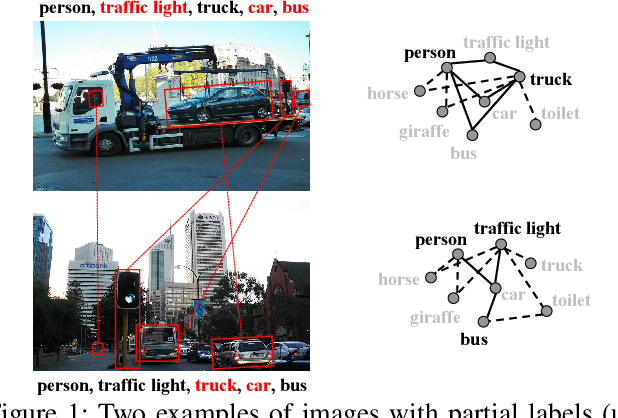
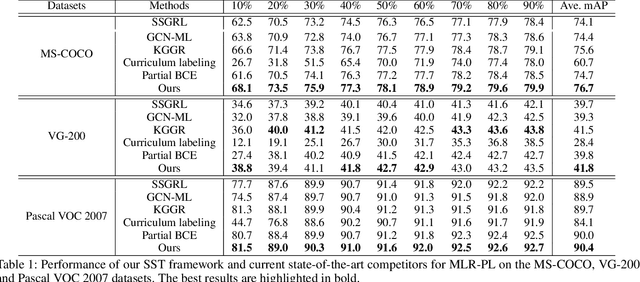
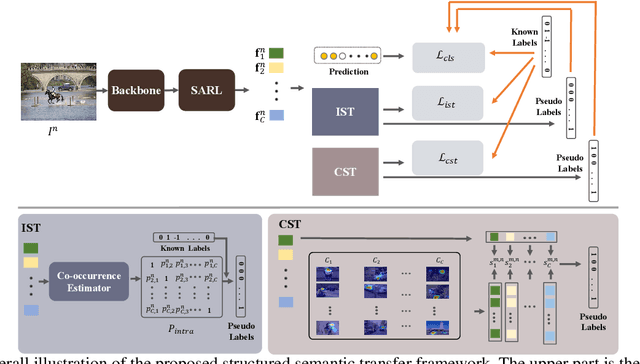
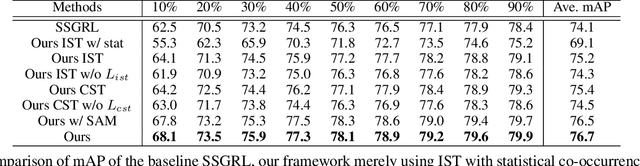
Multi-label image recognition is a fundamental yet practical task because real-world images inherently possess multiple semantic labels. However, it is difficult to collect large-scale multi-label annotations due to the complexity of both the input images and output label spaces. To reduce the annotation cost, we propose a structured semantic transfer (SST) framework that enables training multi-label recognition models with partial labels, i.e., merely some labels are known while other labels are missing (also called unknown labels) per image. The framework consists of two complementary transfer modules that explore within-image and cross-image semantic correlations to transfer knowledge of known labels to generate pseudo labels for unknown labels. Specifically, an intra-image semantic transfer module learns image-specific label co-occurrence matrix and maps the known labels to complement unknown labels based on this matrix. Meanwhile, a cross-image transfer module learns category-specific feature similarities and helps complement unknown labels with high similarities. Finally, both known and generated labels are used to train the multi-label recognition models. Extensive experiments on the Microsoft COCO, Visual Genome and Pascal VOC datasets show that the proposed SST framework obtains superior performance over current state-of-the-art algorithms. Codes are available at https://github.com/HCPLab-SYSU/HCP-MLR-PL.
Aerial Images Meet Crowdsourced Trajectories: A New Approach to Robust Road Extraction
Nov 30, 2021
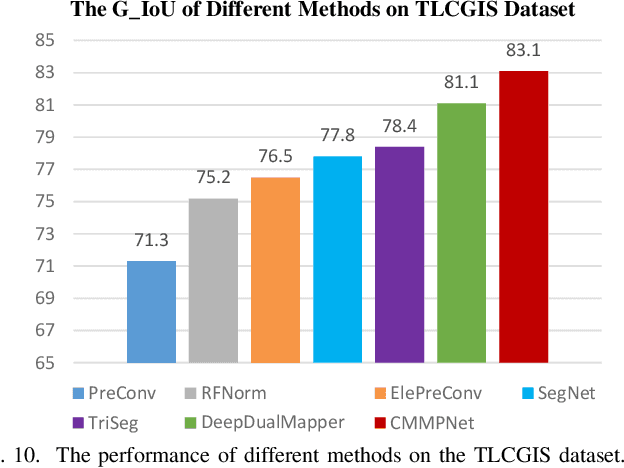
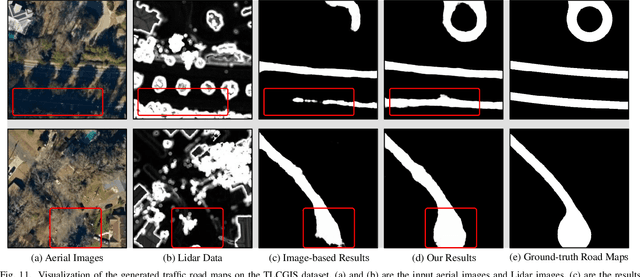
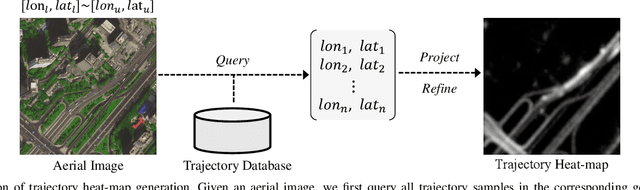
Land remote sensing analysis is a crucial research in earth science. In this work, we focus on a challenging task of land analysis, i.e., automatic extraction of traffic roads from remote sensing data, which has widespread applications in urban development and expansion estimation. Nevertheless, conventional methods either only utilized the limited information of aerial images, or simply fused multimodal information (e.g., vehicle trajectories), thus cannot well recognize unconstrained roads. To facilitate this problem, we introduce a novel neural network framework termed Cross-Modal Message Propagation Network (CMMPNet), which fully benefits the complementary different modal data (i.e., aerial images and crowdsourced trajectories). Specifically, CMMPNet is composed of two deep Auto-Encoders for modality-specific representation learning and a tailor-designed Dual Enhancement Module for cross-modal representation refinement. In particular, the complementary information of each modality is comprehensively extracted and dynamically propagated to enhance the representation of another modality. Extensive experiments on three real-world benchmarks demonstrate the effectiveness of our CMMPNet for robust road extraction benefiting from blending different modal data, either using image and trajectory data or image and Lidar data. From the experimental results, we observe that the proposed approach outperforms current state-of-the-art methods by large margins.
Enhancing Prototypical Few-Shot Learning by Leveraging the Local-Level Strategy
Nov 08, 2021

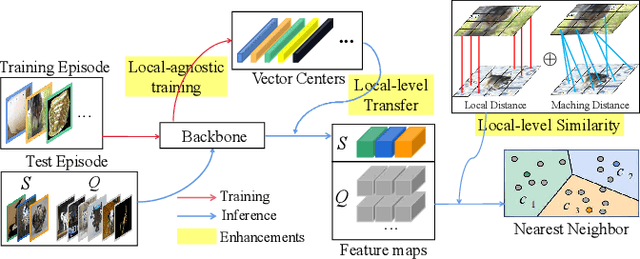
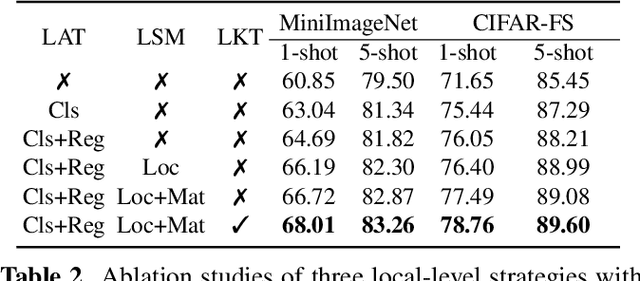
Aiming at recognizing the samples from novel categories with few reference samples, few-shot learning (FSL) is a challenging problem. We found that the existing works often build their few-shot model based on the image-level feature by mixing all local-level features, which leads to the discriminative location bias and information loss in local details. To tackle the problem, this paper returns the perspective to the local-level feature and proposes a series of local-level strategies. Specifically, we present (a) a local-agnostic training strategy to avoid the discriminative location bias between the base and novel categories, (b) a novel local-level similarity measure to capture the accurate comparison between local-level features, and (c) a local-level knowledge transfer that can synthesize different knowledge transfers from the base category according to different location features. Extensive experiments justify that our proposed local-level strategies can significantly boost the performance and achieve 2.8%-7.2% improvements over the baseline across different benchmark datasets, which also achieves state-of-the-art accuracy.
Image Comes Dancing with Collaborative Parsing-Flow Video Synthesis
Oct 28, 2021
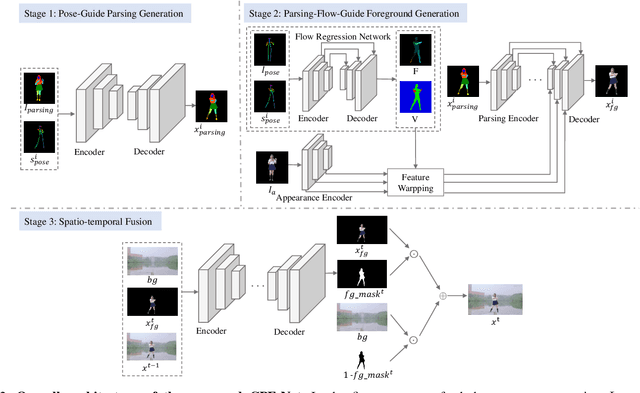


Transferring human motion from a source to a target person poses great potential in computer vision and graphics applications. A crucial step is to manipulate sequential future motion while retaining the appearance characteristic.Previous work has either relied on crafted 3D human models or trained a separate model specifically for each target person, which is not scalable in practice.This work studies a more general setting, in which we aim to learn a single model to parsimoniously transfer motion from a source video to any target person given only one image of the person, named as Collaborative Parsing-Flow Network (CPF-Net). The paucity of information regarding the target person makes the task particularly challenging to faithfully preserve the appearance in varying designated poses. To address this issue, CPF-Net integrates the structured human parsing and appearance flow to guide the realistic foreground synthesis which is merged into the background by a spatio-temporal fusion module. In particular, CPF-Net decouples the problem into stages of human parsing sequence generation, foreground sequence generation and final video generation. The human parsing generation stage captures both the pose and the body structure of the target. The appearance flow is beneficial to keep details in synthesized frames. The integration of human parsing and appearance flow effectively guides the generation of video frames with realistic appearance. Finally, the dedicated designed fusion network ensure the temporal coherence. We further collect a large set of human dancing videos to push forward this research field. Both quantitative and qualitative results show our method substantially improves over previous approaches and is able to generate appealing and photo-realistic target videos given any input person image. All source code and dataset will be released at https://github.com/xiezhy6/CPF-Net.
Plug-and-Play Few-shot Object Detection with Meta Strategy and Explicit Localization Inference
Oct 26, 2021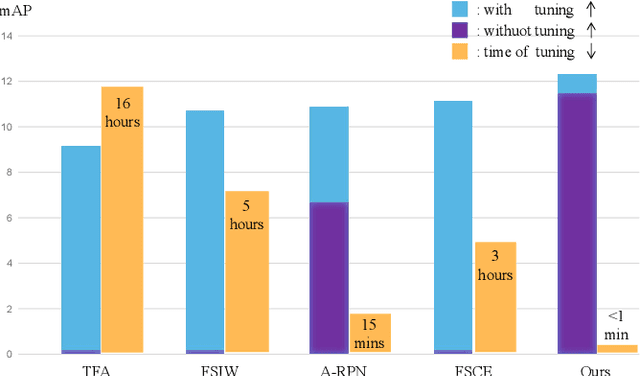
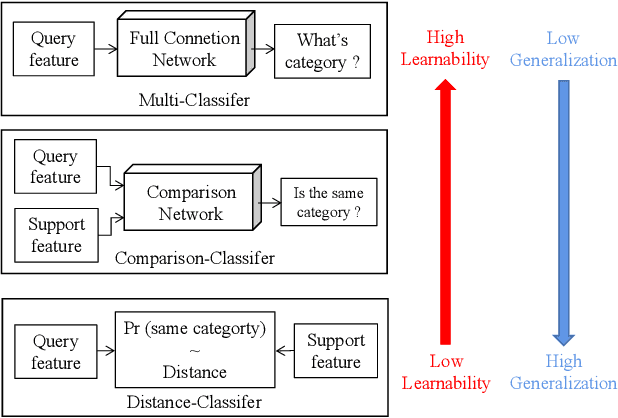
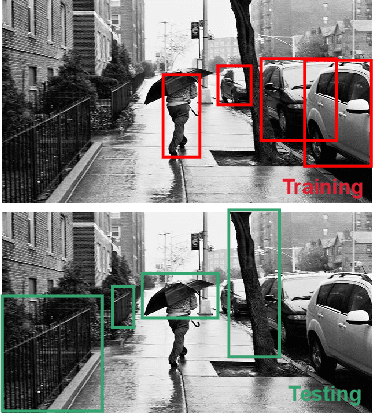
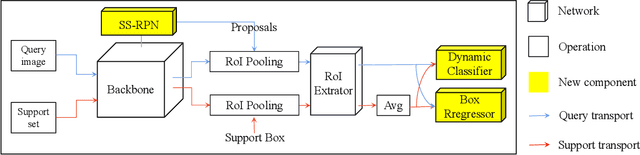
Aiming at recognizing and localizing the object of novel categories by a few reference samples, few-shot object detection is a quite challenging task. Previous works often depend on the fine-tuning process to transfer their model to the novel category and rarely consider the defect of fine-tuning, resulting in many drawbacks. For example, these methods are far from satisfying in the low-shot or episode-based scenarios since the fine-tuning process in object detection requires much time and high-shot support data. To this end, this paper proposes a plug-and-play few-shot object detection (PnP-FSOD) framework that can accurately and directly detect the objects of novel categories without the fine-tuning process. To accomplish the objective, the PnP-FSOD framework contains two parallel techniques to address the core challenges in the few-shot learning, i.e., across-category task and few-annotation support. Concretely, we first propose two simple but effective meta strategies for the box classifier and RPN module to enable the across-category object detection without fine-tuning. Then, we introduce two explicit inferences into the localization process to reduce its dependence on the annotated data, including explicit localization score and semi-explicit box regression. In addition to the PnP-FSOD framework, we propose a novel one-step tuning method that can avoid the defects in fine-tuning. It is noteworthy that the proposed techniques and tuning method are based on the general object detector without other prior methods, so they are easily compatible with the existing FSOD methods. Extensive experiments show that the PnP-FSOD framework has achieved the state-of-the-art few-shot object detection performance without any tuning method. After applying the one-step tuning method, it further shows a significant lead in both efficiency, precision, and recall, under varied evaluation protocols.