 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiang Ding
SpliceMix: A Cross-scale and Semantic Blending Augmentation Strategy for Multi-label Image Classification
Nov 26, 2023
Recently, Mix-style data augmentation methods (e.g., Mixup and CutMix) have shown promising performance in various visual tasks. However, these methods are primarily designed for single-label images, ignoring the considerable discrepancies between single- and multi-label images, i.e., a multi-label image involves multiple co-occurred categories and fickle object scales. On the other hand, previous multi-label image classification (MLIC) methods tend to design elaborate models, bringing expensive computation. In this paper, we introduce a simple but effective augmentation strategy for multi-label image classification, namely SpliceMix. The "splice" in our method is two-fold: 1) Each mixed image is a splice of several downsampled images in the form of a grid, where the semantics of images attending to mixing are blended without object deficiencies for alleviating co-occurred bias; 2) We splice mixed images and the original mini-batch to form a new SpliceMixed mini-batch, which allows an image with different scales to contribute to training together. Furthermore, such splice in our SpliceMixed mini-batch enables interactions between mixed images and original regular images. We also offer a simple and non-parametric extension based on consistency learning (SpliceMix-CL) to show the flexible extensibility of our SpliceMix. Extensive experiments on various tasks demonstrate that only using SpliceMix with a baseline model (e.g., ResNet) achieves better performance than state-of-the-art methods. Moreover, the generalizability of our SpliceMix is further validated by the improvements in current MLIC methods when married with our SpliceMix. The code is available at https://github.com/zuiran/SpliceMix.
Merging Experts into One: Improving Computational Efficiency of Mixture of Experts
Oct 22, 2023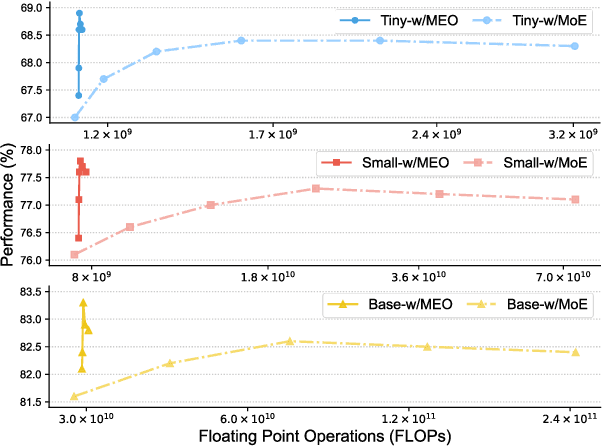
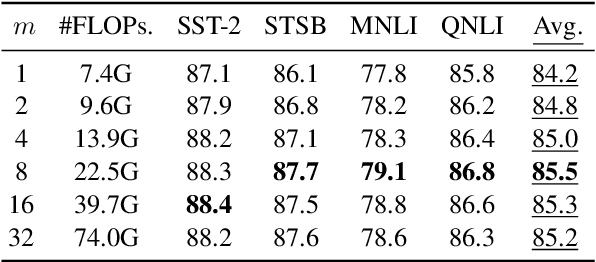
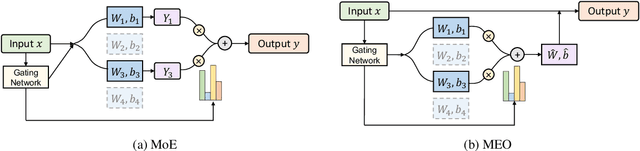

Scaling the size of language models usually leads to remarkable advancements in NLP tasks. But it often comes with a price of growing computational cost. Although a sparse Mixture of Experts (MoE) can reduce the cost by activating a small subset of parameters (e.g., one expert) for each input, its computation escalates significantly if increasing the number of activated experts, limiting its practical utility. Can we retain the advantages of adding more experts without substantially increasing the computational costs? In this paper, we first demonstrate the superiority of selecting multiple experts and then propose a computation-efficient approach called \textbf{\texttt{Merging Experts into One}} (MEO), which reduces the computation cost to that of a single expert. Extensive experiments show that MEO significantly improves computational efficiency, e.g., FLOPS drops from 72.0G of vanilla MoE to 28.6G (MEO). Moreover, we propose a token-level attention block that further enhances the efficiency and performance of token-level MEO, e.g., 83.3\% (MEO) vs. 82.6\% (vanilla MoE) average score on the GLUE benchmark. Our code will be released upon acceptance. Code will be released at: \url{https://github.com/Shwai-He/MEO}.
Zero-Shot Sharpness-Aware Quantization for Pre-trained Language Models
Oct 20, 2023Quantization is a promising approach for reducing memory overhead and accelerating inference, especially in large pre-trained language model (PLM) scenarios. While having no access to original training data due to security and privacy concerns has emerged the demand for zero-shot quantization. Most of the cutting-edge zero-shot quantization methods primarily 1) apply to computer vision tasks, and 2) neglect of overfitting problem in the generative adversarial learning process, leading to sub-optimal performance. Motivated by this, we propose a novel zero-shot sharpness-aware quantization (ZSAQ) framework for the zero-shot quantization of various PLMs. The key algorithm in solving ZSAQ is the SAM-SGA optimization, which aims to improve the quantization accuracy and model generalization via optimizing a minimax problem. We theoretically prove the convergence rate for the minimax optimization problem and this result can be applied to other nonconvex-PL minimax optimization frameworks. Extensive experiments on 11 tasks demonstrate that our method brings consistent and significant performance gains on both discriminative and generative PLMs, i.e., up to +6.98 average score. Furthermore, we empirically validate that our method can effectively improve the model generalization.
Diversifying the Mixture-of-Experts Representation for Language Models with Orthogonal Optimizer
Oct 15, 2023The Mixture of Experts (MoE) has emerged as a highly successful technique in deep learning, based on the principle of divide-and-conquer to maximize model capacity without significant additional computational cost. Even in the era of large-scale language models (LLMs), MoE continues to play a crucial role, as some researchers have indicated that GPT-4 adopts the MoE structure to ensure diverse inference results. However, MoE is susceptible to performance degeneracy, particularly evident in the issues of imbalance and homogeneous representation among experts. While previous studies have extensively addressed the problem of imbalance, the challenge of homogeneous representation remains unresolved. In this study, we shed light on the homogeneous representation problem, wherein experts in the MoE fail to specialize and lack diversity, leading to frustratingly high similarities in their representations (up to 99% in a well-performed MoE model). This problem restricts the expressive power of the MoE and, we argue, contradicts its original intention. To tackle this issue, we propose a straightforward yet highly effective solution: OMoE, an orthogonal expert optimizer. Additionally, we introduce an alternating training strategy that encourages each expert to update in a direction orthogonal to the subspace spanned by other experts. Our algorithm facilitates MoE training in two key ways: firstly, it explicitly enhances representation diversity, and secondly, it implicitly fosters interaction between experts during orthogonal weights computation. Through extensive experiments, we demonstrate that our proposed optimization algorithm significantly improves the performance of fine-tuning the MoE model on the GLUE benchmark, SuperGLUE benchmark, question-answering task, and name entity recognition tasks.
Unlikelihood Tuning on Negative Samples Amazingly Improves Zero-Shot Translation
Sep 28, 2023Zero-shot translation (ZST), which is generally based on a multilingual neural machine translation model, aims to translate between unseen language pairs in training data. The common practice to guide the zero-shot language mapping during inference is to deliberately insert the source and target language IDs, e.g., <EN> for English and <DE> for German. Recent studies have shown that language IDs sometimes fail to navigate the ZST task, making them suffer from the off-target problem (non-target language words exist in the generated translation) and, therefore, difficult to apply the current multilingual translation model to a broad range of zero-shot language scenarios. To understand when and why the navigation capabilities of language IDs are weakened, we compare two extreme decoder input cases in the ZST directions: Off-Target (OFF) and On-Target (ON) cases. By contrastively visualizing the contextual word representations (CWRs) of these cases with teacher forcing, we show that 1) the CWRs of different languages are effectively distributed in separate regions when the sentence and ID are matched (ON setting), and 2) if the sentence and ID are unmatched (OFF setting), the CWRs of different languages are chaotically distributed. Our analyses suggest that although they work well in ideal ON settings, language IDs become fragile and lose their navigation ability when faced with off-target tokens, which commonly exist during inference but are rare in training scenarios. In response, we employ unlikelihood tuning on the negative (OFF) samples to minimize their probability such that the language IDs can discriminate between the on- and off-target tokens during training. Experiments spanning 40 ZST directions show that our method reduces the off-target ratio by -48.0% on average, leading to a +9.1 BLEU improvement with only an extra +0.3% tuning cost.
Deep Model Fusion: A Survey
Sep 27, 2023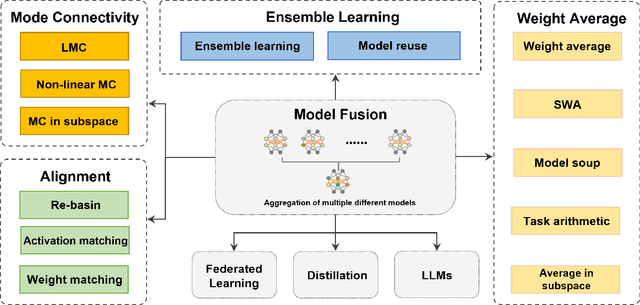

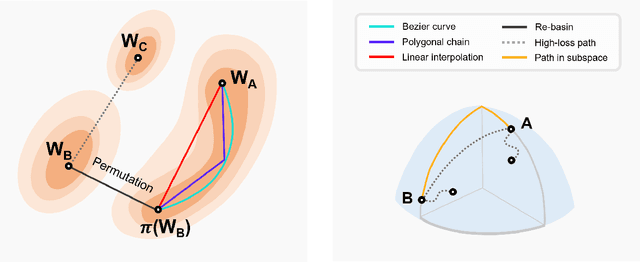
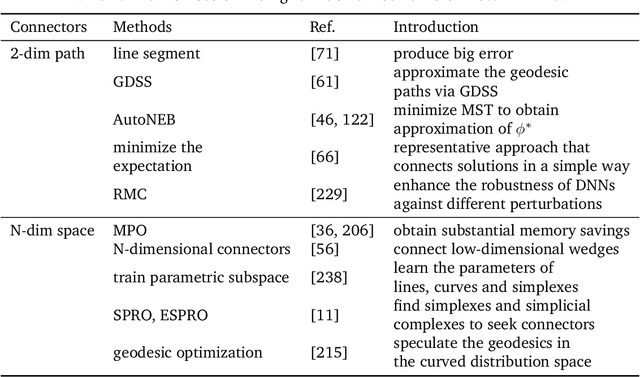
Deep model fusion/merging is an emerging technique that merges the parameters or predictions of multiple deep learning models into a single one. It combines the abilities of different models to make up for the biases and errors of a single model to achieve better performance. However, deep model fusion on large-scale deep learning models (e.g., LLMs and foundation models) faces several challenges, including high computational cost, high-dimensional parameter space, interference between different heterogeneous models, etc. Although model fusion has attracted widespread attention due to its potential to solve complex real-world tasks, there is still a lack of complete and detailed survey research on this technique. Accordingly, in order to understand the model fusion method better and promote its development, we present a comprehensive survey to summarize the recent progress. Specifically, we categorize existing deep model fusion methods as four-fold: (1) "Mode connectivity", which connects the solutions in weight space via a path of non-increasing loss, in order to obtain better initialization for model fusion; (2) "Alignment" matches units between neural networks to create better conditions for fusion; (3) "Weight average", a classical model fusion method, averages the weights of multiple models to obtain more accurate results closer to the optimal solution; (4) "Ensemble learning" combines the outputs of diverse models, which is a foundational technique for improving the accuracy and robustness of the final model. In addition, we analyze the challenges faced by deep model fusion and propose possible research directions for model fusion in the future. Our review is helpful in deeply understanding the correlation between different model fusion methods and practical application methods, which can enlighten the research in the field of deep model fusion.
MerA: Merging Pretrained Adapters For Few-Shot Learning
Aug 30, 2023
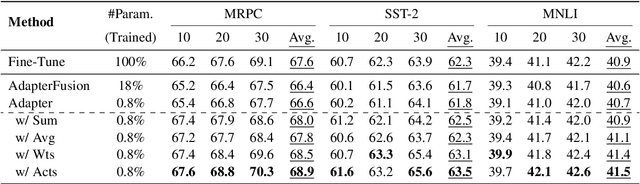
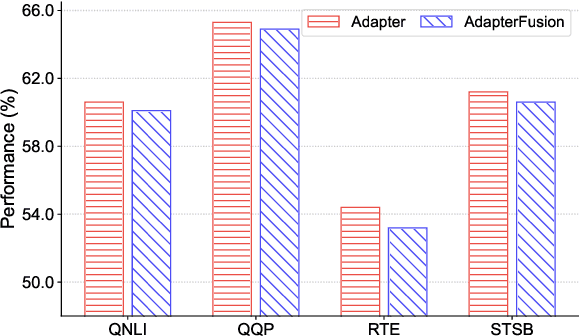
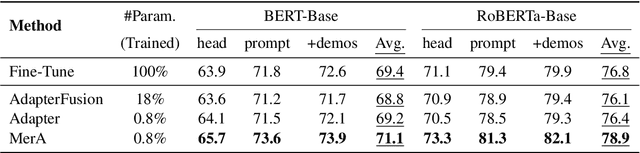
Adapter tuning, which updates only a few parameters, has become a mainstream method for fine-tuning pretrained language models to downstream tasks. However, it often yields subpar results in few-shot learning. AdapterFusion, which assembles pretrained adapters using composition layers tailored to specific tasks, is a possible solution but significantly increases trainable parameters and deployment costs. Despite this, our preliminary study reveals that even single adapters can outperform Adapterfusion in few-shot learning, urging us to propose \textbf{\texttt{Merging Pretrained Adapters}} (MerA) that efficiently incorporates pretrained adapters to a single model through model fusion. Extensive experiments on two PLMs demonstrate that MerA achieves substantial improvements compared to both single adapters and AdapterFusion. To further enhance the capacity of MerA, we also introduce a simple yet effective technique, referred to as the "\textit{same-track}" setting, that merges adapters from the same track of pretraining tasks. With the implementation of the "\textit{same-track}" setting, we observe even more impressive gains, surpassing the performance of both full fine-tuning and adapter tuning by a substantial margin, e.g., 3.5\% in MRPC and 5.0\% in MNLI.
Recursively Summarizing Enables Long-Term Dialogue Memory in Large Language Models
Aug 29, 2023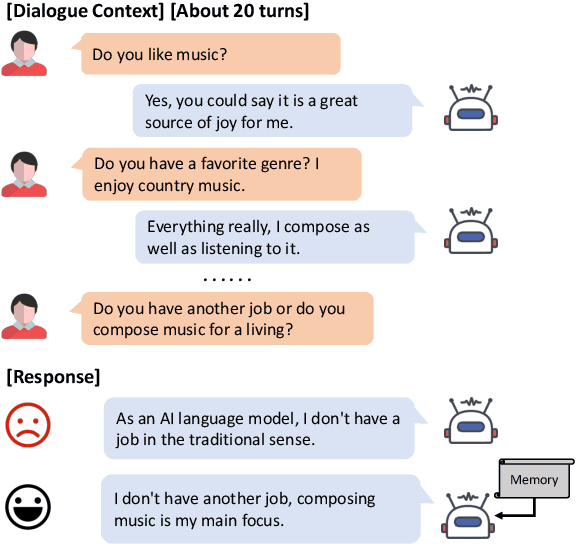

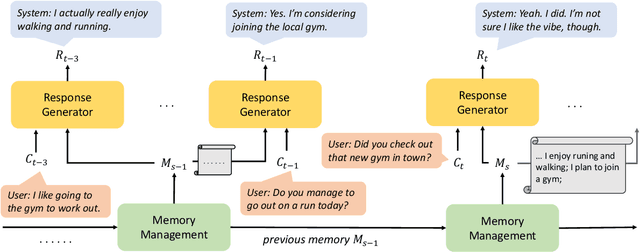
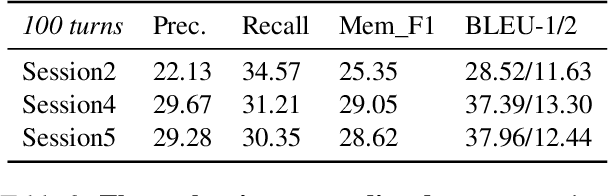
Most open-domain dialogue systems suffer from forgetting important information, especially in a long-term conversation. Existing works usually train the specific retriever or summarizer to obtain key information from the past, which is time-consuming and highly depends on the quality of labeled data. To alleviate this problem, we propose to recursively generate summaries/ memory using large language models (LLMs) to enhance long-term memory ability. Specifically, our method first stimulates LLMs to memorize small dialogue contexts and then recursively produce new memory using previous memory and following contexts. Finally, the LLM can easily generate a highly consistent response with the help of the latest memory. We evaluate our method using ChatGPT and text-davinci-003, and the experiments on the widely-used public dataset show that our method can generate more consistent responses in a long-context conversation. Notably, our method is a potential solution to enable the LLM to model the extremely long context. Code and scripts will be released later.
Can Linguistic Knowledge Improve Multimodal Alignment in Vision-Language Pretraining?
Aug 25, 2023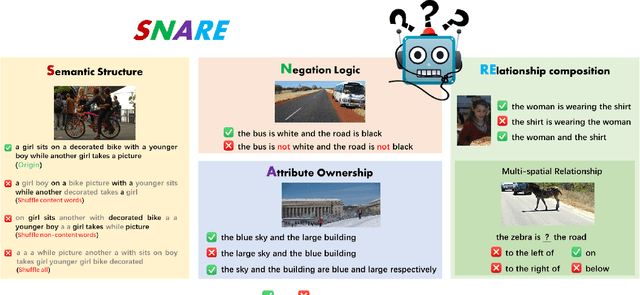
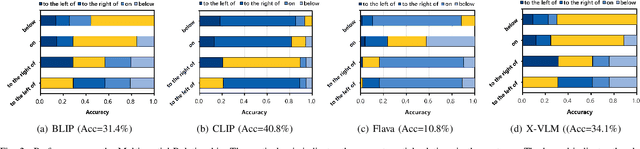
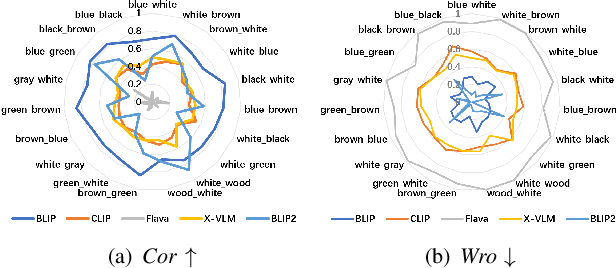
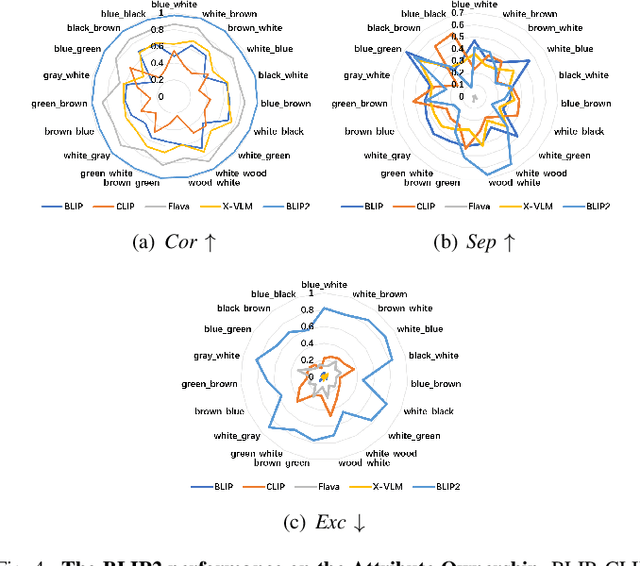
The multimedia community has shown a significant interest in perceiving and representing the physical world with multimodal pretrained neural network models, and among them, the visual-language pertaining (VLP) is, currently, the most captivating topic. However, there have been few endeavors dedicated to the exploration of 1) whether essential linguistic knowledge (e.g., semantics and syntax) can be extracted during VLP, and 2) how such linguistic knowledge impact or enhance the multimodal alignment. In response, here we aim to elucidate the impact of comprehensive linguistic knowledge, including semantic expression and syntactic structure, on multimodal alignment. Specifically, we design and release the SNARE, the first large-scale multimodal alignment probing benchmark, to detect the vital linguistic components, e.g., lexical, semantic, and syntax knowledge, containing four tasks: Semantic structure, Negation logic, Attribute ownership, and Relationship composition. Based on our proposed probing benchmarks, our holistic analyses of five advanced VLP models illustrate that the VLP model: i) shows insensitivity towards complex syntax structures and relies on content words for sentence comprehension; ii) demonstrates limited comprehension of combinations between sentences and negations; iii) faces challenges in determining the presence of actions or spatial relationships within visual information and struggles with verifying the correctness of triple combinations. We make our benchmark and code available at \url{https://github.com/WangFei-2019/SNARE/}.