 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMATCNN: Infrared and Visible Image Fusion Method Based on Multi-scale CNN with Attention Transformer
Feb 04, 2025



While attention-based approaches have shown considerable progress in enhancing image fusion and addressing the challenges posed by long-range feature dependencies, their efficacy in capturing local features is compromised by the lack of diverse receptive field extraction techniques. To overcome the shortcomings of existing fusion methods in extracting multi-scale local features and preserving global features, this paper proposes a novel cross-modal image fusion approach based on a multi-scale convolutional neural network with attention Transformer (MATCNN). MATCNN utilizes the multi-scale fusion module (MSFM) to extract local features at different scales and employs the global feature extraction module (GFEM) to extract global features. Combining the two reduces the loss of detail features and improves the ability of global feature representation. Simultaneously, an information mask is used to label pertinent details within the images, aiming to enhance the proportion of preserving significant information in infrared images and background textures in visible images in fused images. Subsequently, a novel optimization algorithm is developed, leveraging the mask to guide feature extraction through the integration of content, structural similarity index measurement, and global feature loss. Quantitative and qualitative evaluations are conducted across various datasets, revealing that MATCNN effectively highlights infrared salient targets, preserves additional details in visible images, and achieves better fusion results for cross-modal images. The code of MATCNN will be available at https://github.com/zhang3849/MATCNN.git.
Subject Disentanglement Neural Network for Speech Envelope Reconstruction from EEG
Jan 15, 2025



Reconstructing speech envelopes from EEG signals is essential for exploring neural mechanisms underlying speech perception. Yet, EEG variability across subjects and physiological artifacts complicate accurate reconstruction. To address this problem, we introduce Subject Disentangling Neural Network (SDN-Net), which disentangles subject identity information from reconstructed speech envelopes to enhance cross-subject reconstruction accuracy. SDN-Net integrates three key components: MLA-Codec, MPN-MI, and CTA-MTDNN. The MLA-Codec, a fully convolutional neural network, decodes EEG signals into speech envelopes. The CTA-MTDNN module, a multi-scale time-delay neural network with channel and temporal attention, extracts subject identity features from EEG signals. Lastly, the MPN-MI module, a mutual information estimator with a multi-layer perceptron, supervises the removal of subject identity information from the reconstructed speech envelope. Experiments on the Auditory EEG Decoding Dataset demonstrate that SDN-Net achieves superior performance in inner- and cross-subject speech envelope reconstruction compared to recent state-of-the-art methods.
Adaptive Data Augmentation with NaturalSpeech3 for Far-field Speaker Verification
Jan 15, 2025The scarcity of speaker-annotated far-field speech presents a significant challenge in developing high-performance far-field speaker verification (SV) systems. While data augmentation using large-scale near-field speech has been a common strategy to address this limitation, the mismatch in acoustic environments between near-field and far-field speech significantly hinders the improvement of far-field SV effectiveness. In this paper, we propose an adaptive speech augmentation approach leveraging NaturalSpeech3, a pre-trained foundation text-to-speech (TTS) model, to convert near-field speech into far-field speech by incorporating far-field acoustic ambient noise for data augmentation. Specifically, we utilize FACodec from NaturalSpeech3 to decompose the speech waveform into distinct embedding subspaces-content, prosody, speaker, and residual (acoustic details) embeddings-and reconstruct the speech waveform from these disentangled representations. In our method, the prosody, content, and residual embeddings of far-field speech are combined with speaker embeddings from near-field speech to generate augmented pseudo far-field speech that maintains the speaker identity from the out-domain near-field speech while preserving the acoustic environment of the in-domain far-field speech. This approach not only serves as an effective strategy for augmenting training data for far-field speaker verification but also extends to cross-data augmentation for enrollment and test speech in evaluation trials.Experimental results on FFSVC demonstrate that the adaptive data augmentation method significantly outperforms traditional approaches, such as random noise addition and reverberation, as well as other competitive data augmentation strategies.
DiscQuant: A Quantization Method for Neural Networks Inspired by Discrepancy Theory
Jan 11, 2025Quantizing the weights of a neural network has two steps: (1) Finding a good low bit-complexity representation for weights (which we call the quantization grid) and (2) Rounding the original weights to values in the quantization grid. In this paper, we study the problem of rounding optimally given any quantization grid. The simplest and most commonly used way to round is Round-to-Nearest (RTN). By rounding in a data-dependent way instead, one can improve the quality of the quantized model significantly. We study the rounding problem from the lens of \emph{discrepancy theory}, which studies how well we can round a continuous solution to a discrete solution without affecting solution quality too much. We prove that given $m=\mathrm{poly}(1/\epsilon)$ samples from the data distribution, we can round all but $O(m)$ model weights such that the expected approximation error of the quantized model on the true data distribution is $\le \epsilon$ as long as the space of gradients of the original model is approximately low rank (which we empirically validate). Our proof, which is algorithmic, inspired a simple and practical rounding algorithm called \emph{DiscQuant}. In our experiments, we demonstrate that DiscQuant significantly improves over the prior state-of-the-art rounding method called GPTQ and the baseline RTN over a range of benchmarks on Phi3mini-3.8B and Llama3.1-8B. For example, rounding Phi3mini-3.8B to a fixed quantization grid with 3.25 bits per parameter using DiscQuant gets 64\% accuracy on the GSM8k dataset, whereas GPTQ achieves 54\% and RTN achieves 31\% (the original model achieves 84\%). We make our code available at https://github.com/jerry-chee/DiscQuant.
Brick-Diffusion: Generating Long Videos with Brick-to-Wall Denoising
Jan 06, 2025



Recent advances in diffusion models have greatly improved text-driven video generation. However, training models for long video generation demands significant computational power and extensive data, leading most video diffusion models to be limited to a small number of frames. Existing training-free methods that attempt to generate long videos using pre-trained short video diffusion models often struggle with issues such as insufficient motion dynamics and degraded video fidelity. In this paper, we present Brick-Diffusion, a novel, training-free approach capable of generating long videos of arbitrary length. Our method introduces a brick-to-wall denoising strategy, where the latent is denoised in segments, with a stride applied in subsequent iterations. This process mimics the construction of a staggered brick wall, where each brick represents a denoised segment, enabling communication between frames and improving overall video quality. Through quantitative and qualitative evaluations, we demonstrate that Brick-Diffusion outperforms existing baseline methods in generating high-fidelity videos.
4D Gaussian Splatting: Modeling Dynamic Scenes with Native 4D Primitives
Dec 30, 2024



Dynamic 3D scene representation and novel view synthesis from captured videos are crucial for enabling immersive experiences required by AR/VR and metaverse applications. However, this task is challenging due to the complexity of unconstrained real-world scenes and their temporal dynamics. In this paper, we frame dynamic scenes as a spatio-temporal 4D volume learning problem, offering a native explicit reformulation with minimal assumptions about motion, which serves as a versatile dynamic scene learning framework. Specifically, we represent a target dynamic scene using a collection of 4D Gaussian primitives with explicit geometry and appearance features, dubbed as 4D Gaussian splatting (4DGS). This approach can capture relevant information in space and time by fitting the underlying spatio-temporal volume. Modeling the spacetime as a whole with 4D Gaussians parameterized by anisotropic ellipses that can rotate arbitrarily in space and time, our model can naturally learn view-dependent and time-evolved appearance with 4D spherindrical harmonics. Notably, our 4DGS model is the first solution that supports real-time rendering of high-resolution, photorealistic novel views for complex dynamic scenes. To enhance efficiency, we derive several compact variants that effectively reduce memory footprint and mitigate the risk of overfitting. Extensive experiments validate the superiority of 4DGS in terms of visual quality and efficiency across a range of dynamic scene-related tasks (e.g., novel view synthesis, 4D generation, scene understanding) and scenarios (e.g., single object, indoor scenes, driving environments, synthetic and real data).
An Ordinary Differential Equation Sampler with Stochastic Start for Diffusion Bridge Models
Dec 28, 2024



Diffusion bridge models have demonstrated promising performance in conditional image generation tasks, such as image restoration and translation, by initializing the generative process from corrupted images instead of pure Gaussian noise. However, existing diffusion bridge models often rely on Stochastic Differential Equation (SDE) samplers, which result in slower inference speed compared to diffusion models that employ high-order Ordinary Differential Equation (ODE) solvers for acceleration. To mitigate this gap, we propose a high-order ODE sampler with a stochastic start for diffusion bridge models. To overcome the singular behavior of the probability flow ODE (PF-ODE) at the beginning of the reverse process, a posterior sampling approach was introduced at the first reverse step. The sampling was designed to ensure a smooth transition from corrupted images to the generative trajectory while reducing discretization errors. Following this stochastic start, Heun's second-order solver is applied to solve the PF-ODE, achieving high perceptual quality with significantly reduced neural function evaluations (NFEs). Our method is fully compatible with pretrained diffusion bridge models and requires no additional training. Extensive experiments on image restoration and translation tasks, including super-resolution, JPEG restoration, Edges-to-Handbags, and DIODE-Outdoor, demonstrated that our sampler outperforms state-of-the-art methods in both visual quality and Frechet Inception Distance (FID).
Reflective Gaussian Splatting
Dec 26, 2024



Novel view synthesis has experienced significant advancements owing to increasingly capable NeRF- and 3DGS-based methods. However, reflective object reconstruction remains challenging, lacking a proper solution to achieve real-time, high-quality rendering while accommodating inter-reflection. To fill this gap, we introduce a Reflective Gaussian splatting (\textbf{Ref-Gaussian}) framework characterized with two components: (I) {\em Physically based deferred rendering} that empowers the rendering equation with pixel-level material properties via formulating split-sum approximation; (II) {\em Gaussian-grounded inter-reflection} that realizes the desired inter-reflection function within a Gaussian splatting paradigm for the first time. To enhance geometry modeling, we further introduce material-aware normal propagation and an initial per-Gaussian shading stage, along with 2D Gaussian primitives. Extensive experiments on standard datasets demonstrate that Ref-Gaussian surpasses existing approaches in terms of quantitative metrics, visual quality, and compute efficiency. Further, we show that our method serves as a unified solution for both reflective and non-reflective scenes, going beyond the previous alternatives focusing on only reflective scenes. Also, we illustrate that Ref-Gaussian supports more applications such as relighting and editing.
Generalizable Articulated Object Perception with Superpoints
Dec 21, 2024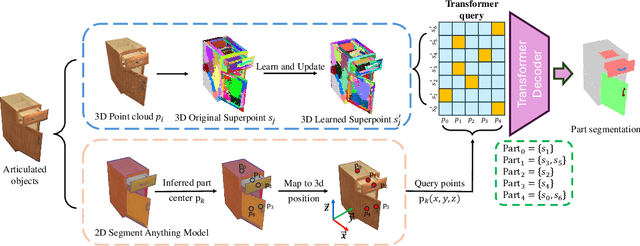



Manipulating articulated objects with robotic arms is challenging due to the complex kinematic structure, which requires precise part segmentation for efficient manipulation. In this work, we introduce a novel superpoint-based perception method designed to improve part segmentation in 3D point clouds of articulated objects. We propose a learnable, part-aware superpoint generation technique that efficiently groups points based on their geometric and semantic similarities, resulting in clearer part boundaries. Furthermore, by leveraging the segmentation capabilities of the 2D foundation model SAM, we identify the centers of pixel regions and select corresponding superpoints as candidate query points. Integrating a query-based transformer decoder further enhances our method's ability to achieve precise part segmentation. Experimental results on the GAPartNet dataset show that our method outperforms existing state-of-the-art approaches in cross-category part segmentation, achieving AP50 scores of 77.9% for seen categories (4.4% improvement) and $39.3\%$ for unseen categories (11.6% improvement), with superior results in 5 out of 9 part categories for seen objects and outperforming all previous methods across all part categories for unseen objects.
IRGS: Inter-Reflective Gaussian Splatting with 2D Gaussian Ray Tracing
Dec 20, 2024In inverse rendering, accurately modeling visibility and indirect radiance for incident light is essential for capturing secondary effects. Due to the absence of a powerful Gaussian ray tracer, previous 3DGS-based methods have either adopted a simplified rendering equation or used learnable parameters to approximate incident light, resulting in inaccurate material and lighting estimations. To this end, we introduce inter-reflective Gaussian splatting (IRGS) for inverse rendering. To capture inter-reflection, we apply the full rendering equation without simplification and compute incident radiance on the fly using the proposed differentiable 2D Gaussian ray tracing. Additionally, we present an efficient optimization scheme to handle the computational demands of Monte Carlo sampling for rendering equation evaluation. Furthermore, we introduce a novel strategy for querying the indirect radiance of incident light when relighting the optimized scenes. Extensive experiments on multiple standard benchmarks validate the effectiveness of IRGS, demonstrating its capability to accurately model complex inter-reflection effects.