 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoedel-Architect: Streamlining Formal Theorem Proving with Blueprint Generation and Refinement
Jun 04, 2026We introduce Goedel-Architect, an agentic framework for formal theorem proving in Lean 4 centered on blueprint generation and refinement. A blueprint is a dependency graph of definitions and lemmas that builds up to the main theorem. First, Goedel-Architect generates a blueprint of formally stated definitions and lemmas, along with declared dependencies. This blueprint is optionally guided by a natural language proof. Then, a tool-equipped Lean prover component closes each open lemma node in parallel using relevant dependencies. Failed lemmas in turn drive refinement of the global blueprint. This strategy contrasts with other mainstream approaches which use recursive lemma decomposition, and can inefficiently loop on dead-end strategies. Using the open-weight DeepSeek-V4-Flash (284B-A13B) as the backbone, Goedel-Architect attains 99.2% pass@1 on MiniF2F-test and 75.6% pass@1 on PutnamBench. With an optional natural-language proof seeding the initial blueprint on the harder problems, we additionally close the remaining two MiniF2F-test problems (reaching 100%), lift PutnamBench to 88.8% (597/672), and solve 4/6 on IMO 2025, 11/12 on Putnam 2025, and 3/6 on USAMO 2026. This represents state-of-the-art performance for an open-source pipeline at a price point up to 500x less than comparable open-source pipelines.
Escaping the Cognitive Well: Efficient Competition Math with Off-the-Shelf Models
Feb 18, 2026In the past year, custom and unreleased math reasoning models reached gold medal performance on the International Mathematical Olympiad (IMO). Similar performance was then reported using large-scale inference on publicly available models but at prohibitive costs (e.g., 3000 USD per problem). In this work, we present an inference pipeline that attains best-in-class performance on IMO-style math problems at an average inference cost orders of magnitude below competing methods while using only general-purpose off-the-shelf models. Our method relies on insights about grader failure in solver-grader pipelines, which we call the Cognitive Well (iterative refinement converging to a wrong solution that the solver as well as the pipeline's internal grader consider to be basically correct). Our pipeline addresses these failure modes through conjecture extraction, wherein candidate lemmas are isolated from generated solutions and independently verified alongside their negations in a fresh environment (context detachment). On IMO-ProofBench Advanced (PB-Adv), our pipeline achieves 67.1 percent performance using Gemini 3.0 Pro with an average cost per question of approximately 31 USD. At the time of evaluation, this represented the state-of-the-art on PB-Adv among both public and unreleased models, and more than doubles the success rate of the next best publicly accessible pipeline, all at a fraction of the cost.
Confabulations from ACL Publications (CAP): A Dataset for Scientific Hallucination Detection
Oct 25, 2025


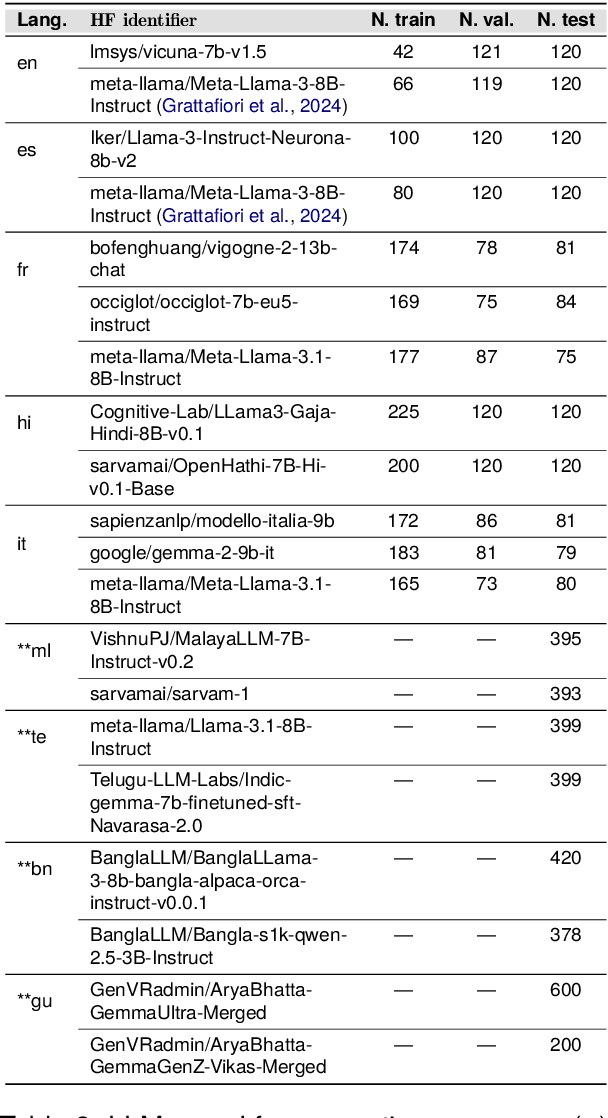
We introduce the CAP (Confabulations from ACL Publications) dataset, a multilingual resource for studying hallucinations in large language models (LLMs) within scientific text generation. CAP focuses on the scientific domain, where hallucinations can distort factual knowledge, as they frequently do. In this domain, however, the presence of specialized terminology, statistical reasoning, and context-dependent interpretations further exacerbates these distortions, particularly given LLMs' lack of true comprehension, limited contextual understanding, and bias toward surface-level generalization. CAP operates in a cross-lingual setting covering five high-resource languages (English, French, Hindi, Italian, and Spanish) and four low-resource languages (Bengali, Gujarati, Malayalam, and Telugu). The dataset comprises 900 curated scientific questions and over 7000 LLM-generated answers from 16 publicly available models, provided as question-answer pairs along with token sequences and corresponding logits. Each instance is annotated with a binary label indicating the presence of a scientific hallucination, denoted as a factuality error, and a fluency label, capturing issues in the linguistic quality or naturalness of the text. CAP is publicly released to facilitate advanced research on hallucination detection, multilingual evaluation of LLMs, and the development of more reliable scientific NLP systems.
Generalizable Articulated Object Perception with Superpoints
Dec 21, 2024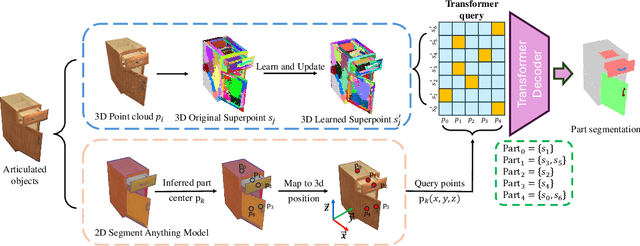



Manipulating articulated objects with robotic arms is challenging due to the complex kinematic structure, which requires precise part segmentation for efficient manipulation. In this work, we introduce a novel superpoint-based perception method designed to improve part segmentation in 3D point clouds of articulated objects. We propose a learnable, part-aware superpoint generation technique that efficiently groups points based on their geometric and semantic similarities, resulting in clearer part boundaries. Furthermore, by leveraging the segmentation capabilities of the 2D foundation model SAM, we identify the centers of pixel regions and select corresponding superpoints as candidate query points. Integrating a query-based transformer decoder further enhances our method's ability to achieve precise part segmentation. Experimental results on the GAPartNet dataset show that our method outperforms existing state-of-the-art approaches in cross-category part segmentation, achieving AP50 scores of 77.9% for seen categories (4.4% improvement) and $39.3\%$ for unseen categories (11.6% improvement), with superior results in 5 out of 9 part categories for seen objects and outperforming all previous methods across all part categories for unseen objects.
ENCLIP: Ensembling and Clustering-Based Contrastive Language-Image Pretraining for Fashion Multimodal Search with Limited Data and Low-Quality Images
Nov 25, 2024



Multimodal search has revolutionized the fashion industry, providing a seamless and intuitive way for users to discover and explore fashion items. Based on their preferences, style, or specific attributes, users can search for products by combining text and image information. Text-to-image searches enable users to find visually similar items or describe products using natural language. This paper presents an innovative approach called ENCLIP, for enhancing the performance of the Contrastive Language-Image Pretraining (CLIP) model, specifically in Multimodal Search targeted towards the domain of fashion intelligence. This method focuses on addressing the challenges posed by limited data availability and low-quality images. This paper proposes an algorithm that involves training and ensembling multiple instances of the CLIP model, and leveraging clustering techniques to group similar images together. The experimental findings presented in this study provide evidence of the effectiveness of the methodology. This approach unlocks the potential of CLIP in the domain of fashion intelligence, where data scarcity and image quality issues are prevalent. Overall, the ENCLIP method represents a valuable contribution to the field of fashion intelligence and provides a practical solution for optimizing the CLIP model in scenarios with limited data and low-quality images.
packetLSTM: Dynamic LSTM Framework for Streaming Data with Varying Feature Space
Oct 22, 2024



We study the online learning problem characterized by the varying input feature space of streaming data. Although LSTMs have been employed to effectively capture the temporal nature of streaming data, they cannot handle the dimension-varying streams in an online learning setting. Therefore, we propose a dynamic LSTM-based novel method, called packetLSTM, to model the dimension-varying streams. The packetLSTM's dynamic framework consists of an evolving packet of LSTMs, each dedicated to processing one input feature. Each LSTM retains the local information of its corresponding feature, while a shared common memory consolidates global information. This configuration facilitates continuous learning and mitigates the issue of forgetting, even when certain features are absent for extended time periods. The idea of utilizing one LSTM per feature coupled with a dimension-invariant operator for information aggregation enhances the dynamic nature of packetLSTM. This dynamic nature is evidenced by the model's ability to activate, deactivate, and add new LSTMs as required, thus seamlessly accommodating varying input dimensions. The packetLSTM achieves state-of-the-art results on five datasets, and its underlying principle is extended to other RNN types, like GRU and vanilla RNN.
Hedging Is Not All You Need: A Simple Baseline for Online Learning Under Haphazard Inputs
Sep 16, 2024



Handling haphazard streaming data, such as data from edge devices, presents a challenging problem. Over time, the incoming data becomes inconsistent, with missing, faulty, or new inputs reappearing. Therefore, it requires models that are reliable. Recent methods to solve this problem depend on a hedging-based solution and require specialized elements like auxiliary dropouts, forked architectures, and intricate network design. We observed that hedging can be reduced to a special case of weighted residual connection; this motivated us to approximate it with plain self-attention. In this work, we propose HapNet, a simple baseline that is scalable, does not require online backpropagation, and is adaptable to varying input types. All present methods are restricted to scaling with a fixed window; however, we introduce a more complex problem of scaling with a variable window where the data becomes positionally uncorrelated, and cannot be addressed by present methods. We demonstrate that a variant of the proposed approach can work even for this complex scenario. We extensively evaluated the proposed approach on five benchmarks and found competitive performance.
Automatic Detection of COVID-19 from Chest X-ray Images Using Deep Learning Model
Aug 27, 2024The infectious disease caused by novel corona virus (2019-nCoV) has been widely spreading since last year and has shaken the entire world. It has caused an unprecedented effect on daily life, global economy and public health. Hence this disease detection has life-saving importance for both patients as well as doctors. Due to limited test kits, it is also a daunting task to test every patient with severe respiratory problems using conventional techniques (RT-PCR). Thus implementing an automatic diagnosis system is urgently required to overcome the scarcity problem of Covid-19 test kits at hospital, health care systems. The diagnostic approach is mainly classified into two categories-laboratory based and Chest radiography approach. In this paper, a novel approach for computerized corona virus (2019-nCoV) detection from lung x-ray images is presented. Here, we propose models using deep learning to show the effectiveness of diagnostic systems. In the experimental result, we evaluate proposed models on publicly available data-set which exhibit satisfactory performance and promising results compared with other previous existing methods.
Online Learning under Haphazard Input Conditions: A Comprehensive Review and Analysis
Apr 07, 2024



The domain of online learning has experienced multifaceted expansion owing to its prevalence in real-life applications. Nonetheless, this progression operates under the assumption that the input feature space of the streaming data remains constant. In this survey paper, we address the topic of online learning in the context of haphazard inputs, explicitly foregoing such an assumption. We discuss, classify, evaluate, and compare the methodologies that are adept at modeling haphazard inputs, additionally providing the corresponding code implementations and their carbon footprint. Moreover, we classify the datasets related to the field of haphazard inputs and introduce evaluation metrics specifically designed for datasets exhibiting imbalance. The code of each methodology can be found at https://github.com/Rohit102497/HaphazardInputsReview
Modelling Irregularly Sampled Time Series Without Imputation
Sep 15, 2023



Modelling irregularly-sampled time series (ISTS) is challenging because of missing values. Most existing methods focus on handling ISTS by converting irregularly sampled data into regularly sampled data via imputation. These models assume an underlying missing mechanism leading to unwanted bias and sub-optimal performance. We present SLAN (Switch LSTM Aggregate Network), which utilizes a pack of LSTMs to model ISTS without imputation, eliminating the assumption of any underlying process. It dynamically adapts its architecture on the fly based on the measured sensors. SLAN exploits the irregularity information to capture each sensor's local summary explicitly and maintains a global summary state throughout the observational period. We demonstrate the efficacy of SLAN on publicly available datasets, namely, MIMIC-III, Physionet 2012 and Physionet 2019. The code is available at https://github.com/Rohit102497/SLAN.