 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMix Data or Merge Models? Balancing the Helpfulness, Honesty, and Harmlessness of Large Language Model via Model Merging
Feb 13, 2025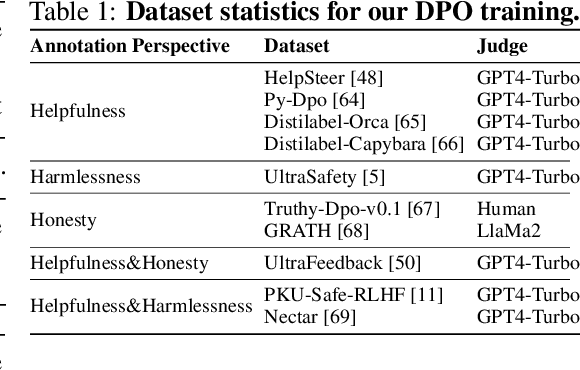
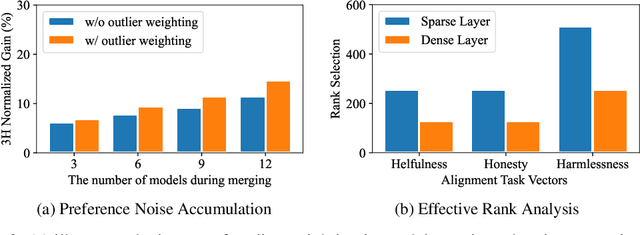
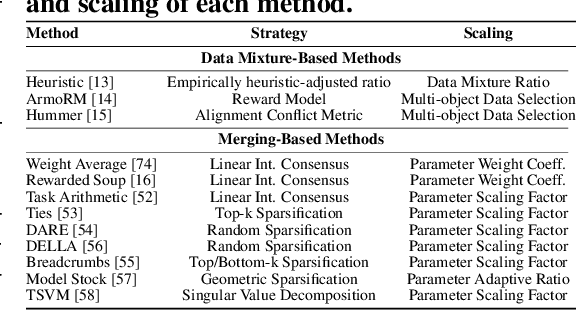
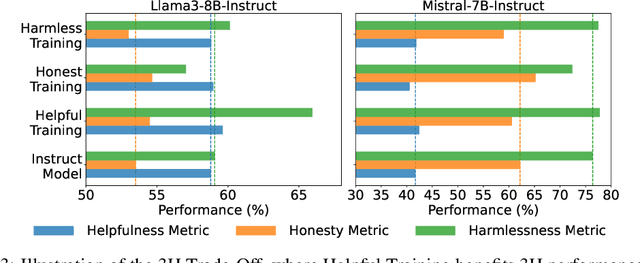
Achieving balanced alignment of large language models (LLMs) in terms of Helpfulness, Honesty, and Harmlessness (3H optimization) constitutes a cornerstone of responsible AI, with existing methods like data mixture strategies facing limitations including reliance on expert knowledge and conflicting optimization signals. While model merging offers a promising alternative by integrating specialized models, its potential for 3H optimization remains underexplored. This paper establishes the first comprehensive benchmark for model merging in 3H-aligned LLMs, systematically evaluating 15 methods (12 training-free merging and 3 data mixture techniques) across 10 datasets associated with 5 annotation dimensions, 2 LLM families, and 2 training paradigms. Our analysis reveals three pivotal insights: (i) previously overlooked collaborative/conflicting relationships among 3H dimensions, (ii) the consistent superiority of model merging over data mixture approaches in balancing alignment trade-offs, and (iii) the critical role of parameter-level conflict resolution through redundant component pruning and outlier mitigation. Building on these findings, we propose R-TSVM, a Reweighting-enhanced Task Singular Vector Merging method that incorporates outlier-aware parameter weighting and sparsity-adaptive rank selection strategies adapted to the heavy-tailed parameter distribution and sparsity for LLMs, further improving LLM alignment across multiple evaluations. We release our trained models for further exploration.
HRP: High-Rank Preheating for Superior LoRA Initialization
Feb 11, 2025This paper studies the crucial impact of initialization on the convergence properties of Low-Rank Adaptation (LoRA). We theoretically demonstrate that random initialization, a widely used schema, will likely lead LoRA to random low-rank results, rather than the best low-rank result. While this issue can be mitigated by adjusting initialization towards a well-informed direction, it relies on prior knowledge of the target, which is typically unknown in real-world scenarios. To approximate this well-informed initial direction, we propose High-Rank Preheating (HRP), which fine-tunes high-rank LoRA for a few steps and uses the singular value decomposition of the preheated result as a superior initialization. HRP initialization is theory-supported to combine the convergence strengths of high-rank LoRA and the generalization strengths of low-rank LoRA. Extensive experiments demonstrate that HRP significantly enhances LoRA's effectiveness across various models and tasks, achieving performance comparable to full-parameter fine-tuning and outperforming other initialization strategies.
Mask-Enhanced Autoregressive Prediction: Pay Less Attention to Learn More
Feb 11, 2025



Large Language Models (LLMs) are discovered to suffer from accurately retrieving key information. To address this, we propose Mask-Enhanced Autoregressive Prediction (MEAP), a simple yet effective training paradigm that seamlessly integrates Masked Language Modeling (MLM) into Next-Token Prediction (NTP) to enhance the latter's in-context retrieval capabilities. Specifically, MEAP first randomly masks a small fraction of input tokens and then directly performs the standard next-token prediction autoregressive using a decoder-only Transformer. MEAP eliminates the need for bidirectional attention or encoder-decoder architectures for MLM, incurring no additional computational overhead during pre-training or inference. Intensive experiments demonstrate that MEAP substantially outperforms NTP on key information retrieval and long-context reasoning tasks, while performing on par or better on commonsense reasoning tasks. The benefits of MEAP also extend to supervised fine-tuning, where it shows remarkable advantages in lost-in-the-middle scenarios, outperforming NTP by 11.77 percentage points. Our analysis indicates that MEAP's effectiveness arises from its ability to promote more distinguishable attention scores by concentrating on a reduced set of non-masked tokens. This mechanism improves the model's focus on task-relevant signals while mitigating the influence of peripheral context. These findings position MEAP as a promising training paradigm for large language models.
Near-Optimal Online Learning for Multi-Agent Submodular Coordination: Tight Approximation and Communication Efficiency
Feb 07, 2025



Coordinating multiple agents to collaboratively maximize submodular functions in unpredictable environments is a critical task with numerous applications in machine learning, robot planning and control. The existing approaches, such as the OSG algorithm, are often hindered by their poor approximation guarantees and the rigid requirement for a fully connected communication graph. To address these challenges, we firstly present a $\textbf{MA-OSMA}$ algorithm, which employs the multi-linear extension to transfer the discrete submodular maximization problem into a continuous optimization, thereby allowing us to reduce the strict dependence on a complete graph through consensus techniques. Moreover, $\textbf{MA-OSMA}$ leverages a novel surrogate gradient to avoid sub-optimal stationary points. To eliminate the computationally intensive projection operations in $\textbf{MA-OSMA}$, we also introduce a projection-free $\textbf{MA-OSEA}$ algorithm, which effectively utilizes the KL divergence by mixing a uniform distribution. Theoretically, we confirm that both algorithms achieve a regret bound of $\widetilde{O}(\sqrt{\frac{C_{T}T}{1-\beta}})$ against a $(\frac{1-e^{-c}}{c})$-approximation to the best comparator in hindsight, where $C_{T}$ is the deviation of maximizer sequence, $\beta$ is the spectral gap of the network and $c$ is the joint curvature of submodular objectives. This result significantly improves the $(\frac{1}{1+c})$-approximation provided by the state-of-the-art OSG algorithm. Finally, we demonstrate the effectiveness of our proposed algorithms through simulation-based multi-target tracking.
Mediator: Memory-efficient LLM Merging with Less Parameter Conflicts and Uncertainty Based Routing
Feb 06, 2025Model merging aggregates Large Language Models (LLMs) finetuned on different tasks into a stronger one. However, parameter conflicts between models leads to performance degradation in averaging. While model routing addresses this issue by selecting individual models during inference, it imposes excessive storage and compute costs, and fails to leverage the common knowledge from different models. In this work, we observe that different layers exhibit varying levels of parameter conflicts. Building on this insight, we average layers with minimal parameter conflicts and use a novel task-level expert routing for layers with significant conflicts. To further reduce storage costs, inspired by task arithmetic sparsity, we decouple multiple fine-tuned experts into a dense expert and several sparse experts. Considering the out-of-distribution samples, we select and merge appropriate experts based on the task uncertainty of the input data. We conduct extensive experiments on both LLaMA and Qwen with varying parameter scales, and evaluate on real-world reasoning tasks. Results demonstrate that our method consistently achieves significant performance improvements while requiring less system cost compared to existing methods.
Leveraging Reasoning with Guidelines to Elicit and Utilize Knowledge for Enhancing Safety Alignment
Feb 06, 2025



Training safe LLMs is one of the most critical research challenge. However, the commonly used method, Refusal Training (RT), struggles to generalize against various OOD jailbreaking attacks. Many safety training methods have been proposed to address this issue. While they offer valuable insights, we aim to complement this line of research by investigating whether OOD attacks truly exceed the capability of RT model. Conducting evaluation with BoN, we observe significant improvements on generalization as N increases. This underscores that the model possesses sufficient safety-related latent knowledge, but RT fails to consistently elicit this knowledge when addressing OOD attacks. Further analysis based on domain adaptation reveals that training with direct refusal causes model to rely on superficial shortcuts, resulting in learning of non-robust representation mappings. Based on our findings, we propose training model to perform safety reasoning for each query. Reasoning supervision encourages model to perform more computations, explicitly eliciting and using latent knowledge through reasoning. To achieve this, we synthesize reasoning supervision based on pre-guidelines, training the model to reason in alignment with them, thereby effectively eliciting and utilizing latent knowledge from diverse perspectives. Extensive experiments show that our method significantly improves generalization performance against OOD attacks.
TeZO: Empowering the Low-Rankness on the Temporal Dimension in the Zeroth-Order Optimization for Fine-tuning LLMs
Jan 31, 2025



Zeroth-order optimization (ZO) has demonstrated remarkable promise in efficient fine-tuning tasks for Large Language Models (LLMs). In particular, recent advances incorporate the low-rankness of gradients, introducing low-rank ZO estimators to further reduce GPU memory consumption. However, most existing works focus solely on the low-rankness of each individual gradient, overlooking a broader property shared by all gradients throughout the training, i.e., all gradients approximately reside within a similar subspace. In this paper, we consider two factors together and propose a novel low-rank ZO estimator, TeZO, which captures the low-rankness across both the model and temporal dimension. Specifically, we represent ZO perturbations along the temporal dimension as a 3D tensor and employ Canonical Polyadic Decomposition (CPD) to extract each low-rank 2D matrix, significantly reducing the training cost. TeZO can also be easily extended to the Adam variant while consuming less memory than MeZO-SGD, and requiring about only 35% memory of MeZO-Adam. Both comprehensive theoretical analysis and extensive experimental research have validated its efficiency, achieving SOTA-comparable results with lower overhead of time and memory.
Panacea: Mitigating Harmful Fine-tuning for Large Language Models via Post-fine-tuning Perturbation
Jan 30, 2025



Harmful fine-tuning attack introduces significant security risks to the fine-tuning services. Mainstream defenses aim to vaccinate the model such that the later harmful fine-tuning attack is less effective. However, our evaluation results show that such defenses are fragile -- with a few fine-tuning steps, the model still can learn the harmful knowledge. To this end, we do further experiment and find that an embarrassingly simple solution -- adding purely random perturbations to the fine-tuned model, can recover the model from harmful behavior, though it leads to a degradation in the model's fine-tuning performance. To address the degradation of fine-tuning performance, we further propose Panacea, which optimizes an adaptive perturbation that will be applied to the model after fine-tuning. Panacea maintains model's safety alignment performance without compromising downstream fine-tuning performance. Comprehensive experiments are conducted on different harmful ratios, fine-tuning tasks and mainstream LLMs, where the average harmful scores are reduced by up-to 21.5%, while maintaining fine-tuning performance. As a by-product, we analyze the optimized perturbation and show that different layers in various LLMs have distinct safety coefficients. Source code available at https://github.com/w-yibo/Panacea
Merging Models on the Fly Without Retraining: A Sequential Approach to Scalable Continual Model Merging
Jan 16, 2025



Deep model merging represents an emerging research direction that combines multiple fine-tuned models to harness their specialized capabilities across different tasks and domains. Current model merging techniques focus on merging all available models simultaneously, with weight interpolation-based methods being the predominant approaches. However, these conventional approaches are not well-suited for scenarios where models become available sequentially, and they often suffer from high memory requirements and potential interference between tasks. In this study, we propose a training-free projection-based continual merging method that processes models sequentially through orthogonal projections of weight matrices and adaptive scaling mechanisms. Our method operates by projecting new parameter updates onto subspaces orthogonal to existing merged parameter updates while using an adaptive scaling mechanism to maintain stable parameter distances, enabling efficient sequential integration of task-specific knowledge. Our approach maintains constant memory complexity to the number of models, minimizes interference between tasks through orthogonal projections, and retains the performance of previously merged models through adaptive task vector scaling. Extensive experiments on CLIP-ViT models demonstrate that our method achieves a 5-8% average accuracy improvement while maintaining robust performance in different task orderings.
Modeling Multi-Task Model Merging as Adaptive Projective Gradient Descent
Jan 02, 2025



Merging multiple expert models offers a promising approach for performing multi-task learning without accessing their original data. Existing methods attempt to alleviate task conflicts by sparsifying task vectors or promoting orthogonality among them. However, they overlook the fundamental requirement of model merging: ensuring the merged model performs comparably to task-specific models on respective tasks. We find these methods inevitably discard task-specific information that, while causing conflicts, is crucial for performance. Based on our findings, we frame model merging as a constrained optimization problem ($\textit{i.e.}$, minimizing the gap between the merged model and individual models, subject to the constraint of retaining shared knowledge) and solve it via adaptive projective gradient descent. Specifically, we align the merged model with individual models by decomposing and reconstituting the loss function, alleviating conflicts through $\textit{data-free}$ optimization of task vectors. To retain shared knowledge, we optimize this objective by projecting gradients within a $\textit{shared subspace}$ spanning all tasks. Moreover, we view merging coefficients as adaptive learning rates and propose a task-aware, training-free strategy. Experiments show that our plug-and-play approach consistently outperforms previous methods, achieving state-of-the-art results across diverse architectures and tasks in both vision and NLP domains.