 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge AI Model Empowered Multimodal Semantic Communications
Sep 03, 2023



Multimodal signals, including text, audio, image and video, can be integrated into Semantic Communication (SC) for providing an immersive experience with low latency and high quality at the semantic level. However, the multimodal SC has several challenges, including data heterogeneity, semantic ambiguity, and signal fading. Recent advancements in large AI models, particularly in Multimodal Language Model (MLM) and Large Language Model (LLM), offer potential solutions for these issues. To this end, we propose a Large AI Model-based Multimodal SC (LAM-MSC) framework, in which we first present the MLM-based Multimodal Alignment (MMA) that utilizes the MLM to enable the transformation between multimodal and unimodal data while preserving semantic consistency. Then, a personalized LLM-based Knowledge Base (LKB) is proposed, which allows users to perform personalized semantic extraction or recovery through the LLM. This effectively addresses the semantic ambiguity. Finally, we apply the Conditional Generative adversarial networks-based channel Estimation (CGE) to obtain Channel State Information (CSI). This approach effectively mitigates the impact of fading channels in SC. Finally, we conduct simulations that demonstrate the superior performance of the LAM-MSC framework.
LAMBO: Large Language Model Empowered Edge Intelligence
Aug 29, 2023Next-generation edge intelligence is anticipated to bring huge benefits to various applications, e.g., offloading systems. However, traditional deep offloading architectures face several issues, including heterogeneous constraints, partial perception, uncertain generalization, and lack of tractability. In this context, the integration of offloading with large language models (LLMs) presents numerous advantages. Therefore, we propose an LLM-Based Offloading (LAMBO) framework for mobile edge computing (MEC), which comprises four components: (i) Input embedding (IE), which is used to represent the information of the offloading system with constraints and prompts through learnable vectors with high quality; (ii) Asymmetric encoderdecoder (AED) model, which is a decision-making module with a deep encoder and a shallow decoder. It can achieve high performance based on multi-head self-attention schemes; (iii) Actor-critic reinforcement learning (ACRL) module, which is employed to pre-train the whole AED for different optimization tasks under corresponding prompts; and (iv) Active learning from expert feedback (ALEF), which can be used to finetune the decoder part of the AED while adapting to dynamic environmental changes. Our simulation results corroborate the advantages of the proposed LAMBO framework.
Retentive Network: A Successor to Transformer for Large Language Models
Aug 09, 2023In this work, we propose Retentive Network (RetNet) as a foundation architecture for large language models, simultaneously achieving training parallelism, low-cost inference, and good performance. We theoretically derive the connection between recurrence and attention. Then we propose the retention mechanism for sequence modeling, which supports three computation paradigms, i.e., parallel, recurrent, and chunkwise recurrent. Specifically, the parallel representation allows for training parallelism. The recurrent representation enables low-cost $O(1)$ inference, which improves decoding throughput, latency, and GPU memory without sacrificing performance. The chunkwise recurrent representation facilitates efficient long-sequence modeling with linear complexity, where each chunk is encoded parallelly while recurrently summarizing the chunks. Experimental results on language modeling show that RetNet achieves favorable scaling results, parallel training, low-cost deployment, and efficient inference. The intriguing properties make RetNet a strong successor to Transformer for large language models. Code will be available at https://aka.ms/retnet.
Evil Operation: Breaking Speaker Recognition with PaddingBack
Aug 08, 2023



Machine Learning as a Service (MLaaS) has gained popularity due to advancements in machine learning. However, untrusted third-party platforms have raised concerns about AI security, particularly in backdoor attacks. Recent research has shown that speech backdoors can utilize transformations as triggers, similar to image backdoors. However, human ears easily detect these transformations, leading to suspicion. In this paper, we introduce PaddingBack, an inaudible backdoor attack that utilizes malicious operations to make poisoned samples indistinguishable from clean ones. Instead of using external perturbations as triggers, we exploit the widely used speech signal operation, padding, to break speaker recognition systems. Our experimental results demonstrate the effectiveness of the proposed approach, achieving a significantly high attack success rate while maintaining a high rate of benign accuracy. Furthermore, PaddingBack demonstrates the ability to resist defense methods while maintaining its stealthiness against human perception. The results of the stealthiness experiment have been made available at https://nbufabio25.github.io/paddingback/.
Universal Defensive Underpainting Patch: Making Your Text Invisible to Optical Character Recognition
Aug 04, 2023



Optical Character Recognition (OCR) enables automatic text extraction from scanned or digitized text images, but it also makes it easy to pirate valuable or sensitive text from these images. Previous methods to prevent OCR piracy by distorting characters in text images are impractical in real-world scenarios, as pirates can capture arbitrary portions of the text images, rendering the defenses ineffective. In this work, we propose a novel and effective defense mechanism termed the Universal Defensive Underpainting Patch (UDUP) that modifies the underpainting of text images instead of the characters. UDUP is created through an iterative optimization process to craft a small, fixed-size defensive patch that can generate non-overlapping underpainting for text images of any size. Experimental results show that UDUP effectively defends against unauthorized OCR under the setting of any screenshot range or complex image background. It is agnostic to the content, size, colors, and languages of characters, and is robust to typical image operations such as scaling and compressing. In addition, the transferability of UDUP is demonstrated by evading several off-the-shelf OCRs. The code is available at https://github.com/QRICKDD/UDUP.
LongNet: Scaling Transformers to 1,000,000,000 Tokens
Jul 19, 2023Scaling sequence length has become a critical demand in the era of large language models. However, existing methods struggle with either computational complexity or model expressivity, rendering the maximum sequence length restricted. To address this issue, we introduce LongNet, a Transformer variant that can scale sequence length to more than 1 billion tokens, without sacrificing the performance on shorter sequences. Specifically, we propose dilated attention, which expands the attentive field exponentially as the distance grows. LongNet has significant advantages: 1) it has a linear computation complexity and a logarithm dependency between any two tokens in a sequence; 2) it can be served as a distributed trainer for extremely long sequences; 3) its dilated attention is a drop-in replacement for standard attention, which can be seamlessly integrated with the existing Transformer-based optimization. Experiments results demonstrate that LongNet yields strong performance on both long-sequence modeling and general language tasks. Our work opens up new possibilities for modeling very long sequences, e.g., treating a whole corpus or even the entire Internet as a sequence.
Kosmos-2: Grounding Multimodal Large Language Models to the World
Jul 13, 2023
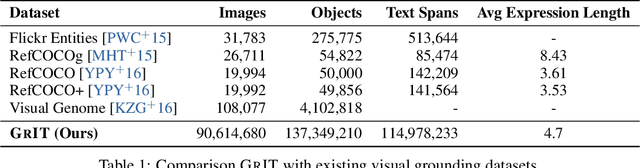

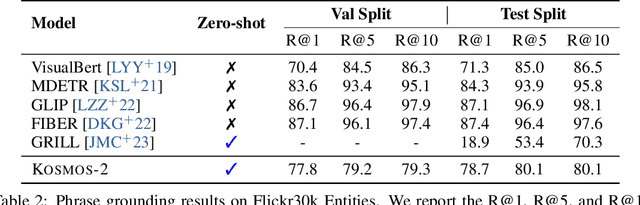
We introduce Kosmos-2, a Multimodal Large Language Model (MLLM), enabling new capabilities of perceiving object descriptions (e.g., bounding boxes) and grounding text to the visual world. Specifically, we represent refer expressions as links in Markdown, i.e., ``[text span](bounding boxes)'', where object descriptions are sequences of location tokens. Together with multimodal corpora, we construct large-scale data of grounded image-text pairs (called GrIT) to train the model. In addition to the existing capabilities of MLLMs (e.g., perceiving general modalities, following instructions, and performing in-context learning), Kosmos-2 integrates the grounding capability into downstream applications. We evaluate Kosmos-2 on a wide range of tasks, including (i) multimodal grounding, such as referring expression comprehension, and phrase grounding, (ii) multimodal referring, such as referring expression generation, (iii) perception-language tasks, and (iv) language understanding and generation. This work lays out the foundation for the development of Embodiment AI and sheds light on the big convergence of language, multimodal perception, action, and world modeling, which is a key step toward artificial general intelligence. Code and pretrained models are available at https://aka.ms/kosmos-2.
Large AI Model-Based Semantic Communications
Jul 07, 2023



Semantic communication (SC) is an emerging intelligent paradigm, offering solutions for various future applications like metaverse, mixed-reality, and the Internet of everything. However, in current SC systems, the construction of the knowledge base (KB) faces several issues, including limited knowledge representation, frequent knowledge updates, and insecure knowledge sharing. Fortunately, the development of the large AI model provides new solutions to overcome above issues. Here, we propose a large AI model-based SC framework (LAM-SC) specifically designed for image data, where we first design the segment anything model (SAM)-based KB (SKB) that can split the original image into different semantic segments by universal semantic knowledge. Then, we present an attention-based semantic integration (ASI) to weigh the semantic segments generated by SKB without human participation and integrate them as the semantic-aware image. Additionally, we propose an adaptive semantic compression (ASC) encoding to remove redundant information in semantic features, thereby reducing communication overhead. Finally, through simulations, we demonstrate the effectiveness of the LAM-SC framework and the significance of the large AI model-based KB development in future SC paradigms.
Fake the Real: Backdoor Attack on Deep Speech Classification via Voice Conversion
Jun 28, 2023Deep speech classification has achieved tremendous success and greatly promoted the emergence of many real-world applications. However, backdoor attacks present a new security threat to it, particularly with untrustworthy third-party platforms, as pre-defined triggers set by the attacker can activate the backdoor. Most of the triggers in existing speech backdoor attacks are sample-agnostic, and even if the triggers are designed to be unnoticeable, they can still be audible. This work explores a backdoor attack that utilizes sample-specific triggers based on voice conversion. Specifically, we adopt a pre-trained voice conversion model to generate the trigger, ensuring that the poisoned samples does not introduce any additional audible noise. Extensive experiments on two speech classification tasks demonstrate the effectiveness of our attack. Furthermore, we analyzed the specific scenarios that activated the proposed backdoor and verified its resistance against fine-tuning.
Semi-Offline Reinforcement Learning for Optimized Text Generation
Jun 16, 2023



In reinforcement learning (RL), there are two major settings for interacting with the environment: online and offline. Online methods explore the environment at significant time cost, and offline methods efficiently obtain reward signals by sacrificing exploration capability. We propose semi-offline RL, a novel paradigm that smoothly transits from offline to online settings, balances exploration capability and training cost, and provides a theoretical foundation for comparing different RL settings. Based on the semi-offline formulation, we present the RL setting that is optimal in terms of optimization cost, asymptotic error, and overfitting error bound. Extensive experiments show that our semi-offline approach is efficient and yields comparable or often better performance compared with state-of-the-art methods.