 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Optimize via Wasserstein Deep Inverse Optimal Control
May 22, 2018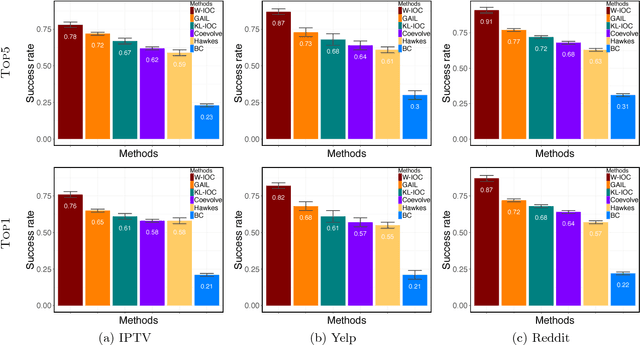
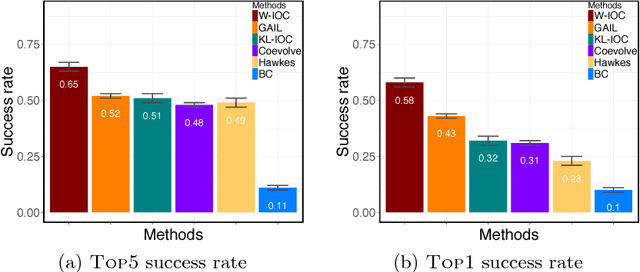
We study the inverse optimal control problem in social sciences: we aim at learning a user's true cost function from the observed temporal behavior. In contrast to traditional phenomenological works that aim to learn a generative model to fit the behavioral data, we propose a novel variational principle and treat user as a reinforcement learning algorithm, which acts by optimizing his cost function. We first propose a unified KL framework that generalizes existing maximum entropy inverse optimal control methods. We further propose a two-step Wasserstein inverse optimal control framework. In the first step, we compute the optimal measure with a novel mass transport equation. In the second step, we formulate the learning problem as a generative adversarial network. In two real world experiments - recommender systems and social networks, we show that our framework obtains significant performance gains over both existing inverse optimal control methods and point process based generative models.
Decoupled Networks
Apr 22, 2018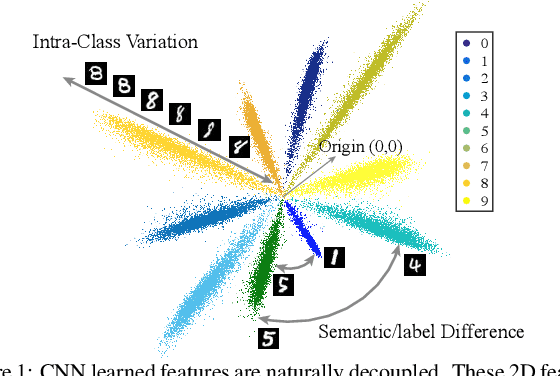

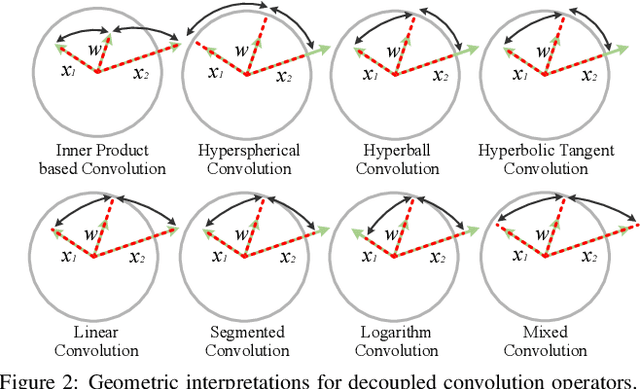
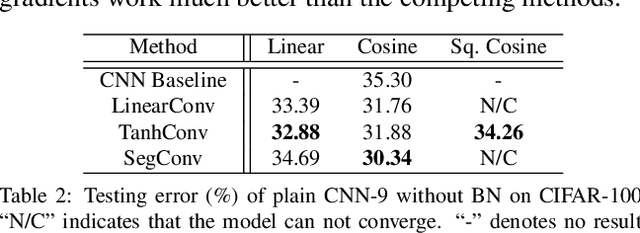
Inner product-based convolution has been a central component of convolutional neural networks (CNNs) and the key to learning visual representations. Inspired by the observation that CNN-learned features are naturally decoupled with the norm of features corresponding to the intra-class variation and the angle corresponding to the semantic difference, we propose a generic decoupled learning framework which models the intra-class variation and semantic difference independently. Specifically, we first reparametrize the inner product to a decoupled form and then generalize it to the decoupled convolution operator which serves as the building block of our decoupled networks. We present several effective instances of the decoupled convolution operator. Each decoupled operator is well motivated and has an intuitive geometric interpretation. Based on these decoupled operators, we further propose to directly learn the operator from data. Extensive experiments show that such decoupled reparameterization renders significant performance gain with easier convergence and stronger robustness.
Iterative Learning with Open-set Noisy Labels
Mar 31, 2018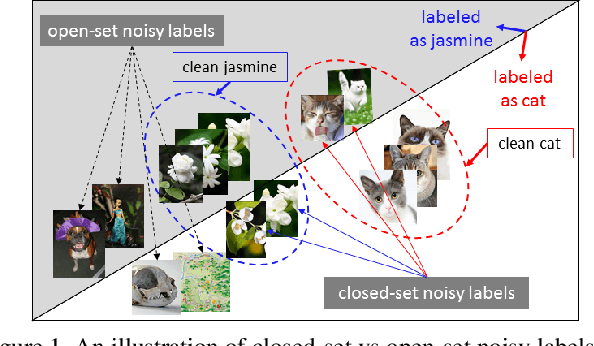

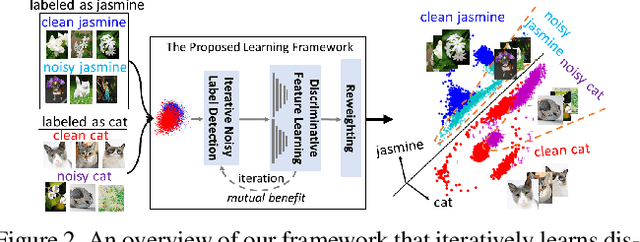
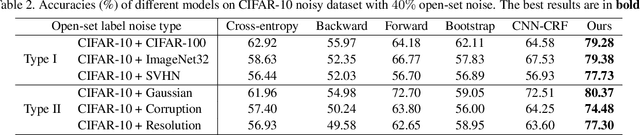
Large-scale datasets possessing clean label annotations are crucial for training Convolutional Neural Networks (CNNs). However, labeling large-scale data can be very costly and error-prone, and even high-quality datasets are likely to contain noisy (incorrect) labels. Existing works usually employ a closed-set assumption, whereby the samples associated with noisy labels possess a true class contained within the set of known classes in the training data. However, such an assumption is too restrictive for many applications, since samples associated with noisy labels might in fact possess a true class that is not present in the training data. We refer to this more complex scenario as the \textbf{open-set noisy label} problem and show that it is nontrivial in order to make accurate predictions. To address this problem, we propose a novel iterative learning framework for training CNNs on datasets with open-set noisy labels. Our approach detects noisy labels and learns deep discriminative features in an iterative fashion. To benefit from the noisy label detection, we design a Siamese network to encourage clean labels and noisy labels to be dissimilar. A reweighting module is also applied to simultaneously emphasize the learning from clean labels and reduce the effect caused by noisy labels. Experiments on CIFAR-10, ImageNet and real-world noisy (web-search) datasets demonstrate that our proposed model can robustly train CNNs in the presence of a high proportion of open-set as well as closed-set noisy labels.
Stochastic Training of Graph Convolutional Networks with Variance Reduction
Mar 01, 2018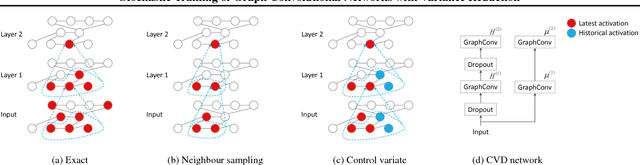
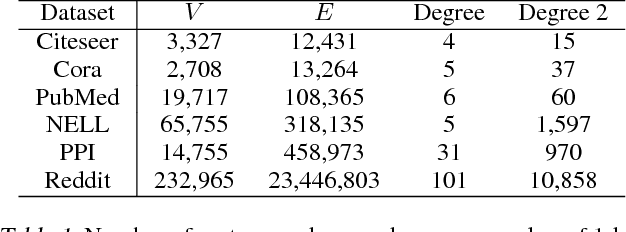
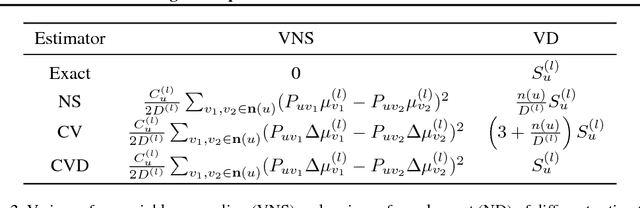
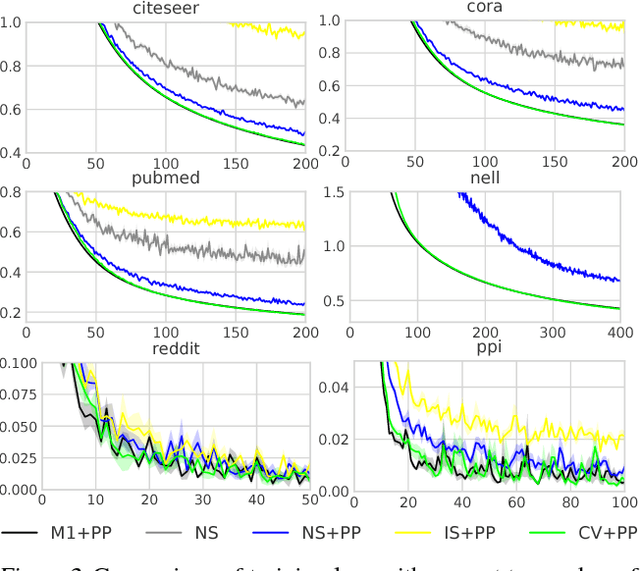
Graph convolutional networks (GCNs) are powerful deep neural networks for graph-structured data. However, GCN computes the representation of a node recursively from its neighbors, making the receptive field size grow exponentially with the number of layers. Previous attempts on reducing the receptive field size by subsampling neighbors do not have a convergence guarantee, and their receptive field size per node is still in the order of hundreds. In this paper, we develop control variate based algorithms which allow sampling an arbitrarily small neighbor size. Furthermore, we prove new theoretical guarantee for our algorithms to converge to a local optimum of GCN. Empirical results show that our algorithms enjoy a similar convergence with the exact algorithm using only two neighbors per node. The runtime of our algorithms on a large Reddit dataset is only one seventh of previous neighbor sampling algorithms.
Syntax-Directed Variational Autoencoder for Structured Data
Feb 24, 2018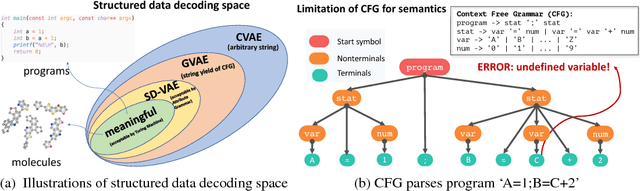
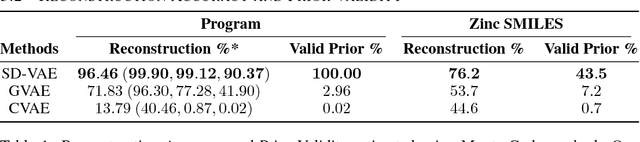
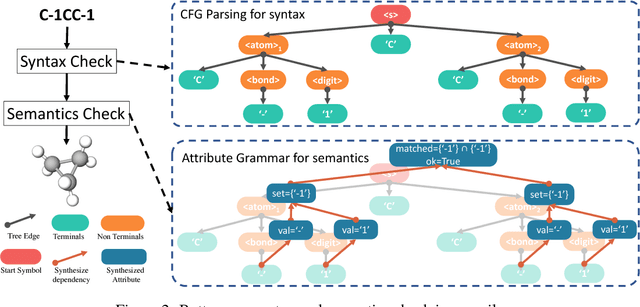
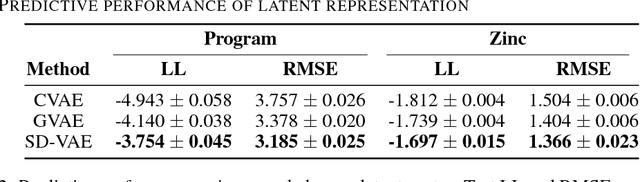
Deep generative models have been enjoying success in modeling continuous data. However it remains challenging to capture the representations for discrete structures with formal grammars and semantics, e.g., computer programs and molecular structures. How to generate both syntactically and semantically correct data still remains largely an open problem. Inspired by the theory of compiler where the syntax and semantics check is done via syntax-directed translation (SDT), we propose a novel syntax-directed variational autoencoder (SD-VAE) by introducing stochastic lazy attributes. This approach converts the offline SDT check into on-the-fly generated guidance for constraining the decoder. Comparing to the state-of-the-art methods, our approach enforces constraints on the output space so that the output will be not only syntactically valid, but also semantically reasonable. We evaluate the proposed model with applications in programming language and molecules, including reconstruction and program/molecule optimization. The results demonstrate the effectiveness in incorporating syntactic and semantic constraints in discrete generative models, which is significantly better than current state-of-the-art approaches.
Learning Combinatorial Optimization Algorithms over Graphs
Feb 21, 2018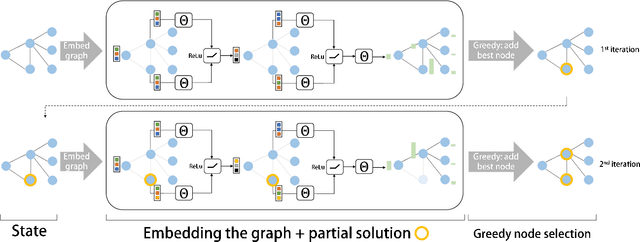

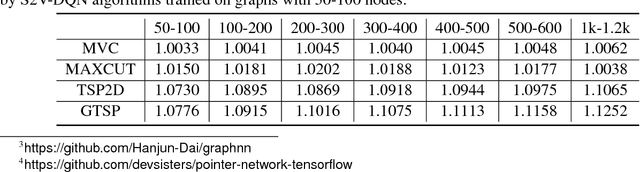
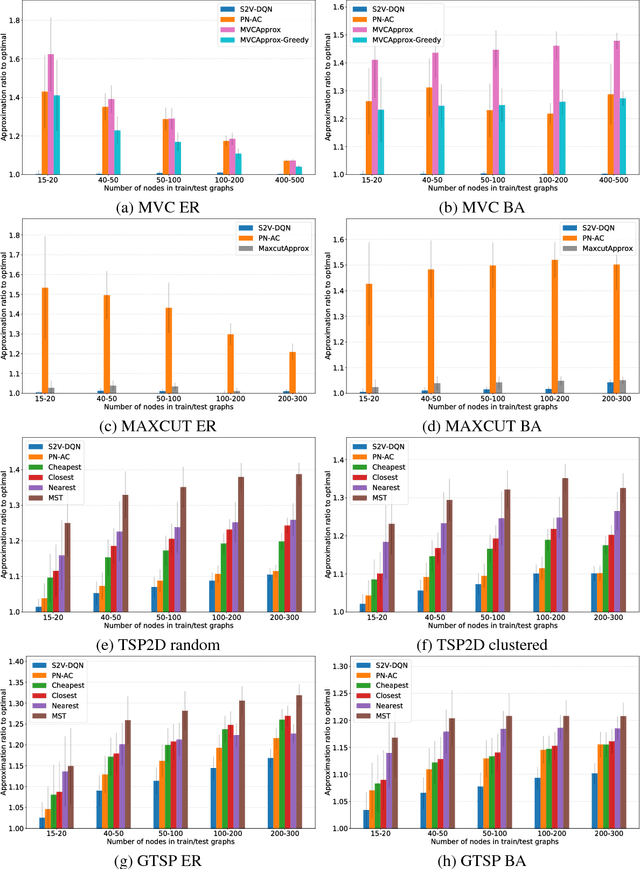
The design of good heuristics or approximation algorithms for NP-hard combinatorial optimization problems often requires significant specialized knowledge and trial-and-error. Can we automate this challenging, tedious process, and learn the algorithms instead? In many real-world applications, it is typically the case that the same optimization problem is solved again and again on a regular basis, maintaining the same problem structure but differing in the data. This provides an opportunity for learning heuristic algorithms that exploit the structure of such recurring problems. In this paper, we propose a unique combination of reinforcement learning and graph embedding to address this challenge. The learned greedy policy behaves like a meta-algorithm that incrementally constructs a solution, and the action is determined by the output of a graph embedding network capturing the current state of the solution. We show that our framework can be applied to a diverse range of optimization problems over graphs, and learns effective algorithms for the Minimum Vertex Cover, Maximum Cut and Traveling Salesman problems.
Deep Hyperspherical Learning
Jan 30, 2018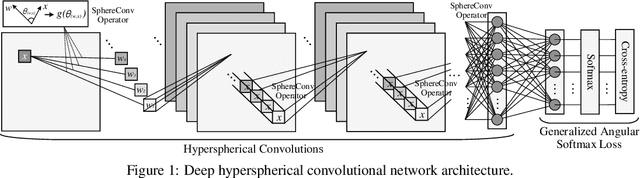
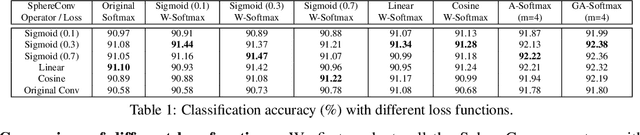
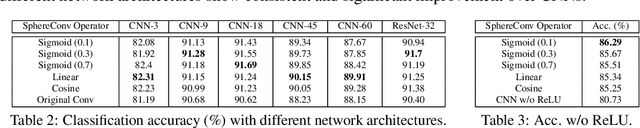
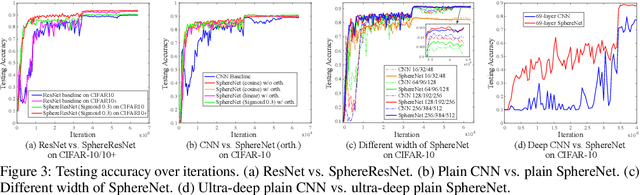
Convolution as inner product has been the founding basis of convolutional neural networks (CNNs) and the key to end-to-end visual representation learning. Benefiting from deeper architectures, recent CNNs have demonstrated increasingly strong representation abilities. Despite such improvement, the increased depth and larger parameter space have also led to challenges in properly training a network. In light of such challenges, we propose hyperspherical convolution (SphereConv), a novel learning framework that gives angular representations on hyperspheres. We introduce SphereNet, deep hyperspherical convolution networks that are distinct from conventional inner product based convolutional networks. In particular, SphereNet adopts SphereConv as its basic convolution operator and is supervised by generalized angular softmax loss - a natural loss formulation under SphereConv. We show that SphereNet can effectively encode discriminative representation and alleviate training difficulty, leading to easier optimization, faster convergence and comparable (even better) classification accuracy over convolutional counterparts. We also provide some theoretical insights for the advantages of learning on hyperspheres. In addition, we introduce the learnable SphereConv, i.e., a natural improvement over prefixed SphereConv, and SphereNorm, i.e., hyperspherical learning as a normalization method. Experiments have verified our conclusions.
SphereFace: Deep Hypersphere Embedding for Face Recognition
Jan 29, 2018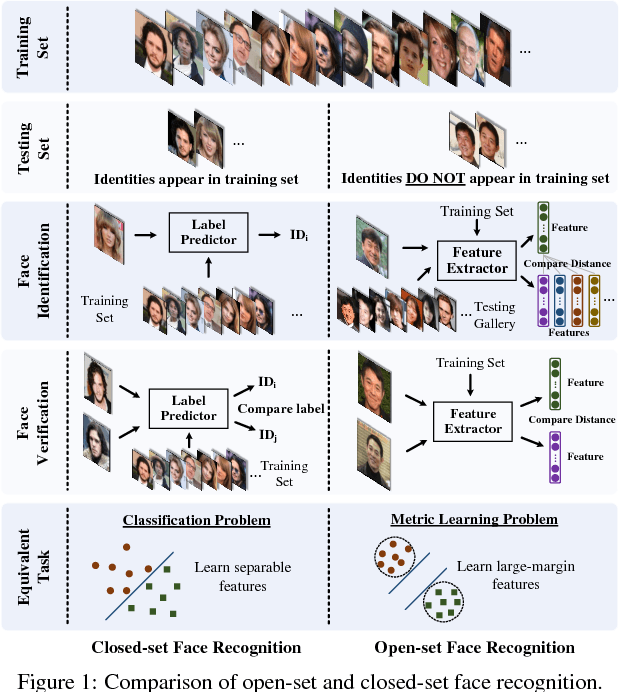
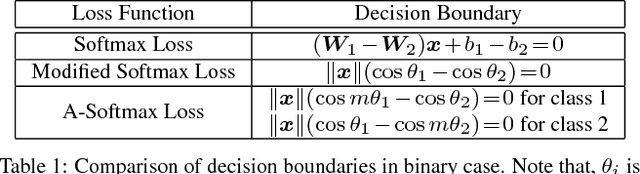

This paper addresses deep face recognition (FR) problem under open-set protocol, where ideal face features are expected to have smaller maximal intra-class distance than minimal inter-class distance under a suitably chosen metric space. However, few existing algorithms can effectively achieve this criterion. To this end, we propose the angular softmax (A-Softmax) loss that enables convolutional neural networks (CNNs) to learn angularly discriminative features. Geometrically, A-Softmax loss can be viewed as imposing discriminative constraints on a hypersphere manifold, which intrinsically matches the prior that faces also lie on a manifold. Moreover, the size of angular margin can be quantitatively adjusted by a parameter $m$. We further derive specific $m$ to approximate the ideal feature criterion. Extensive analysis and experiments on Labeled Face in the Wild (LFW), Youtube Faces (YTF) and MegaFace Challenge show the superiority of A-Softmax loss in FR tasks. The code has also been made publicly available.
Boosting the Actor with Dual Critic
Dec 29, 2017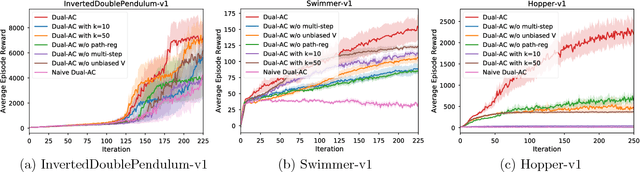
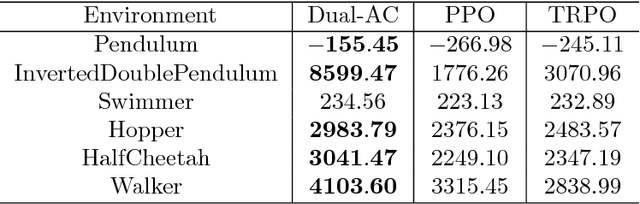
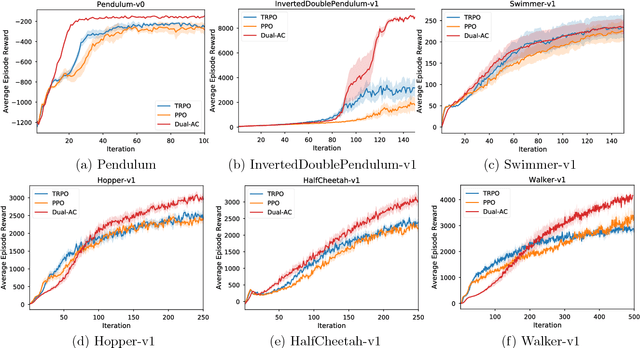
This paper proposes a new actor-critic-style algorithm called Dual Actor-Critic or Dual-AC. It is derived in a principled way from the Lagrangian dual form of the Bellman optimality equation, which can be viewed as a two-player game between the actor and a critic-like function, which is named as dual critic. Compared to its actor-critic relatives, Dual-AC has the desired property that the actor and dual critic are updated cooperatively to optimize the same objective function, providing a more transparent way for learning the critic that is directly related to the objective function of the actor. We then provide a concrete algorithm that can effectively solve the minimax optimization problem, using techniques of multi-step bootstrapping, path regularization, and stochastic dual ascent algorithm. We demonstrate that the proposed algorithm achieves the state-of-the-art performances across several benchmarks.
Variational Reasoning for Question Answering with Knowledge Graph
Nov 27, 2017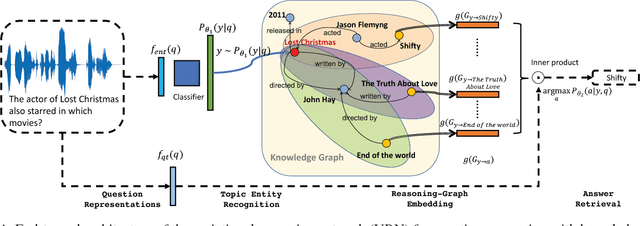

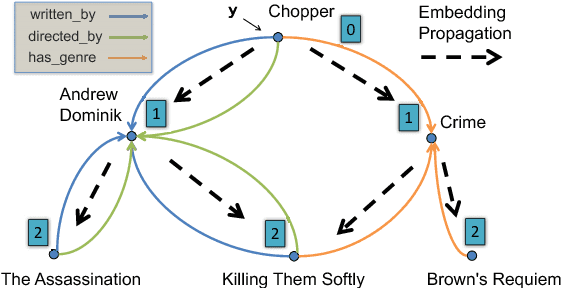

Knowledge graph (KG) is known to be helpful for the task of question answering (QA), since it provides well-structured relational information between entities, and allows one to further infer indirect facts. However, it is challenging to build QA systems which can learn to reason over knowledge graphs based on question-answer pairs alone. First, when people ask questions, their expressions are noisy (for example, typos in texts, or variations in pronunciations), which is non-trivial for the QA system to match those mentioned entities to the knowledge graph. Second, many questions require multi-hop logic reasoning over the knowledge graph to retrieve the answers. To address these challenges, we propose a novel and unified deep learning architecture, and an end-to-end variational learning algorithm which can handle noise in questions, and learn multi-hop reasoning simultaneously. Our method achieves state-of-the-art performance on a recent benchmark dataset in the literature. We also derive a series of new benchmark datasets, including questions for multi-hop reasoning, questions paraphrased by neural translation model, and questions in human voice. Our method yields very promising results on all these challenging datasets.