 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynbols: Probing Learning Algorithms with Synthetic Datasets
Sep 14, 2020
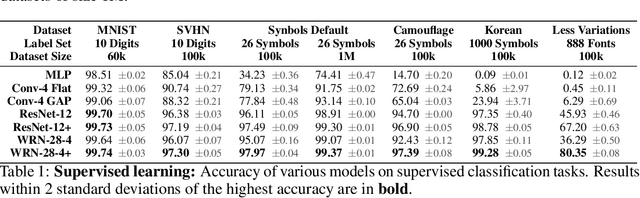
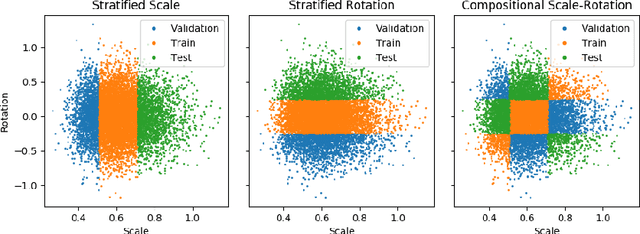
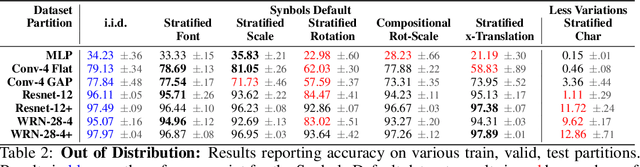
Progress in the field of machine learning has been fueled by the introduction of benchmark datasets pushing the limits of existing algorithms. Enabling the design of datasets to test specific properties and failure modes of learning algorithms is thus a problem of high interest, as it has a direct impact on innovation in the field. In this sense, we introduce Synbols -- Synthetic Symbols -- a tool for rapidly generating new datasets with a rich composition of latent features rendered in low resolution images. Synbols leverages the large amount of symbols available in the Unicode standard and the wide range of artistic font provided by the open font community. Our tool's high-level interface provides a language for rapidly generating new distributions on the latent features, including various types of textures and occlusions. To showcase the versatility of Synbols, we use it to dissect the limitations and flaws in standard learning algorithms in various learning setups including supervised learning, active learning, out of distribution generalization, unsupervised representation learning, and object counting.
A Large-Scale, Open-Domain, Mixed-Interface Dialogue-Based ITS for STEM
May 06, 2020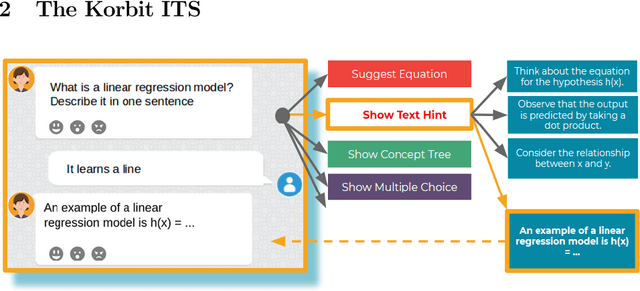
We present Korbit, a large-scale, open-domain, mixed-interface, dialogue-based intelligent tutoring system (ITS). Korbit uses machine learning, natural language processing and reinforcement learning to provide interactive, personalized learning online. Korbit has been designed to easily scale to thousands of subjects, by automating, standardizing and simplifying the content creation process. Unlike other ITS, a teacher can develop new learning modules for Korbit in a matter of hours. To facilitate learning across a widerange of STEM subjects, Korbit uses a mixed-interface, which includes videos, interactive dialogue-based exercises, question-answering, conceptual diagrams, mathematical exercises and gamification elements. Korbit has been built to scale to millions of students, by utilizing a state-of-the-art cloud-based micro-service architecture. Korbit launched its first course in 2019 on machine learning, and since then over 7,000 students have enrolled. Although Korbit was designed to be open-domain and highly scalable, A/B testing experiments with real-world students demonstrate that both student learning outcomes and student motivation are substantially improved compared to typical online courses.
IG-RL: Inductive Graph Reinforcement Learning for Massive-Scale Traffic Signal Control
Mar 19, 2020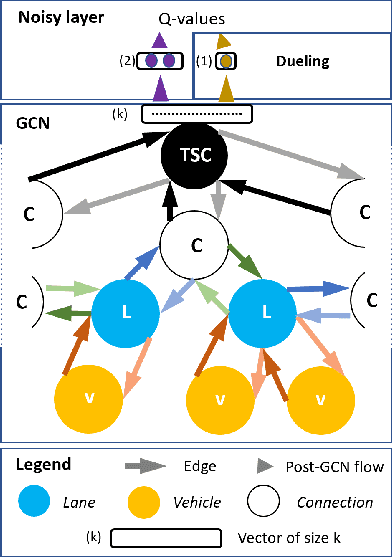

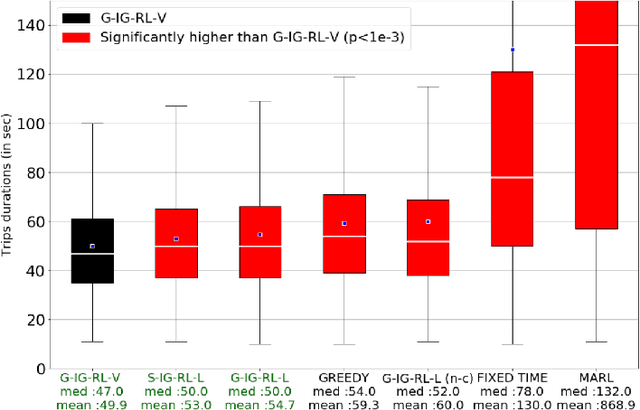
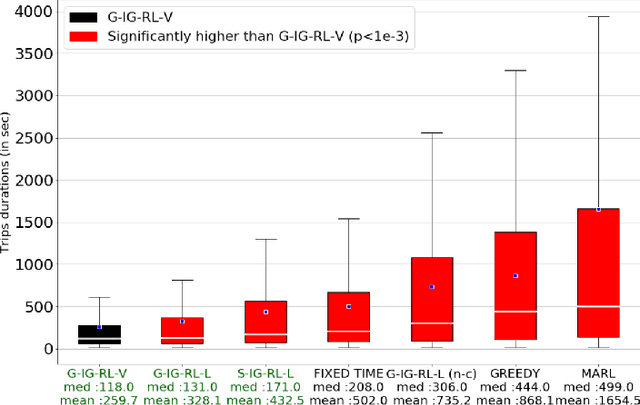
Scaling adaptive traffic-signal control involves dealing with combinatorial state and action spaces. Multi-agent reinforcement learning attempts to address this challenge by distributing control to specialized agents. However, specialization hinders generalization and transferability, and the computational graphs underlying neural-networks architectures---dominating in the multi-agent setting---do not offer the flexibility to handle an arbitrary number of entities which changes both between road networks, and over time as vehicles traverse the network. We introduce Inductive Graph Reinforcement Learning (IG-RL) based on graph-convolutional networks which adapts to the structure of any road network, to learn detailed representations of traffic-controllers and their surroundings. Our decentralized approach enables learning of a transferable-adaptive-traffic-signal-control policy. After being trained on an arbitrary set of road networks, our model can generalize to new road networks, traffic distributions, and traffic regimes, with no additional training and a constant number of parameters, enabling greater scalability compared to prior methods. Furthermore, our approach can exploit the granularity of available data by capturing the (dynamic) demand at both the lane and the vehicle levels. The proposed method is tested on both road networks and traffic settings never experienced during training. We compare IG-RL to multi-agent reinforcement learning and domain-specific baselines. In both synthetic road networks and in a larger experiment involving the control of the 3,971 traffic signals of Manhattan, we show that different instantiations of IG-RL outperform baselines.
Online Fast Adaptation and Knowledge Accumulation: a New Approach to Continual Learning
Mar 12, 2020
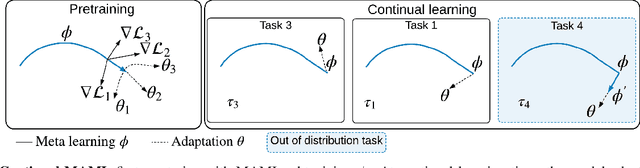
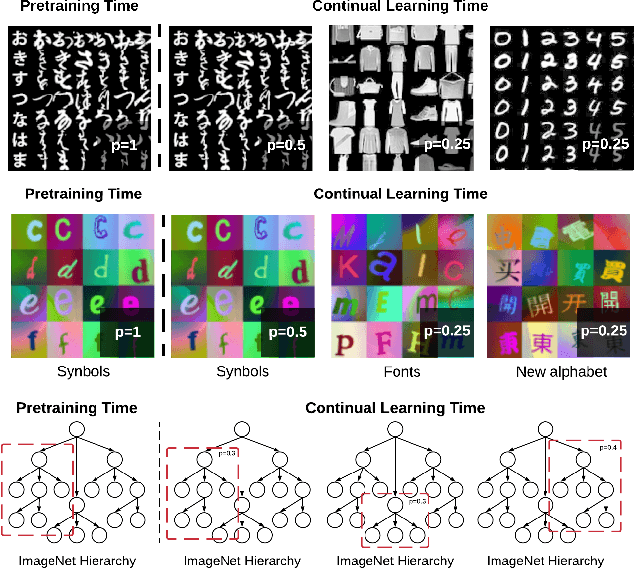
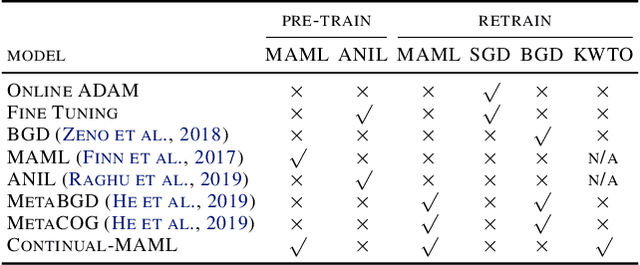
Learning from non-stationary data remains a great challenge for machine learning. Continual learning addresses this problem in scenarios where the learning agent faces a stream of changing tasks. In these scenarios, the agent is expected to retain its highest performance on previous tasks without revisiting them while adapting well to the new tasks. Two new recent continual-learning scenarios have been proposed. In meta-continual learning, the model is pre-trained to minimize catastrophic forgetting when trained on a sequence of tasks. In continual-meta learning, the goal is faster remembering, i.e., focusing on how quickly the agent recovers performance rather than measuring the agent's performance without any adaptation. Both scenarios have the potential to propel the field forward. Yet in their original formulations, they each have limitations. As a remedy, we propose a more general scenario where an agent must quickly solve (new) out-of-distribution tasks, while also requiring fast remembering. We show that current continual learning, meta learning, meta-continual learning, and continual-meta learning techniques fail in this new scenario. Accordingly, we propose a strong baseline: Continual-MAML, an online extension of the popular MAML algorithm. In our empirical experiments, we show that our method is better suited to the new scenario than the methodologies mentioned above, as well as standard continual learning and meta learning approaches.
Online Continual Learning with Maximally Interfered Retrieval
Aug 23, 2019



Continual learning, the setting where a learning agent is faced with a never ending stream of data, continues to be a great challenge for modern machine learning systems. In particular the online or "single-pass through the data" setting has gained attention recently as a natural setting that is difficult to tackle. Methods based on replay, either generative or from a stored memory, have been shown to be effective approaches for continual learning, matching or exceeding the state of the art in a number of standard benchmarks. These approaches typically rely on randomly selecting samples from the replay memory or from a generative model, which is suboptimal. In this work we consider a controlled sampling of memories for replay. We retrieve the samples which are most interfered, i.e. whose prediction will be most negatively impacted by the foreseen parameters update. We show a formulation for this sampling criterion in both the generative replay and the experience replay setting, producing consistent gains in performance and greatly reduced forgetting.
Exact Combinatorial Optimization with Graph Convolutional Neural Networks
Jun 07, 2019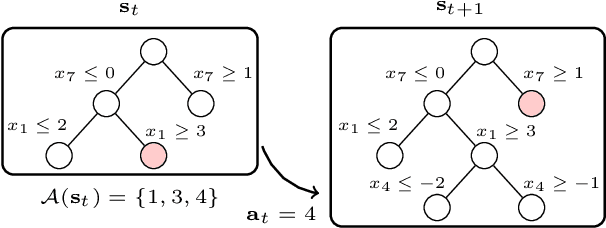
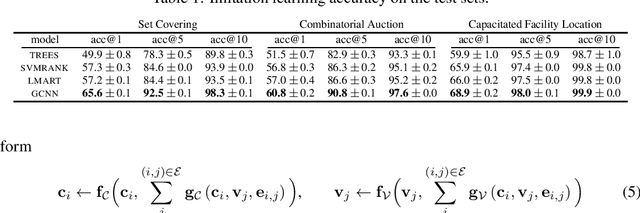
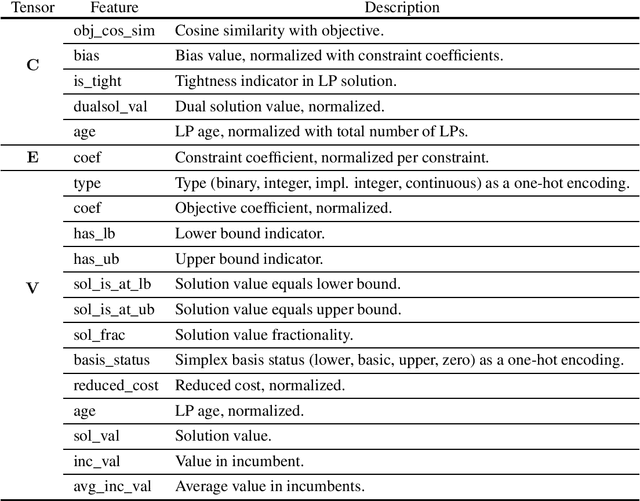
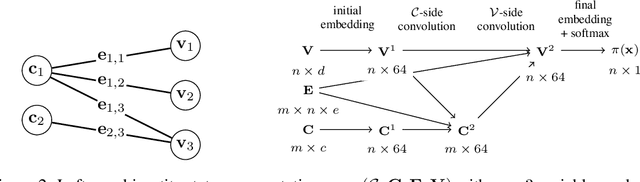
Combinatorial optimization problems are typically tackled by the branch-and-bound paradigm. We propose a new graph convolutional neural network model for learning branch-and-bound variable selection policies, which leverages the natural variable-constraint bipartite graph representation of mixed-integer linear programs. We train our model via imitation learning from the strong branching expert rule, and demonstrate on a series of hard problems that our approach produces policies that improve upon state-of-the-art machine-learning methods for branching and generalize to instances significantly larger than seen during training. Moreover, we improve for the first time over expert-designed branching rules implemented in a state-of-the-art solver on large problems. Code for reproducing all the experiments can be found at https://github.com/ds4dm/learn2branch.
Continual Learning of New Sound Classes using Generative Replay
Jun 03, 2019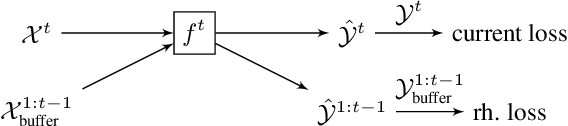

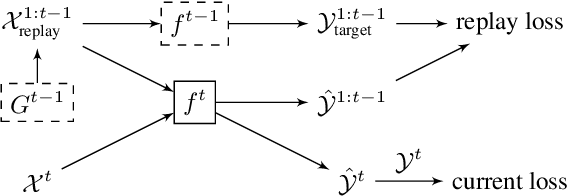
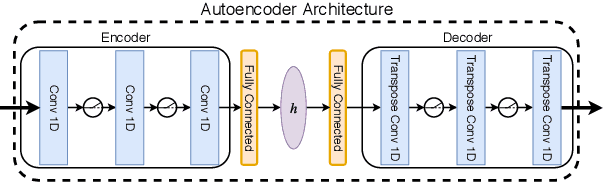
Continual learning consists in incrementally training a model on a sequence of datasets and testing on the union of all datasets. In this paper, we examine continual learning for the problem of sound classification, in which we wish to refine already trained models to learn new sound classes. In practice one does not want to maintain all past training data and retrain from scratch, but naively updating a model with new data(sets) results in a degradation of already learned tasks, which is referred to as "catastrophic forgetting." We develop a generative replay procedure for generating training audio spectrogram data, in place of keeping older training datasets. We show that by incrementally refining a classifier with generative replay a generator that is 4% of the size of all previous training data matches the performance of refining the classifier keeping 20% of all previous training data. We thus conclude that we can extend a trained sound classifier to learn new classes without having to keep previously used datasets.
Towards Deep Conversational Recommendations
Dec 18, 2018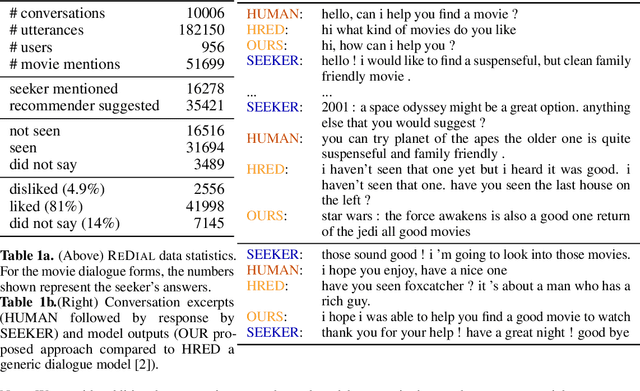
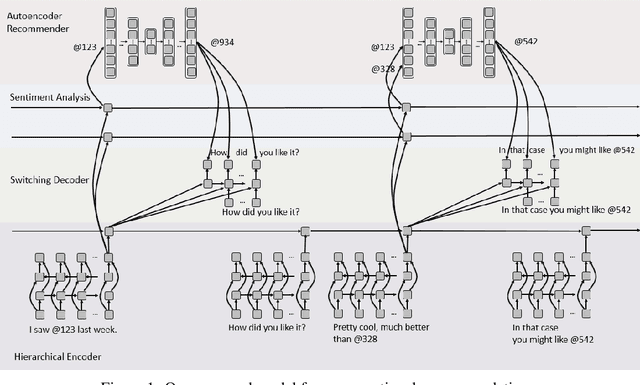


There has been growing interest in using neural networks and deep learning techniques to create dialogue systems. Conversational recommendation is an interesting setting for the scientific exploration of dialogue with natural language as the associated discourse involves goal-driven dialogue that often transforms naturally into more free-form chat. This paper provides two contributions. First, until now there has been no publicly available large-scale dataset consisting of real-world dialogues centered around recommendations. To address this issue and to facilitate our exploration here, we have collected ReDial, a dataset consisting of over 10,000 conversations centered around the theme of providing movie recommendations. We make this data available to the community for further research. Second, we use this dataset to explore multiple facets of conversational recommendations. In particular we explore new neural architectures, mechanisms, and methods suitable for composing conversational recommendation systems. Our dataset allows us to systematically probe model sub-components addressing different parts of the overall problem domain ranging from: sentiment analysis and cold-start recommendation generation to detailed aspects of how natural language is used in this setting in the real world. We combine such sub-components into a full-blown dialogue system and examine its behavior.
Language GANs Falling Short
Nov 08, 2018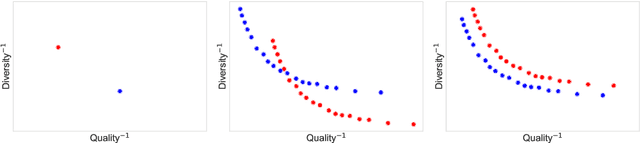

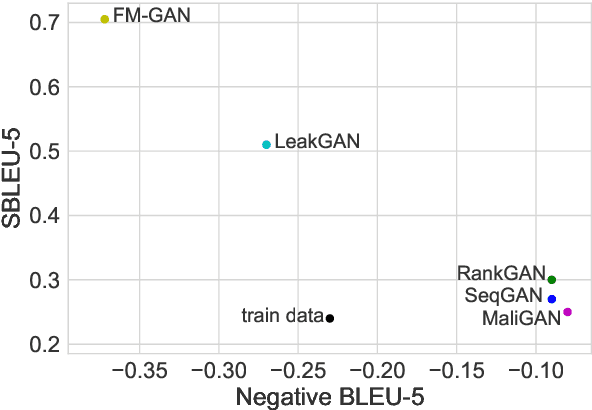
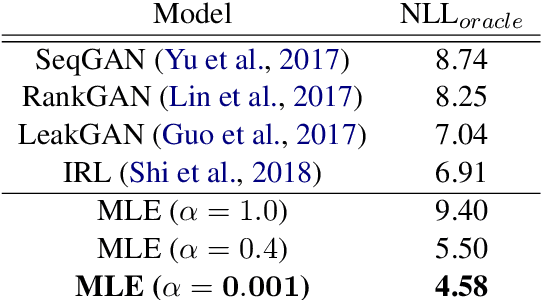
Generating high-quality text with sufficient diversity is essential for a wide range of Natural Language Generation (NLG) tasks. Maximum-Likelihood (MLE) models trained with teacher forcing have constantly been reported as weak baselines, where poor performance is attributed to exposure bias; at inference time, the model is fed its own prediction instead of a ground-truth token, which can lead to accumulating errors and poor samples. This line of reasoning has led to an outbreak of adversarial based approaches for NLG, on the account that GANs do not suffer from exposure bias. In this work, we make several surprising observations with contradict common beliefs. We first revisit the canonical evaluation framework for NLG, and point out fundamental flaws with quality-only evaluation: we show that one can outperform such metrics using a simple, well-known temperature parameter to artificially reduce the entropy of the model's conditional distributions. Second, we leverage the control over the quality / diversity tradeoff given by this parameter to evaluate models over the whole quality-diversity spectrum, and find MLE models constantly outperform the proposed GAN variants, over the whole quality-diversity space. Our results have several implications: 1) The impact of exposure bias on sample quality is less severe than previously thought, 2) temperature tuning provides a better quality / diversity trade off than adversarial training, while being easier to train, easier to cross-validate, and less computationally expensive.
The Deconfounded Recommender: A Causal Inference Approach to Recommendation
Aug 20, 2018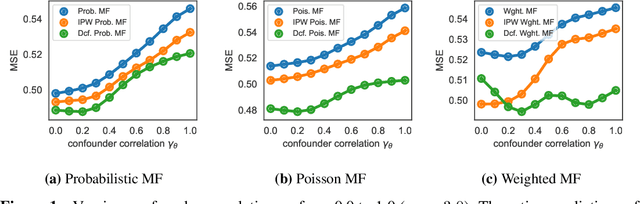
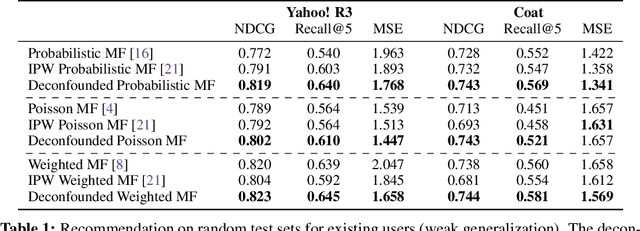
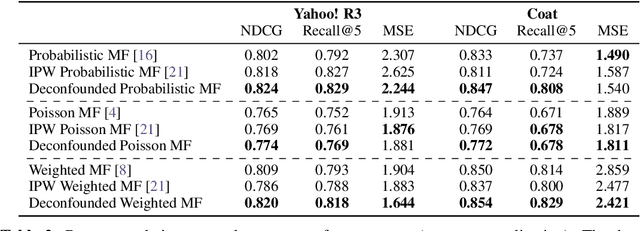
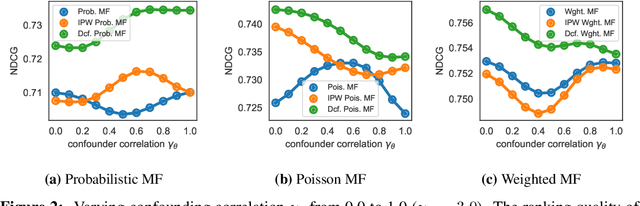
The goal of a recommender system is to show its users items that they will like. In forming its prediction, the recommender system tries to answer: "what would the rating be if we 'forced' the user to watch the movie?" This is a question about an intervention in the world, a causal question, and so traditional recommender systems are doing causal inference from observational data. This paper develops a causal inference approach to recommendation. Traditional recommenders are likely biased by unobserved confounders, variables that affect both the "treatment assignments" (which movies the users watch) and the "outcomes" (how they rate them). We develop the deconfounded recommender, a strategy to leverage classical recommendation models for causal predictions. The deconfounded recommender uses Poisson factorization on which movies users watched to infer latent confounders in the data; it then augments common recommendation models to correct for potential confounding bias. The deconfounded recommender improves recommendation and it enjoys stable performance against interventions on test sets.