 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating DDPM-based Samples from Tilted Distributions
Apr 03, 2026Given $n$ independent samples from a $d$-dimensional probability distribution, our aim is to generate diffusion-based samples from a distribution obtained by tilting the original, where the degree of tilt is parametrized by $θ\in \mathbb{R}^d$. We define a plug-in estimator and show that it is minimax-optimal. We develop Wasserstein bounds between the distribution of the plug-in estimator and the true distribution as a function of $n$ and $θ$, illustrating regimes where the output and the desired true distribution are close. Further, under some assumptions, we prove the TV-accuracy of running Diffusion on these tilted samples. Our theoretical results are supported by extensive simulations. Applications of our work include finance, weather and climate modelling, and many other domains, where the aim may be to generate samples from a tilted distribution that satisfies practically motivated moment constraints.
Causal Identification in Multi-Task Demand Learning with Confounding
Feb 10, 2026We study a canonical multi-task demand learning problem motivated by retail pricing, in which a firm seeks to estimate heterogeneous linear price-response functions across a large collection of decision contexts. Each context is characterized by rich observable covariates yet typically exhibits only limited historical price variation, motivating the use of multi-task learning to borrow strength across tasks. A central challenge in this setting is endogeneity: historical prices are chosen by managers or algorithms and may be arbitrarily correlated with unobserved, task-level demand determinants. Under such confounding by latent fundamentals, commonly used approaches, such as pooled regression and meta-learning, fail to identify causal price effects. We propose a new estimation framework that achieves causal identification despite arbitrary dependence between prices and latent task structure. Our approach, Decision-Conditioned Masked-Outcome Meta-Learning (DCMOML), involves carefully designing the information set of a meta-learner to leverage cross-task heterogeneity while accounting for endogenous decision histories. Under a mild restriction on price adaptivity in each task, we establish that this method identifies the conditional mean of the task-specific causal parameters given the designed information set. Our results provide guarantees for large-scale demand estimation with endogenous prices and small per-task samples, offering a principled foundation for deploying causal, data-driven pricing models in operational environments.
Fundamental limits for weighted empirical approximations of tilted distributions
Dec 30, 2025Consider the task of generating samples from a tilted distribution of a random vector whose underlying distribution is unknown, but samples from it are available. This finds applications in fields such as finance and climate science, and in rare event simulation. In this article, we discuss the asymptotic efficiency of a self-normalized importance sampler of the tilted distribution. We provide a sharp characterization of its accuracy, given the number of samples and the degree of tilt. Our findings reveal a surprising dichotomy: while the number of samples needed to accurately tilt a bounded random vector increases polynomially in the tilt amount, it increases at a super polynomial rate for unbounded distributions.
Systematic Optimization of Open Source Large Language Models for Mathematical Reasoning
Sep 08, 2025This paper presents a practical investigation into fine-tuning model parameters for mathematical reasoning tasks through experimenting with various configurations including randomness control, reasoning depth, and sampling strategies, careful tuning demonstrates substantial improvements in efficiency as well as performance. A holistically optimized framework is introduced for five state-of-the-art models on mathematical reasoning tasks, exhibiting significant performance boosts while maintaining solution correctness. Through systematic parameter optimization across Qwen2.5-72B, Llama-3.1-70B, DeepSeek-V3, Mixtral-8x22B, and Yi-Lightning, consistent efficiency gains are demonstrated with 100% optimization success rate. The methodology achieves an average 29.4% reduction in computational cost and 23.9% improvement in inference speed across all tested models. This framework systematically searches parameter spaces including temperature (0.1-0.5), reasoning steps (4-12), planning periods (1-4), and nucleus sampling (0.85-0.98), determining optimal configurations through testing on mathematical reasoning benchmarks. Critical findings show that lower temperature regimes (0.1-0.4) and reduced reasoning steps (4-6) consistently enhance efficiency without compromising accuracy. DeepSeek-V3 achieves the highest accuracy at 98%, while Mixtral-8x22B delivers the most cost-effective performance at 361.5 tokens per accurate response. Key contributions include: (1) the first comprehensive optimization study for five diverse SOTA models in mathematical reasoning, (2) a standardized production-oriented parameter optimization framework, (3) discovery of universal optimization trends applicable across model architectures, and (4) production-ready configurations with extensive performance characterization.
Collaborative Prediction: Tractable Information Aggregation via Agreement
Apr 08, 2025We give efficient "collaboration protocols" through which two parties, who observe different features about the same instances, can interact to arrive at predictions that are more accurate than either could have obtained on their own. The parties only need to iteratively share and update their own label predictions-without either party ever having to share the actual features that they observe. Our protocols are efficient reductions to the problem of learning on each party's feature space alone, and so can be used even in settings in which each party's feature space is illegible to the other-which arises in models of human/AI interaction and in multi-modal learning. The communication requirements of our protocols are independent of the dimensionality of the data. In an online adversarial setting we show how to give regret bounds on the predictions that the parties arrive at with respect to a class of benchmark policies defined on the joint feature space of the two parties, despite the fact that neither party has access to this joint feature space. We also give simpler algorithms for the same task in the batch setting in which we assume that there is a fixed but unknown data distribution. We generalize our protocols to a decision theoretic setting with high dimensional outcome spaces, where parties communicate only "best response actions." Our theorems give a computationally and statistically tractable generalization of past work on information aggregation amongst Bayesians who share a common and correct prior, as part of a literature studying "agreement" in the style of Aumann's agreement theorem. Our results require no knowledge of (or even the existence of) a prior distribution and are computationally efficient. Nevertheless we show how to lift our theorems back to this classical Bayesian setting, and in doing so, give new information aggregation theorems for Bayesian agreement.
Tractable Agreement Protocols
Nov 29, 2024We present an efficient reduction that converts any machine learning algorithm into an interactive protocol, enabling collaboration with another party (e.g., a human) to achieve consensus on predictions and improve accuracy. This approach imposes calibration conditions on each party, which are computationally and statistically tractable relaxations of Bayesian rationality. These conditions are sensible even in prior-free settings, representing a significant generalization of Aumann's classic "agreement theorem." In our protocol, the model first provides a prediction. The human then responds by either agreeing or offering feedback. The model updates its state and revises its prediction, while the human may adjust their beliefs. This iterative process continues until the two parties reach agreement. Initially, we study a setting that extends Aumann's Agreement Theorem, where parties aim to agree on a one-dimensional expectation by iteratively sharing their current estimates. Here, we recover the convergence theorem of Aaronson'05 under weaker assumptions. We then address the case where parties hold beliefs over distributions with d outcomes, exploring two feedback mechanisms. The first involves vector-valued estimates of predictions, while the second adopts a decision-theoretic approach: the human, needing to take an action from a finite set based on utility, communicates their utility-maximizing action at each round. In this setup, the number of rounds until agreement remains independent of d. Finally, we generalize to scenarios with more than two parties, where computational complexity scales linearly with the number of participants. Our protocols rely on simple, efficient conditions and produce predictions that surpass the accuracy of any individual party's alone.
VELOCITI: Can Video-Language Models Bind Semantic Concepts through Time?
Jun 16, 2024Compositionality is a fundamental aspect of vision-language understanding and is especially required for videos since they contain multiple entities (e.g. persons, actions, and scenes) interacting dynamically over time. Existing benchmarks focus primarily on perception capabilities. However, they do not study binding, the ability of a model to associate entities through appropriate relationships. To this end, we propose VELOCITI, a new benchmark building on complex movie clips and dense semantic role label annotations to test perception and binding in video language models (contrastive and Video-LLMs). Our perception-based tests require discriminating video-caption pairs that share similar entities, and the binding tests require models to associate the correct entity to a given situation while ignoring the different yet plausible entities that also appear in the same video. While current state-of-the-art models perform moderately well on perception tests, accuracy is near random when both entities are present in the same video, indicating that they fail at binding tests. Even the powerful Gemini 1.5 Flash has a substantial gap (16-28%) with respect to human accuracy in such binding tests.
Model Ensembling for Constrained Optimization
May 27, 2024
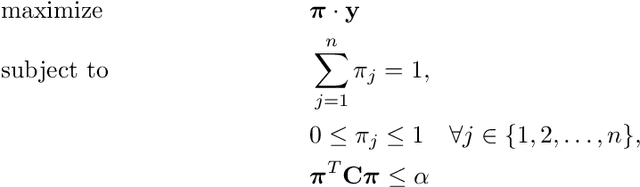


There is a long history in machine learning of model ensembling, beginning with boosting and bagging and continuing to the present day. Much of this history has focused on combining models for classification and regression, but recently there is interest in more complex settings such as ensembling policies in reinforcement learning. Strong connections have also emerged between ensembling and multicalibration techniques. In this work, we further investigate these themes by considering a setting in which we wish to ensemble models for multidimensional output predictions that are in turn used for downstream optimization. More precisely, we imagine we are given a number of models mapping a state space to multidimensional real-valued predictions. These predictions form the coefficients of a linear objective that we would like to optimize under specified constraints. The fundamental question we address is how to improve and combine such models in a way that outperforms the best of them in the downstream optimization problem. We apply multicalibration techniques that lead to two provably efficient and convergent algorithms. The first of these (the white box approach) requires being given models that map states to output predictions, while the second (the \emph{black box} approach) requires only policies (mappings from states to solutions to the optimization problem). For both, we provide convergence and utility guarantees. We conclude by investigating the performance and behavior of the two algorithms in a controlled experimental setting.
Repeated Contracting with Multiple Non-Myopic Agents: Policy Regret and Limited Liability
Feb 27, 2024We study a repeated contracting setting in which a Principal adaptively chooses amongst $k$ Agents at each of $T$ rounds. The Agents are non-myopic, and so a mechanism for the Principal induces a $T$-round extensive form game amongst the Agents. We give several results aimed at understanding an under-explored aspect of contract theory -- the game induced when choosing an Agent to contract with. First, we show that this game admits a pure-strategy \emph{non-responsive} equilibrium amongst the Agents -- informally an equilibrium in which the Agent's actions depend on the history of realized states of nature, but not on the history of each other's actions, and so avoids the complexities of collusion and threats. Next, we show that if the Principal selects Agents using a \emph{monotone} bandit algorithm, then for any concave contract, in any such equilibrium, the Principal obtains no regret to contracting with the best Agent in hindsight -- not just given their realized actions, but also to the counterfactual world in which they had offered a guaranteed $T$-round contract to the best Agent in hindsight, which would have induced a different sequence of actions. Finally, we show that if the Principal selects Agents using a monotone bandit algorithm which guarantees no swap-regret, then the Principal can additionally offer only limited liability contracts (in which the Agent never needs to pay the Principal) while getting no-regret to the counterfactual world in which she offered a linear contract to the best Agent in hindsight -- despite the fact that linear contracts are not limited liability. We instantiate this theorem by demonstrating the existence of a monotone no swap-regret bandit algorithm, which to our knowledge has not previously appeared in the literature.
Learning Self-Supervised Representations for Label Efficient Cross-Domain Knowledge Transfer on Diabetic Retinopathy Fundus Images
Apr 20, 2023



This work presents a novel label-efficient selfsupervised representation learning-based approach for classifying diabetic retinopathy (DR) images in cross-domain settings. Most of the existing DR image classification methods are based on supervised learning which requires a lot of time-consuming and expensive medical domain experts-annotated data for training. The proposed approach uses the prior learning from the source DR image dataset to classify images drawn from the target datasets. The image representations learned from the unlabeled source domain dataset through contrastive learning are used to classify DR images from the target domain dataset. Moreover, the proposed approach requires a few labeled images to perform successfully on DR image classification tasks in cross-domain settings. The proposed work experiments with four publicly available datasets: EyePACS, APTOS 2019, MESSIDOR-I, and Fundus Images for self-supervised representation learning-based DR image classification in cross-domain settings. The proposed method achieves state-of-the-art results on binary and multiclassification of DR images, even in cross-domain settings. The proposed method outperforms the existing DR image binary and multi-class classification methods proposed in the literature. The proposed method is also validated qualitatively using class activation maps, revealing that the method can learn explainable image representations. The source code and trained models are published on GitHub.