 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Video Inpainting Detection
Jan 26, 2021
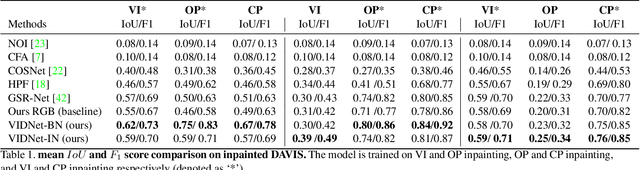
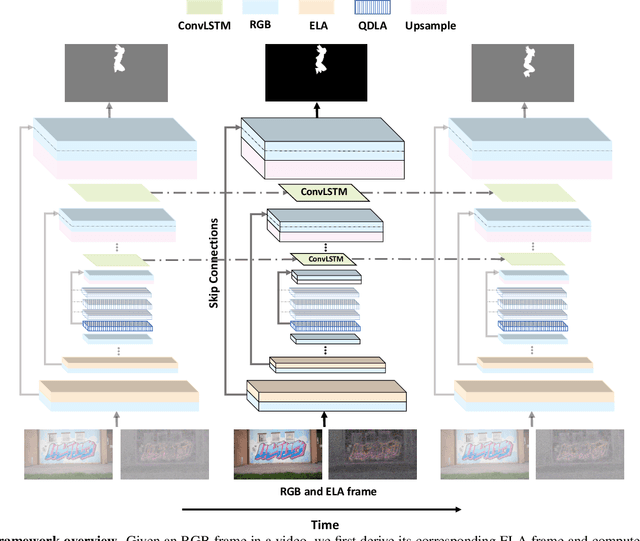
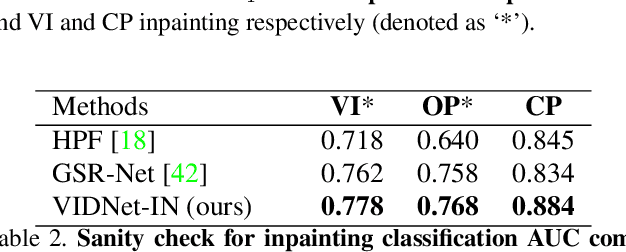
This paper studies video inpainting detection, which localizes an inpainted region in a video both spatially and temporally. In particular, we introduce VIDNet, Video Inpainting Detection Network, which contains a two-stream encoder-decoder architecture with attention module. To reveal artifacts encoded in compression, VIDNet additionally takes in Error Level Analysis frames to augment RGB frames, producing multimodal features at different levels with an encoder. Exploring spatial and temporal relationships, these features are further decoded by a Convolutional LSTM to predict masks of inpainted regions. In addition, when detecting whether a pixel is inpainted or not, we present a quad-directional local attention module that borrows information from its surrounding pixels from four directions. Extensive experiments are conducted to validate our approach. We demonstrate, among other things, that VIDNet not only outperforms by clear margins alternative inpainting detection methods but also generalizes well on novel videos that are unseen during training.
2D or not 2D? Adaptive 3D Convolution Selection for Efficient Video Recognition
Dec 29, 2020
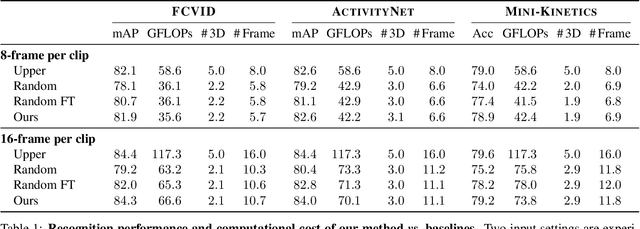
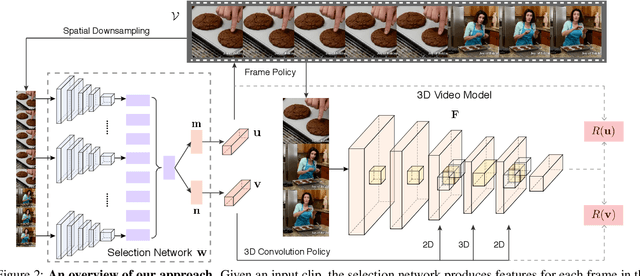

3D convolutional networks are prevalent for video recognition. While achieving excellent recognition performance on standard benchmarks, they operate on a sequence of frames with 3D convolutions and thus are computationally demanding. Exploiting large variations among different videos, we introduce Ada3D, a conditional computation framework that learns instance-specific 3D usage policies to determine frames and convolution layers to be used in a 3D network. These policies are derived with a two-head lightweight selection network conditioned on each input video clip. Then, only frames and convolutions that are selected by the selection network are used in the 3D model to generate predictions. The selection network is optimized with policy gradient methods to maximize a reward that encourages making correct predictions with limited computation. We conduct experiments on three video recognition benchmarks and demonstrate that our method achieves similar accuracies to state-of-the-art 3D models while requiring 20%-50% less computation across different datasets. We also show that learned policies are transferable and Ada3D is compatible to different backbones and modern clip selection approaches. Our qualitative analysis indicates that our method allocates fewer 3D convolutions and frames for "static" inputs, yet uses more for motion-intensive clips.
All About Knowledge Graphs for Actions
Aug 28, 2020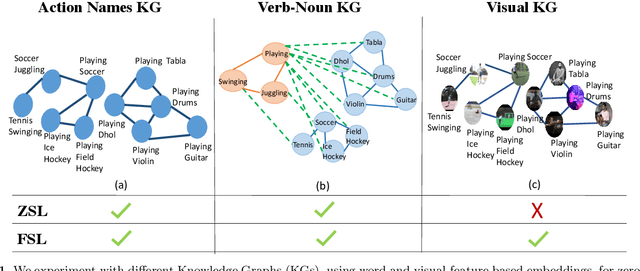
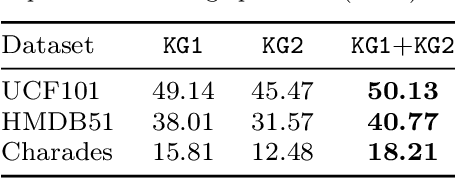
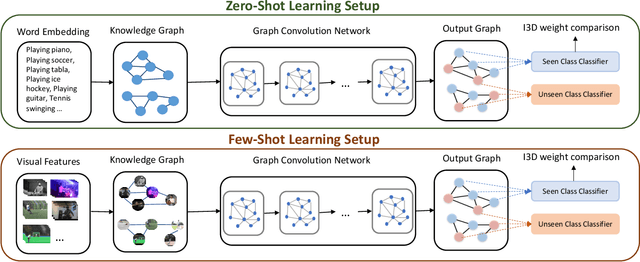
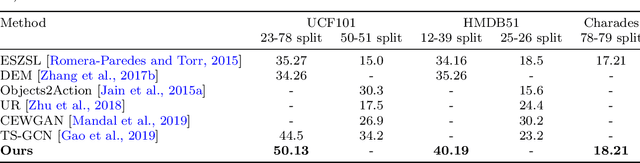
Current action recognition systems require large amounts of training data for recognizing an action. Recent works have explored the paradigm of zero-shot and few-shot learning to learn classifiers for unseen categories or categories with few labels. Following similar paradigms in object recognition, these approaches utilize external sources of knowledge (eg. knowledge graphs from language domains). However, unlike objects, it is unclear what is the best knowledge representation for actions. In this paper, we intend to gain a better understanding of knowledge graphs (KGs) that can be utilized for zero-shot and few-shot action recognition. In particular, we study three different construction mechanisms for KGs: action embeddings, action-object embeddings, visual embeddings. We present extensive analysis of the impact of different KGs in different experimental setups. Finally, to enable a systematic study of zero-shot and few-shot approaches, we propose an improved evaluation paradigm based on UCF101, HMDB51, and Charades datasets for knowledge transfer from models trained on Kinetics.
InfoFocus: 3D Object Detection for Autonomous Driving with Dynamic Information Modeling
Jul 16, 2020

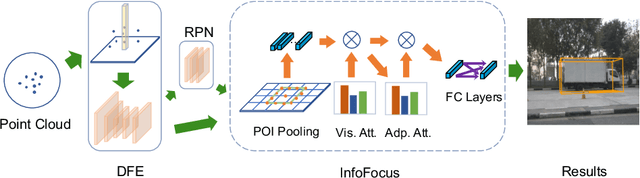
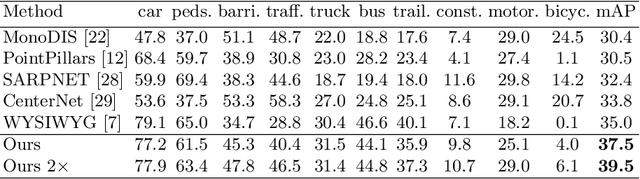
Real-time 3D object detection is crucial for autonomous cars. Achieving promising performance with high efficiency, voxel-based approaches have received considerable attention. However, previous methods model the input space with features extracted from equally divided sub-regions without considering that point cloud is generally non-uniformly distributed over the space. To address this issue, we propose a novel 3D object detection framework with dynamic information modeling. The proposed framework is designed in a coarse-to-fine manner. Coarse predictions are generated in the first stage via a voxel-based region proposal network. We introduce InfoFocus, which improves the coarse detections by adaptively refining features guided by the information of point cloud density. Experiments are conducted on the large-scale nuScenes 3D detection benchmark. Results show that our framework achieves the state-of-the-art performance with 31 FPS and improves our baseline significantly by 9.0% mAP on the nuScenes test set.
DOPS: Learning to Detect 3D Objects and Predict their 3D Shapes
Apr 07, 2020
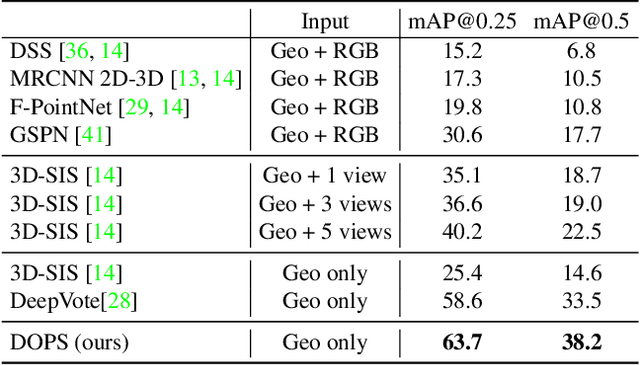
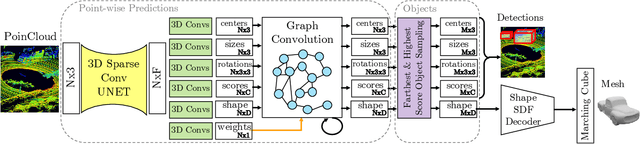
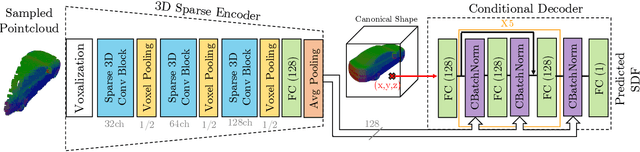
We propose DOPS, a fast single-stage 3D object detection method for LIDAR data. Previous methods often make domain-specific design decisions, for example projecting points into a bird-eye view image in autonomous driving scenarios. In contrast, we propose a general-purpose method that works on both indoor and outdoor scenes. The core novelty of our method is a fast, single-pass architecture that both detects objects in 3D and estimates their shapes. 3D bounding box parameters are estimated in one pass for every point, aggregated through graph convolutions, and fed into a branch of the network that predicts latent codes representing the shape of each detected object. The latent shape space and shape decoder are learned on a synthetic dataset and then used as supervision for the end-to-end training of the 3D object detection pipeline. Thus our model is able to extract shapes without access to ground-truth shape information in the target dataset. During experiments, we find that our proposed method achieves state-of-the-art results by ~5% on object detection in ScanNet scenes, and it gets top results by 3.4% in the Waymo Open Dataset, while reproducing the shapes of detected cars.
SaccadeNet: A Fast and Accurate Object Detector
Mar 26, 2020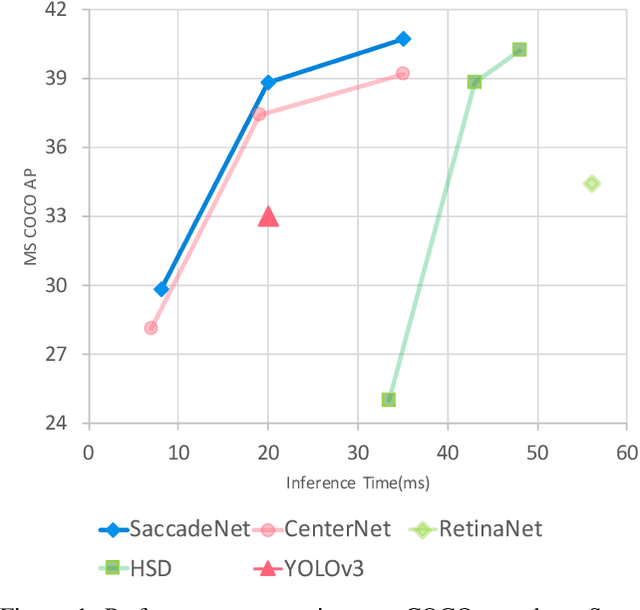
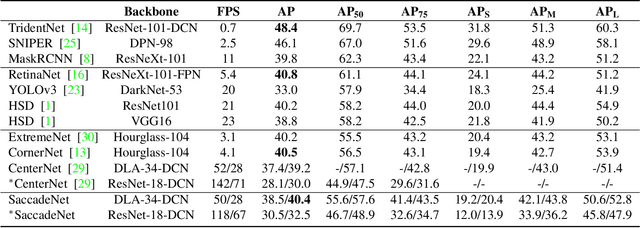
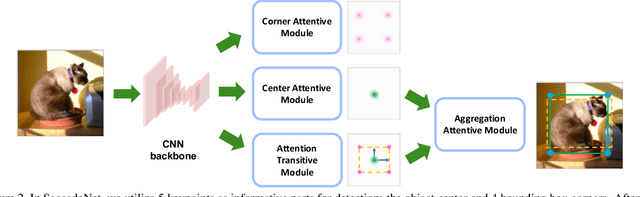

Object detection is an essential step towards holistic scene understanding. Most existing object detection algorithms attend to certain object areas once and then predict the object locations. However, neuroscientists have revealed that humans do not look at the scene in fixed steadiness. Instead, human eyes move around, locating informative parts to understand the object location. This active perceiving movement process is called \textit{saccade}. %In this paper, Inspired by such mechanism, we propose a fast and accurate object detector called \textit{SaccadeNet}. It contains four main modules, the \cenam, the \coram, the \atm, and the \aggatt, which allows it to attend to different informative object keypoints, and predict object locations from coarse to fine. The \coram~is used only during training to extract more informative corner features which brings free-lunch performance boost. On the MS COCO dataset, we achieve the performance of 40.4\% mAP at 28 FPS and 30.5\% mAP at 118 FPS. Among all the real-time object detectors, %that can run faster than 25 FPS, our SaccadeNet achieves the best detection performance, which demonstrates the effectiveness of the proposed detection mechanism.
DeepStrip: High Resolution Boundary Refinement
Mar 25, 2020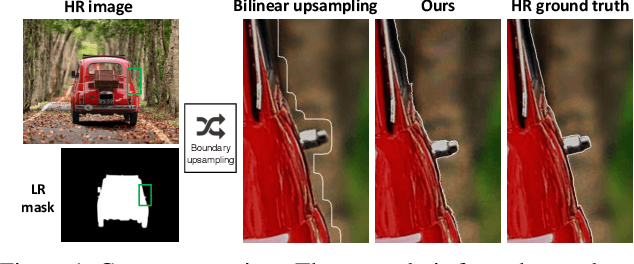
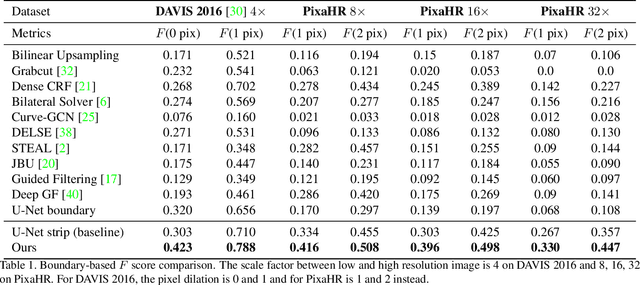
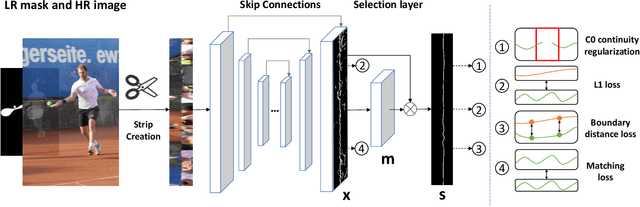
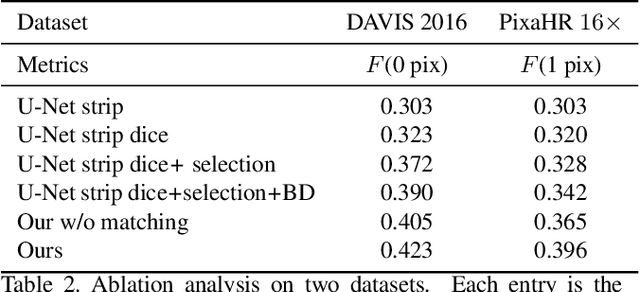
In this paper, we target refining the boundaries in high resolution images given low resolution masks. For memory and computation efficiency, we propose to convert the regions of interest into strip images and compute a boundary prediction in the strip domain. To detect the target boundary, we present a framework with two prediction layers. First, all potential boundaries are predicted as an initial prediction and then a selection layer is used to pick the target boundary and smooth the result. To encourage accurate prediction, a loss which measures the boundary distance in the strip domain is introduced. In addition, we enforce a matching consistency and C0 continuity regularization to the network to reduce false alarms. Extensive experiments on both public and a newly created high resolution dataset strongly validate our approach.
Deep Depth Prior for Multi-View Stereo
Jan 21, 2020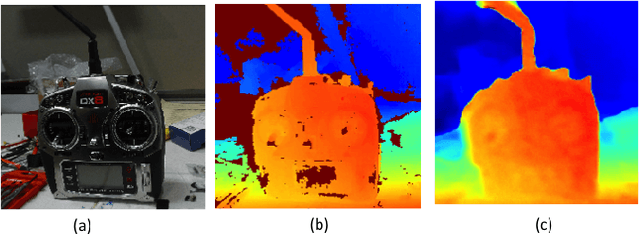
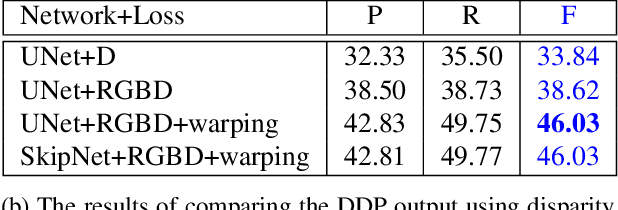
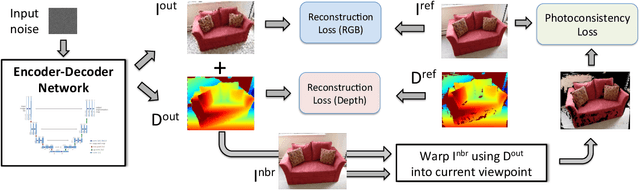
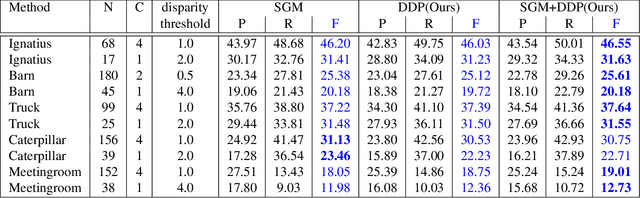
It was recently shown that the structure of convolutional neural networks induces a strong prior favoring natural color images, a phenomena referred to as a deep image prior (DIP), which can be an effective regularizer in inverse problems such as image denoising, inpainting etc. In this paper, we investigate a similar idea for depth images, which we call a deep depth prior. Specifically, given a color image and a noisy and incomplete target depth map from the same viewpoint, we optimize a randomly initialized CNN model to reconstruct an RGB-D image where the depth channel gets restored by virtue of using the network structure as a prior. We propose using deep depth priors for refining and inpainting noisy depth maps within a multi-view stereo pipeline. We optimize the network parameters to minimize two losses 1) a RGB-D reconstruction loss based on the noisy depth map and 2) a multi-view photoconsistency-based loss, which is computed using images from a geometrically calibrated camera from nearby viewpoints. Our quantitative and qualitative evaluation shows that our refined depth maps are more accurate and complete, and after fusion, produces dense 3D models of higher quality.
Recognizing Instagram Filtered Images with Feature De-stylization
Dec 30, 2019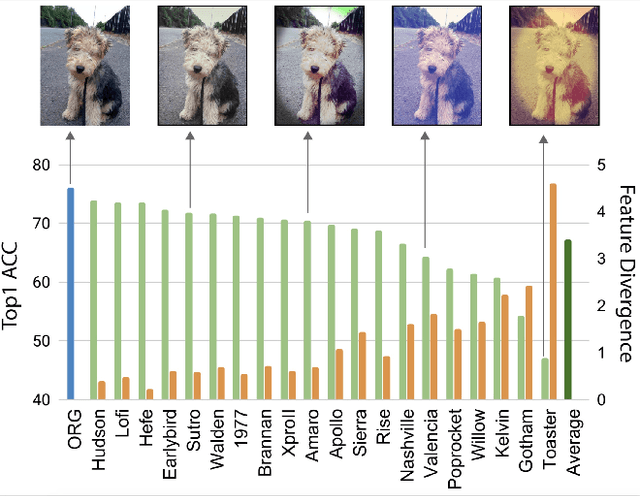


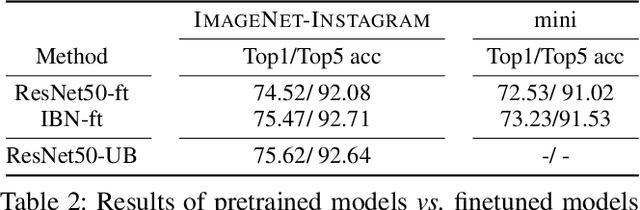
Deep neural networks have been shown to suffer from poor generalization when small perturbations are added (like Gaussian noise), yet little work has been done to evaluate their robustness to more natural image transformations like photo filters. This paper presents a study on how popular pretrained models are affected by commonly used Instagram filters. To this end, we introduce ImageNet-Instagram, a filtered version of ImageNet, where 20 popular Instagram filters are applied to each image in ImageNet. Our analysis suggests that simple structure preserving filters which only alter the global appearance of an image can lead to large differences in the convolutional feature space. To improve generalization, we introduce a lightweight de-stylization module that predicts parameters used for scaling and shifting feature maps to "undo" the changes incurred by filters, inverting the process of style transfer tasks. We further demonstrate the module can be readily plugged into modern CNN architectures together with skip connections. We conduct extensive studies on ImageNet-Instagram, and show quantitatively and qualitatively, that the proposed module, among other things, can effectively improve generalization by simply learning normalization parameters without retraining the entire network, thus recovering the alterations in the feature space caused by the filters.
Fashion Outfit Complementary Item Retrieval
Dec 19, 2019

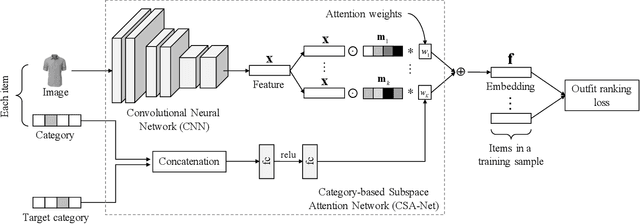

Complementary fashion item recommendation is critical for fashion outfit completion. Existing methods mainly focus on outfit compatibility prediction but not in a retrieval setting. We propose a new framework for outfit complementary item retrieval. Specifically, a category-based subspace attention network is presented, which is a scalable approach for learning the subspace attentions. In addition, we introduce an outfit ranking loss that better models the item relationships of an entire outfit. We evaluate our method on the outfit compatibility, FITB and new retrieval tasks. Experimental results demonstrate that our approach outperforms state-of-the-art methods in both compatibility prediction and complementary item retrieval